
云消息队列 Kafka 版可以作为Output接入Filebeat。本文说明如何在VPC环境下通过Filebeat向云消息队列 Kafka 版发送消息。
前提条件
在开始本教程前,请确保您已完成以下操作:
购买并部署云消息队列 Kafka 版实例。本文以非Serverless实例为例进行说明,具体操作请参见VPC接入。
下载并安装Filebeat。更多信息,请参见Download Filebeat。
下载并安装JDK 8。更多信息,请参见Download JDK 8。
步骤一:获取接入点
Filebeat通过云消息队列 Kafka 版的接入点与云消息队列 Kafka 版建立连接。
在概览页面的资源分布区域,选择地域。
在实例列表页面,单击作为Output接入Filebeat的实例名称。
在实例详情页面的接入点信息区域,获取实例的接入点。在配置信息区域,获取用户名与密码。
 说明
说明不同接入点的差异,请参见接入点对比。
步骤二:创建Topic
创建用于存储消息的Topic。
在概览页面的资源分布区域,选择地域。
重要Topic需要在应用程序所在的地域(即所部署的ECS的所在地域)进行创建。Topic不能跨地域使用。例如Topic创建在华北2(北京)这个地域,那么消息生产端和消费端也必须运行在华北2(北京)的ECS。
在实例列表页面,单击目标实例名称。
在左侧导航栏,单击Topic 管理。
在Topic 管理页面,单击创建 Topic。
在创建 Topic面板,设置Topic属性,然后单击确定。
参数
说明
示例
名称
Topic名称。
demo
描述
Topic的简单描述。
demo test
分区数
Topic的分区数量。
12
存储引擎
说明当前仅非Serverless专业版实例支持选择存储引擎类型,其他实例暂不支持选择,默认为云存储类型。
Topic消息的存储引擎。
云消息队列 Kafka 版支持以下两种存储引擎。
云存储:底层接入阿里云云盘,具有低时延、高性能、持久性、高可靠等特点,采用分布式3副本机制。实例的规格类型为标准版(高写版)时,存储引擎只能为云存储。
Local 存储:使用原生Kafka的ISR复制算法,采用分布式3副本机制。
云存储
消息类型
Topic消息的类型。
普通消息:默认情况下,保证相同Key的消息分布在同一个分区中,且分区内消息按照发送顺序存储。集群中出现机器宕机时,可能会造成消息乱序。当存储引擎选择云存储时,默认选择普通消息。
分区顺序消息:默认情况下,保证相同Key的消息分布在同一个分区中,且分区内消息按照发送顺序存储。集群中出现机器宕机时,仍然保证分区内按照发送顺序存储。但是会出现部分分区发送消息失败,等到分区恢复后即可恢复正常。当存储引擎选择Local 存储时,默认选择分区顺序消息。
普通消息
日志清理策略
Topic日志的清理策略。
当存储引擎选择Local 存储(当前仅专业版实例支持选择存储引擎类型为Local存储,标准版暂不支持)时,需要配置日志清理策略。
云消息队列 Kafka 版支持以下两种日志清理策略。
