
PyTorch是一种深度学习计算框架,可用来训练模型。本文介绍如何通过Triton或TorchServe方式部署PyTorch模型的推理服务。
前提条件
已创建包含GPU的Kubernetes集群。具体操作,请参见创建GPU集群。
Kubernetes集群可以访问公网。具体操作,请参见集群节点可以访问公网。
已安装Arena组件。具体操作,请参见配置Arena客户端。
步骤一:部署PyTorch模型
(推荐)使用Triton部署
本方式采用PyTorch 1.16训练的Bert模型,将模型转换成Torchscript,存储在PVC的triton目录下,然后通过nvidia triton server部署模型。
triton要求的模型目录结构如下:
└── chnsenticorp # 模型名称。
├── 1623831335 # 模型版本。
│ └── model.savedmodel # 模型文件。
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── config.pbtxt # triton 配置。完成PyTorch单机训练,并将PyTorch模型转换成Torchscript,具体操作,请参见使用Arena提交PyTorch单机训练作业。
执行以下命令,检查集群中可用的GPU资源。
arena top node预期输出:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated) cn-beijing.192.168.0.100 192.168.0.100 <none> Ready 1 0 cn-beijing.192.168.0.101 192.168.0.101 <none> Ready 1 0 cn-beijing.192.168.0.99 192.168.0.99 <none> Ready 1 0 --------------------------------------------------------------------------------------------------- Allocated/Total GPUs of nodes which own resource nvidia.com/gpu In Cluster: 0/3 (0.0%)从上述输出可知,该集群有3个GPU节点可以用来部署模型。
将模型上传到阿里云OSS对应的Bucket中。
重要上传到OSS的步骤以Linux系统为例,其他系统的上传操作,请参见命令行工具ossutil命令参考。
创建名称为
examplebucket的存储空间。输入以下命令创建
examplebucket。ossutil64 mb oss://examplebucket以下输出结果表明已成功创建
examplebucket。0.668238(s) elapsed
将模型上传到新建的
examplebucket中。ossutil64 cp model.savedmodel oss://examplebucket
创建PV和PVC。
使用以下模板创建
PyTorch.yaml文件。apiVersion: v1 kind: PersistentVolume metadata: name: model-csi-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: model-csi-pv // 需要和PV名字一致。 volumeAttributes: bucket: "Your Bucket" url: "Your oss url" akId: "Your Access Key Id" akSecret: "Your Access Key Secret" otherOpts: "-o max_stat_cache_size=0 -o allow_other" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 5Gi参数
说明
bucket
OSS的Bucket名称,在OSS范围内全局唯一。更多信息,请参见存储空间命名。
url
OSS文件的访问URL。更多信息,请参见如何获取单个或多个文件的URL。
akId
访问OSS的AccessKey ID和AccessKey Secret。建议使用RAM用户访问,更多信息,请参见创建AccessKey。
akSecret
otherOpts
挂载OSS时支持定制化参数输入。
-o max_stat_cache_size=0代表禁用属性缓存,每次访问文件都会从 OSS 中获取最新的属性信息。-o allow_other代表允许其他用户访问挂载的文件系统。
参数设置的更多信息,请参见ossfs支持的设置参数选项。
执行以下命令,创建PV和PVC。
kubectl apply -f Tensorflow.yaml
执行以下命令,使用
nvidia triton server部署模型。arena serve triton \ --name=bert-triton \ --namespace=inference \ --gpus=1 \ --replicas=1 \ --image=nvcr.io/nvidia/tritonserver:20.12-py3 \ --data=model-pvc:/models \ --model-repository=/models/triton预期输出:
configmap/bert-triton-202106251740-triton-serving created configmap/bert-triton-202106251740-triton-serving labeled service/bert-triton-202106251740-tritoninferenceserver created deployment.apps/bert-triton-202106251740-tritoninferenceserver created INFO[0001] The Job bert-triton has been submitted successfully INFO[0001] You can run `arena get bert-triton --type triton-serving` to check the job status
使用TorchServe部署
使用torch-model-archiver将PyTorch模型打包为TorchServe需要的.mar格式。更多信息,请参见torch-model-archiver。
将模型上传到阿里云OSS对应的Bucket中。
重要上传到OSS的步骤以Linux系统为例,其他系统的上传操作,请参见命令行工具ossutil命令参考。
创建名称为
examplebucket的存储空间。输入以下命令创建
