
注意:此项功能仅支持高级版实例,创建高级版实例将默认打开如下服务: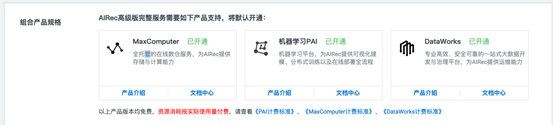 如上服务将用于高级版自定义召回模型的搭建、表存储、计算等。
如上服务将用于高级版自定义召回模型的搭建、表存储、计算等。
如果您希望新增自定义召回模型,需要:
第一步:通过离线算法平台创建AI工作空间;
第二步:通过离线算法平台创建项目;
第三步:通过离线算法平台创建召回结果集;
第四步:创建表成功后,通过在线的控制台的召回表管理处申请资源组;
第五步:待资源组部署完成后,注册召回表;
第六步:在场景下的实验管理中引入召回表,进行实验并观察效果。
一、创建AI工作空间
需要先开通MaxCompute,开通成功后请按照此链接配置:AI工作空间(旧版)
二、通过离线算法平台创建项目
切换到模型训练菜单下,点击创建工作空间。
工作空间定义:
工作空间是管理所有底层资源的最小单元,智能推荐工作空间与DataWorks、PAI的工作空间保持一致,底层可以享受相同的资源。以后DataWorks、PAI工作空间将会直接出现在智能推荐-模型训练列表中。
