召回配置项对应配置总览中的RecallConfs。
如何配置
PAI-Rec引擎已经内置了多个召回模板,包括协同过滤(UserCollaborativeFilterRecall),向量召回(HologresVectorRecall),U2I 召回(UserCustomRecall)等等,并且支持 Hologres、PAI-FeatureStore、TableStore(OTS)等多个数据源。
召回公共配置一览
每种召回配置,都会用到公共配置中的一部分,在此统一解释,单独的召回配置中则不再赘述。
配置示例:
"RecallConfs" :[
{
"Name": "collaborative_filter",
"RecallType": "UserCollaborativeFilterRecall",
"RecallCount": 1000,
"RecallAlgo":"",
"ItemType":"",
"CacheAdapter":"",
"CacheConfig":"",
"CachePrefix":"",
"CacheTime":0
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 召回的自定义名称,可以在SceneConfs中引用。 |
RecallType | string | 是 | 引擎内置召回类型,枚举值,目前支持:
|
RecallCount | string | 是 | 召回数量 |
RecallAlgo | string | 否 | 调用的向量模型名称,需要先在AlgoConfs里配置,只在实时向量召回中使用。 |
ItemType | string | 否 | 推荐物品类型。 |
CacheAdapter | string | 否 | 这里可以将召回的结果进行缓存,枚举值,目前支持Redis和localCache。 |
CacheConfig | string | 否 | 缓存的一些配置。 当使用Redis缓存时,参考配置:"{\"host\":\"xxx.redis.rds.aliyuncs.com\", \"port\":6379,\"maxIdle\":10, \"password\":\"xxxx\"}" 当使用localCache时,参考配置 "{\"defaultExpiration\":600, \"cleanupInterval\":600}"。 |
CachePrefix | string | 否 | 这里可以对当前召回结果的key加一个前缀。 当选择使用缓存时,为必填项。为了避免不同召回之间的缓存互相影响。如 "group_hot_",代表组热门召回的某个user的缓存结果。 |
CacheTime | string | 否 | 缓存时长,默认1800秒。 |
协同过滤(UserCollaborativeFilterRecall)
Hologres
协同过滤需要有两张表,一张u2i表,根据user_id获取item列表,一张i2i表,获取相似的item,这两张表的 schema是固定格式的。
除了通过 i2i 表获取相似的 item(下文称 u2i2i),还可以通过 i2x 和 x2i 两张表间接地获取相似 item(下文称 u2i2x2i),x 可以是类目、品牌、城市等属性,先获取 item 的属性x(如下文中的category字段),然后从x2i表中获取相应x取值下的热门物品作为推荐结果。 。
u2i 表
表字段 | 类型 | 描述 |
user_id | string | 用户id,保持其唯一性 |
item_ids | string | 用户浏览的item id列表,支持格式: item_id1,item_id2,item_id3..... 或者 item_id1:score1,item_id2:score,item_id3:score2...... |
i2i 表(仅 u2i2i 需要)
表字段 | 类型 | 描述 |
item_id | string | item id,保持其唯一性 |
similar_item_ids | string | 和item_id相似的item列表,支持格式:item_id1:score1,item_id2:score2,item_id3:score3...... |
i2x 表(仅 u2i2x2i 需要)
item_id | string | item id,保持其唯一性 |
x | string | item的属性,列名可以自定义,在引擎配置中指定实际列名。 |
x2i 表(仅 u2i2x2i 需要)
x | string | item的属性,列名可以自定义,在引擎配置中指定实际列名。 |
item_id | string | item id,多值用 ”,“分隔 |
u2i2i 配置示例:
"RecallConfs" :[
{
"Name": "collaborative_filter",
"RecallType": "UserCollaborativeFilterRecall",
"RecallCount": 1000,
"UserCollaborativeDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"User2ItemTable": "u2i_table",
"Item2ItemTable": "i2i_table",
"Normalization" : "on"
}
}
]u2i2x2i 配置示例:
"RecallConfs" :[
{
"Name": "collaborative_filter",
"RecallType": "UserCollaborativeFilterRecall",
"RecallCount": 1000,
"UserCollaborativeDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"User2ItemTable": "u2i_table",
"Item2XTable": "i2x_table",
"X2ItemTable": "x2i_table",
"XKey": "category",
"XDelimiter": ",",
"Normalization" : "on"
}
}
]UserCollaborativeDaoConfig:
字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 固定值 hologres |
HologresName | string | 是 | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info |
User2ItemTable | string | 是 | u2i表 |
Item2ItemTable | string | 否 | i2i表,使用 u2i2i 方式时必填 |
