
新建开发环境场景并运行
您可以通过新建开发环境场景,并在开发环境场景画布中编排节点工作流、配置运行参数,来验证数据处理流程的正确性。本文以MaxCompute节点搭建流程为例介绍如何新建开发环境场景并运行。
前提条件
已创建相关的云计算资源,具体操作,请参见新建云计算资源。
背景信息
节点流程定义了一段处理逻辑,通过有向无环图DAG(Directed Acyclic Graph)描述。节点流程中所有节点的输入、输出数据都是具体的数据表、文件、数据流。
步骤一:新建开发环境场景
在页面左上角,单击
 图标,选择协同。
图标,选择协同。在顶部菜单栏,单击
 图标,选择目标工作组,单击资产加工 。说明
图标,选择目标工作组,单击资产加工 。说明若您已在资产加工页面,请跳过“单击资产加工”的操作。
在左侧导航栏,单击
 图标,选择场景模式。
图标,选择场景模式。单击
 图标,在开发环境页签,单击新建场景。
图标,在开发环境页签,单击新建场景。在新建场景对话框,填写场景名称和场景标识,单击确认。
步骤二:添加计算类节点并配置
计算类节点包括:计算节点和公共节点。请根据需要添加一个或者多个计算节点或者公共节点或者二者的混用。
计算节点:主要适用于某个特定场景,或针对某张表的逻辑处理,这些节点不需要复用,在场景中直接创建。
公共节点:主要是用于计算逻辑的复用,在不同的场景中,通过引用公共节点并调整参数的方式,完成符合场景业务要求的计算逻辑,提升开发效率。在公共节点页面创建,场景中引用。例如:1分钟流量估计、2分钟流量估计、5分钟流量估计,其计算逻辑一样,只是运行时的参数不一样。
1.在场景画布中添加计算节点。
计算节点包含多种类型,这里以添加MaxCompute SQL类型的计算节点为例介绍添加计算节点的示例操作。
如果不需要添加计算节点,则直接执行6.添加公共节点并配置。
在开发环境场景画布页面,将左侧需要类型的计算节点拖入到开发环境场景画布,更多信息,请参见计算节点配置说明。
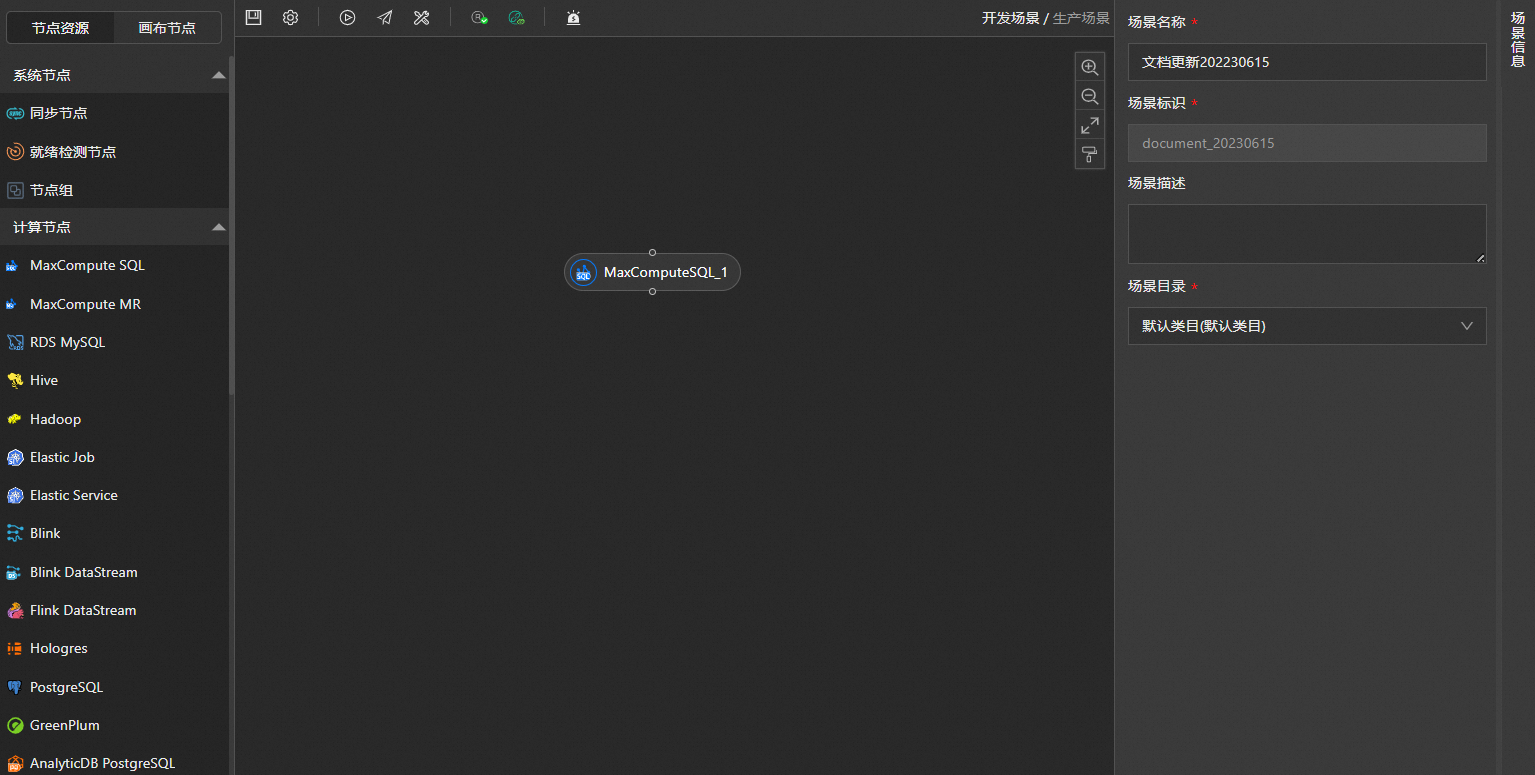
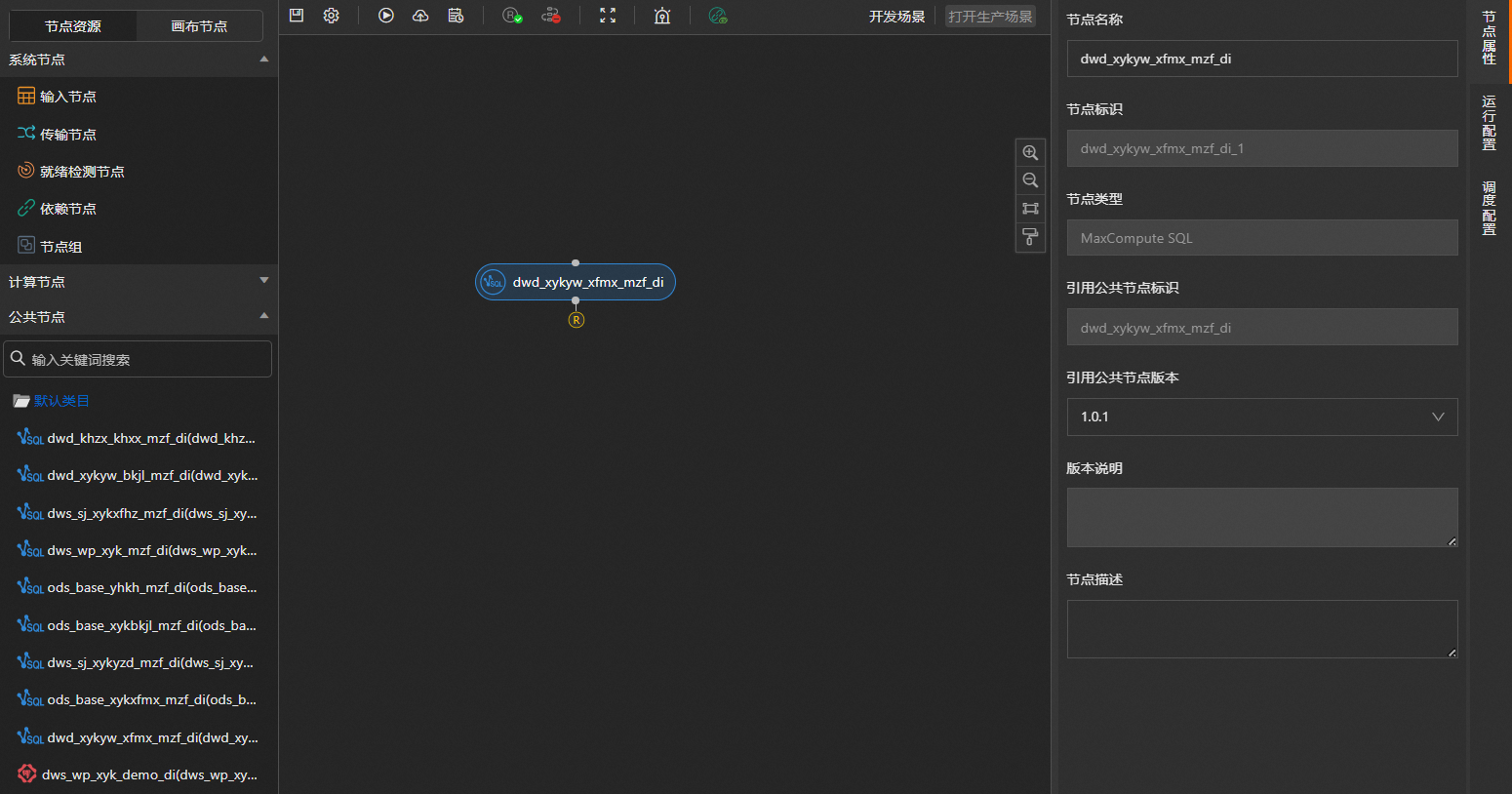
