
PyTorch是一个开源的深度学习框架,广泛应用于各种深度学习模型的训练任务中,本文演示如何使用Arena提交PyTorch单机单卡或单机多卡训练作业,并通过TensorBoard可视化查看训练作业。
前提条件
已创建包含GPU的Kubernetes集群。具体操作,请参见创建包含GPU的Kubernetes集群。
集群节点可以访问公网。具体操作,请参见为已有集群开启公网访问能力。
已安装Arena工具。具体操作,请参见配置Arena客户端。
创建一个名为
training-data的PVC实例,并在路径/pytorch_data下存放MNIST数据集。具体操作,请参见配置NAS共享存储。
背景信息
本文将从远程Git仓库中下载训练代码,并从共享存储系统(基于NAS的PV和PVC)中读取训练数据。torchrun 是 PyTorch 提供的一个命令行工具,用于简化和管理分布式训练任务,本文将使用 torchrun 来启动 PyTorch 单机单卡或单机多卡训练任务,训练代码详见 main.py。
操作步骤
步骤一:查看GPU资源
执行以下命令查看集群中可用的GPU资源。
arena top node预期输出:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0
---------------------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
0/4 (0.0%)可以看到集群中有2个GPU节点,每个GPU节点都包含2张空闲的GPU卡可用于运行训练作业。
步骤二:提交PyTorch训练作业
执行如下命令提交一个单机单卡的PyTorch训练作业。
arena submit pytorch \
--name=pytorch-mnist \
--namespace=default \
--workers=1 \
--gpus=1 \
--working-dir=/root \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/pytorch-with-tensorboard:2.5.1-cuda12.4-cudnn9-runtime \
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=v0.13.1 \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/pytorch_data/logs \
"torchrun /root/code/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"预期输出:
service/pytorch-mnist-tensorboard created
deployment.apps/pytorch-mnist-tensorboard created
pytorchjob.kubeflow.org/pytorch-mnist created
INFO[0002] The Job pytorch-mnist has been submitted successfully
INFO[0002] You can run `arena get pytorch-mnist --type pytorchjob -n default` to check the job status如果您需要执行单机多卡训练作业,例如执行单机两卡训练作业,则可以通过指定 --gpus=2 和 --nproc-per-node=2 参数以分配2张GPU卡并启动2个训练进程:
arena submit pytorch \
--name=pytorch-mnist \
--namespace=default \
--workers=1 \
--gpus=2 \
--nproc-per-node=2 \
--working-dir=/root \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/pytorch-with-tensorboard:2.5.1-cuda12.4-cudnn9-runtime \
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=v0.13.1 \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/pytorch_data/logs \