Item2XTable | string | 否 | i2x表,使用 u2i2x2i 方式时必填 |
X2ItemTable | string | 否 | x2i 表,使用 u2i2x2i 方式时必填 |
XKey | string | 否 | x 键,值为 i2x 表和 x2i 表 x 列名,使用 u2i2x2i 方式时必填 |
XDelimiter | string | 否 | x 值分隔符,默认不对 x 值分割 |
Normalization | string | 否 | 枚举值:on/off。是否对召回的item进行归一化,默认为"on" |
PAI-FeatureStore
协同过滤需要有两张表,一张u2i表,根据user_id获取item列表,一张i2i表,获取相似的item,这两张表的 schema是固定格式的。
两种表的数据是在MaxCompute里产生的。需要通过离线的FeatureView注册到 FeatureStore上。MaxCompute的表数据schema参考如下。
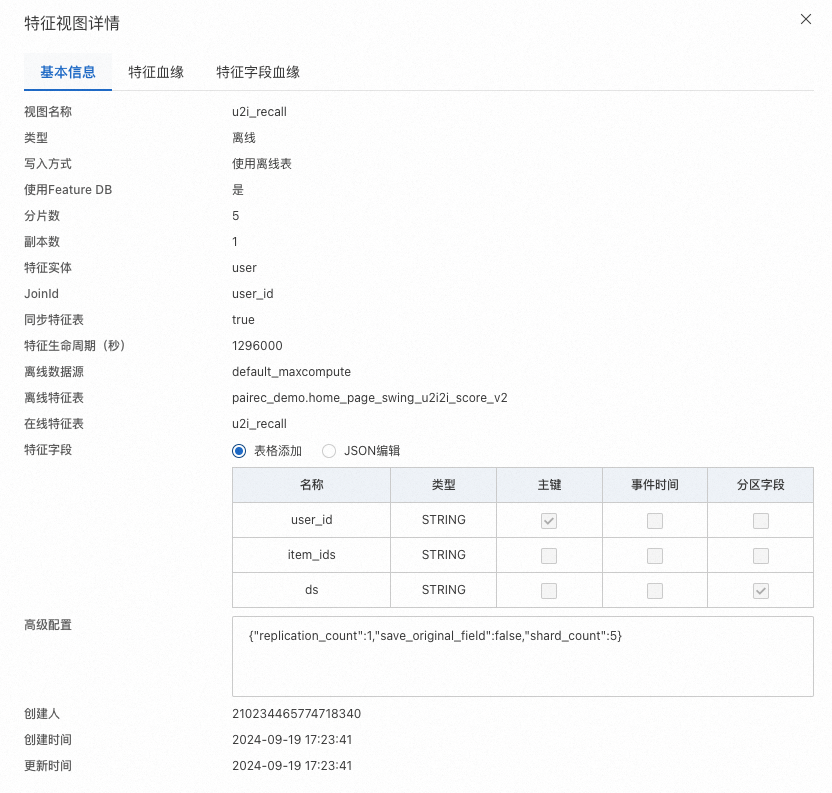
u2i 表
表字段 | 类型 | 描述 |
user_id | string | 用户id,保持其唯一性 |
item_ids | string | 用户浏览的item id列表,支持格式: item_id1,item_id2,item_id3..... 或者 item_id1:score1,item_id2:score,item_id3:score2...... |
ds | string | MaxCompute表分区字段 |
注册到FeatureStore 参考如下:
i2i 表
表字段 | 类型 | 描述 |
item_id | string | item id,保持其唯一性 |
similar_item_ids | string | 和item_id相似的item列表,支持格式:item_id1:score1,item_id2:score2,item_id3:score3...... |
dt | string | MaxCompute表分区字段 |
注册到FeatureStore 参考如下:

配置示例:
"RecallConfs" :[
{
"Name": "collaborative_filter",
"RecallType": "UserCollaborativeFilterRecall",
"RecallCount": 1000,
"UserCollaborativeDaoConf": {
"AdapterType": "featurestore",
"FeatureStoreName": "fs_pairec",
"User2ItemFeatureViewName": "u2i_recall",
"Item2ItemFeatureViewName": "i2i_collaborative"",
"Normalization": "on"
}
}
]UserCollaborativeDaoConfig:
字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 固定值 featurestore |
FeatureStoreName | string | 是 | 在数据源配置(FeatureStoreConfs)中配置好的featurestore的自定义名称,如数据源配置中的fs_pairec |
User2ItemFeatureViewName | string | 是 | u2i表对应的视图名称 |
Item2ItemFeatureViewName | string | 是 | i2i表对应的视图名称 |
Normalization | string | 否 | 枚举值:on/off。是否对召回的item进行归一化,默认为"on" |
TableStore(OTS)
协同过滤需要有两张表,一张u2i表,根据user_id获取item列表,一张i2i表,获取相似的item,这两张表的 schema是固定格式的。
u2i 表
表字段 | 类型 | 描述 |
user_id | string | 用户id,保持其唯一性 |
item_ids | string | 用户浏览的item id列表,支持格式: item_id1,item_id2,item_id3..... 或者 item_id1:score1,item_id2:score,item_id3:score2...... |
i2i 表
表字段 | 类型 | 描述 |
item_id | string | item id,保持其唯一性 |
similar_item_ids | string | 和item_id相似的item列表,支持格式:item_id1:score1,item_id2:score2,item_id3:score3...... |
"RecallConfs" :[
{
"Name": "collaborative_filter",
"RecallType": "UserCollaborativeFilterRecall",
"RecallCount": 1000,
"UserCollaborativeDaoConf": {
"AdapterType": "tablestore",
"TableStoreName": "tablestore_info",
"User2ItemTable": "u2i_table",
"Item2ItemTable": "i2i_table",
"Normalization" : "on"
}
}
]字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 固定值 tablestore |
TableStoreName | string | 是 | 在数据源配置(TableStoreConfs)中配置好的tablestore的自定义名称,如数据源配置中的tablestore_info |
User2ItemTable | string | 是 | u2i表 |
Item2ItemTable | string | 是 | i2i表 |
Normalization | string | 否 | 枚举值:on/off。是否对召回的item进行归一化,默认为"on" |
Redis
Redis进行collaborative_filter流程比较特殊,单独说明。 实际上也是分两步:
根据RedisPrefix + uid构造key , 查询U2I列表, 是个string, 支持格式: item_id1,item_id2,item_id3..... 或者 item_id1:score1,item_id2:score,item_id3:score2......