2.在计算节点编辑页面,配置节点的基本信息。
双击拖入的计算节点。
在节点编辑页面右侧的节点属性页签,自定义输入节点名称和节点描述等。
配置项
说明
节点名称
节点的名称,支持用户自定义。
节点描述
节点的描述性信息,方便用户理解和查找。
在节点编辑页面,输入算法语句,单击
 图标。
图标。(条件必选)当需要在算法语句中使用自定义函数时,单击引用函数页签,在自定义函数列表找到需要的自定义函数,再返回编辑页面输入。若函数列表为空,则需要先新建函数,更多操作请参见新建自定义函数。
在确认节点信息对话框中,确认节点标识、节点名称以及节点目录信息设置无误后,单击确认。
3.在计算节点编辑页面,配置节点的运行配置信息。
单击页面右侧运行配置页签,选择需要的开发和生产计算引擎。
(条件必选)在运行配置页签,手动添加节点的输入、节点输出和节点变量,或通过单击编辑页面的
图标,自动解析节点的输入、节点输出和节点变量,参数设置的更多信息,请参见计算节点配置说明。这里以解析为例介绍。单击编辑页面的
图标。在节点编辑页面的运行配置页签,打开节点输入后面的
开关,查看节点输入。在节点编辑页面的运行配置页签,打开节点输出后面的
开关,查看节点输出。填写节点变量值。
如果业务有依赖关系时,配置依赖信息。
单击解析依赖,当存在依赖节点时,系统会自动解析依赖节点信息并呈现在依赖节点区域,并生成依赖图标呈现在场景画布中。
在节点编辑页面,单击左上角
图标。
在节点编辑页面,单击左上角
图标。(可选)配置字段血缘关系。
说明针对不能自动解析输入和输出的节点类型,当需要了解资产中字段血缘关系时或者自动解析的节点类型中解析存在差异,需要修改字段映射关系时,在配置好输入和输出参数后,单击手动配置血缘,手动配置输入和输出表的字段映射关系。
其中不能自动解析输入和输出参数的节点包括:MaxCompute MR、Hadoop、Elastic Job、Spark Batch、Spark Stream,Elastic Service、Flink Vvp Stream、Flink Vvr Stream。
单击手动配置血缘。