"torchrun /root/code/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"如果您使用的是非公开Git代码仓库,则可以通过配置环境变量GIT_SYNC_USERNAME和GIT_SYNC_PASSWORD的方式来设置Git用户名和密码。
arena submit pytorch \
...
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=v0.13.1 \
--env=GIT_SYNC_USERNAME=<username> \
--env=GIT_SYNC_PASSWORD=<password> \
"torchrun /root/code/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"arena命令使用git-sync同步源代码,因此您可以使用任何在git-sync项目中定义的环境变量。
本文示例从GitHub仓库中拉取源代码,如遇到网络原因等导致代码无法成功拉取时,可以手动将代码下载到共享存储系统中,假设您已经将代码下载至NAS中的 /code/github.com/kubeflow/arena 路径下,则可以如下提交训练作业:
arena submit pytorch \
--name=pytorch-mnist \
--namespace=default \
--workers=1 \
--gpus=1 \
--working-dir=/root \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/pytorch-with-tensorboard:2.5.1-cuda12.4-cudnn9-runtime \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/pytorch_data/logs \
"torchrun /mnt/code/github.com/kubeflow/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"参数解释如下表。
参数 | 是否必选 | 解释 | 默认值 |
| 必选 | 作业名称,全局唯一,不能重复。 | 无 |
| 可选 | 作业所属的命名空间。 |
|
| 可选 | 指定作业需要的节点数,它设置的值包含Master节点。例如设置3,表明该作业包含1个Master节点和2个Worker节点。 |
|
| 可选 | 指定作业Worker节点需要使用的GPU卡数。 |
|
| 可选 | 指定当前执行命令所在的目录。 |
|
| 必选 | 指定训练环境的镜像地址。 | 无 |
| 可选 | 同步代码的模式,您可以指定git、rsync。本文使用Git模式。 | 无 |
| 可选 | 同步代码的仓库地址,需要和--sync-mode一起使用,本文示例使用Git模式,该参数可以为任何GitHub项目、阿里云Code项目等支持Git的代码托管地址。项目代码将会被下载到--working-dir下的 | 无 |
| 可选 | 挂载共享存储卷PVC到运行环境中。它由两部分组成,通过分号 说明 执行 如果没有可用的PVC,您可创建PVC。详情请参见配置NAS共享存储。 | 无 |
| 可选 | 为训练任务开启一个TensorBoard服务,用作数据可视化,您可以结合--logdir指定TensorBoard要读取的event路径。不指定该参数,则不开启TensorBoard服务。 | 无 |
| 可选 | 需要结合--tensorboard一起使用,该参数表示TensorBoard需要读取event数据的路径。 |
|
步骤三:查看PyTorch训练作业
执行以下命令查看通过arena提交的训练作业。
arena list -n default预期输出:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE pytorch-mnist RUNNING PYTORCHJOB 11s 1 1 192.168.xxx.xxx执行以下命令查看训练作业所使用的GPU资源。
arena top job -n default预期输出:
NAME STATUS TRAINER AGE GPU(Requested) GPU(Allocated) NODE pytorch-mnist RUNNING PYTORCHJOB 18s 1 1 192.168.xxx.xxx Total Allocated/Requested GPUs of Training Jobs: 1/1执行以下命令查看集群中的GPU资源使用情况。
