
工具精选策略通过重排序与可选的查询改写,在请求发送至大语言模型前对工具列表进行预处理和筛选,可提升大规模工具集场景下的响应速度与选择精度,并降低Token成本。
适用场景
大规模工具集管理:当开发者构建包含数十或上百个工具的复杂Agent时,需确保模型能够高效且准确地进行工具选择。
多轮对话中的意图识别挑战:在连续多轮对话中,用户的核心意图可能分布在历史对话内容中,若仅依据最新输入进行工具匹配,可能导致选择偏差。
Token限制下的优化需求:当所有工具的名称与描述(不含参数)总长度超出Rerank模型的输入Token限制时,需采用有效的筛选或排序策略以保障功能正常运行。
方案说明
工具精选在API请求被转发至后端大语言模型服务前执行。其工作流如下:
请求接收:AI网关接收包含查询和原始工具列表的API请求。
查询改写(可选):若启用,该模块分析对话上下文,对原始查询(Query)进行优化和重写,生成更明确的查询语句,以提升后续工具匹配的准确性。
工具精排:该模块接收(可能已被改写的)查询和完整的工具列表,使用Rerank模型计算每个工具与查询之间的相关性得分。
工具筛选:根据预设的筛选策略(如Top-N、Top-K),从排序后的工具列表中筛选出一个最优子集。相关性得分低于设定阈值的工具将被丢弃。
请求转发:AI网关将原始请求中的工具列表替换为筛选后的精简工具列表,然后将请求转发给后端的大语言模型。
此策略仅适用于工具信息位于请求体tools字段内的Function Calling请求。
性能表现
在Salesforce的开源数据集上,使用50/100/200/300/400/500个不同规模的工具集进行评测,结果表明:
准确性提升:经过查询改写(Query Rewrite)和工具精排(Reranker)后,工具及参数的选择准确性最高可提升6%。
响应速度提升:当工具集规模超过50个时,响应时间(RT)有显著下降。在500个工具的测试场景下,响应速度最高可提升7倍。