1、输入工作空间名称
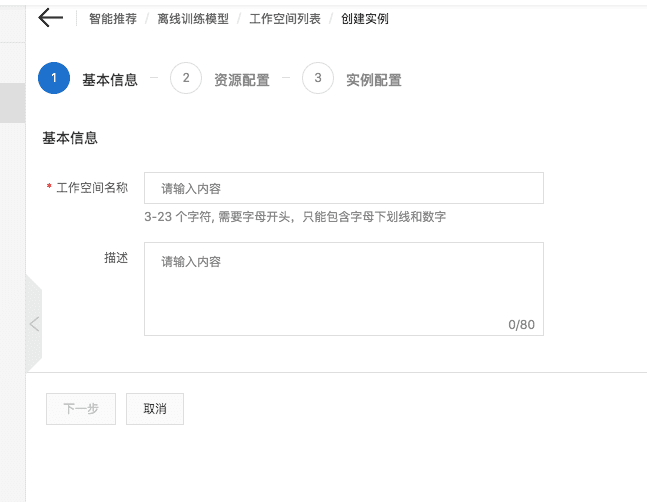
尽量输入较容易区分的名字。
2、购买相应引擎资源
其中PAI后付费为必须购买项,MaxCompute预付费和后付费选择其一即可。
新用户建议购买PAI后付费+MaxCompute后付费的组合,其中MaxCompute为底层大数据计算引擎,PAI为AI引擎。
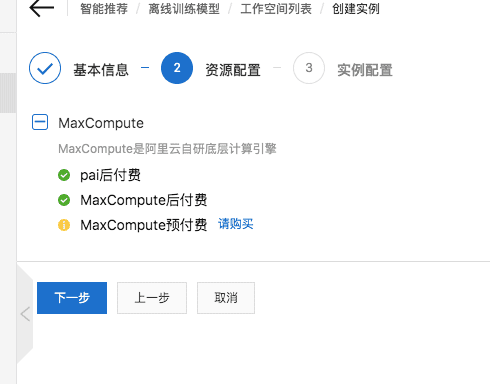
3、创建项目
创建完项目,点击计入算法平台即可开始使用。
模型服务同PAI-EAS功能,用户在模型训练平台完成模型训练并且将模型存储到OSS以后,可以进入模型服务完成模型部署相关操作。
点击左侧的模型上传部署按钮,右侧会弹窗出现配置页。
Processor选择TensorFlow1.12,资源类型按需选择,模型文件地址选择对应的OSS路径。
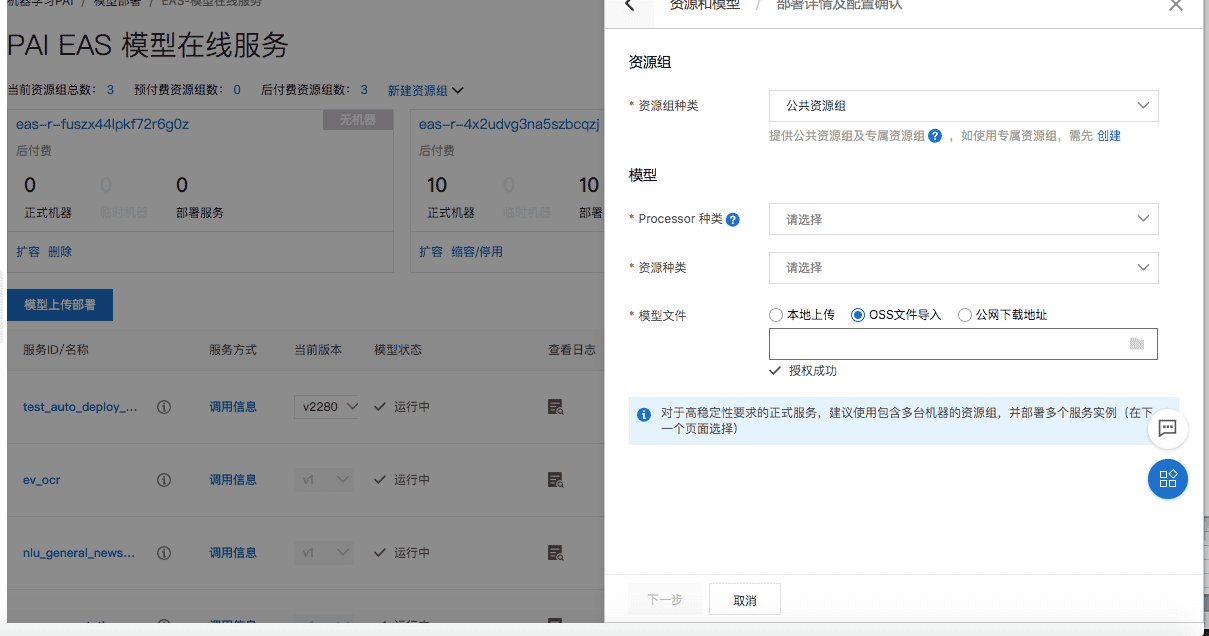
