
数据倾斜诊断
AnalyticDB PostgreSQL版提供的智能诊断数据倾斜功能,可以每小时定期自动诊断数据库内的所有表,并生成相应的诊断信息表,供您检测库内所有表的倾斜情况。
注意事项
智能诊断数据倾斜功能仅支持存储弹性模式实例,且内核版本须满足以下条件:
AnalyticDB PostgreSQL 6.0版实例为v6.3.10.0及以上。
AnalyticDB PostgreSQL 7.0版实例为v7.0.4.0及以上。
智能诊断数据倾斜功能在系统后台以库为维度进行诊断,但不包括系统库(postgres、template0、template1、adbpgadmin和aurora 5个系统库),建议您将业务数据放在新建库中,不要将数据放在上述5个系统库中,否则无法诊断数据。
智能诊断数据倾斜功能会扫描库中的每张表(不包括临时表和unlogged表),但为了兼顾扫描的速度和诊断的意义,默认情况下,数据量小于1 GB的表会被过滤,如需调整该阈值,请参见设置智能诊断参数。
智能诊断数据倾斜功能默认情况下不会显示倾斜率小于20%的表,如需调整该阈值,请参见设置智能诊断参数。
智能诊断数据倾斜功能启动时只会查询元数据表,对数据库查询性能几乎没有影响。
为何会数据倾斜
AnalyticDB PostgreSQL版属于MPP数据库,其中的数据是分布在多个计算节点上。目前AnalyticDB PostgreSQL版支持的数据分布方式有如下三种:
随机(RANDOMLY)分布
该分布方式的表无法充分利用数据的特征。例如,多表关联查询场景下无法采用本地关联(Collocated Join),从而导致查询性能不如采用基于分布键HASH值分布方式的效果。
复制(REPLICATED)分布
该分布方式会在每个计算节点都存放一份完整的数据。复制分布方式通常只会用在数据量小的表中,如果数据量大的表使用复制分布方式,会导致数据急剧膨胀。
哈希(HASH)分布
该分布方式会根据分布键HASH值将数据分布到各个计算节点上,该方式的关键在于如何选择分布键,分布键选择不正确时,容易造成数据倾斜。可遵循如下规则选择分布键:
有主键的表,建议选择主键作为分布键。
无主键的表,建议选择分布比较平均或不同值比较多的列作为分布键。
以下示例为选择恰当的分布键和不恰当的分布键的数据分布情况。
恰当的分布键
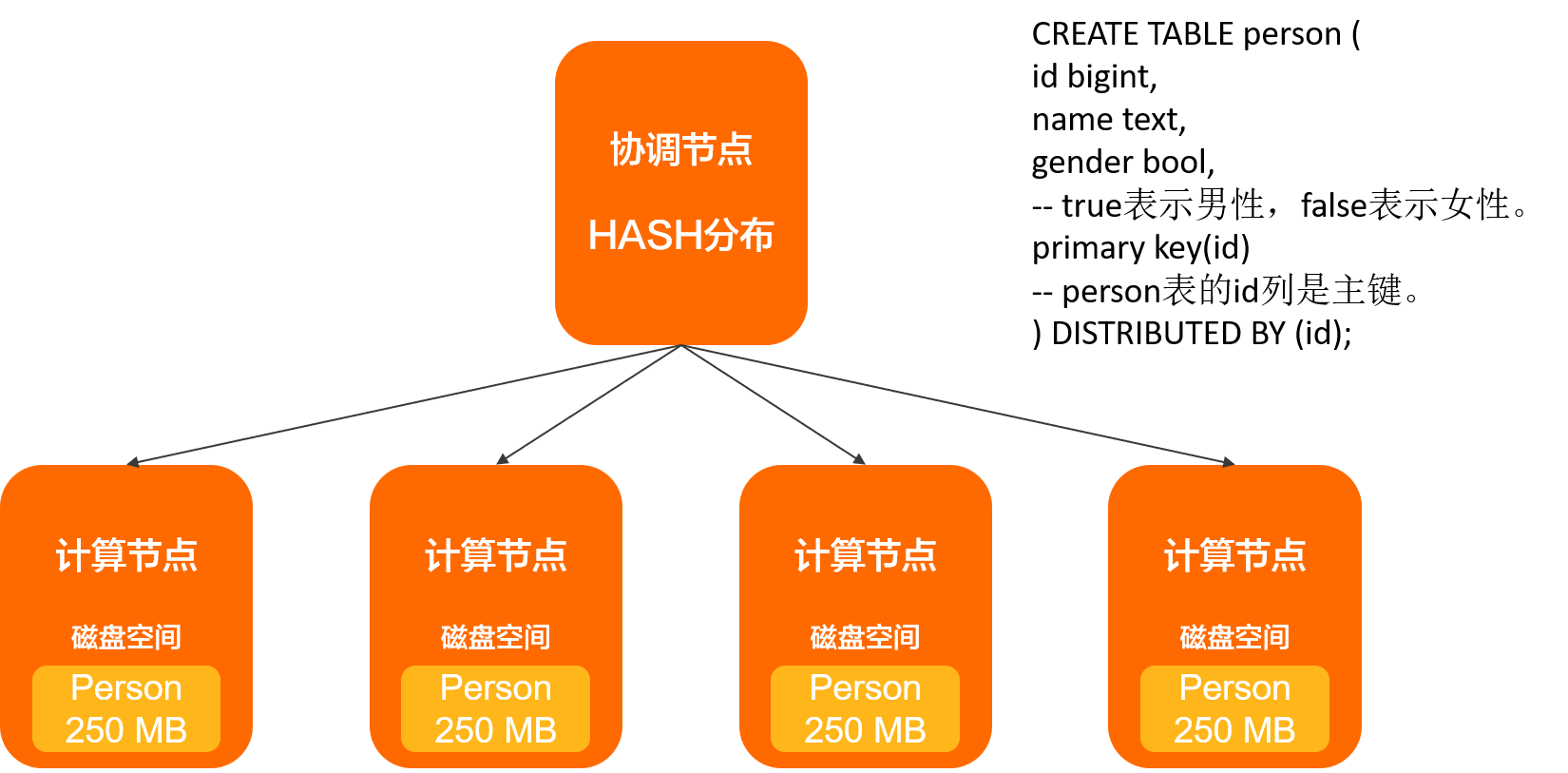
