
开源RabbitMQ迁移上云
在使用开源RabbitMQ集群时,当您希望能够解决各种稳定性痛点(例如消息堆积、脑裂等问题)、实现高并发、分布式、灵活扩缩容时,您可以将开源RabbitMQ集群迁移至云消息队列 RabbitMQ 版,本文介绍迁移上云的前提条件、操作步骤、注意事项等。
迁移前须知
云消息队列 RabbitMQ 版是阿里云基于专有的分布式消息存储技术开发的高级消息队列服务。它严格遵循AMQP 0-9-1协议,但并不是开源RabbitMQ的简单托管版本。云消息队列 RabbitMQ 版的架构有效避免了因消息积压导致的内存泄漏和服务器故障等稳定性问题,并成功解决了分布式系统中的脑裂难题。此外,它还提供了高度的可伸缩性和灵活的按量计费模式,进一步增强了服务的弹性、降低了成本。
然而,与开源RabbitMQ相比,云消息队列 RabbitMQ 版在某些功能实现上存在差异。因此,在考虑迁移至云消息队列 RabbitMQ 版之前,您需要进行技术能力和成本效益评估,以确保选型符合您的需求。
迁移前评估
技术评估
费用评估
云消息队列 RabbitMQ 版提供了预付费系列实例和Serverless系列实例,涵盖多种实例规格。不同实例规格间的差异,请参见实例类型。
相比预付费系列实例,Serverless系列实例具备更好的弹性能力和费用优势。计费规则,请参见Serverless系列计费说明。
开源RabbitMQ集群的消息收发次数、Queue数量及消息量可通过如下途径评估。
Queue数量:在开源RabbitMQ控制台上的Overview页面查看Global counts,获取Queues、Exchanges等各个元数据的数量。
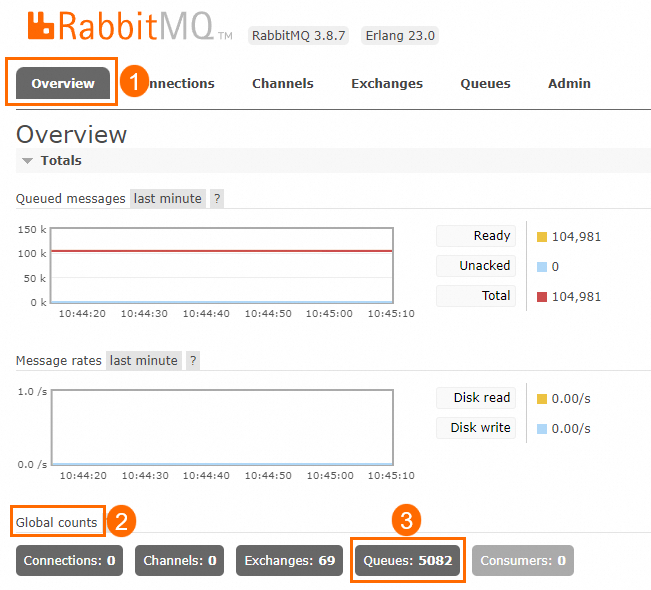
消息收发次数、消息量:
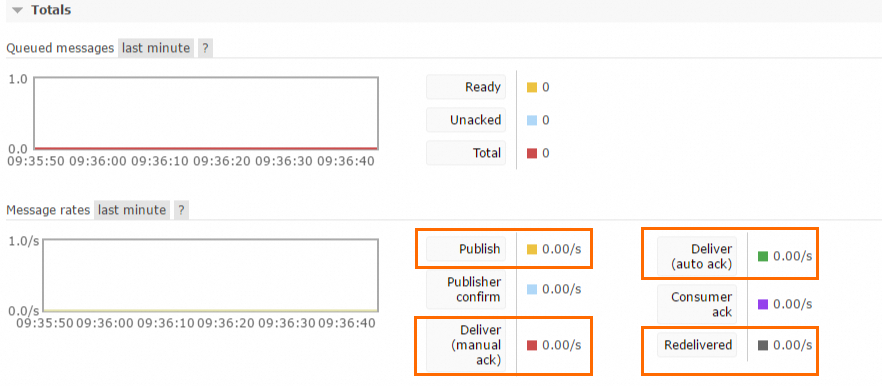
方法一:在开源RabbitMQ控制台上的Overview页面查看Message rates,计算Publish、Deliver(manual ack)/Deliver (auto ack)、Redelivered指标的总和。
方法二:通过Prometheus Grafana大盘查看集群总的消息写入和消息流出的QPS和消息量。
迁移上云
迁移元数据
迁移元数据是指将开源RabbitMQ集群的元数据导出,并将其导入到阿里云云消息队列 RabbitMQ 版实例。云消息队列 RabbitMQ 版会根据成功导入的元数据在目标云消息队列 RabbitMQ 版实例中创建对应的Vhost、Queue、Exchange、Binding,实现RabbitMQ集群元数据迁移上云。详细步骤,请参见迁移元数据上云。
创建用户名
开源客户端访问云消息队列 RabbitMQ 版服务端时,需要传入用户名和密码进行权限认证,认证通过才允许访问服务端。云消息队列 RabbitMQ 版支持以下两种身份权限管理模式,详情请参见用户和权限管理。
开源身份验证和权限管理方式
支持创建自定义用户名和密码,同时支持权限的元数据导入。
阿里云访问控制(RAM)
用户名和密码可通过阿里云访问控制(RAM)的AccessKey和AccessKey Secret生成。
打通网络
云消息队列 RabbitMQ 版提供私网连接接入点,使用私网连接接入点能够支持云企业网(CEN)上云组网,详情请参见私网连接接入点。
如果选用开源身份验证和权限管理方式,且已使用私网连接接入点,则跳过此步骤。
迁移消息数据
迁移方案
以VirtualHost为最小迁移单位,通过连接配置切换、RabbitMQ Shovel插件消息迁移的方式,实现消息数据平滑上云。
方案优势
平滑迁移业务。
保证数据不丢失。
无需梳理应用间调用的网状拓扑结构。
方案步骤
请根据业务场景的不同,选择对应的消息迁移步骤:
业务不可中断:
允许停机维护:若业务具备维护窗口,可容忍短时停机,请参考场景四。
场景一:业务不中断平滑迁移(队列的生产者和消费者集成在同一应用服务中)