配置生成的模型服务,可以通过智能推荐在线服务平台引用并调用。
三、创建召回结果集
数据挖掘的一个经典案例就是尿布与啤酒的例子。尿布与啤酒看似毫不相关的两种产品,但是当超市将两种产品放到相邻货架销售的时候,会大大提高两者销量。很多时候看似不相关的两种产品,却会存在着某种神秘的隐含关系,获取这种关系将会对提高销售额起到推动作用,然而有时这种关联是很难通过经验分析得到的。这时候我们需要借助数据挖掘中的常见算法-协同过滤来实现。这种算法可以帮助我们挖掘人与人以及商品与商品的关联关系。
协同过滤算法是一种基于关联规则的算法,以购物行为为例。假设有甲和乙两名用户,有a、b、c三款产品。如果甲和乙都购买了a和b这两种产品,我们可以假定甲和乙有近似的购物品味。当甲购买了产品c而乙还没有购买c的时候,我们就可以把c也推荐给乙。这是一种典型的user-based情况,就是以user的特性做为一种关联。
本文的业务场景如下:通过一份7月份前的用户购物行为数据,获取商品的关联关系,对用户7月份之后的购买形成推荐,并评估结果。比如用户甲在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。
智能推荐算法平台已经将包含数据和完整使用链路的推荐召回案例内置于模板业务节点中。
在画布左上角的“商品推荐召回模型”,右键从模板创建。
会生成如下图所示的实验,先点击运行按钮执行实验。
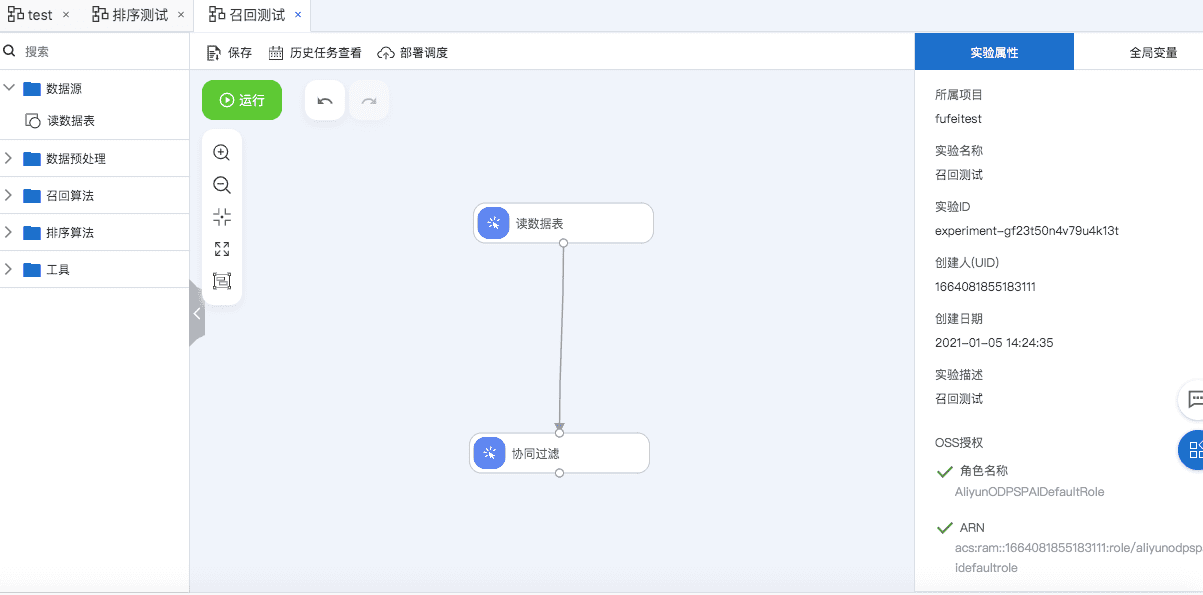
右键数据源,点击查看数据。
数据源:本数据源为天池大赛提供数据,数据按时间分为两份,分别是7月份之前的购买行为数据和7月份之后的。具体字段如下:
字段名 | 含义 | 类型 | 描述 |
user_id | 用户编号 | string | 购物的用户ID |
item_id | 物品编号 | string | 被购买物品的编号 |
active_type | 购物行为 | string | 0表示点击,1表示购买,2表示收藏,3表示购物车 |
active_date | 购物时间 | string | 购物发生的时间 |