成本降低:Token消耗(费用)可降低4~6倍。
评测使用的模型:
大语言模型:
qwen3-235b-a22b-instruct-2507Rerank模型:
gte-rerank-v2查询改写模型:
qwen3-30b-a3b-instruct-2507
评测效果
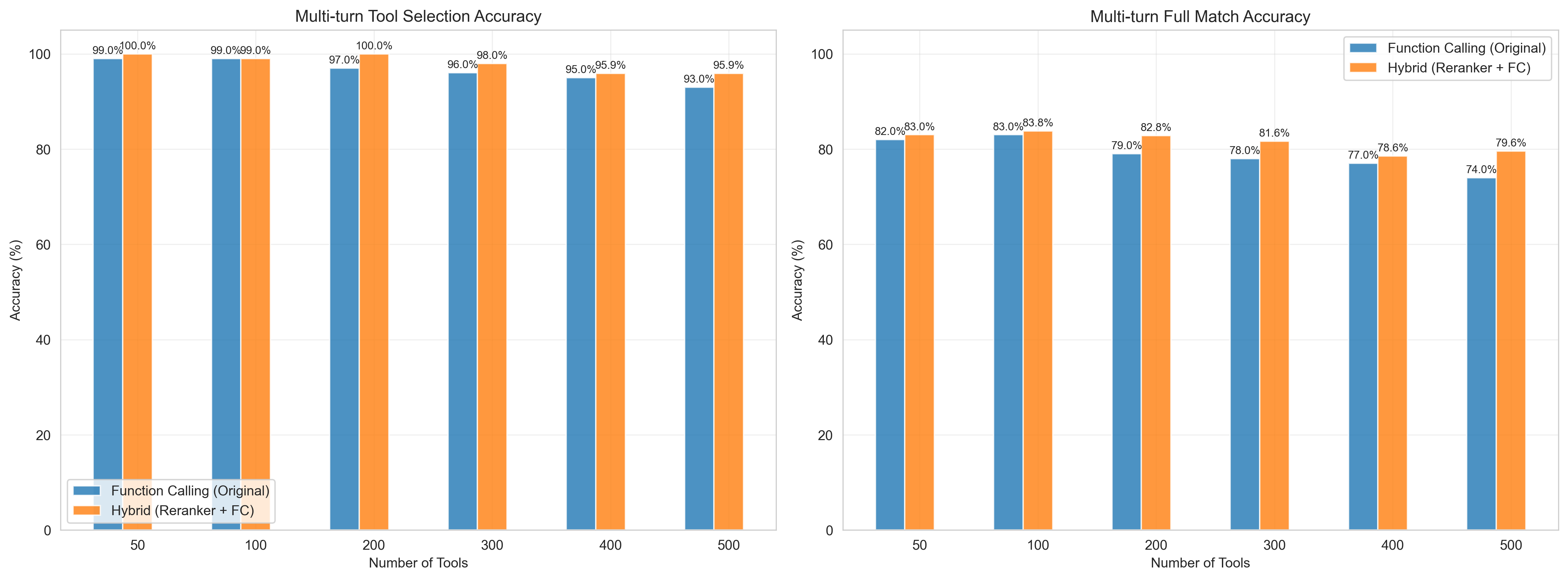
蓝色柱状图为直接使用模型Function Calling。
橙色柱状图为使用工具精选(查询改写 + Rerank + Function Calling)。
横坐标为工具数,纵坐标为准确率(%)。
左图为工具选用准确率,右图为工具选用+参数选用准确率。
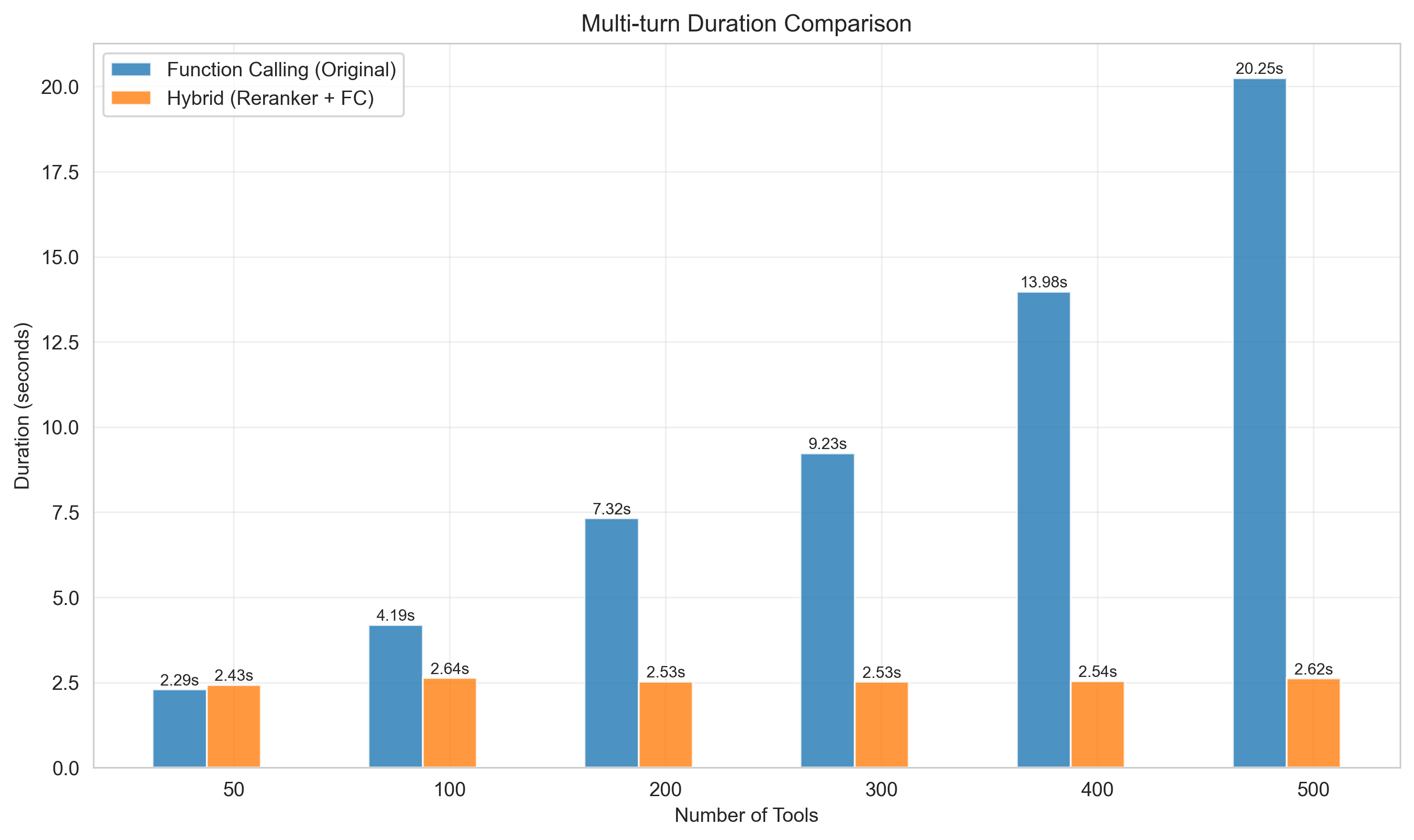
蓝色柱状图为直接使用模型Function Calling。
橙色柱状图为使用工具精选(查询改写 + Rerank + Function Calling)。
横坐标为工具数,纵坐标为单次调用耗时。
随着工具数量增加,采用工具精选的方案几乎不会增加耗时,而直接使用大模型的Function Calling耗时随工具数量增加而线性增加。
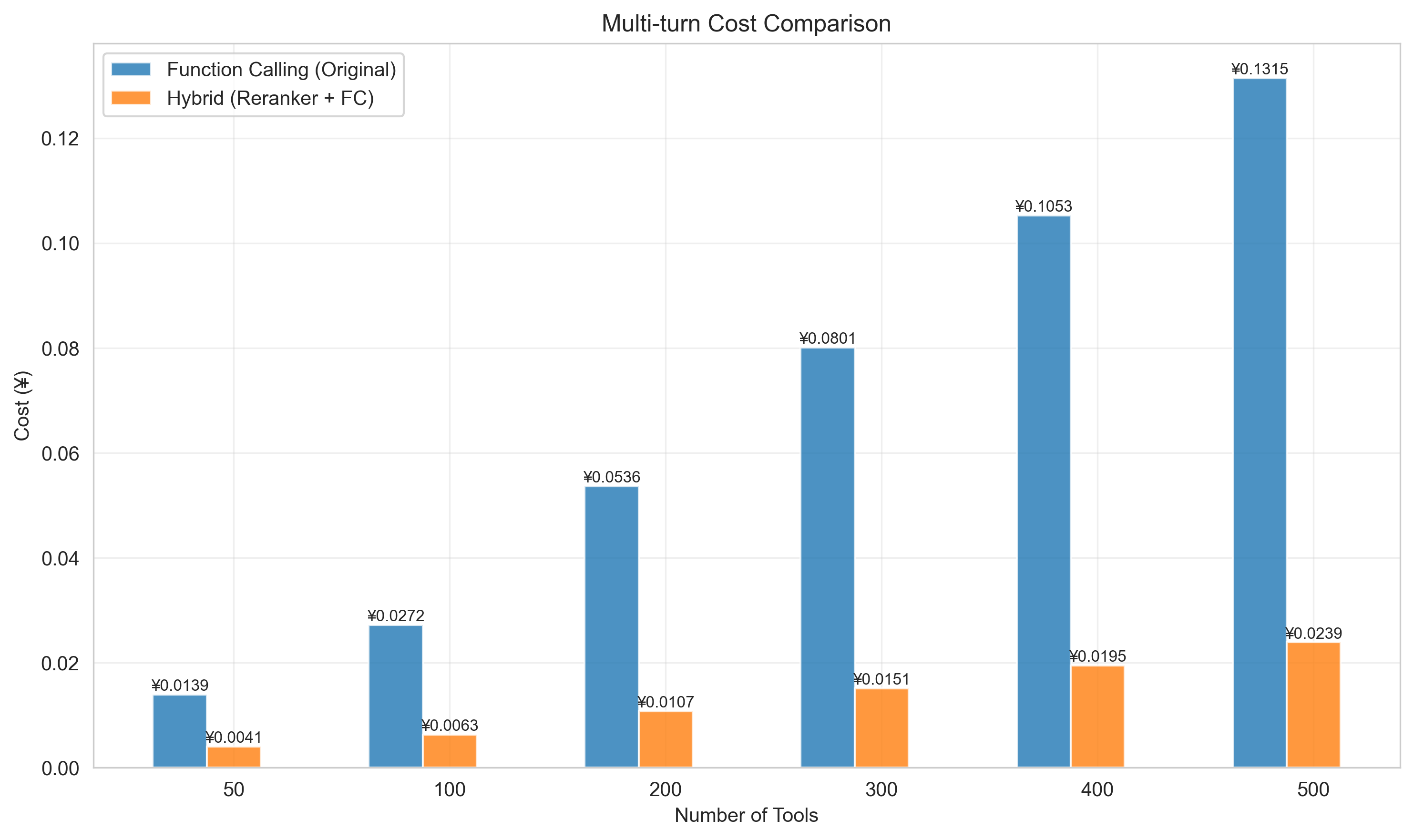
蓝色柱状图为直接使用模型Function Calling。
橙色柱状图为使用工具精选(查询改写 + Rerank + Function Calling)。
横坐标为工具数,纵坐标为每次工具调用的整体费用(以阿里云百炼标准进行Token计费)。
随着工具数量增加,使用工具精选方案并不会产生明显的Token费用提升,相比直接使用大模型Function Calling能节省大量费用。
操作步骤
前往AI 网关控制台实例页面,在顶部菜单栏选择目标实例所在地域,单击目标实例 ID。
在左侧导航栏,选择Model API,然后单击目标API名称进入API详情页面。
单击策略与插件,开启工具精选开关并完成配置,相关配置参考配置项说明。
