本文汇总了云数据库ClickHouse的常见问题及解决方案。
选型与购买
扩容与缩容
连接
迁移与同步
数据写入与查询
数据存储
监控、升级、系统参数
其他
云数据库ClickHouse和官方版本对比多了哪些功能和特性?
云数据库ClickHouse主要对社区版本进行稳定性Bug修复,同时提供资源队列进行用户角色级别的资源使用优先级配置。
购买云数据库ClickHouse实例时,推荐选择哪一个版本?
云数据库ClickHouse根据开源社区公开的LTS内核稳定版提供服务,通常在版本推出3个月相对稳定后启动云服务售卖。当前建议购买21.8及以上版本。更多版本功能对比,请参见版本功能对比。
单双副本实例各有什么特点?
单副本实例每一个Shard节点无副本节点,无高可用服务保障。数据安全性基于云盘多副本存储,性价比高。
双副本实例每一个Shard节点对应一个副本服务节点,在主节点故障不能提供服务时副本节点可提供容灾服务支持。
购买链路资源时显示“当前区域资源不足”,应该如何处理?
解决方案:您可以选择同地域的其他区域购买。VPC网络支持相同区域不同可用区之间打通,同区域网络延迟无感知。
水平扩缩容耗时受什么影响?
水平扩缩容过程涉及数据搬迁,实例里面数据越多搬得越多,耗时时间越长。
扩缩容期间对实例有什么影响?
为保证扩缩容中数据搬迁后的数据一致性,扩缩容期间实例处于可读不可写状态。
水平扩缩容升级有什么建议?
水平扩缩容耗时较长,当集群性能不满足时,请优先选择垂直升配。如何进行垂直升配,请参见社区兼容版集群垂直变配和水平扩缩容。
每个端口的含义是什么?
版本支持 | 协议 | 端口号 | 适用场景 |
社区兼容版/企业版 | TCP | 3306 | 使用clickhouse-client工具连接云数据库ClickHouse时配置,详细操作请参见通过命令行工具连接ClickHouse。 |
社区兼容版/企业版 | HTTP | 8123 | 使用JDBC方式连接云数据库ClickHouse进行应用开发时配置,详细操作请参见通过JDBC方式连接ClickHouse。 |
社区兼容版 | MySQL | 9004 | 使用MySQL协议连接云数据库ClickHouse时配置,详细操作请参见通过MySQL协议连接ClickHouse。 |
社区兼容版/企业版 | HTTPS | 8443 | 使用HTTPS协议访问云数据库ClickHouse时配置,详细操作请参见通过HTTPS协议连接ClickHouse。 |
每种开发语言通过SDK连接云数据库ClickHouse对应的端口是什么?
开发语言 | HTTP协议 | TCP协议 |
Java | 8123 | 3306 |
Python | ||
Go |
Go、Python语言对应推荐什么SDK?
详情请参见第三方开发库。
如何处理客户端工具连接集群时报错:connect timed out?
为什么MySQL、HDFS、Kafka等外表无法连通?
目前20.3和20.8版本在创建相关外表时程序内会自动进行验证,如果创建表成功,那说明网络是通的。如果无法创建成功,常见原因如下。
目标端和ClickHouse不在同一个VPC内,网络无法连通。
MySQL端存在白名单相关设置,需要在MySQL端添加ClickHouse的白名单。
对于Kafka外表,表创建成功,但查询没有结果。常见原因是Kafka中数据通过表结构给出的字段和格式解析失败,报错信息会给出解析失败的具体位置。
为什么程序无法连接ClickHouse?
常见原因及解决方案如下。
常见原因1:VPC网络、公网网络环境不对。同一VPC内可用内网连接,不在同一VPC内需开设公网后连接。
解决方案:开通公网详情请参见申请和释放外网地址。
常见原因2:白名单未配置。
解决方案:设置白名单详情请参见设置白名单。
常见原因3:ECS安全组未放开。
解决方案:开放安全组详情请参见安全组操作指引。
常见原因4:公司设置了网络防火墙。
解决方案:修改防火墙规则。
常见原因5:连接串中的账号密码包含特殊字符
!@#$%^&*()_+=,这些特殊字符在连接时无法被识别,导致实例连接失败。解决办法:您需要在连接串中对特殊字符进行转义处理,转义规则如下。
! : %21 @ : %40 # : %23 $ : %24 % : %25 ^ : %5e & : %26 * : %2a ( : %28 ) : %29 _ : %5f + : %2b = : %3d示例:密码为
ab@#c时,在连接串中对特殊字符进行转义处理,密码对应为ab%40%23c。常见原因6:云数据库ClickHouse会默认为您挂载CLB。CLB为按量付费,如果您的账号欠费可能会导致您的云数据库ClickHouse无法访问。
解决办法:查询阿里云账号是否欠费。如果欠费请及时进行缴费,阿里云账户查询详情请参见资金账户查询入口。
如何处理ClickHouse超时问题?
云数据库ClickHouse内核中有很多超时相关的参数设置,并且提供了多种协议进行交互,例如您可以设置HTTP协议和TCP协议的相关参数处理云数据库ClickHouse超时问题。
HTTP协议
HTTP协议是云数据库ClickHouse在生产环境中最常使用的交互方式,包括官方提供的jdbc driver、阿里云DMS、DataGrip,后台使用的都是HTTP协议。HTTP协议常用的端口号为8123。
如何处理distributed_ddl_task_timeout超时问题
分布式DDL查询(带有 on cluster)的执行等待时间,系统默认是180s。您可以在DMS上执行以下命令来设置全局参数,设置后需要重启集群。
set global on cluster default distributed_ddl_task_timeout = 1800;由于分布式DDL是基于ZooKeeper构建任务队列异步执行,执行等待超时并不代表查询失败,只表示之前发送还在排队等待执行,用户不需要重复发送任务。
如何处理max_execution_time超时问题
一般查询的执行超时时间,DMS平台上默认设置是7200s,jdbc driver、DataGrip上默认是30s。超时限制触发之后查询会自动取消。用户可以进行查询级别更改,例如
select * from system.numbers settings max_execution_time = 3600,也可以在DMS上执行以下命令来设置全局参数。set global on cluster default max_execution_time = 3600;
如何处理socket_timeout超时问题
HTTP协议在监听socket返回结果时的等待时间,DMS平台上默认设置是7200s,jdbc driver、DataGrip上默认是30s。该参数不是Clickhouse系统内的参数,它属于jdbc在HTTP协议上的参数,但它是会影响到前面的max_execution_time参数设置效果,因为它决定了客户端在等待结果返回上的时间限制。所以一般用户在调整max_execution_time参数的时候也需要配套调整socket_timeout参数,略微高于max_execution_time即可。用户设置参数时需要在jdbc链接串上添加socket_timeout这个property,单位是毫秒,例如:'jdbc:clickhouse://127.0.0.1:8123/default?socket_timeout=3600000'。
使用ClickHouse服务端IP直接链接时的Client异常hang住
阿里云上的ECS在跨安全组链接时,有可能陷入静默链接错误。具体原因是jdbc客户端所在ECS机器的安全组白名单并没有开放给ClickHouse服务端机器。当客户端的请求经过超长时间才得到查询结果时,返回的报文可能因为路由表不通无法发送到客户端。此时客户端就陷入了异常hang住状态。
该问题的处理办法和SLB链接异常断链问题一样,开启send_progress_in_http_headers可以解决大部分问题。在极少数情况下,开启send_progress_in_http_headers仍不能解决问题的,您可以尝试配置jdbc客户端所在ECS机器的安全组白名单,把ClickHouse服务端地址加入到白名单中。
TCP协议
TCP协议最常使用的场景是ClickHouse自带的命令行工具进行交互分析时,社区兼容版集群常见端口号为3306,企业版集群常见端口号为9000。因为TCP协议里有链接定时探活报文,所以它不会出现socket层面的超时问题。您只需关注distributed_ddl_task_timeout和max_execution_time参数的超时,设置方法和HTTP协议一致。
为什么OSS外表导入ORC、PARQUET等格式的数据,出现内存报错或OOM挂掉?