在血缘配置对话框中,单击输出表待配置的目标字段后的
图标,下拉选择对应的输入表以及输入表的字段,单击保存。
说明配置完字段血缘关系并上线后,可至资产中心查看该节点输出表和输入的字段映射关系,具体操作,请参见查看表资产详情的血缘关联内容。
4.运行计算节点
单击
图标,出现节点变量页面,确认参数类型和默认值无误后,单击确定。说明如果计算节点类型为在线节点或者流式节点,则不需要运行,跳过本步骤和查看运行结果和日志的步骤。
查看运行结果和日志,当结果显示如下所示“Current task status:SUCCESS”,则表示节点运行成功。
关闭当前计算节点编辑页面。
5.在场景编辑页面,配置计算节点信息。
在场景画布中,单击拖入的计算节点。
(可选)在开发环境场景编辑页面的右侧的节点属性页签,可修改节点名称、描述和版本说明。
说明如果需要复用当前计算节点的计算逻辑时,可以将该计算节点发布为公共节点,在开发环境场景编辑页面的右侧的节点属性页签,单击发布为公共节点。
单击页面右侧运行配置页签,选择计算节点的开发和生产计算引擎。
如果业务有依赖关系时,需要设置上游依赖节点信息。
支持通过自动解析依赖节点和在场景画布中拖入依赖节点两种方式设置依赖信息,其中拖入依赖节点的操作,更多信息,请参见步骤三:(可选)添加系统节点并配置。以下以自动解析依赖节点为例介绍。
在运行配置页签的节点依赖区域,单击解析依赖,参数说明的更多信息,请参见计算节点配置说明。
若存在依赖节点,则解析完成后,在依赖节点区域的上游页签中,会自动显示该节点的依赖节点相关信息,并在场景画布中自动生成对应依赖节点图标。
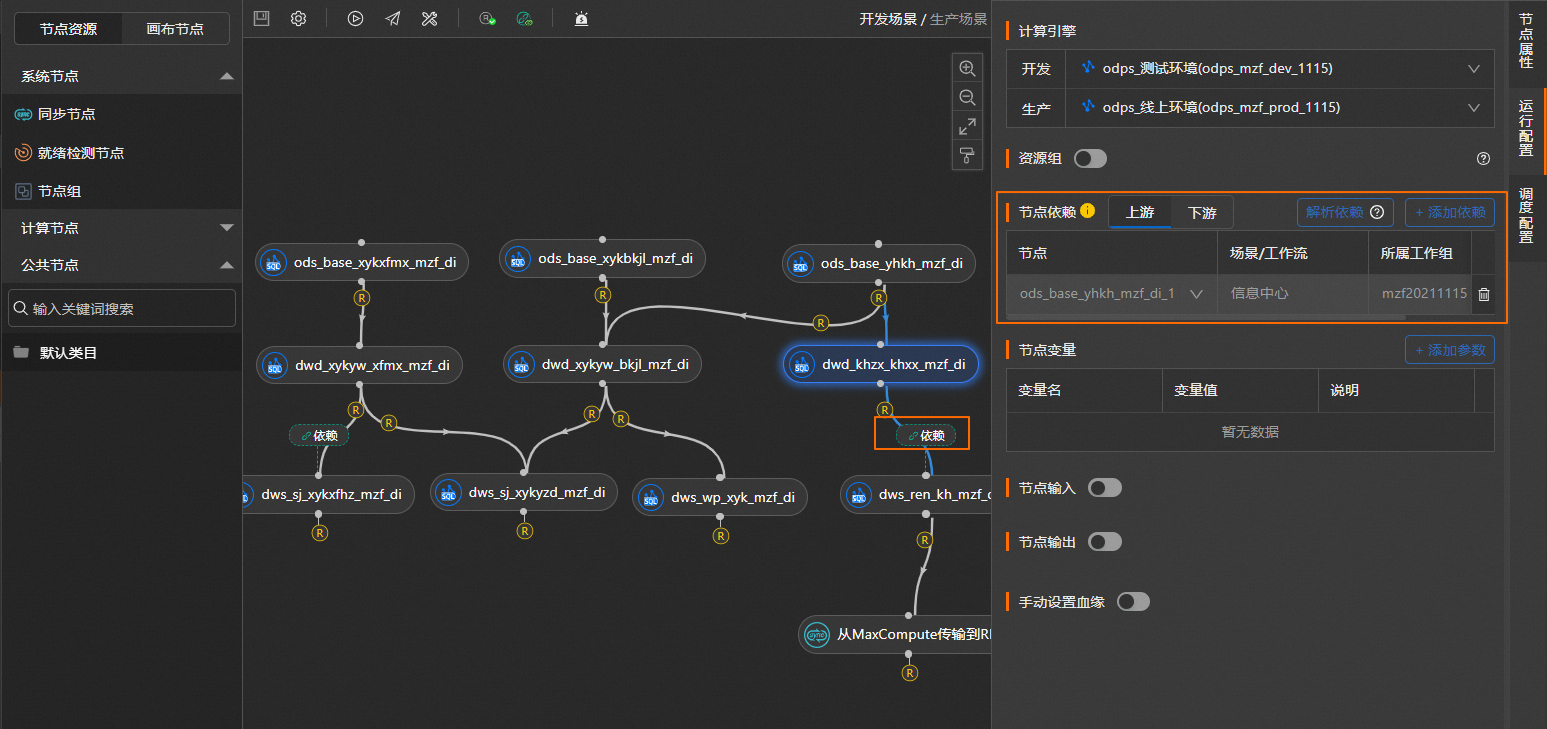
6.添加公共节点并配置。
将左侧公共节点区域下已新建的公共节点拖入到画布。公共节点的创建方法,具体操作,请参见添加MaxCompute SQL类型的公共节点~添加Spark Stream类型的公共节点。
说明如果公共节点较多,您可在左侧导航栏的搜索框,输入关键词,进行搜索。
如果不需要添加公共节点,则直接执行步骤四:连接各节点。
