
基于DataWorks+AnalyticDB Spark构建湖仓分析
本文将基于DataWorks DataStudio托管的Notebook集成AnalyticDB Spark,进行交互式湖仓开发。
方案架构

方案介绍
使用 AnalyticDB MySQL 的 Spark 计算资源,加工存放在 OSS 中的 Delta Lake 原始数据。
将加工后的数据写入 AnalyticDB MySQL 的数仓存储。
在 DataWorks Notebook 中,使用 SparkSQL 或 PySpark 编写数据加工任务,并编排为工作流,并发布到 DataWorks,进行例行调度。
数据写入 AnalyticDB MySQL 数仓后,通过 QuickBI 或 PowerBI 进行多维分析与可视化。
方案优势
免运维的高效开发:AnalyticDB 托管 Spark 引擎,无需自建集群,自动扩缩容。Notebook 支持交互式调试,SQL 与 Python 混合编程,快速验证逻辑。
湖仓一体:原始数据存 OSS(低成本),热数据存 AnalyticDB(高性能),兼顾弹性与查询效率。
端到端闭环:从数据加工(DataWorks)到分析(BI)全程在阿里云体系内完成,权限、网络、监控统一管理。
调度可靠:依托 DataWorks 强大的任务编排能力,支持依赖管理、失败重试、告警通知。
前提条件
如果使用RAM用户进行开发,请确保其已具备如下权限:
已经在AnalyticDB MySQL控制台,中的右上角进行日志配置。
DataWorks DataStudio准备
创建与绑定资源组
登录DataWorks控制台,单击左侧导航栏的资源组,单击创建资源组。
创建与AnalyticDB MySQL同一地域,以及同一VPC与交换机的资源组。
单击资源组的网络设置,查看对应的交换机网段。
将网段信息配置在AnalyticDB MySQL的白名单中,避免网络访问被拒。
单击左侧导航栏的工作空间,单击对应的工作空间名称,进入工作空间。
单击左侧导航栏的资源组,单击绑定资源组,在弹窗中选择绑定已创建的资源组。
绑定计算资源
单击左侧导航栏的计算资源,单击绑定计算资源,选择AnalyticDB for Spark。
选择对应实例,数据库名称填写自带的测试数据库,
ADB_External_TPCH_10GB。自定义计算资源实例名,如
SparkSQL_JDBC_Query。单击选择绑定的资源组,可以单击批量测试连通性,确认网络可以正常连通。
创建个人开发环境(Data Studio)
单击左侧导航栏,进入数据开发。
单击上方导航栏。
资源组:步骤1创建的资源组。
资源类型:CPU
资源配额与镜像:默认
专有网络与交换机:与资源组配置相同。
安全组:同一VPC下的安全组,且添加入方向规则为VPC网段开放15002和4040的端口,如无,详情请参见创建安全组。
注意记录或查看交换机与安全组的ID,后续操作中需替换。
