
仓内智能(公测)
通过AnalyticDB PostgreSQL版的PG_CATALOG.AI_GENERATE_TEXT(...)函数与部署在阿里云PAI模型在线服务(EAS)平台中的LLM(大语言模型)服务进行交互,实现对语言的推理、分类、归纳、总结等。
背景信息
AIGC(Artificial Intelligence Generative Content)是一种新的人工智能技术,即人工智能生成内容。它基于机器学习和自然语言处理的技术,能够自动产生文本、图像、音频等多种类型的内容。
AnalyticDB PostgreSQL版作为数据分析与轻量级AI一体化的平台,可以帮助绝大多数中小型用户在数据库内部,闭环实现数据分析为主与AI应用为辅的诉求,为数据分析插上AI的翅膀。
AnalyticDB PostgreSQL版的AIGC仓内智能,提供人工智能文本生成(AI Text Generation)服务。使用LLM服务来生成(或推理)在风格、语气和内容上与输入数据相似的新文本。
前提条件
AnalyticDB PostgreSQL版实例的内核版本需满足以下条件。如何查看实例内核版本,请参见查看内核小版本。
存储弹性模式6.0版实例,内核版本需为v6.6.1.0及以上。
存储弹性模式7.0版实例,内核版本需为v7.0.4.0及以上。
Serverless模式实例,内核版本需为cn.v2.1.1.5 及以上。
已开通与AnalyticDB PostgreSQL版实例同地域的PAI模型在线服务(EAS),且至少部署了一款LLM服务(如:通义千问大模型、ChatGLM、Llama2等)。本文以部署通义千问大模型为例。具体操作,请参见5分钟操作EAS一键部署通义千问模型。
说明对中文文本进行推理、归纳、总结等操作时,建议首选通义千问模型。经与其他模型测试对比,通义千问模型在处理数据的响应时间、生成推理内容的准确度等方面,均有不俗的表现。
部署ChatGLM大语言模型的操作,请参见5分钟使用EAS一键部署ChatGLM及LangChain应用。
部署Llama2大语言模型的操作,请参见Llama2-WebUI基于EAS的一键部署。
PG_CATALOG.AI_GENERATE_TEXT(...)函数介绍
语法
FUNCTION PG_CATALOG.AI_GENERATE_TEXT
(input_endpoint text,
input_token text,
input_prompt text,
input_additional_parms text)
RETURNS TEXT
......参数
参数 | 是否必填 | 描述 |
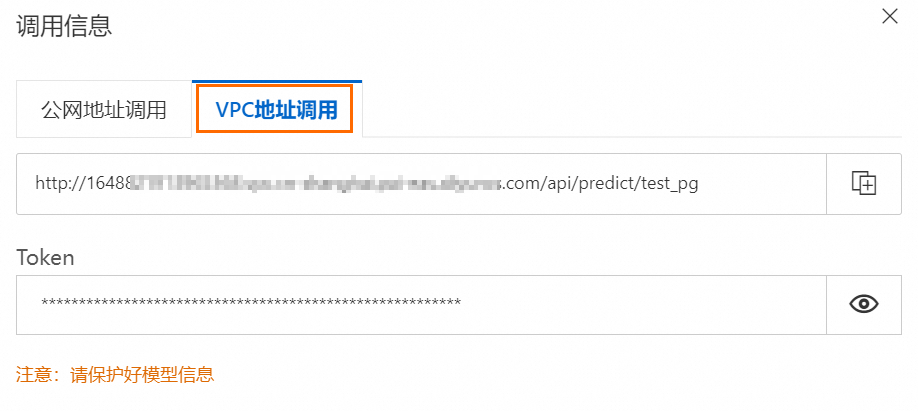
input_endpoint | 是 | 指定访问部署在PAI-EAS平台中的LLM服务时所需要的Endpoint。 Endpoint获取方法:
|
input_token | 是 | 指定访问部署在PAI-EAS平台中的LLM服务时所需要的Token。 Token获取方法:
|
input_prompt | 是 | 需要推理的文本内容。 |
input_additional_parms | 否 | 支持设置参数 格式:
如果不设置该参数,调用 |
示例
示例一:使用参数
input_prompt进行语言推理。SELECT PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '浙江省的省会在哪里?', NULL) AS 答复;返回结果如下。
-[RECOND 1]--------------- 答复 | 浙江省的省会是杭州市。示例二:使用参数
input_additional_parms提供上下文,进行语言推理。加入相关的上下文,可以提高语言推理的准确性。本示例提供的上下文话题背景与省会相关,因此针对问题“江苏呢?”,所得到的推论是“江苏省的省会是南京”,而非与江苏省相关的一些其它信息介绍。
SELECT PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '江苏呢?', '{ "history" : [ ["浙江的省会在哪里?", "浙江省的省会是杭州。"], ["辽宁的省会在哪里?", "辽宁省的省会是沈阳。"] ] }') as 答复;返回结果如下。