examplebucket。ossutil64 mb oss://examplebucket以下输出结果表明已成功创建
examplebucket。0.668238(s) elapsed
将模型上传到新建的
examplebucket中。ossutil64 cp model.savedmodel oss://examplebucket
创建PV和PVC。
使用以下模板创建
Tensorflow.yaml文件。apiVersion: v1 kind: PersistentVolume metadata: name: model-csi-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: model-csi-pv // 需要和PV名字一致。 volumeAttributes: bucket: "Your Bucket" url: "Your oss url" akId: "Your Access Key Id" akSecret: "Your Access Key Secret" otherOpts: "-o max_stat_cache_size=0 -o allow_other" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 5Gi参数
说明
bucket
OSS的Bucket名称,在OSS范围内全局唯一。更多信息,请参见存储空间命名。
url
OSS文件的访问URL。更多信息,请参见如何获取单个或多个文件的URL。
akId
访问OSS的AccessKey ID和AccessKey Secret。建议使用RAM用户访问,更多信息,请参见创建AccessKey。
akSecret
otherOpts
挂载OSS时支持定制化参数输入。
-o max_stat_cache_size=0代表禁用属性缓存,每次访问文件都会从 OSS 中获取最新的属性信息。-o allow_other代表允许其他用户访问挂载的文件系统。
参数设置的更多信息,请参见ossfs支持的设置参数选项。
执行以下命令,创建PV和PVC。
kubectl apply -f Tensorflow.yaml
执行以下命令部署PyTorch模型。
arena serve custom \ --name=torchserve-demo \ --gpus=1 \ --replicas=1 \ --image=pytorch/torchserve:0.4.2-gpu \ --port=8000 \ --restful-port=8001 \ --metrics-port=8002 \ --data=model-pvc:/data \ 'torchserve --start --model-store /data/models --ts-config /data/config/ts.properties'说明image可以是官方镜像,也可以是自定义的TorchServe镜像。
参数中
--model-store的路径需要和您的PyTorch模型的实际路径保持一致。
预期输出:
service/torchserve-demo-202109101624 created deployment.apps/torchserve-demo-202109101624-custom-serving created INFO[0001] The Job torchserve-demo has been submitted successfully INFO[0001] You can run `arena get torchserve-demo --type custom-serving` to check the job status
步骤二:验证推理服务部署
执行以下命令,查看PyTorch模型的部署情况。
arena serve list -n inference预期输出:
NAME TYPE VERSION DESIRED AVAILABLE ADDRESS PORTS bert-triton Triton 202106251740 1 1 172.16.70.14 RESTFUL:8000,GRPC:8001执行以下命令,查看推理服务详情。
arena serve get bert-tfserving -n inference预期输出:
Name: bert-triton Namespace: inference Type: Triton Version: 202106251740 Desired: 1 Available: 1 Age: 5m Address: 172.16.70.14 Port: RESTFUL:8000,GRPC:8001 Instances: NAME STATUS AGE READY RESTARTS NODE ---- ------ --- ----- -------- ---- bert-triton-202106251740-tritoninferenceserver-667cf4c74c-s6nst Running 5m 1/1 0 cn-beijing.192.168.0.89从上述输出可知,通过
nvidia triton server部署模型成功,并提供了8001(GRPC)和8000(RESTFUL)两个API端口。通过
nvidia triton server部署的推理服务默认提供ClusterIP,需要配置公网Ingress才能直接访问。在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在页面顶端的命名空间列表,选择第2步中的命名空间
inference。单击页面右上角的创建Ingress。
服务名称配置为第1步的
bert-triton。端口配置为8501端口(RESTful)。
其他参数按需配置,更多信息,请参见创建Nginx Ingress。
路由创建成功后,在路由页面的规则列获取Ingress地址。
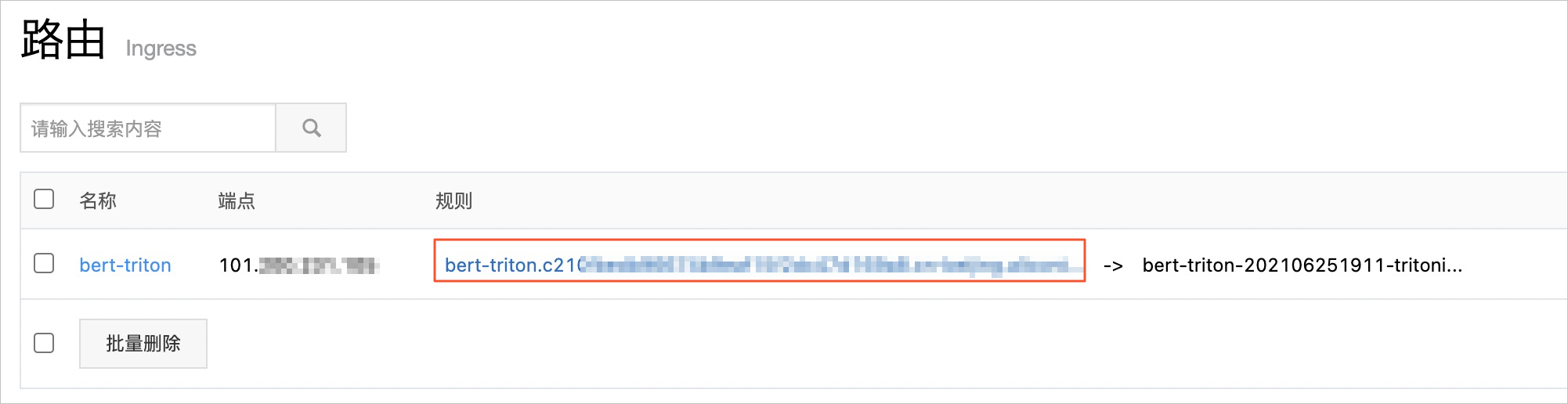
利用获取的Ingress地址,执行以下命令,调用推理服务接口。
nvidia triton server遵循KFServing接口规范。更多信息,请参见API文档Nvidia Triton Server API。curl "http://<Ingress地址>"预期输出:
{ "name":"chnsenticorp", "versions":[ "1623831335" ], "platform":"tensorflow_savedmodel", "inputs":[ { "name":"input_ids", "datatype":"INT64", "shape":[ -1, 128 ] } ], "outputs":[ { "name":"probabilities", "datatype":"FP32", "shape":[ -1, 2 ] } ] }