
阿里云文件存储 NAS(File Storage NAS)是面向阿里云ECS实例、E-HPC和ACK等计算节点的文件存储服务。阿里云NAS服务具有无缝集成、共享访问、安全控制等特性,非常适合跨多个ECS、E-HPC或ACK实例部署的应用程序访问相同数据来源的应用场景。本文介绍如何配置NAS共享存储。
背景信息
为了保护数据科学家的工作内容并方便读取共享的训练数据,建议在Arena提交作业的运行环境中配置共享存储卷并挂载。确保数据科学家的工作内容(代码、数据)得以保留,不会随着容器删除而丢失。在团队开发中,建议分配一个共享的存储池,让数据和代码能够在团队里共享。
在Arena提交作业时,如果声明了配置共享存储及要挂载到运行环境的路径,可以使用--data参数。共享存储将会被挂载到指定的目录中,提交作业可以复用这部分数据或者代码。
在Kubernetes中,通过存储卷(PV)和存储声明(PVC)描述存储对象。作为集群管理员,分配环境时需要为每个数据科学家创建属于自己的存储声明。例如用户A和用户B,存储声明的后端可以挂载到相同的NAS或者CPFS,但是必须指定不同的子目录,保证他们的工作环境隔离。
步骤一:创建NAS实例
有关创建NAS实例的具体操作步骤,请参见通过控制台创建通用型NAS文件系统。
创建NAS实例的参数配置说明如下:
-
文件系统类型设置为通用型。
-
地域设置为和ACK集群相同的地域。
-
专有网络VPC选择和ACK集群相同的VPC。
-
协议类型设置为NFS。
步骤二:挂载文件系统
创建文件存储NAS实例后,需要将NFS文件系统挂载至同一VPC内的ECS实例并验证挂载,本文以控制台一键挂载为例。更多挂载方式请参见挂载文件系统场景说明。
挂载NAS文件系统
登录NAS控制台,执行以下操作:
在左侧导航栏,选择。
在页面左侧顶部,选择目标文件系统所在的资源组和地域。
找到刚创建的文件系统,然后单击操作列的挂载。
说明首次使用NAS一键挂载功能,需要进行NAS一键挂载关联角色授权,请根据对话框中的提示,完成NAS一键挂载服务关联角色授权。更多信息,请参见文件存储NAS服务关联角色。
在挂载面板,完成挂载NAS文件系统配置。
选择挂载点,然后单击下一步。
选择目标ECS实例,然后单击下一步。
请选择与NAS在同一VPC下的ECS实例,当选择不一致时,NAS会提示可能导致网络不通,请注意排查。
说明如果您在实例下拉菜单中查询不到新建的ECS实例,请您刷新页面后再次尝试。
该配置仅支持选择一台目标ECS实例,如果您需要多台ECS实例挂载同一文件系统,请参见多台ECS实例批量挂载同一NFS协议文件系统。
配置挂载到ECS。
配置项
说明
挂载路径
目标ECS实例上待挂载文件系统的本地路径。
自动挂载
默认选中开机自动挂载,当您重启ECS实例时,无需重复挂载操作。
协议类型
选择文件系统协议类型。
通用性NAS文件系统支持NFSv3和NFSv4.0。如果您的业务场景不包含多台ECS实例同时编辑同一个NAS文件,建议您选择NFSv3,达到最优性能。
极速型NAS文件系统支持NFSv3。
NAS目录
NAS文件系统目录。
NAS的根目录(/)或任意子目录(例如:/abc)。
说明如果提示目录不存在,您可以选中确认新建目录,在文件系统中新建该目录。同时您还需要配置创建该目录的UID和GID以及POSIX权限,如果不配置,则使用默认值和默认权限直接创建。
挂载参数
建议您使用默认挂载参数。更多参数说明,请参见参数说明。
单击完成挂载。
挂载需要大约1~2分钟。当挂载状态为挂载成功时,则表示NAS文件系统已成功挂载至ECS。
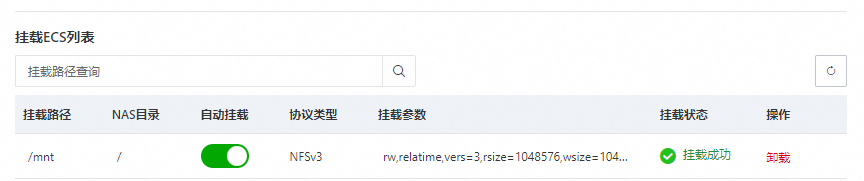
如果挂载状态为挂载失败时,您可以通过排查工具进行排查,详情请参见Linux挂载NFS协议文件系统失败自动检查脚本。
挂载完成后,您还可以连接ECS实例,执行
mount -l或者df -h命令,查看挂载参数信息或文件系统容量信息。
验证挂载
-
挂载成功后,可以在ECS上把NAS文件系统当作一个普通的目录来访问和使用,示例如下。
-
远程连接ECS实例,执行以下命令,在ECS实例上访问NAS文件系统。
mkdir /mnt/dir1 mkdir /mnt/dir2 touch /mnt/file1 echo 'some file content' > /mnt/file2 ls /mnt -
返回如图所示信息,说明成功访问通用容量型NAS NFS文件系统。

-