数据截图: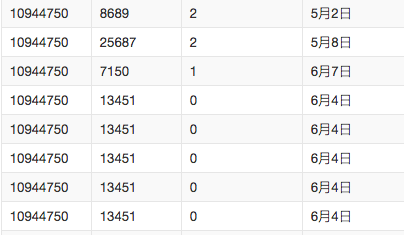
实验运行完成后,右键实验节点,点击查看召回数据表。
会自动跳往召回数据管理页面,该页面会自动遍历出当前节点运行过程中产出的召回数据表。
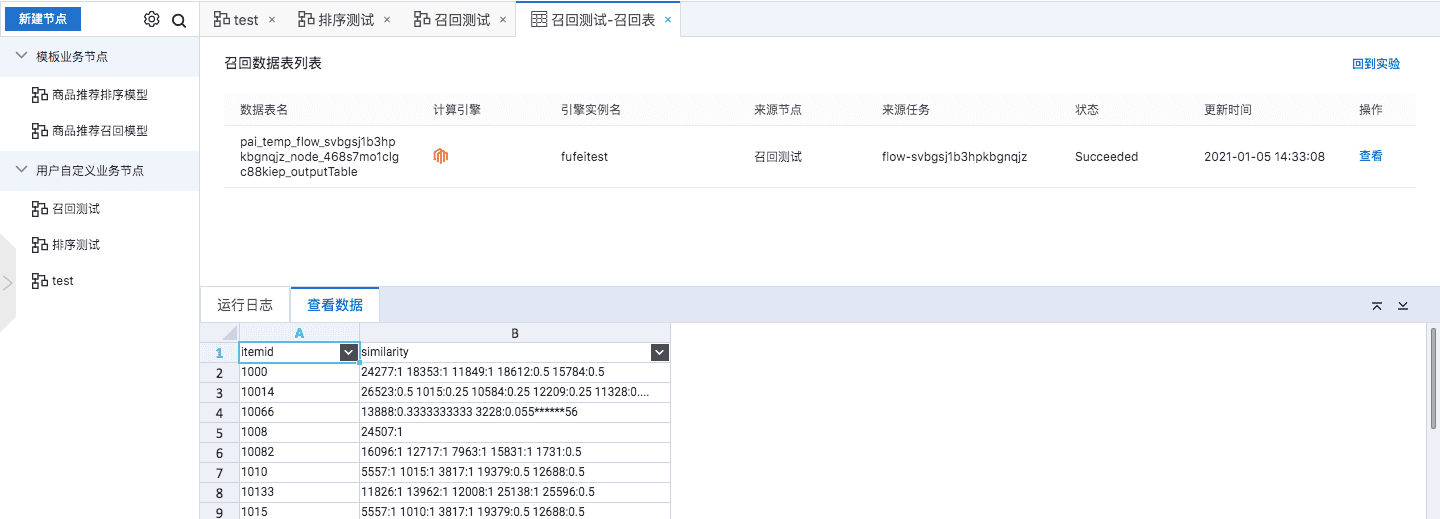
协同过滤结果,表示的是商品的关联性,itemid表示目标商品,similarity字段的冒号左侧表示与目标关联性高的商品,右边表示概率:
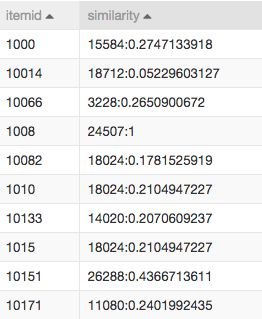
比如第一行,表示的是ID等于的1000这个商品和ID等于15584这个商品被同时购买的概率为0.2747133918。
召回结果表可以在智能推荐在线服务的实验中直接使用。
四、申请资源组
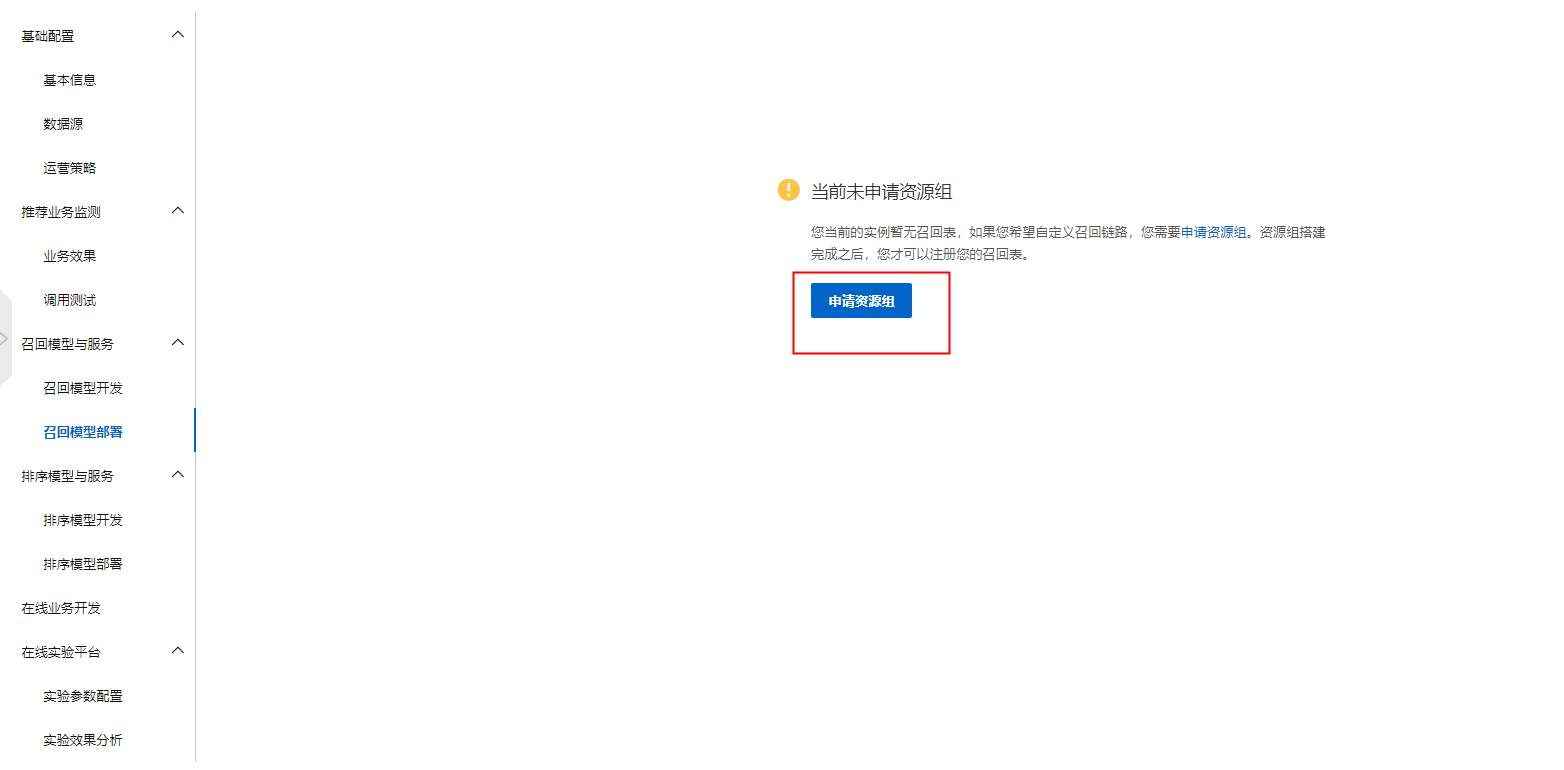
注意:一个实例最多20张表(包含未上线及运行中的表)。
申请之后建议在钉钉群联系技术支持人员,加快处理速度。