然后查询I2I列表, 根据上步查询到的多个item_id,使用MGET进行查询。 I2I的数据也是string , 格式如下:item_id1:score1,item_id2:score2,item_id3:score3......
配置示例:
"RecallConfs" :[
{
"Name": "collaborative_filter",
"RecallType": "UserCollaborativeFilterRecall",
"RecallCount": 1000,
"UserCollaborativeDaoConf": {
"AdapterType": "redis",
"RedisName": "redis_info",
"RedisPrefix": "cr_",
"Normalization" : "on"
}
}
]字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 固定值 redis |
RedisName | string | 是 | 在数据源配置(RedisConfs)中配置好的Redis的自定义名称,如数据源配置中的redis_info |
RedisPrefix | string | 否 | U2I数据的前缀,key通过RedisPrefix + uid进行构造 |
仅支持Redis进行缓存数据。
实时 U2I2I(RealTimeU2IRecall)
Hologres
获取数据的思路和协同过滤中的是一样的,只不过U2I的数据获取是通过user历史行为表实时计算的。
user历史行为表是根据实时日志来同步更新的,这样的召回是实时的召回。
和协同过滤一样,也支持 u2i2x2i,先获取 item 的 x 属性,再通过相同 x 属性的 item。
user历史行为表
字段 | 类型 | 描述 |
user_id | string | 用户id |
item_id | string | 用户浏览的item id |
event | string | 事件名称 |
play_time | float | 事件的耗时,比如视频观看的时长,不存在可以设置为0 |
timestamp | int | 事件发生的时间戳,单位为秒 |
i2i 表(仅 u2i2i 需要)
表字段 | 类型 | 描述 |
item_id | string | item id,保持其唯一性 |
similar_item_ids | string | 和item_id相似的item列表,支持格式:item_id1:score1,item_id2:score2,item_id3:score3...... |
i2x 表(仅 u2i2x2i 需要)
item_id | string | item id,保持其唯一性 |
x | string | item的属性,列名可以自定义,在引擎配置中指定实际列名。 |
x2i 表(仅 u2i2x2i 需要)
x | string | item的属性,列名可以自定义,在引擎配置中指定实际列名。 |
item_id | string | item id,多值用 ”,“分隔 |
行为表建表语句:
BEGIN;
CREATE TABLE "sv_rec"."user_behavior_seq" (
"user_id" text NOT NULL,
"item_id" text NOT NULL,
"event" text NOT NULL,
"play_time" float8 NULL,
"timestamp" int8 NOT NULL
);
CALL SET_TABLE_PROPERTY('"sv_rec"."user_behavior_seq"', 'orientation', 'column');
call set_table_property('table_name', 'distribution_key', '"user_id"');
CALL SET_TABLE_PROPERTY('"sv_rec"."user_behavior_seq"', 'clustering_key', '"user_id:asc","timestamp:desc"');
CALL SET_TABLE_PROPERTY('"sv_rec"."user_behavior_seq"', 'bitmap_columns', '"user_id","event"');
CALL SET_TABLE_PROPERTY('"sv_rec"."user_behavior_seq"', 'dictionary_encoding_columns', '"user_id:auto","item_id:auto","event"');
CALL SET_TABLE_PROPERTY('"sv_rec"."user_behavior_seq"', 'time_to_live_in_seconds', '2592000');
comment on table "sv_rec"."user_behavior_seq" is '用户实时行为序列';
comment on column "sv_rec"."user_behavior_seq"."user_id" is '用户id';
comment on column "sv_rec"."user_behavior_seq"."item_id" is 'item id';
comment on column "sv_rec"."user_behavior_seq"."event" is '事件类型';
comment on column "sv_rec"."user_behavior_seq"."play_time" is '阅读时长,播放时长';
comment on column "sv_rec"."user_behavior_seq"."timestamp" is '时间戳,单位秒';
COMMIT;配置示例:
"RecallConfs" :[
{
"Name": "RealTimeEtrecRecall",
"RecallType": "RealTimeU2IRecall",
"RecallCount": 200,
"RealTimeUser2ItemDaoConf": {
"UserTriggerDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "user_behavior_table",
"WhereClause": "event='xxx'",
"Limit": 200,
"EventPlayTime": "playback:5000;playvslide:5000",
"EventWeight": "playback:1;playvslide:2",
"WeightExpression": "(-0.2)*((currentTime-eventTime)/3600/24)",
"WeightMode": "sum",
"NoUsePlayTimeField": false
},
"Item2ItemTable": "i2i_table"
}
}
]u2i2x2i 配置示例:
"RecallConfs" :[
{
"Name": "RealTimeU2I2X2IRecall",