常见原因:内存使用率比较高。
您可以采取如下解决方案。
把OSS上的文件拆分为一个一个的小文件,然后再进行导入。
进行内存的升配。如何升配,请参见社区兼容版集群垂直变配和水平扩缩容。
如何处理导入数据报错:too many parts?
ClickHouse每次写入都会生成一个data part,如果每次写入一条或者少量的数据,那会造成ClickHouse内部有大量的data part(会给merge和查询造成很大的负担)。为了防止出现大量的data part,ClickHouse内部做了很多限制,这就是too many parts报错的内在原因。出现该错误,请增加写入的批量大小。如果无法调整批量大小,可以在控制台修改参数:merge_tree.parts_to_throw_insert,将参数的取值设置的大一些。
为什么DataX导入速度慢?
常见原因及解决方案如下。
常见原因1:参数设置不合理。ClickHouse适合使用大batch、少数几个并发进行写入。多数情况下batch可以高达几万甚至几十万(取决于您的单行RowSize大小,一般按照每行100Byte进行评估,您需要根据实际数据特征进行估算)。
解决方案:并发数建议不超过10个。您可以调整不同参数进行尝试。
常见原因2:DataWorks独享资源组的ECS规格太小。比如独享资源的CPU、Memory太小,导致并发数、网络出口带宽受限;或者是batch设置太大而Memory太小,引起DataWorks进程Java GC等。
解决方案:您可以通过DataWorks的输出日志对ECS规格大小进行确认。
常见原因3:从数据源中读取慢。
解决方案:您可以在DataWorks输出日志中搜索totalWaitReaderTime、totalWaitWriterTime,如果发现totalWaitReaderTime明显大于totalWaitWriterTime,则表明主要耗时在读取端,而不是写入端。
常见原因4:使用了公网Endpoint。公网Endpoint的带宽非常有限,无法承载高性能的数据导入导出。
解决方案:您需要替换为VPC网络的Endpoint。
常见原因5:有脏数据。在没有脏数据的情况下,数据以batch方式写入。但是遇到了脏数据,正在写入的batch就会失败,并回退到逐行写入,生成大量的data part,大幅度降低了写入速度。
您可以参考如下两种方式判断是否有脏数据。
查看报错信息,如果返回信息包含
Cannot parse,则存在脏数据。代码如下。
SELECT written_rows, written_bytes, query_duration_ms, event_time, exception FROM system.query_log WHERE event_time BETWEEN '2021-11-22 22:00:00' AND '2021-11-22 23:00:00' AND lowerUTF8(query) LIKE '%insert into <table_name>%' and type != 'QueryStart' and exception_code != 0 ORDER BY event_time DESC LIMIT 30;查看batch行数,如果batch行数变为1,则存在脏数据。
代码如下。
SELECT written_rows, written_bytes, query_duration_ms, event_time FROM system.query_log WHERE event_time BETWEEN '2021-11-22 22:00:00' AND '2021-11-22 23:00:00' AND lowerUTF8(query) LIKE '%insert into <table_name>%' and type != 'QueryStart' ORDER BY event_time DESC LIMIT 30;
解决方案:您需要在数据源删除或修改脏数据。
为什么Hive导入后其数据行数跟ClickHouse对不上?
您可以通过以下手段进行排查。
首先通过系统表query_log来查看导入的过程中是否有报错,如果有报错,那很有可能出现数据丢失的情况。
确定使用的表引擎是否可以去重,比如使用ReplacingMergeTree,那很可能出现ClickHouse中的Count小于Hive中的情况。
重新确认Hive中数据行数的正确性,很有可能出现源头的行数确定错误的情况。
为什么Kafka导入后其数据行数跟ClickHouse对不上?
您可以通过以下手段进行排查。
首先通过系统表query_log来查看导入的过程中是否有报错,如果有报错,那很有可能出现数据丢失的情况。
确定使用的表引擎是否可以去重,比如使用ReplacingMergeTree,那很可能出现ClickHouse中的Count小于Kafka中的情况。
查看Kafka外表的配置是否有kafka_skip_broken_messages参数的配置,如果有该参数,那可能会跳过解析失败的Kafka消息,导致ClickHouse总的行数是小于Kafka中的。
如何使用Spark、Flink导入数据?
如何使用Spark导入数据请参见从Spark导入。
如何使用Flink导入数据请参见从Flink SQL导入。
如何从现有ClickHouse导入数据到云数据库ClickHouse?
您可以采取如下方案。
通过ClickHouse Client以导出文件的形式进行数据迁移,详情请参见将自建ClickHouse数据迁移至云ClickHouse社区兼容版。
通过Remote函数进行数据的迁移。
INSERT INTO <目的表> SELECT * FROM remote('<连接串>', '<库>', '<表>', '<username>', '<password>');
使用MaterializeMySQL引擎同步MySQL数据时,为什么出现如下报错:The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires?
常见原因:MaterializeMySQL引擎停止同步的时间太久,导致MySQL Binlog日志过期被清理掉。
解决方案:删除报错的数据库,重新在云数据库ClickHouse中创建同步的数据库。
使用MaterializeMySQL引擎同步MySQL数据时,为什么出现表停止同步?为什么系统表system.materialize_mysql中sync_failed_tables字段不为空?
常见原因:同步过程中使用了云数据库ClickHouse不支持的MySQL DDL语句。
解决方案:重新同步MySQL数据,具体步骤如下。
删除停止同步的表。
DROP TABLE <table_name> ON cluster default;说明table_name为停止同步的表名。如果停止同步的表有分布式表,那么本地表和分布式表都需要删除。重启同步进程。
ALTER database <database_name> ON cluster default MODIFY SETTING skip_unsupported_tables = 1;说明<database_name>为云数据库ClickHouse中同步的数据库。
如何处理报错:“Too many partitions for single INSERT block (more than 100)”?
常见原因:单个INSERT操作中超过了max_partitions_per_insert_block(最大分区插入块,默认值为100)。ClickHouse每次写入都会生成一个data part(数据部分),一个分区可能包含一个或多个data part,如果单个INSERT操作中插入了太多分区的数据,那会造成ClickHouse内部有大量的data part(会给合并和查询造成很大的负担)。为了防止出现大量的data part,ClickHouse内部做了限制。
解决方案:请执行以下操作,调整分区数或者max_partitions_per_insert_block参数。
调整表结构,调整分区方式,或避免单次插入的不同分区数超过限制。
避免单次插入的不同分区数超过限制,可根据数据量适当修改max_partitions_per_insert_block参数,放大单个插入的不同分区数限制,修改语法如下:
单节点实例
SET GLOBAL max_partitions_per_insert_block = XXX;多节点实例
SET GLOBAL ON cluster DEFAULT max_partitions_per_insert_block = XXX;说明ClickHouse社区推荐默认值为100,分区数不要设置得过大,否则可能对性能产生影响。在批量导入数据后可修改值为默认值。
如何处理insert into select XXX内存超限报错?