单击拖入的公共节点,在右侧的节点属性页签,查看节点名称等信息。
单击页面右侧运行配置页签,选择公共节点的开发和生产计算引擎,关于参数配置的更多信息,请参见下表。
参数
说明
计算引擎
开发
开发环境场景使用资源,用于在开发环境中运行。
生产
生产场景使用资源,用于在生产环境中运行。
资源组
资源组是发布任务的资源池。设置后,可查看当前公共节点所属的开发资源组和生产资源组,请至系统设置 > 资源组管理中设置。
节点输入
输入标识
节点的输入参数标识。
数据结构
输入表的数据格式,由数据模型定义,在下拉列表中选择,表示该计算资源中提供数据的数据表的结构。
当选择数据表时,需保证输入的模型与上游节点的输出数据模型相同,物理表名可以自定义。
当选择星号(*)时,代表数据结构为任意结构,用于对未创建数据模型的表进行操作,此时物理表必须选择已经存在的表。
开发环境
云计算资源
开发环境中节点输入使用的物理表所在资源。
表名
开发环境中节点输入参数的物理表名,可自定义新建物理表名或者选择已物理化至资源库中的物理表名。
当输入数据结构为星号(*)时,输入物理表名必须选择已经存在的物理表。
当输入数据结构为具体的模型结构时,填写物理表名,系统会自动执行物理化。
当打开依赖上游开关时,且本节点输入参数连接到上游节点输出参数时,则本节点输入参数对应的物理表依赖上游输出,为上游节点输出物理表,不能手动再修改。
生产环境
云计算资源
生产环境中节点输入使用的物理表所在资源。
表名
生产环境中节点输入的物理表名,可自定义新建物理表名或者选择已物理化至资源库中的物理表名。
当输入数据结构为星号(*)时,输入物理表名必须选择已经存在的物理表。
当输入数据结构为具体的模型结构时,填写物理表名,系统会自动执行物理化。
当打开依赖上游开关时,且本节点输入参数连接到上游节点输出参数时,则本节点输入参数对应的物理表依赖上游输出,为上游节点输出物理表,不能手动再修改
节点输出
输出标识
节点的输出参数标识。
数据结构
输出表的数据格式,由数据模型定义,在下拉列表中选择,表示该计算资源中输出数据的数据表的结构。
当选择数据表时,需保证节点输出的模型与下游节点的输入数据模型相同,物理表名可以自定义。