Delete:默认的消息清理策略。在磁盘容量充足的情况下,保留在最长保留时间范围内的消息;在磁盘容量不足时(一般磁盘使用率超过85%视为不足),将提前删除旧消息,以保证服务可用性。
Compact:使用Kafka Log Compaction日志清理策略。Log Compaction清理策略保证相同Key的消息,最新的value值一定会被保留。主要适用于系统宕机后恢复状态,系统重启后重新加载缓存等场景。例如,在使用Kafka Connect或Confluent Schema Registry时,需要使用Kafka Compact Topic存储系统状态信息或配置信息。
重要Compact Topic一般只用在某些生态组件中,例如Kafka Connect或Confluent Schema Registry,其他情况的消息收发请勿为Topic设置该属性。具体信息,请参见云消息队列 Kafka 版Demo库。
Compact
标签
Topic的标签。
demo
创建完成后,在Topic 管理页面的列表中显示已创建的Topic。
步骤三:Filebeat发送消息
在安装了Filebeat的机器上启动Filebeat,向创建的Topic发送消息。
执行cd命令切换到Filebeat的安装目录。
创建output.conf配置文件。
执行命令
vim output.conf创建空的配置文件。按i键进入插入模式。
输入以下内容。
filebeat.inputs: - type: stdin output.kafka: hosts: ["alikafka-pre-cn-zv**********-1-vpc.alikafka.aliyuncs.com:9092", "alikafka-pre-cn-zv**********-2-vpc.alikafka.aliyuncs.com:9092", "alikafka-pre-cn-zv**********-3-vpc.alikafka.aliyuncs.com:9092"] topic: 'filebeat_test' required_acks: 1 compression: none max_message_bytes: 1000000参数
描述
示例值
hosts
云消息队列 Kafka 版提供以下VPC接入点:
默认接入点
SASL接入点
alikafka-pre-cn-zv**********-1-vpc.alikafka.aliyuncs.com:9092,alikafka-pre-cn-zv**********-2-vpc.alikafka.aliyuncs.com:9092,alikafka-pre-cn-zv**********-3-vpc.alikafka.aliyuncs.com:9092
topic
Topic的名称。
filebeat_test
required_acks
ACK可靠性。取值:
0:无响应
1:等待本地提交
-1:等待所有副本提交
默认值为1。
1
compression