常见原因及解决方案如下。
常见原因1:内存使用率比较高。
解决方案:调整参数max_insert_threads,减少可能的内存使用量。
常见原因2:当前是通过
insert into select把数据从一个ClickHouse集群导入到另外一个集群。解决方案:通过导入文件的方式来迁移数据,更多信息请参见将自建ClickHouse数据迁移至云ClickHouse社区兼容版。
如何查询CPU使用量和内存使用量?
您可以在system.query_log系统表里自助查看CPU和MEM在查询时的使用日志,里面有每个查询的CPU使用量和内存使用量统计。更多信息请参见system.query_log。
如何处理查询时内存超出限制?
ClickHouse服务端对所有查询线程都配有memory tracker,同一个查询下的所有线程tracker会汇报给一个memory tracker for query,再上层还是memory tracker for total。您可以根据情况采取如下解决方案。
遇到
Memory limit (for query)超限报错说明是查询内存占用过多(实例总内存的70%)导致失败,这种情况下您需要垂直升配提高实例内存规模。遇到
Memory limit (for total)超限报错说明是实例总内存使用超限(实例总内存的90%),这种情况下您可以尝试降低查询并发,如果仍然不行则可能是后台异步任务占用了比较大的内存(常常是写入后主键合并任务),您需要垂直升配提高实例内存规模。
为什么企业版执行SQL的时候报错memory limit?
原因分析:云数据库 ClickHouse 企业版集群的计算单元CCU(ClickHouse Compute Units)个数为多节点的CCU总个数,单节点的规格是32c128g,即32CCU,内存上限为128g(含操作系统,实际可用内存量约为115g)。单条SQL默认在单节点上执行,因此,当单条SQL内存消耗超过115g时可能会报错memory limit。
集群的节点个数仅与集群的CCU上限相关。当CCU上限大于64时,企业版集群的节点数计算公式为:CCU上限/32;当CCU上限小于64时,企业版集群的节点数为2。
解决方案:可以在SQL后面设置以下参数,让SQL在多节点上并行执行,可能会降低负载,避免内存超出限制。
SETTINGS
allow_experimental_analyzer = 1,
allow_experimental_parallel_reading_from_replicas = 1;当执行Group By操作且结果集较大时,导致内存消耗过大SQL报错如何解决?
可以设置 max_bytes_before_external_group_by 参数限制GROUP BY操作的内存消耗,需要注意,allow_experimental_analyzer 会影响此参数的生效。
如何处理查询报并发超限?
默认Server查询最大并发数为100,您可以在控制台上进行修改。修改运行参数值具体操作步骤如下。
在集群列表页面,选择社区版实例列表,单击目标集群ID。
单击左侧导航栏的参数配置。
在参数配置页面,单击max_concurrent_queries参数的运行参数值后面的编辑按钮。
在悬浮框中填写目标值,单击确定。
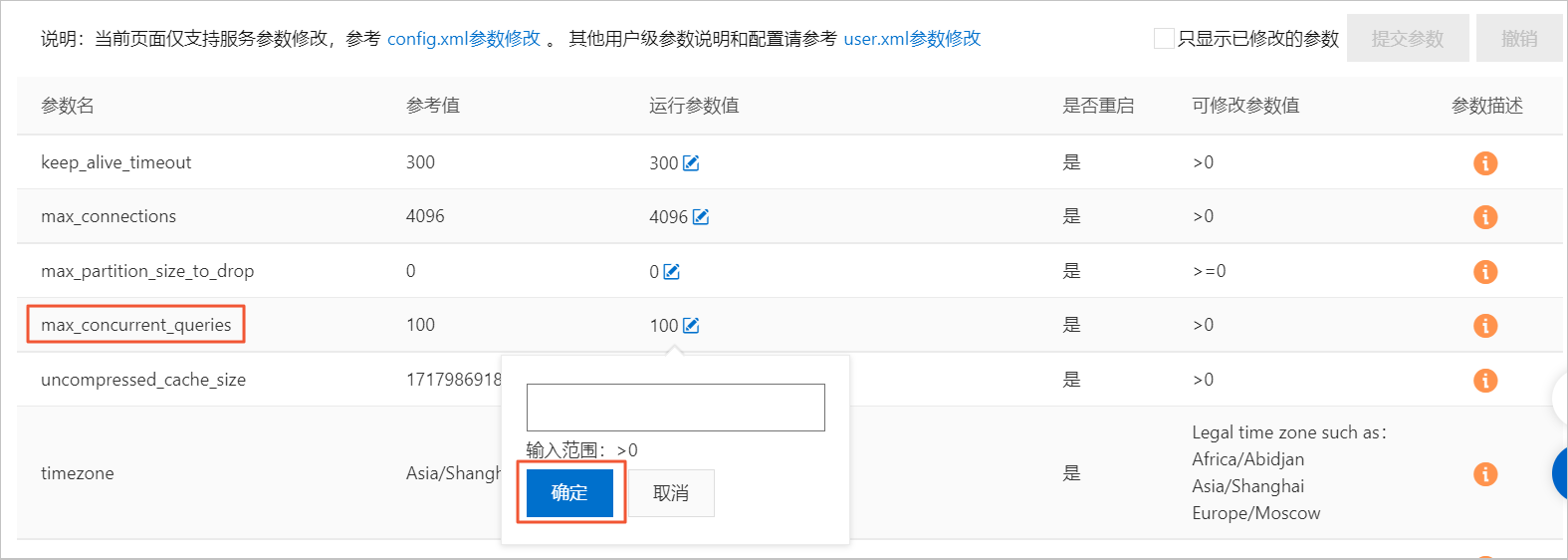
单击提交参数。
单击确定。
在数据停止写入时,同一个查询语句每次查询的结果不一致,应该如何处理?
问题详细描述:通过select count(*) 查询数据时只有整体数据的大概一半,或者数据一直在跳变。
为什么有时看不到已经创建好的表并且查询结果一直抖动时多时少?
常见原因及解决方案如下。
常见原因1:建表流程存在问题。ClickHouse的分布式集群搭建并没有原生的分布式DDL语义。如果您在自建ClickHouse集群时使用
create table创建表,查询虽然返回了成功,但实际这个表只在当前连接的Server上创建了。下次连接重置换一个Server,您就看不到这个表了。解决方案:
建表时,请使用
create table <table_name> on cluster default语句,on cluster default声明会把这条语句广播给default集群的所有节点进行执行。示例代码如下。CREATE TABLE test ON cluster default (a UInt64) Engine = MergeTree() ORDER BY tuple();在test表上再创建一个分布式表引擎,建表语句如下。
CREATE TABLE test_dis ON cluster default AS test Engine = Distributed(default, default, test, cityHash64(a));
常见原因2:ReplicatedMergeTree存储表配置有问题。ReplicatedMergeTree表引擎是对应MergeTree表引擎的主备同步增强版,在单副本实例上限定只能创建MergeTree表引擎,在双副本实例上只能创建ReplicatedMergeTree表引擎。
解决方案:在双副本实例上建表时,请使用
ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')或ReplicatedMergeTree()配置ReplicatedMergeTree表引擎。其中,ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')为固定配置,无需修改。
如何处理往表里写入时间戳数据后查询出来的结果与实际数据不同?