-[RECOND 1]------------- 答复 | 江苏省的省会是南京。
最佳实践:封装函数AI_GENERATE_TEXT
每次在使用函数AI_GENERATE_TEXT时,都需要传入较长内容的参数input_endpoint与input_token。不仅使用方式不够简洁,还会在应用程序中暴露敏感信息。建议自定义一个新的函数,将AI_GENERATE_TEXT进行封装。这有利于:
简化使用方式,同时屏蔽敏感信息。
可以对推理生成的内容,进行二次加工。
封装函数AI_GENERATE_TEXT示例:
-- 定义封装函数:
CREATE OR REPLACE FUNCTION Wrapper_AI_GENERATE_TEXT(prompt text, context text)
RETURNS TEXT AS
$$
DECLARE
result text := ' ';
BEGIN
SELECT PG_CATALOG.AI_GENERATE_TEXT ('<... use_your_endpoint ...>',
'<... use_your_token ...>',
prompt, context) INTO result;
IF result IS NOT NULL
AND result LIKE '%some_condition%' THEN
result := '<... your_expected_value ...> ';
END IF;
RETURN result;
END;
$$ LANGUAGE plpgsql;
-- 使用封装函数,可以极大简化使用方式:
SELECT Wrapper_AI_GENERATE_TEXT('浙江的省会在哪里?', null) AS 答复;
---------------------------
答复 | 浙江省的省会是杭州市。应用案例
对消费者在购物网站中发表的商品使用评价信息进行总结,并判断其内容是趋于正面或负面的反馈。
执行如下语句,创建一张名为feedback_collect的表,其中存储了消费者对于所购买商品的评价信息。
-- 创建表。
CREATE TABLE feedback_collect
(
id int not null,
name varchar(10),
age int,
feedback text,
AI_evaluation text
)
distributed by (id);
-- 插入客户信息、以及对商品的‘评价信息’。
INSERT INTO feedback_collect VALUES(1, '张三', 38, '苹果15手机外观精美,轻薄便携,功能强大。其拥有独特的颜色和材质,同时屏幕清晰,操作流畅。拍照效果优秀,支持长焦功能,能够满足用户的多种需求。此外,该手机还采用USB-C接口,支持快速充电和数据传输。总的来说,苹果15是一款易于使用的手机,具有很高的性价比');
INSERT INTO feedback_collect VALUES(2, '李四', 30, 'Thinkpad P系列笔记本电脑外观时尚,轻薄便携,功能强大。它采用了高清晰度屏幕,操作流畅,键盘舒适,性能卓越。它支持多种连接方式,包括USB、HDMI和Thunderbolt等,同时也支持快速充电和数据传输。Thinkpad P系列笔记本电脑易于使用,具有很高的性价比');
INSERT INTO feedback_collect VALUES(3, '王五', 40, '这款手机贴膜真是太糟糕了!首先,它的质量很差,使用起来非常不顺畅。其次,它的粘性很弱,没过几天就失去了粘性,无法保护手机屏幕。最重要的是,它还会影响我的使用体验,让我非常不满意。我强烈建议大家不要购买这款贴膜,以免浪费时间和金钱');
INSERT INTO feedback_collect VALUES(4, '孙六', 45, '这款电动牙刷真是太差劲了!首先,它的电池寿命非常短,每次充电只能使用一两天。其次,它的清洁效果也不如预期,牙齿上还是残留了很多细菌。最重要的是,它的质量也很差,经常出现卡顿和故障。我非常失望,建议大家在购买之前一定要仔细考虑。');场景一:根据商品评价的内容,自动判断其为正面反馈还是负面反馈,并把判断结果存放回