数据压缩编码器。默认值为gzip。取值:
none:无
snappy:用来压缩和解压缩的C++开发包
lz4:着重于压缩和解压缩速度的无损数据压缩算法
gzip:GNU自由软件的文件压缩程序
none
max_message_bytes
最大消息大小。单位为字节。默认值为1000000。该值应小于您配置的云消息队列 Kafka 版最大消息大小。
1000000
更多参数说明,请参见Kafka output plugin。
按Esc键回到命令行模式。
按:键进入底行模式,输入wq,然后按回车键保存文件并退出。
向创建的Topic发送消息。
执行
./filebeat -c ./output.yml。输入test,然后按回车键。
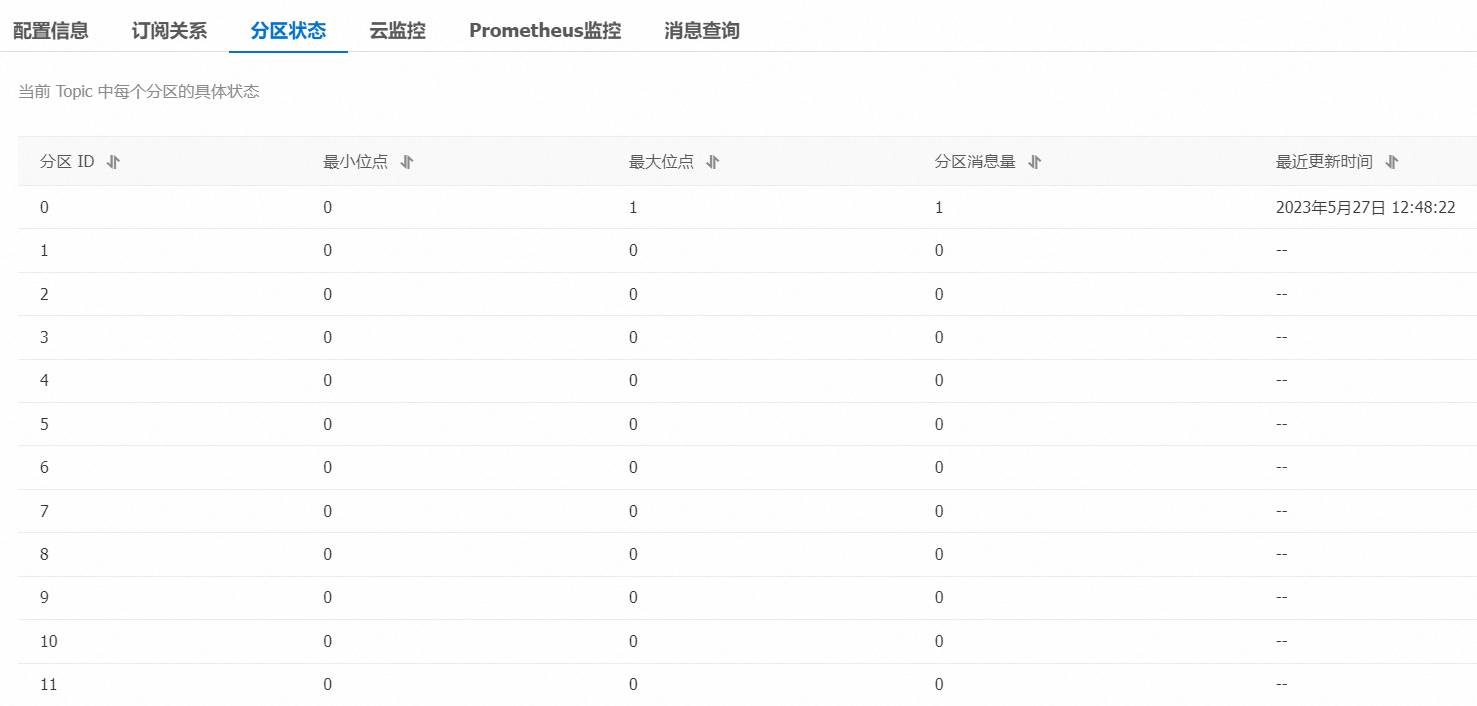
步骤四:查看Topic分区
查看消息发送到Topic的情况。
在概览页面的资源分布区域,选择地域。
在实例列表页面,单击目标实例名称。
在左侧导航栏,单击Topic 管理。
在Topic 管理页面,单击目标Topic名称进入Topic 详情页面,然后单击分区状态页签。
表 1. 分区状态信息
参数
说明
分区ID
该Topic分区的ID号。
最小位点
该Topic在当前分区下的最小消费位点。
最大位点
该Topic在当前分区下的最大消费位点。
分区消息量
该Topic在当前分区下的消息总量。
最近更新时间
本分区中最近一条消息的存储时间。
步骤五:按位点查询消息
您可以根据发送的消息的分区ID和位点信息查询该消息。
在概览页面的资源分布区域,选择地域。
在实例列表页面,单击目标实例名称。
在左侧导航栏,单击消息查询。
在消息查询页面的查询方式列表中,选择按位点查询。
在Topic列表中,选择消息所属Topic名称;在分区列表中,选择消息所属的分区;在起始位点文本框,输入消息所在分区的位点,然后单击查询。
展示该查询位点及以后连续的消息。例如,指定的分区和位点都为“5”,那么返回的结果从位点“5”开始。
表 2. 查询结果参数解释
参数
描述
分区
消息的Topic分区。
位点
消息的所在的位点。
Key
消息的键(已强制转化为String类型)。
Value
消息的值(已强制转化为String类型),即消息的具体内容。
消息创建时间
发送消息时,客户端自带的或是您指定的
ProducerRecord中的消息创建时间。说明如果配置了该字段,则按配置值显示。
如果未配置该字段,则默认取消息发送时的系统时间。
如果显示值为1970/x/x x:x:x,则说明发送时间配置为0或其他有误的值。
0.9及以前版本的云消息队列 Kafka 版客户端不支持配置该时间。
操作
单击下载 Key:下载消息的键值。
单击下载 Value:下载消息的具体内容。
重要查询到的每条消息在控制台上最多显示1 KB的内容,超过1 KB的部分将自动截断。如需查看完整的消息内容,请下载相应的消息。
下载的消息最大为10 MB。如果消息超过10 MB,则只下载10 MB的内容。