选择少量服务节点进行灰度发布,将其 RabbitMQ 客户端配置切换至云上实例。验证以下关键点:
生产者能否正常向云上队列发送消息;
消费者能否正确消费云上队列中的消息;
业务链路端到端功能与性能是否符合预期;
在确认灰度节点运行正常后,在自建 RabbitMQ 集群上配置并启用 Shovel 插件,将指定 VirtualHost 下各队列中尚未消费的历史堆积消息迁移至云上 RabbitMQ 对应队列。
将 RabbitMQ 连接配置全面切换至云上实例,并对所有服务节点执行滚动发布。此时:
所有新产生的消息直接写入云上队列;
所有消费者从云上队列消费消息;
自建集群不再接收新消息,仅作为 Shovel 的源端提供剩余堆积消息。
观察自建集群队列的消息堆积在减少,当自建集群队列没有堆积后,停止Shovel任务。
VirtualHost下队列的堆积情况可以在自建RabbitMQ集群的管控页面上查看,当队列的可消费消息和未确认的消息数量都为0时,说明已经没有堆积。
 重要
重要若代码中向 x-delayed-message 类型的交换机发送了延迟消息,则这些消息在延迟期结束前不会进入队列,也不会计入队列堆积量。因此,在停止 Shovel 任务前,需确保等待时间至少覆盖当前时间加上最大延迟时长,以避免遗漏尚未投递的延迟消息。
场景二:业务不中断平滑迁移(队列的生产者和消费者分布在独立的多个应用服务中)

在自建 RabbitMQ 集群上配置并启用 Shovel 插件,将目标 VirtualHost 下所有待迁移队列中的现有堆积消息迁移到云上对应队列;
启动云上 RabbitMQ 实例的消费者服务,使其开始从云上队列拉取消息;
观察云上消费者工作正常后,停止自建集群消费者服务;
启动云上 RabbitMQ 实例的生产者服务,验证新消息是否成功发布至云上队列,并通过消费者端确认端到端链路畅通;
在确认新消息已稳定流入云上队列且被正常消费后,停止自建集群上的生产者服务;
此时新消息直接进入云上队列,而 Shovel 会继续搬运完自建集群队列中剩余的消息;
观察自建集群队列的消息堆积在减少,当自建集群队列没有堆积后,停止Shovel任务。
场景三:业务不中断平滑迁移(自建 RabbitMQ 集群有运行 Shovel 任务)

停止自建集群生产者服务和消费者服务,并修改服务中的rabbitmq配置,指向云上RabbitMQ实例;
启动云上实例生产者服务和消费者服务,观察生产者和消费者工作正常;
在自建集群上配置新的 Shovel 任务(记为 Shovel A),将 VirtualHost A 下所有相关队列的当前堆积消息迁移至云上 RabbitMQ 对应队列;
暂停自建集群中原有的 VirtualHost B到VirtualHost A 的 Shovel 任务(Shovel B),修改 Shovel B 的目标地址,将其直接指向云上 RabbitMQ 实例的对应队列,重新启用 Shovel B;
观察自建集群VirtualHost B下队列的消息堆积在减少,待没有堆积后,删除Shovel B任务;
观察自建集群VirtualHost A下队列的消息堆积在减少,待没有堆积后,删除Shovel A任务。
场景四:业务停机迁移

停止自建集群生产者服务和消费者服务;
修改服务中的rabbitmq配置,指向云上RabbitMQ实例;
启动云上实例生产者和消费者服务,观察生产者和消费者工作正常;
在自建 RabbitMQ 集群上配置并启用 Shovel 插件,将停机时各队列中的全部剩余消息逐条迁移至云上对应队列;
观察自建集群队列的消息堆积在减少,当自建集群队列没有堆积后,停止Shovel。
如何使用Shovel
登录自建集群,在命令行中执行以下命令为自建RabbitMQ集群启动Shovel插件。
rabbitmq-plugins enable rabbitmq_shovel rabbitmq_shovel_management
登录自建RabbitMQ集群控制台,在顶部菜单栏单击Admin,然后单击右侧的Shovel Management,在Add a new shovel区域设置Source和Destination,单击Add shovel。
Source配置格式:URI填写
amqp://{username}:{password}@{ip}:{port}/{vhost}。其中,username和password为用户名密码,ip为自建集群所在IP地址,port为通信端口,通常为5672,vhost为队列所在vhost。Destination配置格式:URI填写
amqp://{username}:{password}@{endpoint}:{port}/{vhost}。其中,username和password为在云消息队列 RabbitMQ 版控制台上创建的静态用户名密码,endpoint为云消息队列 RabbitMQ 版的接入点地址,port为5672,vhost为队列所在vhost。

Shovel添加成功后,在Shovel Status页面中查看Shovel任务状态,State显示为running,说明Shovel任务启动成功。

待自建RabbitMQ集群的队列里没有消息堆积后,删除Shovel任务。

相关文档
更多关于Shovel插件的信息,请参见Shovel Plugin。