当选择星号(*)时,代表数据结构为任意结构,以输出表为准,此时物理表必须选择已经存在的表。
开发环境
云计算资源
开发环境中节点输出使用的物理表所在资源。
表名
开发环境节点输出的物理表名,可自定义新建物理表或者选择已物理化至资源库中的物理表名。
当输出数据结构为星号(*)时,物理表必须选择资源库中已经存在的物理表。
当输出数据结构为具体的模型结构时,填写物理表名,系统会自动执行物理化。
当输出数据结构为具体的模型结构且数据资源类型为MaxCompute、Hive、AnalyticDB PostgreSQL、PostgreSQL时,系统会自动生成节点的输出物理表,当需要修改时,可打开自定义开关以后修改。
生产环境
云计算资源
生产环境中节点输入使用的物理表所在资源。
表名
生产环境节点输出的物理表名,可自定义新建物理表或者选择已物理化至资源库中的物理表名。
当输出数据结构为星号(*)时,物理表必须选择资源库中已经存在的物理表。
当输出数据结构为具体的模型结构时,填写物理表名,系统会自动执行物理化。
当输出数据结构为具体的模型结构且数据资源类型为MaxCompute、Hive、AnalyticDB PostgreSQL、PostgreSQL时,系统会自动生成节点的输出物理表,当需要修改时,可打开自定义开关以后修改。
节点变量
变量名
算法参数的名称,用户自定义。
变量值
参数的值设置。
说明
参数的说明信息。
如果业务有依赖关系时,需要设置上游依赖节点信息。
支持通过自动解析依赖节点和手动添加依赖节点,其中拖入依赖节点的操作,更多信息,请参见步骤三:(可选)添加系统节点并配置。以下以自动解析依赖节点为例介绍。
在运行配置页签的依赖节点区域,单击解析依赖。
若该节点存在依赖节点,解析完成后,在依赖节点区域会自动显示依赖节点的详细信息,并在场景画布中自动生成对应依赖节点图标。
参数
说明
依赖节点
上游
说明查看当前节点依赖的节点信息。
解析依赖
当配置完节点输入信息后,单击解析依赖,可自动解析该节点的依赖节点,并将依赖信息展示在场景画布运行配置的依赖节点区域中。