"RecallType": "RealTimeU2IRecall",
"RecallCount": 200,
"RealTimeUser2ItemDaoConf": {
"UserTriggerDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "user_behavior_table",
"WhereClause": "event='xxx'",
"Limit": 200,
"EventPlayTime": "playback:5000;playvslide:5000",
"EventWeight": "playback:1;playvslide:2",
"WeightExpression": "(-0.2)*((currentTime-eventTime)/3600/24)",
"WeightMode": "sum",
"NoUsePlayTimeField": false
},
"Item2XTable": "i2x_table",
"X2ItemTable": "x2i_table",
"XKey": "category",
"XDelimiter": ",",
}
}
]RealTimeUser2ItemDaoConf:
字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 固定值 hologres |
HologresName | string | 是 | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info |
HologresTableName | string | 是 | holo中user历史行为表的表名 |
WhereClause | string | 否 | 过滤条件,相当于sql中的where条件 |
Limit | int | 否 | 查询数量限制,相当于sql中的limit |
EventPlayTime | string | 否 | 事件播放时间的过滤。可以针对每个事件,进行过滤e_sv_func_svplayback:5000表示针对事件 e_sv_func_svplayback,play_time的值必须大于5000 , 不符合条件则被过滤掉。可以设置多个事件,以 ; 分隔 |
EventWeight | string | 否 | 事件的权重, 可以定义每个事件的权重, 不设置的话,默认值为1 |
WeightExpression | string | 否 | 权重表达式。 以时间衰减来计算事件的权重。currentTime代表当前的时间戳,eventTime代表行为表的里timestamp |
WeightMode | string | 否 | 计算trigger权重的方式,取值为sum或者max 。 默认是sum |
NoUsePlayTimeField | bool | 否 | 如果不使用play_time字段,可以设置为true |
Item2ItemTable | string | 否 | holo中的i2i表名称,使用 u2i2i 方式时必填 |
Item2XTable | string | 否 | i2x表名,使用 u2i2x2i 方式时必填 |
X2ItemTable | string | 否 | x2i 表名,使用 u2i2x2i 方式时必填 |
XKey | string | 否 | x 键,值为 i2x 表和 x2i 表 x 列名,使用 u2i2x2i 方式时必填 |
XDelimiter | string | 否 | x 值分隔符,默认不对 x 值分割 |
向量召回(HologresVectorRecall)
目前向量召回只能使用hologres数据源,向量数据都存在hologres表中
配置示例:
"RecallConfs" :[
{
"Name": "vector_recall",
"RecallType": "HologresVectorRecall",
"RecallCount": 100,
"VectorDaoConf" :{
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "user_embedding_table",
"KeyField": "user_id",
"EmbeddingField" :"emb"
},
"HologresVectorConf" :{
"VectorTable" :"item_embedding_table",
"VectorEmbeddingField" :"emb",
"VectorKeyField" :"item_id"
}
}
]VectorDaoConf:
字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 数据源的类型,取值hologres |
HologresName | string | 是 | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info |
HologresTableName | string | 是 | holo中对应的向量表名称 |
KeyField | string | 是 | 向量表中的主键字段 |
EmbeddingField | string | 是 | 向量表中存储向量的字段 |
HologresVectorConf:
字段 | 类型 | 是否必填 | 描述 |
VectorTable | string | 是 | holo中item向量表 |
VectorEmbeddingField | string | 是 | item向量表中的主键字段 |
VectorKeyField | string | 是 | item向量表中存储向量的字段 |
VectorDaoConf里记录的是user向量信息,表的定义如下
BEGIN;
CREATE TABLE "public"."graphsage_user_embedding" (
"user_id" text NOT NULL,
"emb" float4[] NOT NULL,
"dt" text,
PRIMARY KEY ("user_id")
);
CALL SET_TABLE_PROPERTY('"public"."graphsage_user_embedding"', 'orientation', 'row');
CALL SET_TABLE_PROPERTY('"public"."graphsage_user_embedding"', 'clustering_key', '"user_id:asc"');
CALL SET_TABLE_PROPERTY('"public"."graphsage_user_embedding"', 'time_to_live_in_seconds', '3153600000');
comment on column "public"."graphsage_user_embedding"."user_id" is '用户ID';
comment on column "public"."graphsage_user_embedding"."emb" is '用户特征向量';