五、注册召回表
I 点击注册召回表
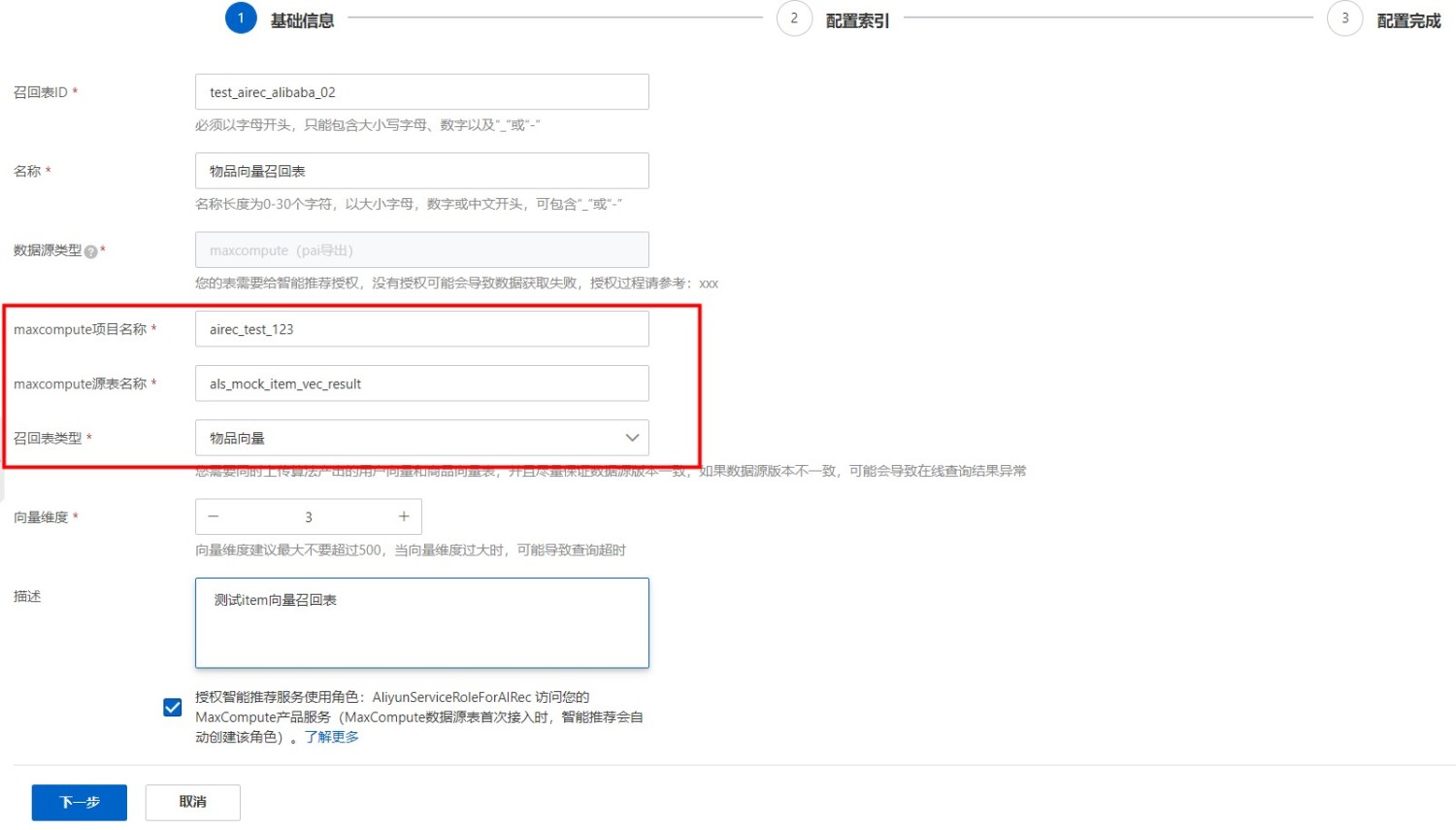
1、填入召回表基础信息
注意:
对应创建服务时配置文件中的model_config字段,表示自定义的模型配置信息。 网站初始阶段访问量小,只需要一台配置低的云服务器ECS实例即可运行Apache或Nginx等Web应用程序、数据库、存储文件等。随着网站的发展,您可以随时升级ECS实例的配置,或者增加ECS实例数量,无需担心低配计算单元在业务突增时带来的资源不足问题。 ①其中的MaxCompute项目名称及源表名称,需要按照事先在离线平台处创建出来的MaxCompute表进行填写。
②MaxCompute源表和召回表类型必须属于同一类型,如图:二者类型为物品向量源表及类型。
2、配置索引
选择全量更新周期、更新启动时间后完成配置。
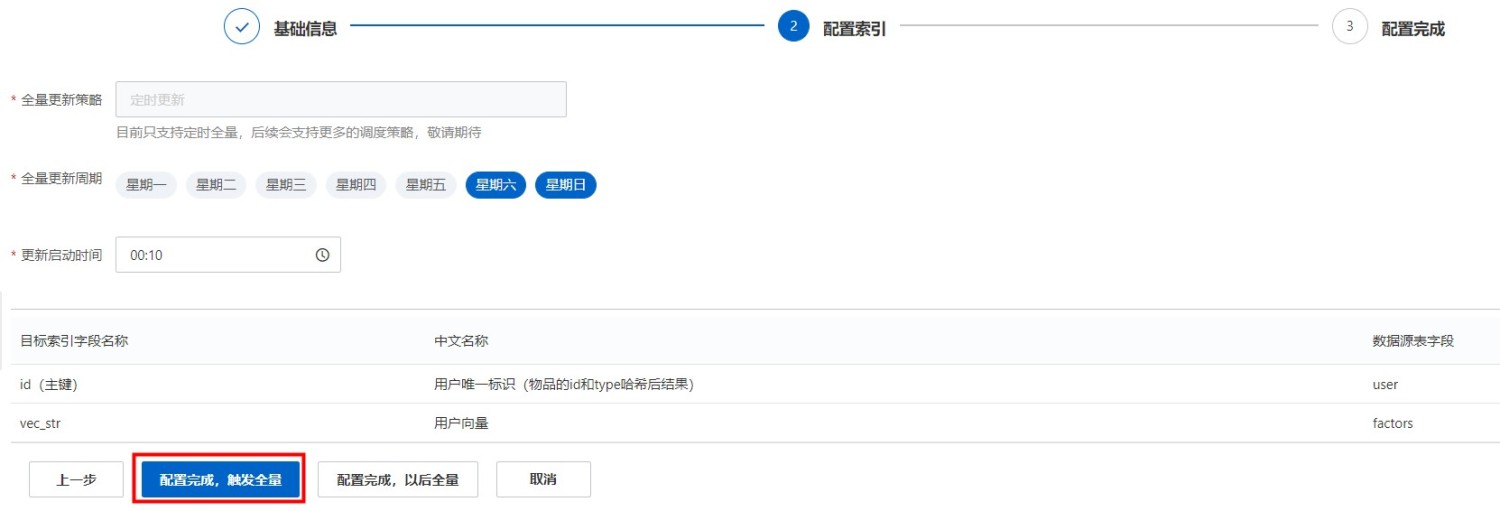
3、配置完成,触发全量
注:触发全量:开始同步MaxCompute相应表下的所有数据。