确认配置信息并单击保存。
配置项说明
全局配置
配置项 | 说明 |
启用工具精选 | 工具精排功能总开关。开启后相关配置生效。关闭后,网关将透传原始请求,不进行工具筛选。 |
触发条件 | 工具数量的最小阈值。当API请求中的工具数量大于或等于此阈值时,工具精排功能才会被激活。 |
工具精排
通过智能工具精选功能,在请求送达LLM之前对工具列表进行预处理和筛选,提升模型响应速度、提高工具选择精确性并降低API调用成本。
配置项 | 说明 |
Rerank 模型服务 |
|
筛选方式 |
|
相关性得分阈值 | 范围0.0~1.0。Rerank得分低于此阈值的工具将被丢弃,即使它在Top-K/N范围内。0表示禁用此功能。 |
失败处理策略 | 当精排模型调用失败时的处理方式:• 跳过精排,使用原始工具• 中断请求并报错 |
查询改写
适用于多轮对话,在工具精排前,汇总多轮对话摘要,优化用户查询,以提升精排准确率。建议多轮对话场景中开启。
配置项 | 说明 |
启用查询改写 | 是否启用此增强功能。 |
改写模型服务 |
|
改写提示词 | 可选用内置优化过的Prompt模板,或自定义Prompt。 |
最大输出Token | 控制改写后查询的最大长度。 |
触发条件 | 对话轮次超过此数值时启用查询改写。设置为0表示禁用此条件。 |
上下文选择 | 定义用于改写的上下文范围。 |
失败处理策略 | 当改写模型调用失败时的处理方式:
|
常见问题
问题一:“工具精排”功能相比传统的向量检索有什么优势?为什么它更精准?
两者的核心区别在于信息处理的方式,这直接决定了其精确度的差异。
传统向量检索(不够精准):此方法通常先将“用户查询”和“工具描述”分开、独立地转换成数学向量(Embedding),然后再计算这些向量之间的相似度来排序。局限性:这个过程是“隔离”的,查询和工具之间缺乏深度的交互。这就像是通过比较两本书的摘要来判断它们是否相关,很多细节、上下文和复杂的逻辑关系会丢失,导致对用户真实意图的理解不够深入。
