
若您已部署一套包含召回、过滤、精排及重排的成熟推荐系统,在引入 PAI-Rec 时,完整的在PAI-Rec上复现所有逻辑会有较大的工作量,因此我们建议您先替换原有系统的精排和重排模块,同时复用已有的召回结果。待 PAI-Rec 的精排模型在实验中取得显著效果后,再逐步将召回策略迁移至 PAI-Rec 引擎。
架构图
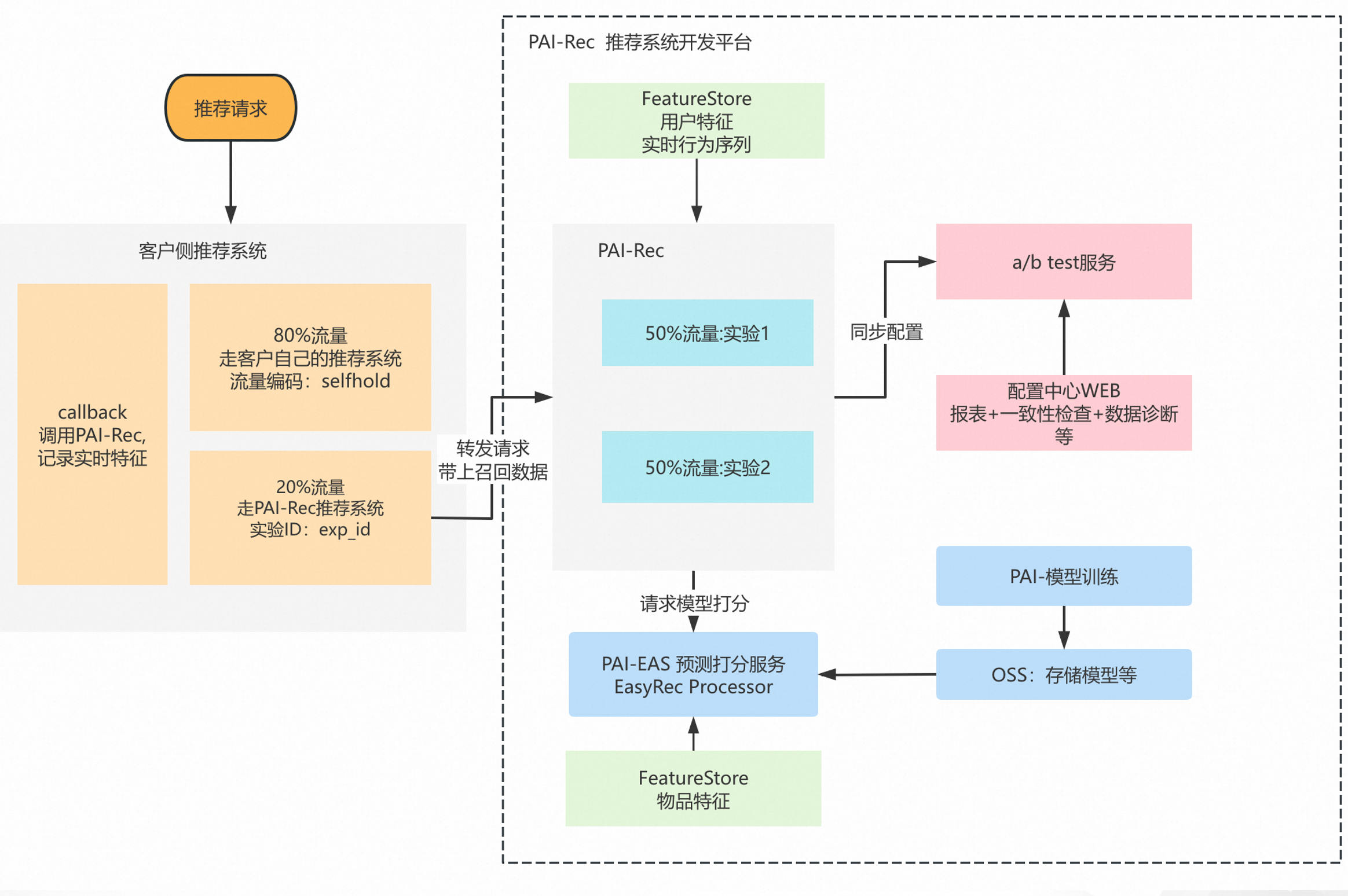
架构的核心是将您系统中的召回结果作为输入,交由PAI-Rec进行精排,再返回给您原有的系统。
召回与过滤:原有系统完成召回与过滤处理,生成待排序的物品列表。
流量切分与API调用:通过用户ID等方式切分部分流量,调用PAI-Rec推荐引擎接口。在调用时,将待排序的物品列表通过
item_list参数传入。PAI-Rec精排处理:PAI-Rec接收到请求后,将
item_list作为一路召回源。随后,引擎获取用户与物品特征,利用已部署的精排模型进行打分排序,并可执行重排等后续操作。结果返回与日志记录:PAI-Rec返回排序后的物品列表以及本次推荐的实验ID(
exp_id)。您的客户端需记录exp_id与request_id,用于后续的效果分析和实验评估。
PAI-Rec侧配置
基于PAI-Rec的推荐方案(使用PAI-FeatureStore来管理特征),配置特征工程、精排模型,然后生成代码,部署到DataWorks中。
模型打分服务:分为TensorFlow和PyTorch版本,请分别参考EasyRec Processor和 TorchEasyRec Processor。
PAI-Rec引擎内部:
通过FeatureStore获取用户特征,详情请参见PAI-FeatureStore。
引擎配置单中配置上下文召回(ContextItemRecall)。配置上下文召回之后,推荐引擎才会把接口传入的item_list作为一路召回。
{ "SceneConfs": { "${scene_name}": { "default": { "RecallNames": [ "ContextItemRecall" ] } } } }在PAI-Rec引擎配置单中设置调用精排模型,详情请参见精排配置。
通过A/B服务管理内部的A/B实验,可按照用户ID分桶,设置多个排序模型。
用户侧工作
用户侧推荐系统保留原有的召回、过滤和曝光等操作,并将召回结构、用户ID、用户特征和过滤规则等传给PAI-Rec做排序打分、重排等逻辑。此外,为配合PAI-Rec的集成,原有系统需要进行如下少量改造:
接口调用:改造推荐请求逻辑,调用PAI-Rec引擎接口,并在
item_list参数中传入召回和过滤后的物品ID列表。日志埋点:在曝光和行为日志中,记录从PAI-Rec接口返回的
request_id和exp_id字段,这是进行实验效果归因和数据诊断的关键。