单击确认后,等待创建完成。
单击上方导航栏,选择创建好的环境,确认切换,重新刷新界面。
创建 Notebook 并提交 Spark 作业
在数据开发页,创建 Notebook 节点。
单击添加Python单元格,运行下列代码。(约1分钟)
<vswitch_id>:填写交换机ID。
<security_group_id>:填写安全组ID。
spark.adb.acuPerApp:当前作业在资源组中可使用的最大 ACU 资源配额。
<job_resource_group_name>:AnalyticDB MySQL的Job类型资源组名称,可自行创建,可以默认填写
serverless。
spark = %adb_spark add \ --spark-conf spark.adb.eni.vswitchId=<vswitch_id> \ --spark-conf spark.adb.eni.securityGroupId=<security_group_id>\ --spark-conf spark.adb.acuPerApp=32\ --resource-group <job_resource_group_name>创建一个ADB Spark SQL单元格,创建数据库。
替换
<your_bucket_with_same_region>为同地域的 OSS Bucket。CREATE DATABASE IF NOT EXISTS db_sample LOCATION 'oss://<your_bucket>/adb_demo/';运行完成后,可以看到AnalyticDB MySQL控制台的数据目录,存在
db_sample这个库,说明已经完成集成。
构建分层加工的数据管道
DataWorks提供了周期工作流,以满足需要周期性调度运行的业务场景。
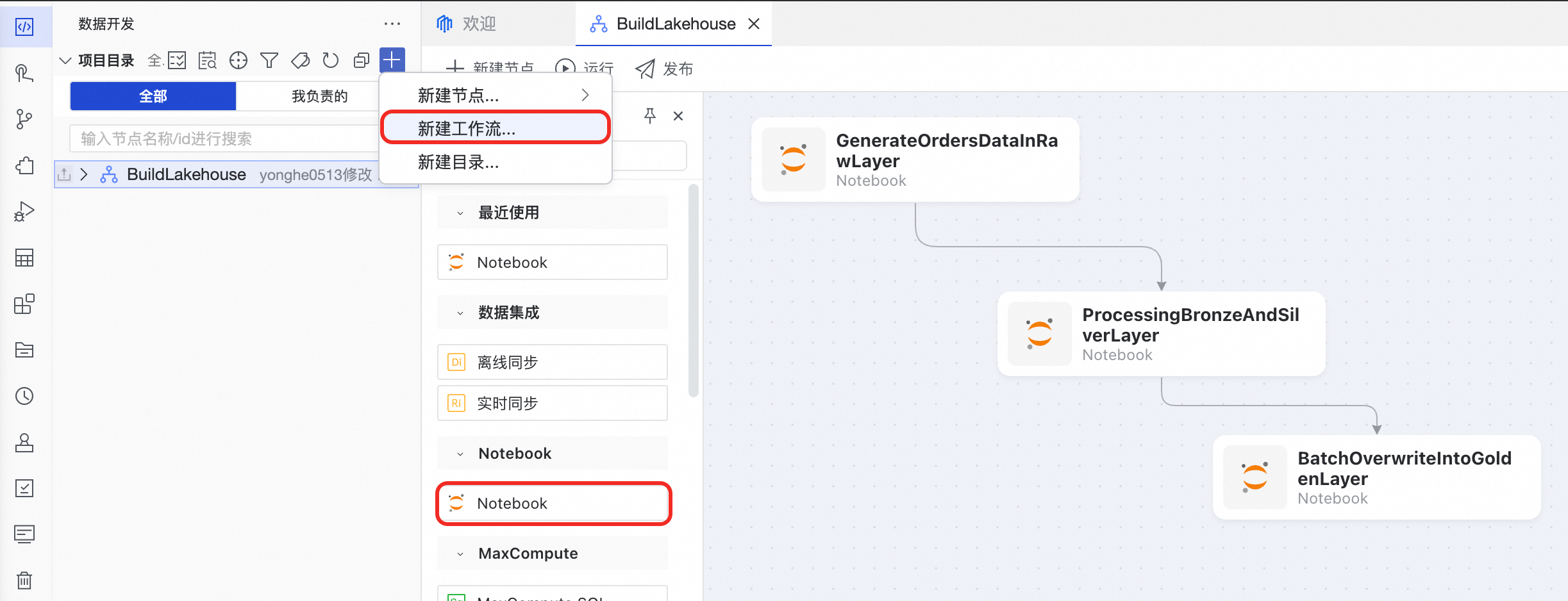
流程代码示例参考
文件下载 | 任务描述 |
随机生成订单数据,写入orders_raw表,其中 | |
从orders_raw表清洗数据,写入orders_bronze表;再聚合写入orders_silver表。 | |
从orders_silver提取数据,按分区写入数仓的orders_golden表,该表为事实表,支持 BI 高效查询。 |
替换所有
.ipynb文件中的<your_vswitch_id>和<your_security_group_id>。替换
GenerateOrdersDataInRawLayer.ipynb中的 OSS 路径。
使用 BI 工具可视化
数据写入 AnalyticDB MySQL 数仓后,通过其 MySQL 兼容的 SQL 端点对接 BI 工具。
将 BI 工具所在网段加入 AnalyticDB MySQL 实例 IP 白名单。
确保AnalyticDB MySQL的user_default资源组的 ACU 数量大于 0。