
解决方案:免费体验AnalyticDB PostgreSQL版以文搜图
本文为您介绍在实际的电商业务中,通过将商品图片集合的向量化结果存储在云原生数据仓库AnalyticDB PostgreSQL版向量检索引擎中,实现以文搜图的高效准确检索。
背景信息
在现实世界中,绝大多数的数据都是以非结构化数据的形式存在,如图片,音频,视频,文本等。这些非结构化数据随着智慧城市、短视频、商品个性化推荐、视觉商品搜索等应用的出现而爆发式增长。为了能够处理这些非结构化数据,通常会使用人工智能技术提取这些非结构化数据的特征,并将其转化为特征向量,再对这些特征向量进行分析和检索以实现对非结构化数据的处理。通过构建云原生数据仓库AnalyticDB PostgreSQL版向量检索引擎和中文CLIP模型组成以文搜图的方案体验,实现高性能图文多模态检索,从而体验向量检索在业务场景的能力和高性能。
多模态检索在电商场景中扮演重要的角色,是满足用户需求、促成点击交易不可缺少的一环。 图文检索场景中,通过自然语言形式的检索,从给定的商品图片池中检索出相关图片,是衡量模型多模态理解与匹配的能力。
使用场景
通过AnalyticDB PostgreSQL版向量分析,您可以非常容易地搭建各种智能化应用。
以文搜图服务,即通过文字检索图片的应用服务。
视频检索服务,即通过视频中的某些帧图片进行视频图片检索。
声纹检索服务,即通过音频匹配音频的应用服务。
推荐系统服务,即通过用户特征实现推荐匹配的功能。
基于语义的文本检索和推荐,通过文本检索近似文本。
问答机器人,通过与大模型结合搭建高效的问答机器人服务。
文件去重,通过文件指纹特征来去除重复文件。
前提条件
AnalyticDB PostgreSQL版实例资源类型为存储弹性模式。
注意事项
本方案采用预置数据集的方式进行以文搜图的方案体验,不支持通过上传自有图片进行搜索体验。预置数据集详情,请参见数据集。
在释放AnalyticDB PostgreSQL版实例时,AnalyticDB PostgreSQL版创建的安全组无法释放,需要在实例释放6个小时后释放安全组。即通过本解决方案创建的资源在一键释放后,在ECS上会有一个安全组的残留。
说明残留安全组不会带来业务影响,本方案涉及到的云资源已经释放,您可以在后续合适的时间(即6个小时后)登录ECS控制台删除该安全组。
检索架构
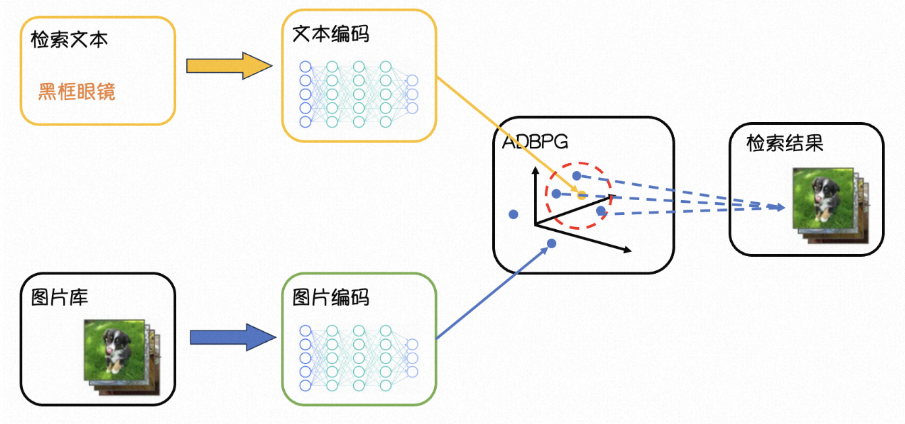
为了建立图像和自然语言的联系,本解决方案采用CLIP模型对文本图片编码。CLIP模型是一种基于自然语言处理和计算机视觉的神经网络模型,可以同时理解文本和图像,并在二者之间建立联系。
在以文搜图方案中,CLIP模型作用主要是文本和图像的匹配。CLIP模型可以将文本和图像进行编码,并计算它们之间的相似度。该相似度可以用来评估一个图像是否与输入的文本描述相匹配。在以文搜图中,用户可以输入文本描述,CLIP模型自动匹配相关的图像。
本解决⽅案将基于AnalyticDB PostgreSQL版的向量检索引擎,实现⽂本向量到图⽚向量的快速检索。
向量数据集,表结构如下:
CREATE TABLE IF NOT EXISTS public.text_search_graphic ( id INTEGER NOT NULL, path TEXT, image_vector REAL[], PRIMARY KEY(id) ) DISTRIBUTED BY(id); ALTER TABLE public.text_search_graphic ALTER COLUMN image_vector SET STORAGE PLAIN;向量索引结构如下:
CREATE INDEX ON public.text_search_graphic USING ann (image_vector) WITH (dim = '1000', hnsw_m = '100', pq_enable='0');使⽤如下SQL语句完成对⽂本向量的最近邻查询:
SELECT id, path, l2_distance({image_vector}, Array{text_embedding}::real[]) AS similarity FROM public.text_search_graphic ORDER BY {image_vector} <-> Array{text_embedding}::real[] LIMIT {top_k};其中
image_vector为存储向量数据的列名,text_embedding为 ⽂本的编码向量。l2_distance函数计算图像向量与⽂本描述向量的欧式距离,并重命名为similarity列。该SQL按照图像向量与⽂本描述向量的距离进⾏排序,以便将相似的图像放在前 ⾯,并返回最相似的top_k张图像。