用SELECT timezone()语句,查看时区是否为当地时区,如果不是修改timezone配置项的值为当地时区。如何修改请参见修改配置项运行参数值。
如何处理建表后查询表不存在?
常见原因:DDL语句只在一个节点上执行。
解决方案:检查DDL语句是否有on cluster关键字。更多信息,请参见建表语法。
为什么Kafka外表建表后数据不增加?
您可以先对Kafka外表进行select * from的查询,如果查询报错,那可以根据报错信息确定原因(一般是数据解析失败)。如果查询正常返回结果,那需要进一步查看目的表(Kafka外表的具体存储表)和Kafka源表(Kafka外表)的字段是否匹配。如果数据写入失败,那说明字段是匹配不上的。示例语句如下。
insert into <目的表> as select * from <kafka外表>;为什么客户端看到的时间结果和时区显示的不一样?
客户端设置了use_client_time_zone,并设定在了错误时区上。
数据写入后不可见?
问题描述:为什么数据写入后,却查询不到数据?
原因:一般原因可能包括以下几个方面。
分布式表和本地表的表结构不一致造成的。
写入分布式表后,分布式临时文件未分发完成。
写入双副本其中一个副本后,副本同步未完成。
原因分析以及解决方案:
分布式表和本地表的表结构不一致
您可以通过查询系统表system.distribution_queue来查看写入分布式表的时候是否发生错误。
写入分布式表后,分布式临时文件未分发完成
原因分析:在云数据库ClickHouse多节点形态下,如果业务通过域名连接数据库,并且INSERT语句是针对分布式表进行的,那么这个INSERT请求通过前置的CLB组件转发后会随机落在集群中的某个节点上。在节点接收该INSERT请求之后,会先将一部分数据直接写入本节点磁盘中进行存储,另一部分数据作为临时文件暂存于本节点中,并后续异步分发给集群中的其他节点。当这个分发行为未完成时,下一次查询可能无法查询到未分发出去的数据。
解决方案:如果业务对于INSERT之后,立即查询其结果的准确性有强需求的话,可以考虑在INSERT语句中增加settings insert_distributed_sync = 1,配置该参数之后,针对分布式表的INSERT会变为同步等待模式,所有的节点都完成分发后,INSERT才会返回成功。如何配置该参数,请参见下述内容:
设置此参数后,因为要同步等待数据分发,insert语句的执行时间可能会增加,业务上需要结合写入性能考虑是否设置该参数。
设置此参数集群维度生效,需慎重考虑。建议您通过在单条query中添加该参数进行测试,确保验证无误后,再结合业务需求决定是否将其应用于集群维度。
仅需单个query生效,则直接加在query后面,示例如下。
INSERT INTO <table_name> values() settings insert_distributed_sync = 1;需集群维度生效,则设置在user.xml中,如何设置,请参见配置user.xml参数。
写入双副本其中一个副本后,副本同步未完成
原因分析:在云数据库ClickHouse双副本形态下,在执行INSERT语句时,两个副本中只有随机一个会实际执行该INSERT语句,而另一个副本将会异步同步相关数据。因此在执行一条INSERT语句之后,当数据还未同步到另一个副本时,如果SELECT语句请求被未同步数据完成的副本执行时,则会出现查询不到预期数据的现象。
解决方案:如果业务对于INSERT之后,对其立即查询的结果准确性有强需求的话,可以考虑在写入语句中增加settings insert_quorum = 2,配置该参数之后,副本间数据同步会变为同步等待模式,所有的副本同步结束之后,INSERT才会返回成功。
设置此参数,需注意以下事项:
设置此参数后,需要等待副本之间的数据同步完成,INSERT语句的执行时间可能会增加,业务上需要结合写入性能考虑是否设置该参数。
设置此参数后,因为INSERT要等待副本之间同步完成才能执行成功,这意味着如果有副本不可用,则配置了insert_quorum = 2的所有写入均会失败,这与双副本的可靠性保证是冲突的。
设置此参数集群维度生效,需慎重考虑。建议您通过在单条query中添加该参数进行测试,确保验证无误后,再结合业务需求决定是否将其应用于集群维度。
仅需单个query生效,则直接加在query后面,示例如下。
INSERT INTO <table_name> values() settings insert_quorum = 2;需集群维度生效,则设置在user.xml中,如何设置,请参见配置user.xml参数。
为什么ClickHouse设置TTL后,数据过期未删除?
问题描述
业务表已经正确配置了TTL,但是表中的过期数据未自动删除,TTL不生效。
排查方法
检查表的TTL设置是否合理。
根据业务实际情况设置TTL,建议到天级别,避免秒、分钟级别的TTL设置(例如
TTL event_time + INTERVAL 30 SECOND)。检查参数
materialize_ttl_after_modify。该参数用于控制在执行
ALTER MODIFY TTL语句后,是否对存量数据应用新的TTL规则。默认设置为1表示开启;0表示仅对新数据生效,存量数据不会受到TTL限制。查看参数设置
SELECT * FROM system.settings WHERE name like 'materialize_ttl_after_modify';修改参数设置
重要此命令会扫描所有存量数据,资源压力会比较大,请谨慎使用。
ALTER TABLE $table_name MATERIALIZE TTL;
诊断分区清理策略。
ttl_only_drop_parts参数值为1时,表示只有当数据分区(part)内所有数据都过期时才整体删除该分区。查看
ttl_only_drop_parts参数设置SELECT * FROM system.merge_tree_settings WHERE name LIKE 'ttl_only_drop';查看分区过期情况
SELECT partition, name, active, bytes_on_disk, modification_time, min_time, max_time, delete_ttl_info_min, delete_ttl_info_max FROM system.parts c WHERE database = 'your_dbname' AND TABLE = 'your_tablename' LIMIT 100;delete_ttl_info_min:表示该part中用于TTL DELETE规则的最小日期时间键值。
delete_ttl_info_max:表示该part中用于TTL DELETE规则的最大日期时间键值。
如果分区规则与TTL规则不匹配,可能导致部分数据迟迟无法被整体清理。分区规则与TTL规则匹配说明如下。
partition规则与TTL规则一致(例如分区规则是按天分区,TTL规则也是按天删除),则可以通过partition_id判定TTL,一次TTL一个分区,这种策略的代价最低。推荐结合分区(如按天分区)和
ttl_only_drop_parts=1设置,高效删除过期数据,提升性能。partition规则与TTL规则一致不匹配,且
ttl_only_drop_parts = 1,则通过每个part的ttl_info进行匹配。只有当整个part都超过了delete_ttl_info_max时间,才会做TTL。partition规则与TTL规则一致不匹配,且
ttl_only_drop_parts = 0,则需要扫描每个part的数据,找出需要删除数据进行删除,这种策略代价最大。
控制合并触发频率。
过期数据的删除是在数据合并(merge)过程中异步完成,而不是实时立即删除。可以通过
merge_with_ttl_timeout参数控制合并频率,或通过ALTER TABLE ... MATERIALIZE TTL强制触发TTL应用。查看参数
SELECT * FROM system.merge_tree_settings WHERE name = 'merge_with_ttl_timeout';说明单位为秒,线上默认值为7200秒(2小时)。
修改参数
如果
merge_with_ttl_timeout设置过高,TTL合并触发频率会降低,导致过期数据长时间未被清理。可以适当调低该参数以加快清理频率,具体操作请参见参数说明。
检查线程池参数设置。
数据的TTL淘汰是在part的合并阶段执行,TTL受参数
max_number_of_merges_with_ttl_in_pool(线上实例默认值为2)和background_pool_size(线上实例默认值为16)限制。查询当前后台线程活动情况
SELECT * FROM system.metrics WHERE metric LIKE 'Background%';其中“BackgroundPoolTask ”表示对“background_pool_size”指标的实时监控值。
修改参数
当您的其他参数设置没有异常时,且在CPU较为空闲的情况下,结合业务情况,首先可以适当调大
max_number_of_merges_with_ttl_in_pool参数,例如从2调整到4 ,或者从4调整到8;如果调整之后还是没有效果,建议您调大background_pool_size参数。重要调整
max_number_of_merges_with_ttl_in_pool参数需要重启集群,调大background_pool_size参数无需重启集群,但调小background_pool_size参数需要重启集群。
检查表结构或分区设计是否合理。
如果表没有合理分区,或者分区粒度过大,TTL清理效率会降低。为高效清理过期数据,建议分区粒度与 TTL 粒度一致(如都按天),具体操作请参见最佳实践。
检查集群磁盘空间是否充足。
TTL是伴随merge操作在后台触发的,需要预留一定的磁盘空间,当有大part存在或者空间不足(水位超过90%)时,可能也会导致无法TTL。
检查
system.merge_tree_settings中的其他系统参数设置。merge_with_recompression_ttl_timeout:使用重新压缩 TTL 重复合并之前的最小延迟,线上实例默认设置为4小时。默认情况下,TTL规则将至少每 4 小时应用于业务表一次。如果您需要更频繁地应用 TTL 规则,只需修改上述设置即可。max_number_of_merges_with_ttl_in_pool:控制TTL任务数的可以使用的最大线程数的参数,当后台线程池中正在进行的带有TTL的合并任务数量超过该参数指定的值时,不再分配新的带有 TTL 的合并任务。
为什么optimize任务很慢?