上图示例中,选择了主键id为分布键,数据均匀地分布到了四个计算节点上。
不恰当的分布键
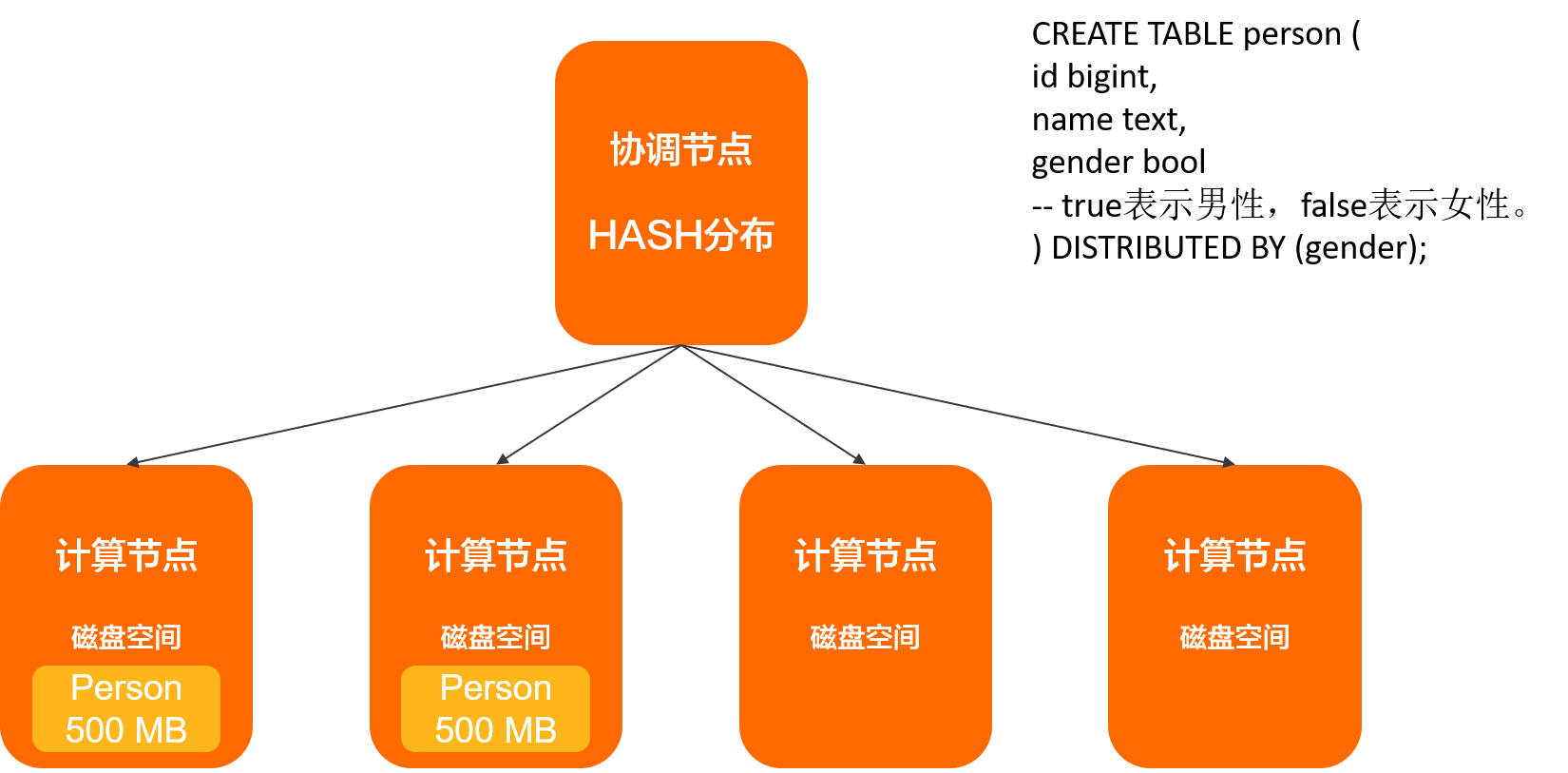
上图示例中,选择了gender字段作为分布键,由于gender字段只有true和false两个值,导致仅有两个计算节点上有数据,其他节点没有数据,从而导致了数据的倾斜。
查看数据倾斜
智能诊断功能的诊断信息存储在adbpg_toolkit.diag_skew_tables表中。您可以在控制台直接查看诊断信息,也可以连接实例后执行SQL语句查看诊断信息:
控制台查看诊断信息的具体操作,请参见数据膨胀、倾斜与索引统计。
查看诊断信息的SQL语句如下:
SELECT * FROM adbpg_toolkit.diag_skew_tables;表diag_skew_tables各个字段的详细说明如下:
字段
类型
说明
schema_name
name (63-byte type for storing system identifiers)
表所在的Schema的名称。
table_name
name
表名。
table_size
bigint
表的大小,单位为Byte。
table_skew
real
表的倾斜率,取值范围为0~100,单位为%。
table_owner
name
表的拥有者的名称。
table_distributed_policy
text
表的分布键。
diagnose_time
timestamp with time zone
诊断信息的生成时间。
您也可以添加过滤条件,查看指定Schema或指定表的数据倾斜情况,查询语句如下:
查看指定Schema下所有表的数据倾斜情况:
SELECT * FROM adbpg_toolkit.diag_skew_tables WHERE schema_name = '<Schema名称>';查看指定表的数据倾斜情况:
SELECT * FROM adbpg_toolkit.diag_skew_tables WHERE table_name = '<Table名称>';
手动触发数据倾斜诊断
智能诊断功能默认会在每个整点启动。如果您修改了某张表的分布键后,想要立刻查看修改后的效果,就需要手动触发数据倾斜诊断。手动触发数据倾斜诊断的语句如下:
SELECT adbpg_toolkit.diagnose_skew_tables();设置智能诊断参数
设置数据量阈值
默认情况下,智能诊断功能会过滤小于1 GB的表,如需调整过滤的表的阈值大小,可以通过如下语句进行设置:
ALTER DATABASE <数据库名称> SET adb_diagnose_table_threshold_size to <表的数据量,单位为字节>;例如,您需要诊断500 MB以上的表,设置语句如下:
ALTER DATABASE diagnose SET adb_diagnose_table_threshold_size to 536870912;设置倾斜率阈值
默认情况下,智能诊断功能不会显示倾斜率小于20%的表,如需调整显示的表的倾斜率的阈值,可以通过如下语句进行设置:
ALTER DATABASE <数据库名称> SET adb_diagnose_skew_percent to <倾斜率,取值范围为0~100,单位为%>;例如,您需要显示diagnose库中所有倾斜率大于0%的表,设置语句如下:
ALTER DATABASE diagnose SET adb_diagnose_skew_percent to 0;数据倾斜计算规则
AnalyticDB PostgreSQL版会根据表的倾斜率去定义数据存储在每个计算节点之间的倾斜程度。倾斜率的取值范围是0%~100%,该值越大表示数据倾斜的越严重。倾斜率计算公式如下:
Avg=(S1+S2+....Sn)/n
Max=Max(S1,S2,....Sn)
倾斜率=(1 - Avg / Max) / (1 - 1/n) * 100%假设表的数据分布在n个计算节点上,Sn代表每个节点上面的数据大小。
消除数据倾斜
导致数据倾斜的原因一般都是分布键选择不正确。例如,一张表的某个字段的相同值特别多时,如果选择了该字段作为分布键进行HASH分布,就会导致该字段的这些相同值所在的计算节点上的数据比其他计算节点上的数据多。为了避免解决数据倾斜,建议您重新选择分布键。分布键的选择策略,请参见分布键的选择策略。
修改表分布键的语句如下:
ALTER TABLE <table_name> SET DISTRIBUTED BY (<column_name>);例如,需要将表t1的分布键修改为c2列。
ALTER TABLE t1 SET DISTRIBUTED BY (c2);