节点
该依赖节点的名称。
场景/工作流
该依赖节点的所属场景或者任务流的名称及标识。
所属工作区组
该依赖节点的所属工作区。
依赖关系
依赖节点的类型。
强依赖:若依赖节点运行失败,调度阻塞,当前节点无法执行,等待依赖节点恢复成功。
弱依赖:若依赖节点运行失败,调度不阻塞,当前节点继续按照计划继续触发执行
下游
说明在下游节点页签中,查看当前节点被哪些节点或者任务依赖,即展示依赖当前节点的其他节点信息。无需配置。
节点
依赖当前节点的节点名称。
场景/工作流
当前节点作为依赖节点的其他节点所属场景的场景名称及标识以及工作流名称及标识。
所属工作组
把当前节点作为依赖节点的其他节点的所属工作组。
步骤五:运行开发环境场景
单击
图标。在确认对话框中,单击确定。
在物理化预分析对话框中,确认待物理化的逻辑表无误后,单击确定,等待部署成功。
在设置业务日期对话框,选择日期,单击确定,等待运行成功。
说明日期只能选择T-1之前的日期。T表示今天(Today)。
如果您需要查看之前日期的运行结果,可以通过补数据功能实现,具体操作,请参见新建补数据计划。
如果场景运行失败,您可将鼠标移动至状态,单击后面的查看日志,通过运行日志定位失败原因,更多详情,请参见查看开发环境场景运维信息。
相关操作
操作 | 说明 |
删除开发环境场景 | 在开发环境场景列表中,选择待删除的开发环境场景,单击删除。在弹出对话框中,单击确认。 说明 如果待删除的开发环境场景已发布了生产场景,则您需要预先下线该生产场景,具体操作,请参见下线生产环境场景。 重要 场景删除后不可恢复,请谨慎操作。 |
修改开发环境场景所属目录 | 在开发环境场景列表中,选中需要修改所属目录的场景,单击修改所属目录,选择需要归属的目录,单击确定。 说明 不支持将开发环境场景的所属目录修改为默认目录,只可从默认类目改成其他目录。 |
发布计算节点为公共节点 | 如果需要复用当前计算节点的计算逻辑时,可以将该计算节点发布为公共节点。操作方法如下:
|
后续步骤
开发环境场景运行后,需要将开发环境场景上线至生产场景,才能提供生产服务,具体操作,请参见上线开发环境场景。