comment on column "public"."graphsage_user_embedding"."dt" is '日期 yyyyMMdd';
COMMIT;HologresVectorConf记录的是item向量, 表定义如下
BEGIN;
CREATE TABLE "public"."graphsage_item_embedding" (
"item_id" text NOT NULL,
"emb" float4[] NOT NULL,
PRIMARY KEY ("item_id")
);
CALL SET_TABLE_PROPERTY('"public"."graphsage_item_embedding"', 'orientation', 'column');
CALL SET_TABLE_PROPERTY('"public"."graphsage_item_embedding"', 'bitmap_columns', '"item_id"');
CALL SET_TABLE_PROPERTY('"public"."graphsage_item_embedding"', 'time_to_live_in_seconds', '3153600000');
comment on column "public"."graphsage_item_embedding"."item_id" is '物品ID';
comment on column "public"."graphsage_item_embedding"."emb" is '物品特征向量';
COMMIT;实时向量召回(OnlineHologresVectorRecall)
实时向量召回和向量召回的实现方式是一致的,也是基于hologres的表数据,不同的是,user向量不是从表里获取的,而是实时通过模型获取到的,然后去item向量表查数据。实现思路基本上分为三步:
获取user相关特征,user特征可以从数据表里查询
调用向量模型,获取user向量。在我们的支持中,模型是部署在EAS上的
和向量召回一样,通过item向量表进行查询
配置示例:
"RecallConfs" :[
{
"Name": "online_vector_recall",
"RecallType": "OnlineHologresVectorRecall",
"RecallCount": 500,
"UserFeatureConfs": [
{
"FeatureDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"FeatureKey": "user:uid",
"UserFeatureKeyName": "userid",
"HologresTableName": "user_all_feature_table",
"UserSelectFields": "*",
"FeatureStore": "user"
},
"Features": []
}
],
"RecallAlgo": "sv_v2_mind",
"HologresVectorConf": {
"HologresName": "holo_info",
"VectorTable": "item_embedding_table",
"VectorEmbeddingField": "item_emb",
"VectorKeyField": "item_id"
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值OnlineHologresVectorRecall |
RecallCount | int | 是 | 召回数量 |
RecallAlgo | string | 是 | 调用的向量模型名称,需要在AlgoConfs里配置,具体配置参考算法配置。 |
UserFeatureConfs:
字段 | 类型 | 是否必填 | 描述 |
AdapterType | string | 是 | 数据源的类型,取值hologres |
HologresName | string | 是 | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info |
FeatureKey | string | 是 | 这里为引擎中user_id的来源,user:uid代表user中的uid特征 |
UserFeatureKeyName | string | 是 | user特征表中的主键字段 |
HologresTableName | string | 是 | user特征表 |
UserSelectFields | string | 是 | 要选择哪些特征,支持"*"的写法,也可以 "f1,f2...."逗号分隔的写法 |
FeatureStore | string | 是 | 在引擎中特征存储的位置,枚举值:user/item |
HologresVectorConf:
字段 | 类型 | 是否必填 | 描述 |
HologresName | string | 是 | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info |
VectorTable | string | 是 | holo中item向量表的表名 |
VectorEmbeddingField | string | 是 | item向量表中存储向量的字段 |
VectorKeyField | string | 是 | item向量表中的主键字段 |
模型sv_v2_mind在AlgoConfs里定义如下
{
"AlgoConfs": [
{
"Name": "sv_v2_mind",
"Type": "EAS",
"EasConf": {
"Processor": "EasyRec",
"Timeout": 100,
"ResponseFuncName": "easyrecUserEmbResponseFunc",
"Url": "http://xxx.vpc.cn-beijing.pai-eas.aliyuncs.com/api/predict/sv_v2_mind",
"Auth": "xxx"
}
}
]
}和排序模型的配置是一样的,不同点是ResponseFuncName需要固定为easyrecUserEmbResponseFunc
U2I召回
Hologres
根据user id来找到对应的item列表。这里的表定义是约定好的。
u2i 表
字段 | 类型 | 描述 |
user_id | string | 用户id |
item_ids | string | item id列表,支持格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
配置示例:
"RecallConfs" :[
{
"Name": "user2item_recall",
"RecallType": "UserCustomRecall",
"RecallCount": 500,
"DaoConf" :{