feedback_collect表中。-- 首先查询列AI_evaluation,可以看到目前尚无评价结果返回。 SELECT AI_evaluation FROM feedback_collect; -- 自动判断:商品评价是正面/负面反馈,并保存于feedback_collect表中。 UPDATE feedback_collect SET AI_evaluation = PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '判断“'|| feedback ||'”的内容,是正面还是负面的。', '{ "history" : [ ["这台相机的拍照效果不好,电池续航差!", "负面评价。"], ["这台冰箱,节能、环保、噪音小。", "正面评价。"] ] }'); -- 再次查询列AI_evaluation,可以看到如下信息。 SELECT AI_evaluation FROM feedback_collect; ai_evaluation ------------------------ 这段评价属于负面评价。 负面评价。 正面评价。 正面评价。 (4 rows)场景二:选出负面反馈的用户商品评价进行总结,并显示输出。
-- 对负面评价的内容,进行总结并返回。 SELECT feedback AS 原评价, AI_evaluation 原评价推理, PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '对“'|| feedback ||'”的内容,进行总结。字数在30左右。', NULL) AS 总结 FROM feedback_collect WHERE AI_evaluation LIKE '%负面%'; -- 产生的结果如下。 -[ RECORD 1 ]------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 原评价 | 这款手机贴膜真是太糟糕了!首先,它的质量很差,使用起来非常不顺畅。其次,它的粘性很弱,没过几天就失去了粘性,无法保护手机屏幕。最重要的是,它还会影响我的使用体验,让我非常不满意。我强烈建议大家不要购买这款贴膜,以免浪费时间和金钱 原评价推理 | 这段评价属于负面评价。 总结 | 该款手机贴膜质量差、粘性弱且影响使用体验,不建议购买。 -[ RECORD 2 ]------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 原评价 | 这款电动牙刷真是太差劲了!首先,它的电池寿命非常短,每次充电只能使用一两天。其次,它的清洁效果也不如预期,牙齿上还是残留了很多细菌。最重要的是,它的质量也很差,经常出现卡顿和故障。我非常失望,建议大家在购买之前一定要仔细考虑。 原评价推理 | 负面评价。 总结 | 该电动牙刷的电池寿命短、清洁效果差、质量差,建议购买前仔细考虑。
场景一和场景二的推论结果仅作为参考示例。使用不同的大语言模型服务(如通义千问、ChatGLM等),所得到的推论结果会有差异。即使确定大语言模型后,将同一条SQL执行多次,所得到的推论结果内容,也会略有不同。
常见问题及解决方案
出错信息提示
出现错误提示:
AI_GENERATE_TEXT error: HTTP request service failure或AI_GENERATE_TEXT error: Incorrect endpoint URL is specified。检查在调用函数
PG_CATALOG.AI_GENERATE_TEXT时,参数input_endpoint是否填写正确,一定要填写在VPC下的地址。Endpoint获取方式,请参见PG_CATALOG.AI_GENERATE_TEXT(...)函数介绍。出现错误提示:
AI_GENERATE_TEXT error: Incorrect endpoint URL is specified。检查在调用函数