optimize任务非常占用CPU和磁盘吞吐量,查询和optimize任务都会相互影响,在机器节点负载压力较大的时候就会表现出optimize很慢问题,目前没有特殊优化方法。
为什么optimize后数据仍未主键合并?
首先为了让数据有正确的主键合并逻辑,需要保证以下两个前提条件。
存储表里的partition by定义字段必须是包含在
order by里的,不同分区的数据不会主键合并。分布式表里定义的Hash算法字段必须是包含在
order by里的,不同节点的数据不会主键合并。
optimize常用命令及相关说明如下。
命令 | 说明 |
| 尝试选取MergeTree的data parts进行合并,有可能没有执行任务就返回。执行了也并不保证全表的记录都完成了主键合并,一般不会使用。 |
| 指定某个分区,选取分区中所有的data parts进行合并,有可能没有执行任务就返回。任务执行后代表某个分区下的数据都合并到了同一个data part,单分区下已经完成主键合并。但是在任务执行期间写入的数据不会参与合并,若是分区下只有一个data part也不会重复执行任务。 说明 对于没有分区键的表,其默认分区就是partition tuple()。 |
| 对全表所有分区强制进行合并,即使分区下只有一个data part也会进行重新合并,可以用于强制移除TTL过期的记录。任务执行代价最高,但也有可能没有执行合并任务就返回。 |
对于上面三种命令,您可以设置参数optimize_throw_if_noop通过异常报错感知是否执行任务。
为什么optimize后数据TTL仍未生效?
常见原因及解决方案如下。
常见原因1:数据的TTL淘汰是在主键合并阶段执行的,如果data part迟迟没有进行主键合并,那过期的数据就无法淘汰。
解决方案:
您可以通过手动
optimize final或者optimize 指定分区的方式触发合并任务。您可以在建表时设置merge_with_ttl_timeout、ttl_only_drop_parts等参数,提高含有过期数据data parts的合并频率。
常见原因2:表的TTL经过修改或者添加,存量的data part里缺少TTL信息或者不正确,这样也可能导致过期数据淘汰不掉。
解决方案:
您可以通过
alter table materialize ttl命令重新生成TTL信息。您可以通过
optimize 分区更新TTL信息。
为什么optimize后更新删除操作没有生效?
云数据库ClickHouse中的更新删除都是异步执行的,目前没有机制可以干预其进度。您可以通过system.mutations系统表查看进度。
如何进行DDL增加列、删除列、修改列操作?
本地表的修改直接执行即可。如果要对分布式表进行修改,需分如下情况进行。
如果没有数据写入,您可以先修改本地表,然后修改分布式表。
如果数据正在写入,您需要区分不同的类型进行操作。
类型
操作步骤
增加Nullable的列
修改本地表。
修改分布式表。
修改列的数据类型(类型可以相互转换)
删除Nullable列
修改分布式表。
修改本地表。
增加非Nullable的列
停止数据的写入。
执行SYSTEM FLUSH DISTRIBUTED分布式表。
修改本地表。
修改分布式表。
重新进行数据的写入。
删除非Nullable的列
修改列的名称
为什么DDL执行慢,经常卡住?
常见原因:DDL全局的执行是串行执行,复杂查询会导致死锁。
您可以采取如下解决方案。
等待运行结束。
在控制台尝试终止查询。
如何处理分布式DDL报错:longer than distributed_ddl_task_timeout (=xxx) seconds?
您可以通过使用set global on cluster default distributed_ddl_task_timeout=xxx命令修改默认超时时间,xxx为自定义超时时间,单位为秒。全局参数修改请参见集群参数修改。
如何处理语法报错:set global on cluster default?
常见原因及解决方案如下。
常见原因1:ClickHouse客户端会进行语法解析,而
set global on cluster default是服务端增加的语法。在客户端尚未更新到与服务端对齐的版本时,该语法会被客户端拦截。解决方案:
使用JDBC Driver等不会在客户端解析语法的工具,比如DataGrip、DBeaver。
编写JDBC程序来执行该语句。
常见原因2:
set global on cluster default key = value;中value是字符串,但是漏写了引号。解决方案:在字符串类型的value两侧加上引号。
有什么BI工具推荐?
Quick BI。
有什么数据查询IDE工具推荐?
DataGrip、DBEaver。
云数据库ClickHouse支持向量检索吗?
云数据库ClickHouse支持向量检索。更多详情,参见以下文档:
在建表时报ON CLUSTER is not allowed for Replicated database怎么办?
如果您的集群是企业版集群,且建表语句中包含ON CLUSTER default,可能会报错ON CLUSTER is not allowed for Replicated database,建议您将实例版本升级至最新版本,部分小版本存在此缺陷。如何升级版本,请参见升级内核小版本。
分布式表使用子查询(JOIN或IN联表查询)时报Double-distributed IN/JOIN subqueries is denied (distributed_product_mode = 'deny')怎么办?