arena top node预期输出:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated) cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0 cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0 cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 1 cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0 --------------------------------------------------------------------------------------------------- Allocated/Total GPUs In Cluster: 1/4 (25.0%)可以看到集群中总共有4张GPU,当前已经分配1张GPU。
执行以下命令查看训练作业详情。
arena get pytorch-mnist -n default预期输出:
Name: pytorch-mnist Status: RUNNING Namespace: default Priority: N/A Trainer: PYTORCHJOB Duration: 45s CreateTime: 2025-02-12 11:20:10 EndTime: Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-mnist-master-0 Running 45s true 1 cn-beijing.192.168.xxx.xxx Tensorboard: Your tensorboard will be available on: http://192.168.xxx.xxx:31949说明当在训练作业中启用了TensorBoard时,作业详情中将会展示TensorBoard访问地址;如果没有启用TensorBoard,则不会展示。
步骤四:查看TensorBoard
在本地执行如下命令,将集群中的TensorBoard的访问端口6006映射到本地的9090端口。
重要请注意kubectl port-forward建立的端口转发不具备生产级别的可靠性、安全性和扩展性,因此仅适用于开发和调试目的,不适合在生产环境使用。更多关于Kubernetes集群内生产可用的网络方案的信息,请参见Ingress管理。
kubectl port-forward -n default svc/pytorch-mnist-tensorboard 9090:6006在浏览器中访问 http://127.0.0.1:9090,即可查看TensorBoard。
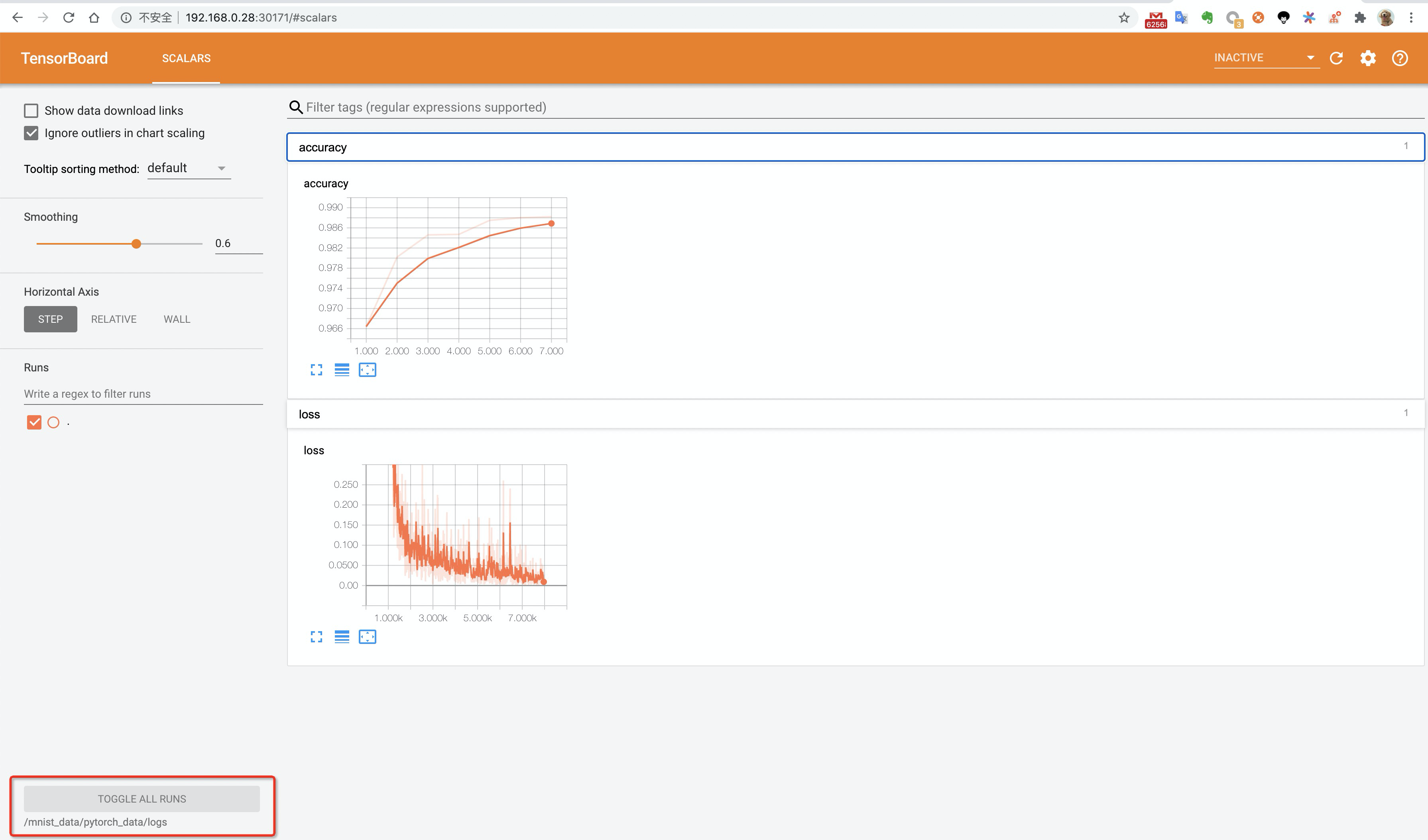 说明
说明本文中PyTorch示例代码,默认每10个epoch写入event信息。如果您修改了--epochs参数,请修改为10的整数倍,否则无法在TensorBoard上看到数据。
步骤五:查看训练作业日志
执行如下命令查看训练作业日志。
arena logs pytorch-mnist -n default预期输出:
Train Epoch: 10 [55680/60000 (93%)] Loss: 0.025778
Train Epoch: 10 [56320/60000 (94%)] Loss: 0.086488
Train Epoch: 10 [56960/60000 (95%)] Loss: 0.003240
Train Epoch: 10 [57600/60000 (96%)] Loss: 0.046731
Train Epoch: 10 [58240/60000 (97%)] Loss: 0.010752
Train Epoch: 10 [58880/60000 (98%)] Loss: 0.010934
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.065813
Accuracy: 9921/10000 (99.21%)如果需要实时查看作业日志,可以添加
-f参数;如果仅需要查看最后 N 行日志,可以添加
-t N或--tail N参数;更多用法请参见
arena logs --help。
(可选)步骤六:环境清理
训练作业执行结束后如不再需要,执行如下命令进行删除:
arena delete pytorch-mnist -n default预期输出:
INFO[0001] The training job pytorch-mnist has been deleted successfully