在文件存储NAS中,需要通过挂载点将文件系统挂载至云服务器ECS。添加更多挂载点、查看挂载点地址的具体操作,请参见管理挂载点。
-
添加挂载点需注意:
-
挂载点类型设置为专有网络。
-
VPC网络和交换机设置为和ACK集群一致的VPC和交换机。
-
步骤三:配置ACK集群的存储卷(PV)和存储声明(PVC)
创建PV
创建PV,在集群中“注册”已有的NAS文件系统。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
-
在存储卷页面,单击创建,在弹出的对话框完成参数配置,然后单击创建。
配置项
说明
示例值
存储卷类型
选择NAS。
NAS
名称
PV名称,在集群内保持唯一。
pv-nas
总量
PV容量声明。此声明仅为PVC匹配依据,不限制实际可用容量。应用实际可用存储上限为NAS文件系统总容量。
NAS实际容量上限由其规格决定,请参见通用型NAS和极速型NAS。
5Gi
访问模式
配置访问模式。可取值:
-
ReadWriteMany:多节点读写。
-
ReadWriteOnce:单节点读写。
ReadWriteMany
是否使用CNFS
是否使用容器网络文件系统CNFS,使用其在自动化运维、缓存加速、性能监控等方面提供的增强能力。
如需使用CNFS管理已有NAS,请参见创建CNFS管理NAS文件系统(推荐)。
不开启
挂载点域名
未开启CNFS时可配置
NAS挂载点地址。
如需获取地址,请参见管理挂载点。
-
选择挂载点:选择此前添加的挂载点地址。
-
自定义:使用自定义域名作为挂载地址。请确保已完成自定义域名到目标NAS挂载点的解析配置。
0c47****-mpk25.cn-shenzhen.nas.aliyuncs.com
高级选项(选填)
挂载路径
待挂载的NAS子目录。如果未设置,则默认挂载到根目录。
如果NAS中没有该目录,系统会自动创建并进行挂载。
-
通用型NAS:根目录为
/。 -
极速型NAS:根目录为
/share。挂载子目录时,path需以/share开头(如/share/data)。
/data
回收策略
-
Retain(默认):删除PVC时,PV和NAS文件不会被删除,需手动删除。
-
Delete:需配合
archiveOnDelete一起使用。静态PV不支持archiveOnDelete,即使配置为Delete,删除PVC时也不会真正删除PV和NAS文件。如需配置
archiveOnDelete,请参见使用NAS动态存储卷。
Retain
挂载选项
NAS的挂载参数,包括NFS协议版本等。推荐使用NFS v3。
-
nolock,tcp,noresvport
-
vers=3
标签
PV的标签。
pv-nas
创建完成后,可在存储卷页面查看新创建的PV。
-
创建PVC
创建PVC,为应用声明其所需的持久化存储容量。
步骤四:给PVC填充数据
因为 Kubernetes 集群通过 PVC 访问各种共享数据(也就是本文在步骤一中创建的NAS实例),所以仅需要给 PVC 实例对应的 NAS 实例填充数据即可。本文已经在 default 命名空间中创建了名为 training-data 的 PVC 实例,下面将通过创建两个 Job 分别从示例容器镜像中复制 PyTorch/TensorFlow MNIST 数据集到 NAS 中的指定目录下。
-
根据如下内容创建并保存为文件
prepare-pytorch-mnist-data.yaml。apiVersion: batch/v1 kind: Job metadata: name: prepare-pytorch-mnist-data namespace: default spec: completions: 1 parallelism: 1 backoffLimit: 3 ttlSecondsAfterFinished: 3600 template: spec: containers: - name: pytorch-mnist-example image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/pytorch-mnist-example:2.5.1-cuda12.4-cudnn9-runtime imagePullPolicy: Always command: - /bin/bash - -c args: - | set -eux mkdir -p /mnt/pytorch_data/MNIST/raw cp -r /data/MNIST/raw/* /mnt/pytorch_data/MNIST/raw || { echo "Copy failed"; exit 1; } echo "MNIST data prepared successfully at /mnt/pytorch_data/MNIST/raw." resources: requests: cpu: 100m memory: 128Mi limits: cpu: 100m memory: 128Mi volumeMounts: - name: training-data mountPath: /mnt volumes: - name: training-data persistentVolumeClaim: claimName: training-data restartPolicy: Never -
创建 Job 从容器镜像中复制 PyTorch MNIST 数据集到 NAS 中的
/pytorch_data目录下:# 创建 Job kubectl create -f prepare-pytorch-mnist-data.yaml # 等待 Job 执行完成 kubectl wait --for=condition=complete --namespace=default --timeout=300s job/prepare-pytorch-mnist-data输出如下则表示 Job 已经成功执行完成:
job.batch/prepare-pytorch-mnist-data condition met -
根据如下内容创建并保存为文件
prepare-tensorflow-mnist-data.yaml。apiVersion: batch/v1 kind: Job metadata: name: prepare-tensorflow-mnist-data namespace: default spec: completions: 1 parallelism: 1 backoffLimit: 3 ttlSecondsAfterFinished: 3600 template: spec: containers: - name: tensorflow-mnist-example image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/tensorflow-mnist-example:2.15.0-gpu imagePullPolicy: Always command: - /bin/bash - -c args: - | set -eux mkdir -p /mnt/tf_data cp -r /data/mnist.npz /mnt/tf_data/mnist.npz || { echo "Copy failed"; exit 1; } echo "MNIST data prepared successfully at /mnt/tf_data/mnist.npz." resources: requests: cpu: 100m memory: 128Mi limits: cpu: 100m memory: 128Mi volumeMounts: - name: training-data mountPath: /mnt volumes: - name: training-data persistentVolumeClaim: claimName: training-data restartPolicy: Never -
创建 Job 从容器镜像中复制 TensorFlow MNIST 数据集到 NAS 中的
/tf_data目录下:# 创建 Job kubectl create -f prepare-tensorflow-mnist-data.yaml # 等待 Job 执行完成 kubectl wait --for=condition=complete --namespace=default --timeout=300s job/prepare-tensorflow-mnist-data输出如下则表示 Job 已经成功执行完成:
job.batch/prepare-tensorflow-mnist-data condition met
本文示例中使用的 PVC 位于 default 命名空间中,名称为 training-data,如您的 PVC 位于其它命名空间中或者具有不同的名称,则需要根据实际值调整上述资源清单内容。