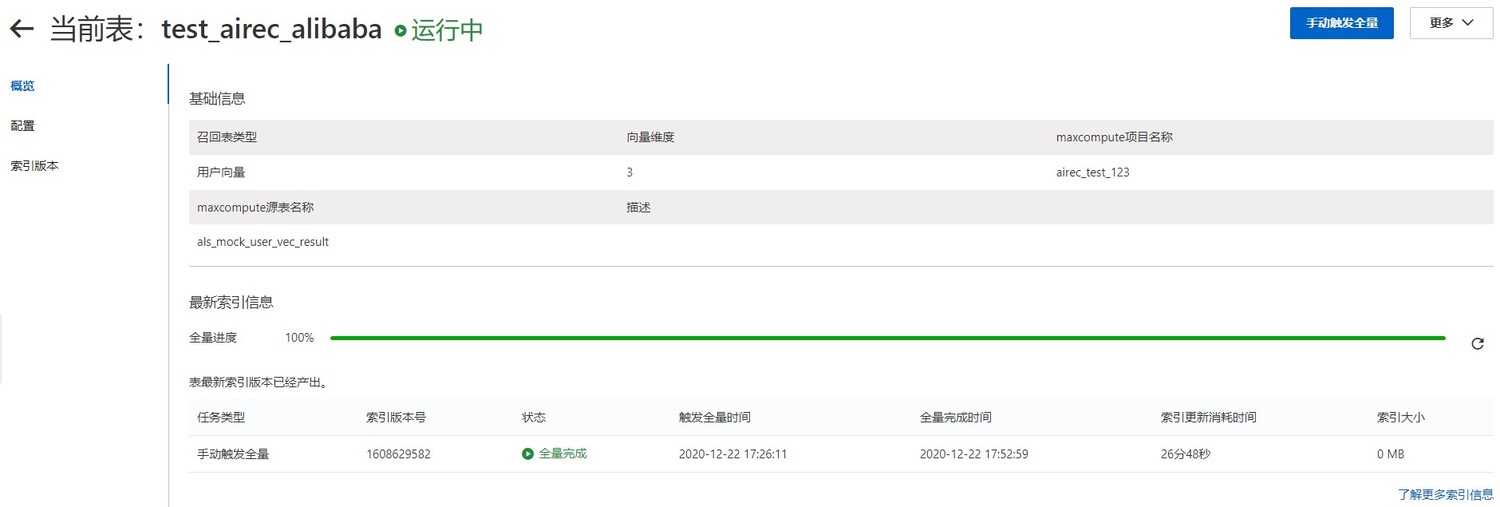
点击触发全量后即可开始执行全量任务。
创建执行成功的召回表可以在控制台的召回表管理页面查看。
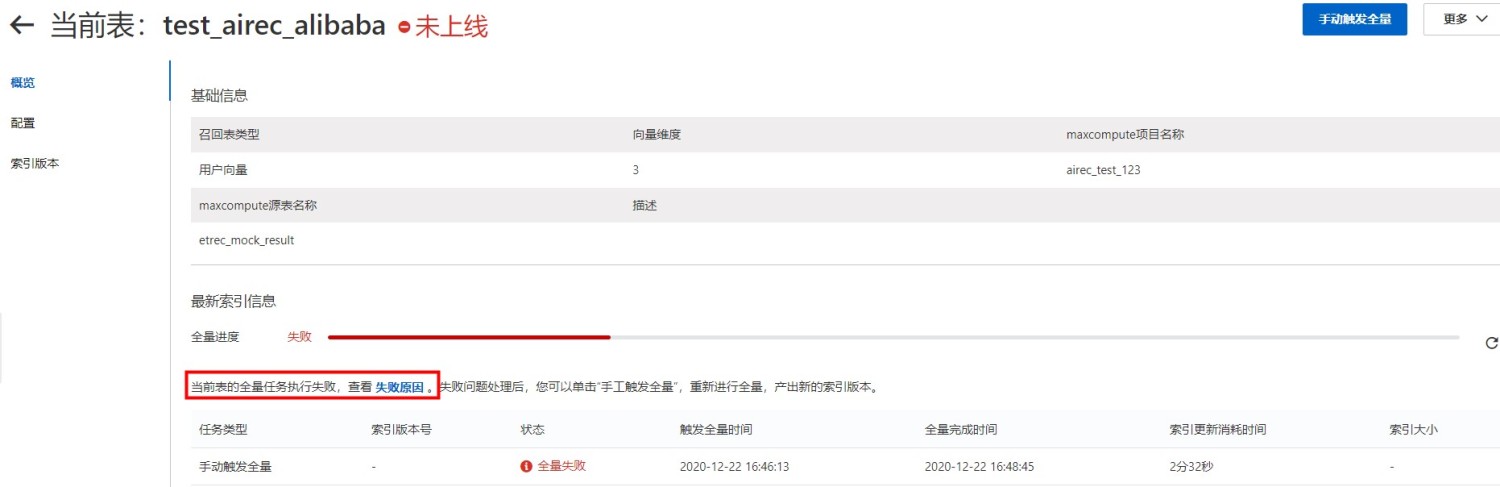
如果在注册召回表时提示“当前表的全量任务执行失败”,可以点击“失败原因”来查看失败原因。
六、应用自定义的召回模型
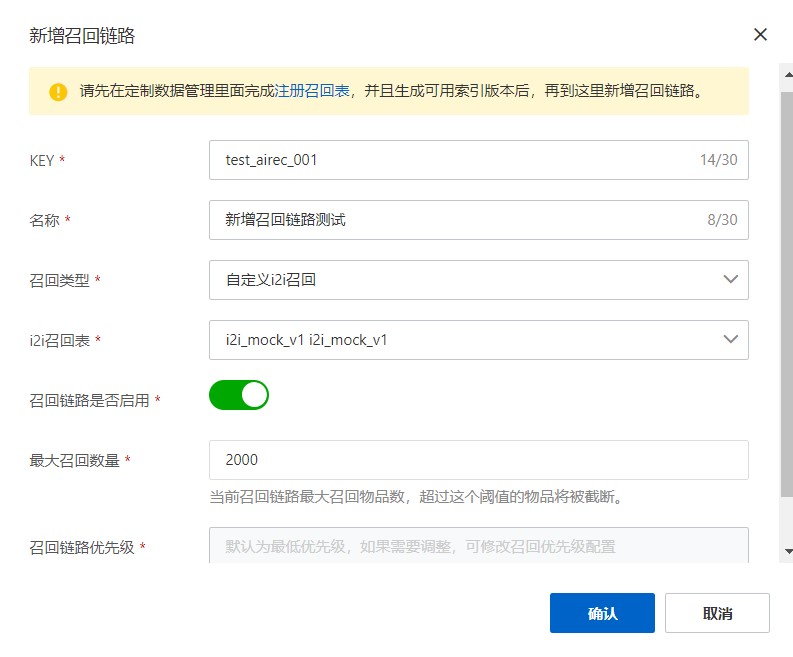
在控制台-场景管理-实验管理功能中进入实验详情,点击“新增召回链路”。
注意:请先在本实验上线之前,完成新增自定义召回,实验上线后再新增召回链路会对实验效果有直接的影响,请勿在开始做实验后修改实验算法策略。
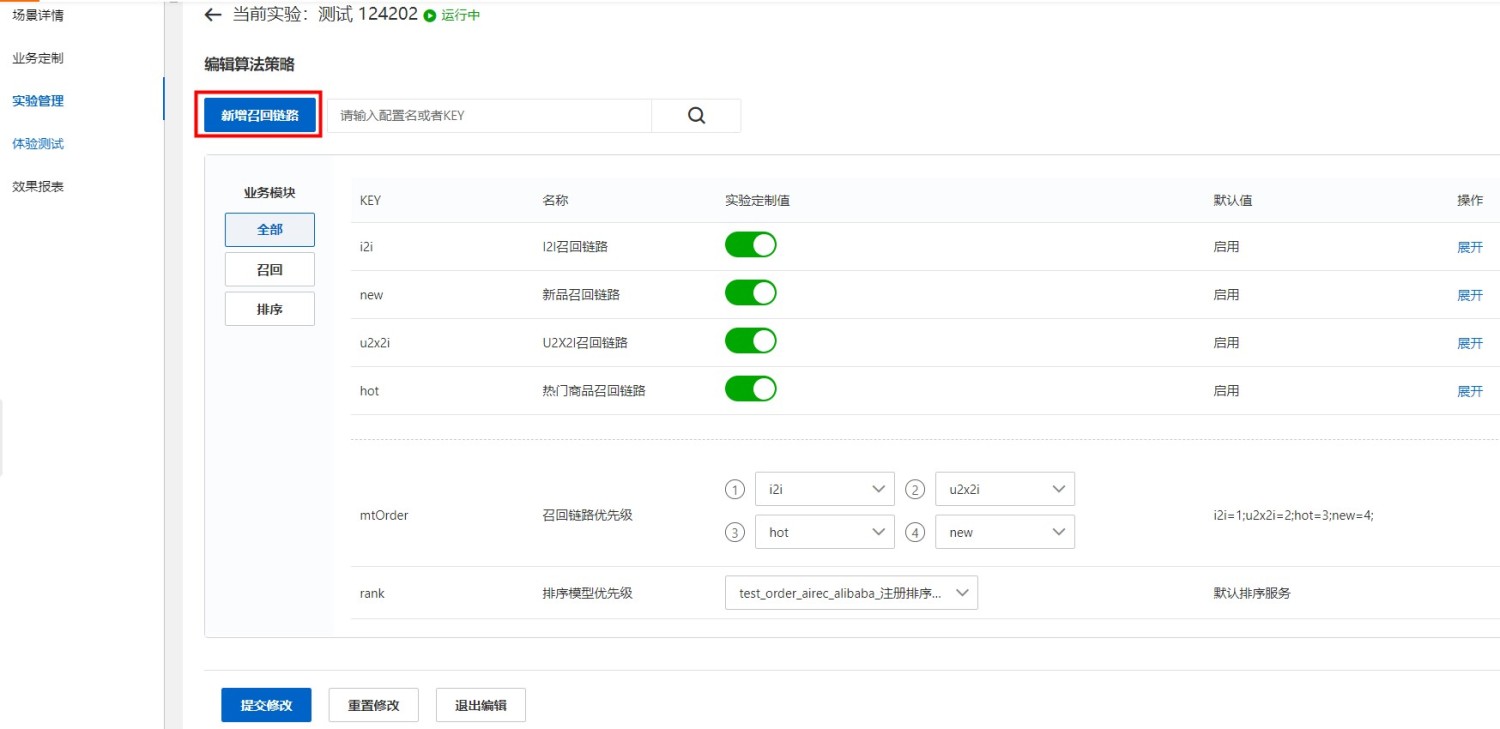
填入自定义召回链路的信息:
注:请先在定制数据管理里面完成注册召回表,并且生成可用索引版本后,再回到此处新增召回链路。
七、召回表决策