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "user_item_table"
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserCustomRecall |
RecallCount | int | 是 | 召回数量 |
DaoConf | json object | 是 | Dao定义 |
AdapterType | string | 是 | 数据源类型,取值hologres |
HologresName | string | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info | |
HologresTableName | string | 是 | 数据表名称 |
PAI-FeatureStore
根据user id来找到对应的item列表。这里的表定义是约定好的。
表的数据是在MaxCompute里产生的。需要通过离线的FeatureView注册到 FeatureStore上。MaxCompute的表数据schema参考如下。
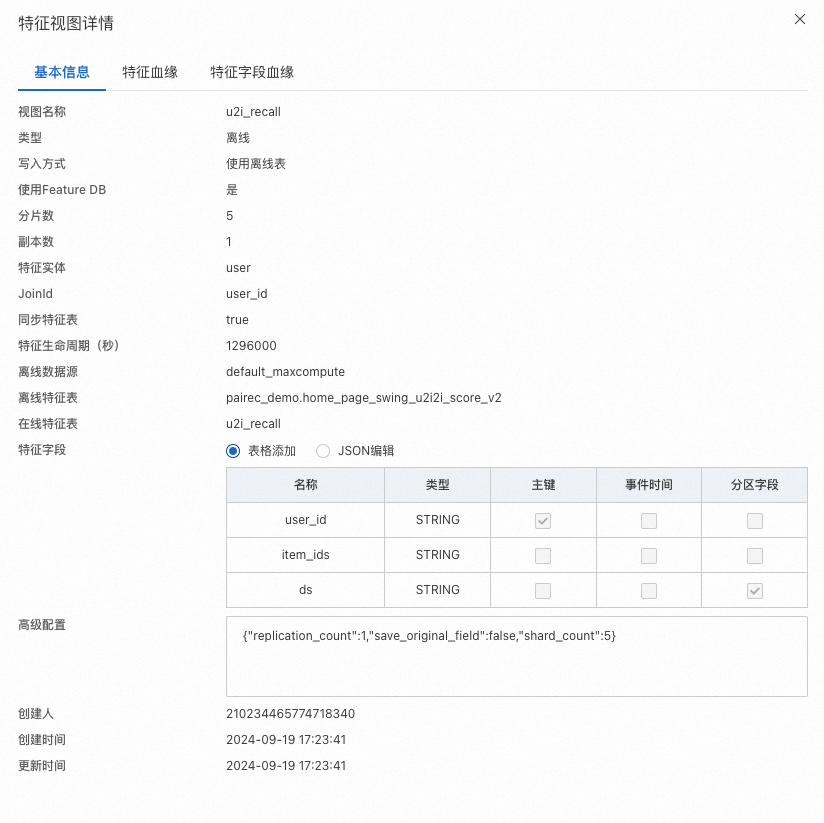
u2i 表
字段 | 类型 | 描述 |
user_id | string | 用户id |
item_ids | string | item id列表,支持格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
ds | string | MaxCompute表分区字段,名称自定义 |
注册到FeatureStore参考如下:
配置示例:
"RecallConfs" :[
{
"Name": "user2item_recall",
"RecallType": "UserCustomRecall",
"RecallCount": 500,
"DaoConf" :{
"AdapterType": "featurestore",
"FeatureStoreName": "fs_pairec",
"FeatureStoreViewName": "u2i_recall"
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserCustomRecall |
RecallCount | int | 是 | 召回数量 |
DaoConf | json object | 是 | Dao定义 |
AdapterType | string | 是 | 数据源类型,取值featurestore |
FeatureStoreName | string | 在数据源配置(FeatureStoreConfs)中配置好的holo的自定义名称,如数据源配置中的fs_pairec | |
FeatureStoreViewName | string | 是 | u2i表注册的视图名称 |
TableStore(OTS)
根据user id来找到对应的item列表。这里的表定义是约定好的。
u2i 表
字段 | 类型 | 描述 |
user_id | string | 用户id |
item_ids | string | item id列表,支持格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
配置示例:
"RecallConfs" :[
{
"Name": "user2item_recall",
"RecallType": "UserCustomRecall",
"RecallCount": 500,
"DaoConf" :{
"AdapterType": "tablestore",
"TableStoreName": "ots_info",
"TableStoreTableName": "user_item_table"
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserCustomRecall |
RecallCount | int | 是 | 召回数量 |
DaoConf | json object | 是 | Dao定义 |
AdapterType | string | 是 | 数据源类型,取值tablestore |
TableStoreName | string | 在数据源配置(TableStoreConfs)中配置好的 tablestore的自定义名称,如数据源配置中的tablestore_info | |
TableStoreTableName | string | 是 | 数据表名称 |
Redis
配置示例:
"RecallConfs" :[
{
"Name": "user2item_recall",
"RecallType": "UserCustomRecall",
"RecallCount": 500,
"DaoConf" :{
"AdapterType": "redis",
"RedisName": "redis_info",
"RedisPrefix": ""
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserCustomRecall |
RecallCount | int | 是 | 召回数量 |
DaoConf | json object | 是 | Dao定义 |
AdapterType | string | 是 | 数据源类型,取值redis |
RedisName | string | 在数据源配置(RedisConfs)中配置好的Redis的自定义名称,如数据源配置中的redis_info | |
RedisPrefix | string | 是 | U2I数据的前缀,通过RedisPrefix + uid构造key获取, value 的格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
图召回(GraphRecall)
图召回也属于U2I召回的一种。通过GraphCompute图数据库进行召回。GraphCompute文档参考概览。
配置示例:
"RecallConfs" :[
{
"Name": "graph_recall",
"RecallType": "GraphRecall",
"RecallCount": 500,
"GraphConf": {
"GraphName": "graph_test",
"ItemId": "item_id",
"QueryString": "g(\"test\").V(\"$1\").hasLabel(\"user\").outE().inV()",
"Params": ["user.uid"]
}
}
]GraphConf:
字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值GraphRecall |
RecallCount | int | 是 | 召回数量 |
GraphName | string | 是 | 在数据源配置(GraphConfs)中配置好的graph的自定义名称,如数据源配置中的graph_info |