问题描述:如果您的集群是多节点的社区版集群,查询中使用多个分布式表JOIN或IN联表查询时,可能会报错Exception: Double-distributed IN/JOIN subqueries is denied (distributed_product_mode = 'deny'). 。
原因分析:当多个分布式表JOIN或IN联表查询时,会导致查询放大。例如,以3个节点为例,分布式表JOIN或IN联表的查询规模将扩大为3*3个本地表的子查询,这将导致资源浪费和延迟增加,故系统默认不允许此类查询执行。
解决原理:将IN或JOIN替换为GLOBAL IN或GLOBAL JOIN,让GLOBAL IN或GLOBAL JOIN右侧子查询在一个节点完成后存储到临时表,将临时表发送给其他节点用于上一级查询。
将IN或JOIN替换为GLOBAL IN或GLOBAL JOIN的影响:
临时表将被发送到所有远程服务器,尽量避免使用大型数据集。
使用remote函数查询外部实例的数据,将IN或JOIN替换为GLOBAL IN或GLOBAL JOIN后,原本应该在外部实例执行的子查询会在本实例执行,可能导致查询结果错误。
例如,在实例a执行以下语句,使用remote函数查询外部实例
cc-bp1wc089c****的数据。SELECT * FROM remote('cc-bp1wc089c****.clickhouse.ads.aliyuncs.com:3306', `default`, test_tbl_distributed1, '<your_Account>', '<YOUR_PASSWORD>') WHERE id GLOBAL IN (SELECT id FROM test_tbl_distributed1);根据上述解决原理理解该语句,实例a将执行GLOBAL IN右侧的子查询
SELECT id FROM test_tbl_distributed1生成临时表A,并将临时表的数据传给实例cc-bp1wc089c****用于上一级查询。最终,实例cc-bp1wc089c****执行的语句是SELECT * FROM default.test_tbl_distributed1 WHERE id IN (临时表A);以上为GLOBAL IN或GLOBAL JOIN的执行原理。延续上述例子,进一步理解,为什么将IN或JOIN替换为GLOBAL IN或GLOBAL JOIN后,使用remote函数查询外部实例的数据,可能导致结果错误。
根据上述描述,实例
cc-bp1wc089c****最终执行的语句是SELECT * FROM default.test_tbl_distributed1 WHERE id IN (临时表A);,但这里的条件集临时表A却是在实例a执行得到的,上述示例,原本最终实例cc-bp1wc089c****执行的应该是SELECT * FROM default.test_tbl_distributed1 WHERE id IN (SELECT id FROM test_tbl_distributed1 );条件集应该来源于实例cc-bp1wc089c****,所以由于使用GLOBAL IN或GLOBAL JOIN后,导致子查询得到条件集的来源错误,导致结果错误。
解决方案:
方案一:修改业务代码中的SQL,手工将IN或JOIN改成GLOBAL IN或GLOBAL JOIN。
例如您可以将以下语句:
SELECT * FROM test_tbl_distributed WHERE id IN (SELECT id FROM test_tbl_distributed1);添加GLOBAL,修改为
SELECT * FROM test_tbl_distributed WHERE id GLOBAL IN (SELECT id FROM test_tbl_distributed1);方案二:修改系统参数distributed_product_mode或者prefer_global_in_and_join,系统自动将IN或JOIN替换为GLOBAL IN或GLOBAL JOIN。
distributed_product_mode
使用以下语句,设置distributed_product_mode为global,使系统自动将IN或JOIN查询替换为GLOBAL IN或者GLOBAL JOIN。
SET GLOBAL ON cluster default distributed_product_mode='global';distributed_product_mode使用说明
作用:ClickHouse中的一个重要设置,用于控制分布式子查询的行为。
值描述:
deny(默认值):禁止使用IN和JOIN子查询,会抛出
"Double-distributed IN/JOIN subqueries is denied"异常。local:将子查询中的数据库和表替换为目标服务器(分片)的本地表,保留普通的IN或JOIN。
global:将IN或JOIN查询替换为GLOBAL IN或者GLOBAL JOIN。
allow:允许使用IN和JOIN子查询。
适用场景:仅适用于查询中使用多个分布式表JOIN或IN联表查询。
prefer_global_in_and_join
prefer_global_in_and_join
使用以下语句,设置prefer_global_in_and_join为1,使系统自动将IN或JOIN查询替换为GLOBAL IN或者GLOBAL JOIN。
SET GLOBAL ON cluster default prefer_global_in_and_join = 1;prefer_global_in_and_join使用说明
作用:ClickHouse 中的一个重要设置,用于控制 IN 和 JOIN 操作符的行为。
值描述:
0(默认值):禁止使用IN和JOIN子查询,会抛出
"Double-distributed IN/JOIN subqueries is denied"异常。1:启用IN和JOIN子查询,将IN或JOIN查询替换为GLOBAL IN或者GLOBAL JOIN。
适用场景:仅适用于查询中使用多个分布式表JOIN或IN联表查询。
如何查看每张表所占的磁盘空间?
您可以通过如下代码查看每张表所占的磁盘空间。
SELECT table, formatReadableSize(sum(bytes)) as size, min(min_date) as min_date, max(max_date) as max_date FROM system.parts WHERE active GROUP BY table; 如何查看冷数据大小?
示例代码如下。
SELECT * FROM system.disks;如何查询哪些数据在冷存上?
示例代码如下。
SELECT * FROM system.parts WHERE disk_name = 'cold_disk';如何移动分区数据到冷存?
示例代码如下。
ALTER TABLE table_name MOVE PARTITION partition_expr TO DISK 'cold_disk';为什么监控中存在数据中断情况?
常见原因如下。
查询触发OOM。
修改配置触发重启。
升降配后的实例重启。
20.8后的版本是否支持平滑升级,不需要迁移数据?
ClickHouse的集群是否支持平滑升级,主要取决于集群的创建时间。对于2021年12月01日之后购买的集群,支持原地平滑升级内核大版本,无需迁移数据。而对于2021年12月01日之前购买的集群,则需要通过数据迁移的方式进行内核大版本升级。如何升级版本,请参见升级内核大版本。
常用系统表有哪些?
常用系统表及作用如下。
名称 | 作用 |
system.processes | 查询正在执行的SQL。 |
system.query_log | 查询历史执行过的SQL。 |
system.merges | 查询集群上的merge信息。 |
system.mutations | 查询集群上的mutation信息。 |
如何修改系统级别的参数?是否要重启,有什么影响?
系统级别的参数对应config.xml内的部分配置项,具体修改步骤如下。
在集群列表页面,选择社区版实例列表,单击目标集群ID。
单击左侧导航栏的参数配置。
在参数配置页面,单击max_concurrent_queries参数的运行参数值后面的编辑按钮。
在悬浮框中填写目标值,单击确定。
单击提交参数。
单击确定。
单击确定后,自动重启clickhouse-server,重启会造成约1min闪断。
如何修改用户级别的参数?
用户级别的参数对应users.xml内的部分配置项,你需要执行如下示例语句。
SET global ON cluster default ${key}=${value};无特殊说明的参数执行成功后即可生效。
如何修改Quota?
您可以在执行语句的settings里增加,示例代码如下。
settings max_memory_usage = XXX;为什么节点之间的CPU使用率、内存使用率、内存使用量差别很大?
如果您的集群是双副本,或单副本多节点的集群,在进行较多写入操作时,写入节点的CPU和内存使用率将高于其他节点。待数据同步至其他节点后,CPU和内存使用率将趋于基本平衡。
如何查看系统的详细日志信息?
问题描述:
如何查看系统的详细日志信息,以便排查错误或发现潜在问题。
解决方案:
查看集群text_log.level参数,进行以下操作:
text_log.level为空,表示您未开启text_log,您需设置text_log.level以开启text_log。
text_log.level不为空,查看text_log等级是否满足目前需求,如不满足,您需修改此参数,设置text_log等级。
如何查看和修改text_log.level参数,请参见配置config.xml参数。
登录目标数据库。如何登录,请参见连接数据库。
执行以下语句,查看分析。
SELECT * FROM system.text_log;
如何解决目标集群与数据源网络互通问题?