PG_CATALOG.AI_GENERATE_TEXT时,参数input_token是否填写正确。Token获取方式,请参见PG_CATALOG.AI_GENERATE_TEXT(...)函数介绍。出现错误提示:
AI_GENERATE_TEXT error: Invalid JSON syntax against the 4th parameter within UDF。请检查在调用函数
PG_CATALOG.AI_GENERATE_TEXT时,参数input_additional_parms是否填写正确。错误可能由如下原因引起:参数
input_additional_parms的JSON格式填写不正确。参数
input_additional_parms使用了中文字符的逗号、单引号或双引号,作为JSON格式的一部分,导致JSON 无法识别。
出现错误提示:
function AI_GENERATE_TEXT (unknown, unknown, unknown, unknown) does not exist。检查AnalyticDB PostgreSQL版实例内核版本是否满足要求。如何查看实例内核版本,请参见查看内核小版本。
调用函数
PG_CATALOG.AI_GENERATE_TEXT时,没有指定Schema:PG_CATALOG,导致函数无法被系统识别。
调用AI_GENERATE_TEXT后,长时间没有结果返回
当调用函数PG_CATALOG.AI_GENERATE_TEXT后,长时间没有返回结果,可以从如下维度排查。
确保AnalyticDB PostgreSQL版实例的地域与LLM服务部署PAI-EAS所在的地域相同。
确保使用函数的
input_endpoint与input_token,与LLM服务的部署信息一致。详情请参见参数。模型自身的性能问题。通常情况下,LLM服务处理一条请求的平均响应时间,在2~3秒(s)钟左右。
说明该值仅作为参考。因为响应时间,与需要被分析内容的长度、生成推理内容的长度、不同模型自身的处理性能、部署模型的实例硬件规格、模型部署的实例个数,都有关系。
例如,使用
SELECT pg_catalog.ai_generate_text (...) where column >= ...语句,对文本内容进行推理。可以尝试采用如下方法,提升文本推理的处理速度。增加LLM服务实例个数。
首先预估模型处理时间。
计算
SELECT COUNT(*) WHERE column >= ...需要处理数据的总量,假设得到数值为1000。抽样若干条数据,统计LLM服务的处理时间。例如,SELECT pg_catalog.ai_generate_text (...) LIMIT 100统计处理100条请求的时间(可在应用程序内,执行该SELECT语句前后,记录系统时间戳,以便统计执行时长)。基于该统计时间,乘以10可以大致估算整体的处理完成的时间。然后根据上述估算时间,增加部署LLM服务的实例个数。实例配置规格选择建议,请参见附录:LLM服务实例配置规格建议。
增加LLM服务实例个数的方法有以下几种:
对于执行时间较长的SQL语句,合理设置如下参数,避免语句超时。示例如下:
SET idle_in_transaction_session_timeout =5h;设置连接5小时后超时(根据实际情况合理设置超时时间)。SET statement_timeout = 0;设置执行语句永不超时(酌情考虑)。
附录:LLM服务实例配置规格建议
LLM服务的计算资源主要由GPU承担。因此,如果对LLM服务处理请求时间有较高要求,可以选择规格更高的GPU。
GPU核数的选择:在保证相同核数的前提下,服务实例数越多,对LLM处理请求时间的提升会更明显。
例如,同样选择4核的GPU,部署4个单核GPU的实例,对LLM处理请求性能的提升更明显。并且部署4个单核GPU的实例,与部署1个4核GPU的实例,成本是相同的。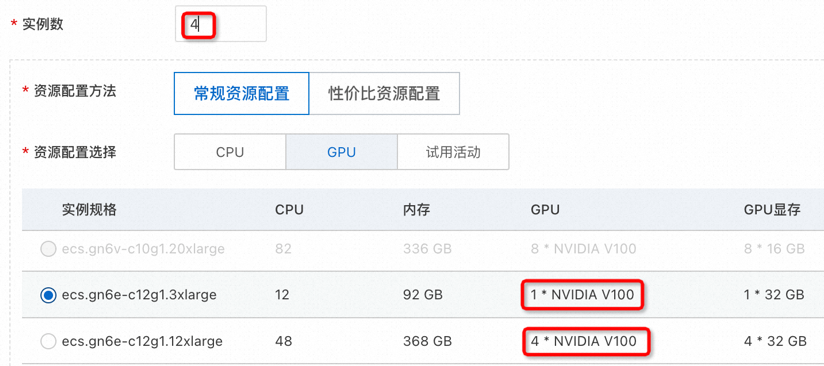
相关文档
如果您想了解更多关于阿里云PAI模型在线服务(EAS)信息,请参见EAS模型服务概述。