ItemId | string | 是 | graph返回结果中,item的主键字段 |
QueryString | string | 是 | 图召回的查询语句,其中$1为占位符,需要从Params里面取,详细语法可以参考Gremlin查询语法。 |
Params | string | 是 | 填充参数的来源。具体格式如:
|
用户分组热门召回(UserGroupHotRecall)
Hologres
分组热门召回的表的格式也是约定好的。
group_hot_table
表字段 | 类型 | 描述 |
trigger_id | string | trigger信息,多个特征组装 |
item_ids | string | item id 列表,支持格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
按照用户特征和context信息(例如地域、机型等)组装trigger_id
按照顺序将特征用下划线(_)拼接为trigger_id
特征值为空对应 "NULL"
包含 Boundaries 字段的特征需要进行离散化(左开,右闭区间),比如年龄 [20, 30, 40, 50] --> trigger对应 <=20, 20-30, 30-40,40-50, >50
用户年龄23,对应"20-30"
用户年龄空,对应"NULL"
用户年龄60,对应">50"
用户年龄19,对应"<=20"
hologres表示例:
此处使用性别、年龄、机型三个特征
trigger_id | item_ids |
Male_<=20_IOS | item_id1::score1,item_id2::score2....... |
Famale_20-30_Android | item_id4::score4,item_id5::score5....... |
...... | ....... |
配置示例:
"RecallConfs" :[
{
"Name":"user_group_hot_recall",
"RecallType": "UserGroupHotRecall",
"RecallCount" :500,
"Triggers": [
{
"TriggerKey": "gender"
},
{
"TriggerKey": "age",
"Boundaries": [20,30,40,50]
},
{
"TriggerKey": "os"
}
],
"DaoConf":{
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "group_hotness_table"
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserGroupHotRecall |
RecallCount | int | 是 | 召回数量 |
Triggers | json array | 是 | 构造trigger_id的具体信息 |
| string | 是 | 从user的特征里获取trigger值 |
| json int array | 否 | 字段的边界值范围 |
DaoConf | json object | 是 | Dao定义 |
| string | 是 | 数据源类型,取值hologres |
| string | 在数据源配置(HologresConfs)中配置好的holo 的自定义名称,如数据源配置中的holo_info | |
| string | 是 | 数据表名称 |
PAI-FeatureStore
分组热门召回的表的格式也是约定好的。
表的数据是在MaxCompute里产生的。需要通过离线的FeatureView注册到 FeatureStore上。MaxCompute的表数据schema参考如下。
group_hot_table
表字段 | 类型 | 描述 |
trigger_id | string | trigger信息,多个特征组装 |
item_ids | string | item id 列表,支持格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
ds | string | MaxCompute表的分区字段,可以自定义 |
按照用户特征和context信息(例如地域、机型等)组装trigger_id
按照顺序将特征用下划线(_)拼接为trigger_id
特征值为空对应 "NULL"
包含 Boundaries 字段的特征需要进行离散化(左开,右闭区间),比如年龄 [20, 30, 40, 50] --> trigger对应 <=20, 20-30, 30-40,40-50, >50
用户年龄23,对应"20-30"
用户年龄空,对应"NULL"
用户年龄60,对应">50"
用户年龄19,对应"<=20"
表示例:
此处使用性别、年龄、机型三个特征
trigger_id | item_ids |
Male_<=20_IOS | item_id1::score1,item_id2::score2....... |
Famale_20-30_Android | item_id4::score4,item_id5::score5....... |
...... | ....... |
注册到FeatureStore参考如下:

这里使用了 trigger 特征实体。
配置示例:
"RecallConfs" :[
{
"Name":"user_group_hot_recall",
"RecallType": "UserGroupHotRecall",
"RecallCount" :500,
"Triggers": [
{
"TriggerKey": "gender"
},
{
"TriggerKey": "age",
"Boundaries": [20,30,40,50]
},
{
"TriggerKey": "os"
}
],
"DaoConf":{
"AdapterType": "featurestore",
"FeatureStoreName": "fs_pairec",
"FeatureStoreViewName": "group_hot_recall""
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserGroupHotRecall |
RecallCount | int | 是 | 召回数量 |
Triggers | json array | 是 | 构造trigger_id的具体信息 |
| string | 是 | 从user的特征里获取trigger值 |
| json int array | 否 | 字段的边界值范围 |
DaoConf | json object | 是 | Dao定义 |
| string | 是 | 数据源类型,取值featurestore |
| string | 在数据源配置(FeatureStoreConfs)中配置好的holo 的自定义名称,如数据源配置中的fs_pairec | |
| string | 是 | 热门召回表对应的视图名称 |