请根据实验效果的实际情况进行召回表决策。
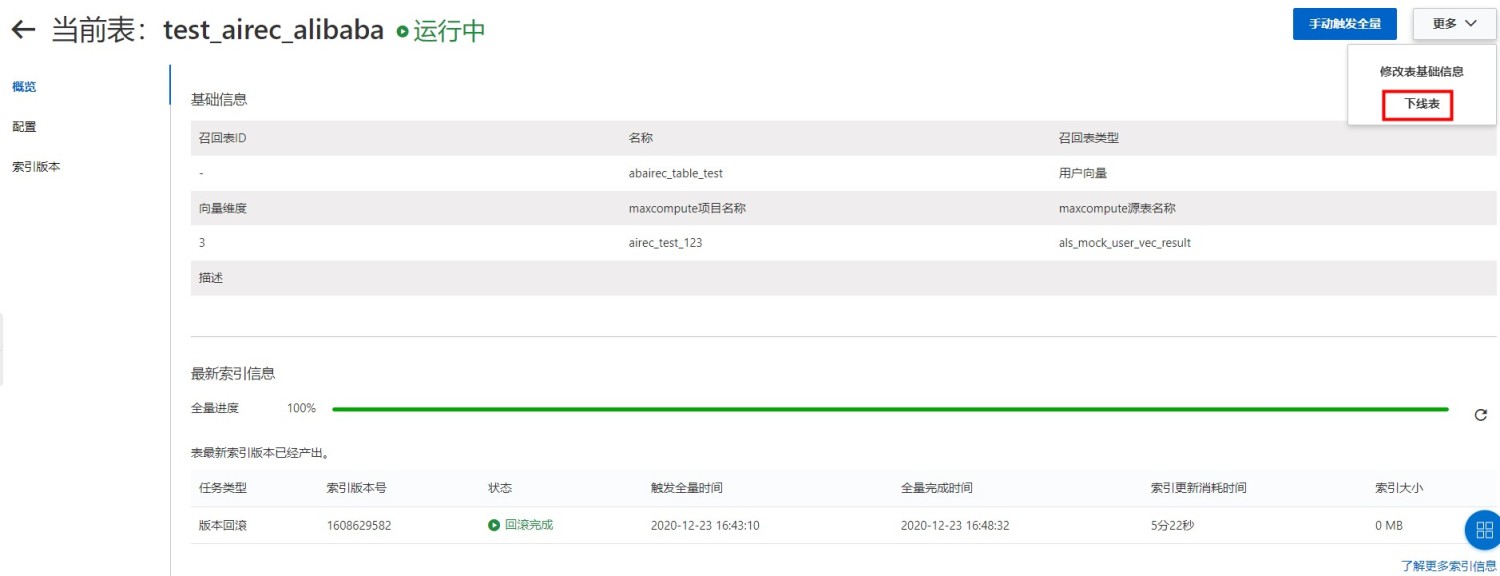
I 下线表
注意:您的表下线之后,索引将会被清理,且不可恢复, 请谨慎操作。
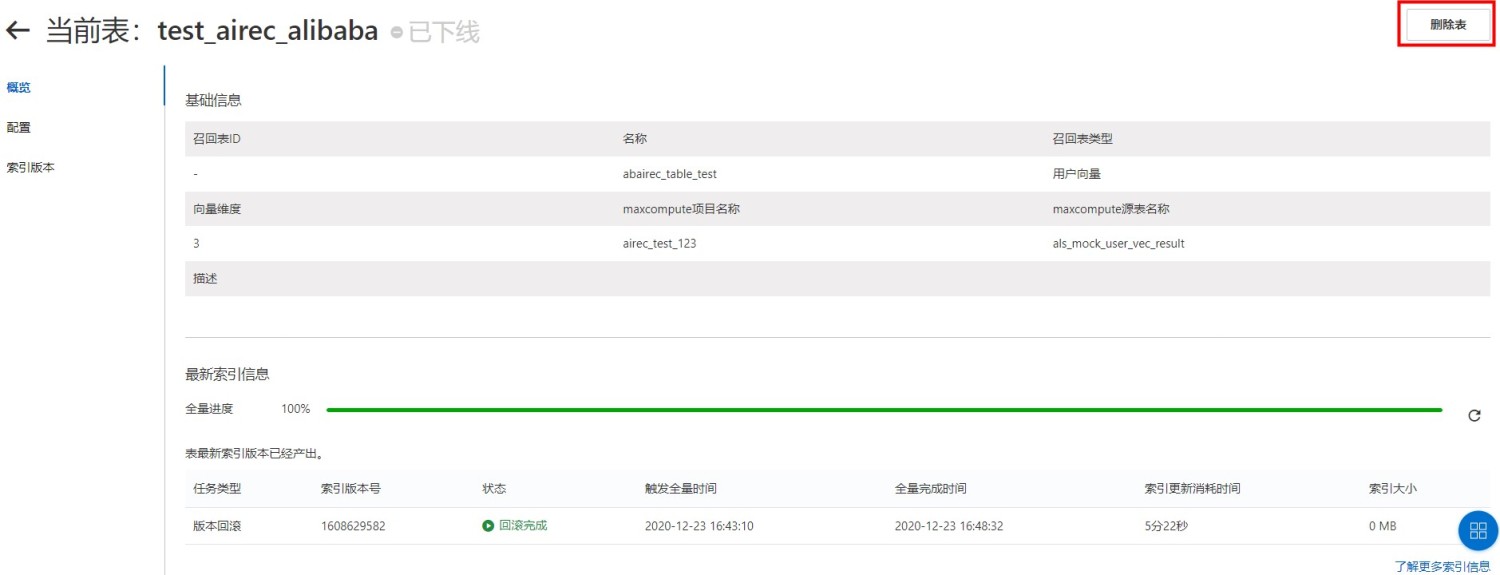
II 删除表
注意:表删除之后,不可恢复,请谨慎操作。
III 回滚索引
当您修改过召回表配置后,点击手动触发全量,即可生成新的索引版本。
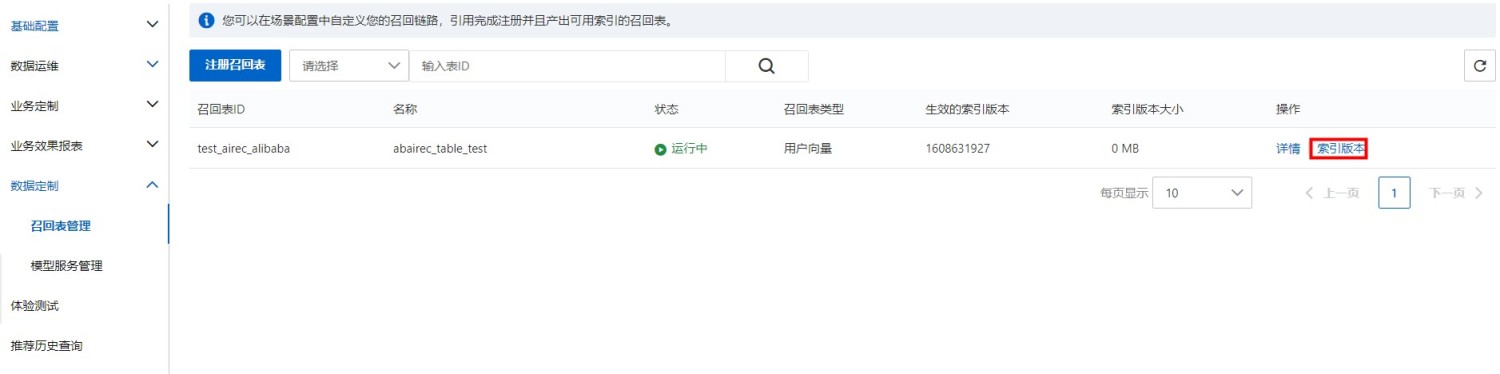

回滚操作执行后,召回表将处于回滚状态。为避免再次出现问题,在您解决问题之前,定时全量任务和手工触发全量均不会执行。
可以在当前召回表的概览页面查看回滚进度,回滚结束前定时全量任务和手工触发全量都不会执行。
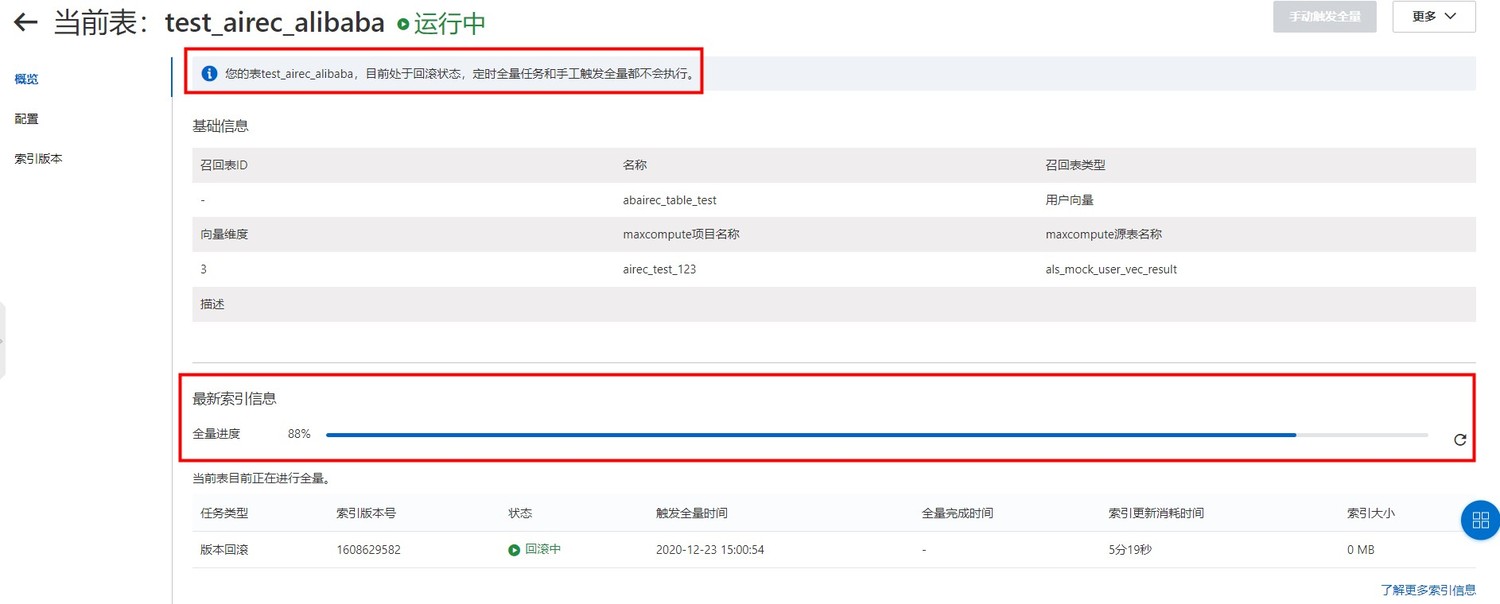
当您的问题解决后,您可以在本页面单击“解除回滚状态”,来解除回滚状态。
解除回滚状态后,定时全量任务和手工触发全量都会恢复正常。