如果目标集群与数据源使用相同的VPC并位于同一地域。您需检查二者是否将IP地址添加到了对方的白名单中。如果没有,请添加白名单。
ClickHouse中如何添加白名单,请参见设置白名单。
其他数据源如何添加白名单,请参见自身产品文档。
如果目标集群与数据源不属于上述情况,选择合适的网络解决方案,解决网络问题后再将彼此IP地址添加到对方的白名单中。
场景 | 解决方案 |
云上云下互通 | |
跨地域跨账号VPC互通 | |
同地域不同VPC互通 | |
跨地域跨账号VPC互通 | |
使用公网互通 |
ClickHouse社区版集群支持迁移至企业版集群吗?
ClickHouse社区版集群支持迁移至企业版集群。
企业版集群与社区版集群相互迁移数据的主要方式有两种,通过remote函数和通过文件导出导入方式。具体操作,请参见将自建ClickHouse数据迁移至云ClickHouse社区兼容版。
数据迁移时不同分片的库表结构不一致,如何处理?
问题描述
数据迁移要求所有分片的库表结构一致,否则会导致部分库表结构无法迁移。
解决方案
MergeTree表(非物化视图inner表)的库表结构在不同分片不一致。
建议排查业务逻辑是否导致分片间表结构存在差异:
若业务预期所有分片表结构应完全一致,请自行重新创建。
若业务预期不同分片的表结构不同,请提交工单联系技术支持进行处理。
物化视图inner表在不同分片不一致。
方案1:重命名inner表,并将物化视图、分布式表显示指定到目标MergeTree表。以原物化视图
up_down_votes_per_day_mv为例,操作步骤如下。列出数量不等于节点数的表。NODE_NUM=分片数*副本数。
SELECT database,table,any(create_table_query) AS sql,count() AS cnt FROM cluster(default, system.tables) WHERE database NOT IN ('system', 'information_schema', 'INFORMATION_SCHEMA') GROUP BY database, table HAVING cnt != <NODE_NUM>;查看inner表数量不正常的物化视图。
SELECT substring(hostName(),38,8) AS host,* FROM cluster(default, system.tables) WHERE uuid IN (<UUID1>, <UUID2>, ...);关闭默认的集群同步行为(云数据库ClickHouse必须关闭,自建ClickHouse无需执行),并重命名inner表,使得各节点的表名一致(为降低操作风险,以下操作请获取各个节点IP,连接端口3005,逐个节点执行)。
SELECT count() FROM mv_test.up_down_votes_per_day_mv; SET enforce_on_cluster_default_for_ddl=0; RENAME TABLE `mv_test`.`.inner_id.9b40675b-3d72-4631-a26d-25459250****` TO `mv_test`.`up_down_votes_per_day`;删除物化视图(逐个节点执行)。
SELECT count() FROM mv_test.up_down_votes_per_day_mv; SET enforce_on_cluster_default_for_ddl=0; DROP TABLE mv_test.up_down_votes_per_day_mv;新建物化视图显示指向重命名的inner表(逐个节点执行)。
SELECT count() FROM mv_test.up_down_votes_per_day_mv; SET enforce_on_cluster_default_for_ddl=0; CREATE MATERIALIZED VIEW mv_test.up_down_votes_per_day_mv TO `mv_test`.`up_down_votes_per_day` ( `Day` Date, `UpVotes` UInt32, `DownVotes` UInt32 ) AS SELECT toStartOfDay(CreationDate) AS Day, countIf(VoteTypeId = 2) AS UpVotes, countIf(VoteTypeId = 3) AS DownVotes FROM mv_test.votes GROUP BY Day;注意:物化视图必须按照原定义格式定义目标表的列,不能使用SELECT推测,否则可能出现异常。例如,列
tcp_cn在SELECT时使用sumIf,在目标表中应定义为sum。正确用法
CREATE MATERIALIZED VIEW net_obs.public_flow_2tuple_1m_local TO net_obs.public_flow_2tuple_1m_local_inner ( ... tcp_cnt AggregateFunction(sum, Float64), ) AS SELECT ... sumIfState(pkt_cnt, protocol = '6') AS tcp_cnt, FROM net_obs.public_flow_5tuple_1m_local ...错误用法
CREATE MATERIALIZED VIEW net_obs.public_flow_2tuple_1m_local TO net_obs.public_flow_2tuple_1m_local_inner AS SELECT ... sumIfState(pkt_cnt, protocol = '6') AS tcp_cnt, FROM net_obs.public_flow_5tuple_1m_local ...
方案2:重命名inner表,物化视图全局重建,迁移inner表数据。
方案3:双写物化视图,等7天。
相同的SQL,在原有实例中未报错,但在企业版的24.5或更新的版本实例中,却发生错误,应该如何处理?
新建的企业版24.5及以后的版本实例,其查询引擎默认使用新analyzer。新analyzer具有更好的查询性能,但可能与部分旧版SQL不兼容,从而导致解析错误。如遇该错误,您可执行以下语句,将新analyzer回退至旧analyzer。更多新analyzer详情,请参见进一步了解全新analyzer。
SET allow_experimental_analyzer = 0;如何暂停云数据库ClickHouse集群?
ClickHouse社区版集群暂不支持暂停功能,企业版集群支持此功能。如果您需要暂停企业版集群,您可前往企业版集群列表,在集群列表页面左上角,选中目标地域,在集群列表找到目标集群,单击目标集群操作列的 >暂停。
>暂停。
如何将集群中的MergeTree表转为ReplicatedMergeTree表?
问题描述
由于用户不熟悉ClickHouse的特性原理,在使用多副本集群时,经常会误创建一些MergeTree引擎的表,这样就会导致各个分片的副本节点之间的数据不会相互同步,进而导致在查询分布式表时,每次查询的数据会不一致。这时就需要将原来的MergeTree引擎表,转化为ReplicatedMergeTree引擎表。
解决方案
在ClickHouse中,没有对应的DDL语句直接修改表的存储引擎,所以要把MergeTree表转为ReplicatedMergeTree表,只能创建ReplicatedMergeTree表,并将MergeTree的数据导入至ReplicatedMergeTree的方式进行。
例如您的多副本集群中有一个引擎为MergeTree类型的表table_src,其对应的分布式表为table_src_d。转换为ReplicatedMergeTree引擎表,请参见以下步骤:
创建ReplicatedMergeTree类型的目标表table_dst,对应的分布式表为table_dst_d。如何建表,请参见CREATE TABLE。
将引擎为MergeTree类型的表table_src中的数据导入至table_dst_d。有如下两种方案:
以下两种方案在查询源数据时,都是对MergeTree的本地表的查询。
往目标表中插入时,数据量不是特别多的情况下,为了使数据均衡 ,直接插入到分布式表table_dst_d中。
如果原来的MergeTree表table_src的数据在各个节点均衡,且数据量特别大,可以直接插入到ReplicatedMergeTree引擎的本地表table_dst中。
如果数据量大,执行时间会很长,使用remote函数时,需注意remote函数的超时时间的设置。
使用remote函数导入数据
获取各个节点IP。
SELECT cluster, shard_num, replica_num, is_local, host_address FROM system.clusters WHERE cluster = 'default';使用remote函数,导入数据。
将上个步骤获取的各节点的IP,依次传入remote函数中,并执行。
INSERT INTO table_dst_d SELECT * FROM remote('node1', db.table_src) ;例如,查询到两个节点IP分别为10.10.0.165、10.10.0.167,然后分别执行如下的insert语句:
INSERT INTO table_dst_d SELECT * FROM remote('10.10.0.167', default.table_src) ; INSERT INTO table_dst_d SELECT * FROM remote('10.10.0.165', default.table_src) ;所有节点IP带入执行完成后,即可完成将集群中的MergeTree表转为ReplicatedMergeTree表。
使用本地表导入数据
如果您在下有的VPC下有ECS,且安装了ClickHouse的client端,也可以通过client分别登录到各个节点执行以下操作。
获取各个节点IP。
SELECT cluster, shard_num, replica_num, is_local, host_address FROM system.clusters WHERE cluster = 'default';导入数据。
使用节点IP依次登录各个节点,执行以下语句。
INSERT INTO table_dst_d SELECT * FROM db.table_src ;所有节点依次登录执行后,即可完成将集群中的MergeTree表转为ReplicatedMergeTree表。
如何使多个SQL语句在同一个Session中执行?