全局热门召回(UserGlobalHotRecall)
Hologres
全局热门召回的表schema和分组召回的表schema是相同的,只是全局热门召回表中只有一条数据,而且 trigger_id = -1 。
配置示例:
"RecallConfs" :[
{
"Name":"UserGlobalHotRecall",
"RecallType": "UserGlobalHotRecall",
"RecallCount" :500,
"DaoConf":{
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "global_hotness_table"
}
}
]PAI-FeatureStore
全局热门召回的表schema和分组召回的表schema是相同的,只是全局热门召回表中只有一条数据,而且 trigger_id = -1 。
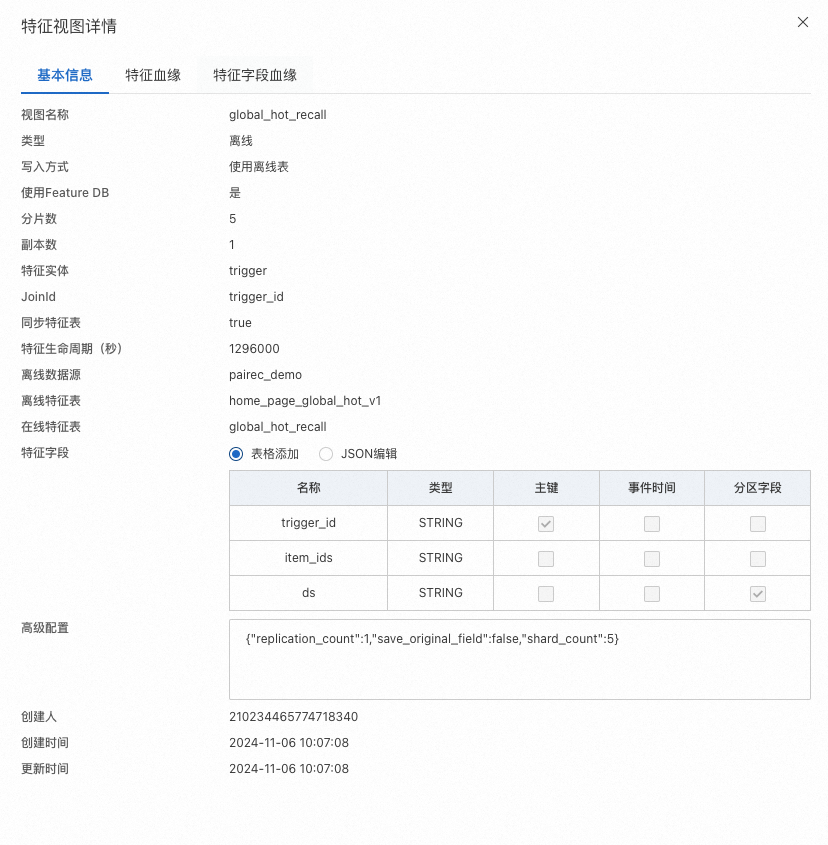
表的数据是在MaxCompute里产生的。需要通过离线的FeatureView注册到 FeatureStore上。MaxCompute的表数据schema参考如下。
表字段 | 类型 | 描述 |
trigger_id | string | 表里只有一行数据,值为 -1 。 |
item_ids | string | item id 列表,支持格式:item_id1,item_id2,item_id3..... 或 item_id1:recall_id1,item_id2:recall_id2..... 或 item_id1:recall_id1:score1,item_id2:recall_id2:score2..... |
ds | string | MaxCompute表的分区字段,可以自定义 |
注册到FeatureStore参考如下:
配置示例:
"RecallConfs" :[
{
"Name":"UserGlobalHotRecall",
"RecallType": "UserGlobalHotRecall",
"RecallCount" :500,
"DaoConf":{
"AdapterType": "featurestore",
"FeatureStoreName": "fs_pairec",
"FeatureStoreViewName": "global_hot_recall""
}
}
]TableStore(OTS)
全局热门召回的表schema和分组召回的表schema是相同的,只是全局热门召回表中只有一条数据,而且 trigger_id = -1。
配置示例:
"RecallConfs" :[
{
"Name":"UserGlobalHotRecall",
"RecallType": "UserGlobalHotRecall",
"RecallCount" :500,
"DaoConf":{
"AdapterType": "tablestore",
"TableStoreName": "ots_info",
"TableStoreTableName": "global_hotness_recall"
}
}
]字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值UserGlobalHotRecall |
RecallCount | int | 是 | 召回数量 |
DaoConf | json object | 是 | Dao定义 |
AdapterType | string | 是 | 数据源类型,取值tablestore |
TableStoreName | string | 在数据源配置(TableStoreConfs)中配置好的 tablestore的自定义名称,如数据源配置中的tablestore_info | |
TableStoreTableName | string | 是 | 数据表名称 |
冷启动召回(ColdStartRecall)
查询item表,根据条件或者时间进行过滤,查询出符合规则的候选集
hologres
"RecallConfs" :[
{
"Name": "AllLiveItemRecall",
"RecallType": "ColdStartRecall",
"RecallCount": 3000,
"ColdStartDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "item_status_table",
"WhereClause": "islist_status=1",
"PrimaryKey": "\"item_id\"",
"TimeInterval": 0
}
}
]ColdStartDaoConf:
字段 | 类型 | 是否必填 | 描述 |
Name | string | 是 | 自定义召回名称 |
RecallType | string | 是 | 召回类型,固定值ColdStartRecall |
RecallCount | int | 是 | 召回数量 |
ColdStartDaoConf | json object | 是 | 冷启动数据定义 |
AdapterType | string | 是 | 数据源的类型,取值hologres等 |
HologresName | string | 是 | 在数据源配置(HologresConfs)中配置好的holo的自定义名称,如数据源配置中的holo_info |
HologresTableName | string | 是 | holo中的冷启动召回表的表名 |
WhereClause | string | 否 | 过滤条件, 如果需要时间过滤,使用${time}。 比如根据创建时间, create_time > ${time} |
PrimaryKey | string | 是 | 表的主键 |
TimeInterval | int | 否 | 根据时间差,计算${time}时间值。 ${time} = 当前时间- TimeInterval |
上下文召回(ContextItemRecall)
有时候会把召回的条目通过引擎接口传递过来。引擎接口参考接口测试。通过 item_list 来传递自定义召回的数据。
ContextItemRecall 是引擎内置的召回名称。可以直接在RecallNames中使用。参考如下:
"SceneConfs": {
"scene_name": {
"default": {
"RecallNames": [
"ContextItemRecall"
]
}
}
}如何使用
召回的使用位置对应配置总览中的SceneConfs,SceneConfs是一个Map[string]object结构,可以分场景的使用召回,配置如下
"SceneConfs": {
"scene_name": {
"default": {
"RecallNames": [
"collaborative_filter"
]
}
}
}scene_name需要替换为自己的场景名。
default为目录,这里保持默认即可。
RecallNames是一个[]string,值为召回配置中的自定义名称。