AI网关工具精选的Rerank交叉编码器(更精准): Rerank模型采用了一种更先进的架构。不会分开处理,而是将“用户查询”和“工具描述”配对拼接在一起,作为一个整体输入给模型进行分析。优势:这种方式实现了“深度交互”。模型可以直接、细致地分析查询中的每个词与工具描述中每个词的关联。这就像是把两本书并排放在一起逐页对比阅读,能够捕捉到复杂的意图、否定关系和特定条件。结果:因此,Rerank的判断标准从“语义上是否相似”跃升到了“功能上是否真正匹配”,能够更精准地理解用户的任务需求,从而筛选出最合适的工具。
问题二:查询改写(Query Rewriting)功能推荐开启吗?有什么副作用?
在多轮对话的业务场景下,强烈推荐开启。
收益:查询改写能将依赖上下文的模糊、简洁的用户问题,转化为一个信息完整的独立查询,极大地提升后续工具精排(Reranking)和最终LLM选择工具的准确性。
副作用:会引入一次额外的模型调用,因此会带来轻微的响应耗时增加。但对于多轮对话场景,增加的耗时换来的准确性提升通常是完全值得的。如果应用场景均为单轮对话,则可以关闭此功能。
问题3:遇到不符合预期的工具选择结果,应如何解决?
可以从以下几个方面进行排查和优化:
优化工具描述:确保每个工具的名称(name)和描述(description)清晰、准确且具有区分度。Rerank模型和LLM都强依赖这部分信息来理解工具的功能。
自定义查询改写提示词:如果内置的改写逻辑不完全符合业务需求,可以尝试使用自定义Prompt,设计更贴合场景的改写策略,指导改写模型生成更精准的查询。
调整筛选参数:根据实际情况调整Top-N/Top-K的数值。如果发现正确的工具经常被过滤掉,可以适当调高该值;如果总是引入不相关的工具,可以适当调低。
调整相关性得分阈值:适当提高相关性得分阈值(如设置为0.3),可以过滤掉相关性不高的工具,进一步提升工具列表的“信噪比”。