通过设置唯一的session_id标识符,ClickHouse服务端会为同一Session ID的请求维护相同的上下文环境,实现多个SQL语句在同一个Session中执行。以使用ClickHouse Java Client (V2)连接ClickHouse为例,实现关键步骤如下:
在Maven项目的pom.xml中添加依赖。
<dependency> <groupId>com.clickhouse</groupId> <artifactId>client-v2</artifactId> <version>0.8.2</version> </dependency>在CommandSetting中增加自定义的
Session ID。package org.example; import com.clickhouse.client.api.Client; import com.clickhouse.client.api.command.CommandSettings; public class Main { public static void main(String[] args) { Client client = new Client.Builder() // 添加实例接入点 .addEndpoint("endpoint") // 添加用户名 .setUsername("username") // 添加密码 .setPassword("password") .build(); try { client.ping(10); CommandSettings commandSettings = new CommandSettings(); // 设置session_id commandSettings.serverSetting("session_id","examplesessionid"); // 在session内设置参数max_block_size = 65409 client.execute("SET max_block_size=65409 ",commandSettings); // 执行查询 client.execute("SELECT 1 ",commandSettings); client.execute("SELECT 2 ",commandSettings); } catch (Exception e) { throw new RuntimeException(e); } finally { client.close(); } } }
上述示例中的2条SELECT语句均在同一个Session内,并且他们的max_block_size参数均为65409。更多ClickHouse Java Client使用详情,请参见Java Client | ClickHouse Docs。
为何ClickHouse的FINAL关键词去重因JOIN失效?
问题描述
使用 FINAL 关键字对查询去重时,若 SQL 中包含 JOIN,去重失效,结果仍存在重复数据。示例SQL如下:
SELECT * FROM t1 FINAL JOIN t2 FINAL WHERE xxx;问题原因
此问题是ClickHouse官方未修复的已知bug,因 FINAL 和 JOIN 执行逻辑冲突导致去重失效。更多详情,请参见ClickHouse's issues。
解决方案
方案一(推荐):启用实验性优化器,在查询末尾添加配置,启用query级
FINAL(无需表级声明)。示例如下:例如原SQL为:
SELECT * FROM t1 FINAL JOIN t2 FINAL WHERE xxx;您需去除表名后的
FINAL关键字,在SQL末尾增加settings allow_experimental_analyzer = 1,FINAL = 1,语句调整结果如下:SELECT * FROM t1 JOIN t2 WHERE xxx SETTINGS allow_experimental_analyzer = 1, FINAL = 1;重要仅23.8及以上版本支持
allow_experimental_analyzer参数。如您的版本小于23.8,建议您升级版本后调整SQL语句。如何升级,请参见升级内核大版本。方案二(谨慎使用):
强制合并去重:定期执行
OPTIMIZE TABLE 本地表名 FINAL提前合并数据(大表慎用,IO 开销高)。查询SQL调整:移除
FINAL关键字,数据去重依赖合并后数据查询。
重要谨慎操作,表数据量较大时会消耗较大IO,影响性能。
为何ClickHouse社区兼容版删除/更新数据操作一直未完成?
问题描述
ClickHouse社区兼容版集群,执行数据删除(DELETE)或更新(UPDATE)操作时,任务长时间处于未完成状态。
原因分析
与MySQL的同步操作不同,ClickHouse社区兼容版集群的DELETE和UPDATE操作基于Mutation机制异步执行,非实时生效。Mutation的核心流程如下:
提交任务:用户执行
ALTER TABLE ... UPDATE/DELETE生成异步任务。标记数据:后台创建
mutation_*.txt记录待修改的数据范围(不立即生效)。后台重写:ClickHouse逐步重写受影响的
data part,合并时应用变更。清理旧数据:旧数据块在合并完成后被标记删除。
分析上述Mutation流程,如果短时间内下发过多Mutation操作,可能导致Mutation任务阻塞,进而导致删除和更新数据操作一直未完成。建议您在下发Mutation之前,通过下述SQL,查看当前是否有大量Mutation在运行,如果没有,再进行下发Mutation,避免造成Mutation堆积。
SELECT * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;解决方案
检查集群是否存在过多正在执行的Mutation。
您可通过下述SQL,查看集群当前Mutation情况。
SELECT * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;如果存在较多正在执行的Mutation,您需使用高权限账号取消部分或全部Mutation任务。
取消单表上所有Mutation任务。
KILL MUTATION WHERE database = 'default' AND table = '<table_name>'取消某个Mutation任务。
KILL MUTATION WHERE database = 'default' AND table = '<table_name>' AND mutation_id = '<mutatiton_id>'其中,mutatiton_id可通过以下SQL获取。
SELECT mutation_id, * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;
问题描述
ClickHouse社区兼容版集群,执行数据删除(DELETE)或更新(UPDATE)操作时,任务长时间处于未完成状态。
原因分析
与MySQL的同步操作不同,ClickHouse社区兼容版集群的DELETE和UPDATE操作基于Mutation机制异步执行,非实时生效。Mutation的核心流程如下:
提交任务:用户执行
ALTER TABLE ... UPDATE/DELETE生成异步任务。标记数据:后台创建
mutation_*.txt记录待修改的数据范围(不立即生效)。后台重写:ClickHouse逐步重写受影响的
data part,合并时应用变更。清理旧数据:旧数据块在合并完成后被标记删除。
分析上述Mutation流程,如果短时间内下发过多Mutation操作,可能导致Mutation任务阻塞,进而导致删除和更新数据操作一直未完成。建议您在下发Mutation之前,通过下述SQL,查看当前是否有大量Mutation在运行,如果没有,再进行下发Mutation,避免造成Mutation堆积。
SELECT * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;解决方案
检查集群是否存在过多正在执行的Mutation。
您可通过下述SQL,查看集群当前Mutation情况。
SELECT * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;如果存在较多正在执行的Mutation,您需使用高权限账号取消部分或全部Mutation任务。
取消单表上所有Mutation任务。
KILL MUTATION WHERE database = 'default' AND table = '<table_name>'取消某个Mutation任务。
KILL MUTATION WHERE database = 'default' AND table = '<table_name>' AND mutation_id = '<mutatiton_id>'其中,mutatiton_id可通过以下SQL获取。
SELECT mutation_id, * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;
为何ClickHouse社区兼容版集群连续查询数据结果不一致?
问题描述
云数据库ClickHouse社区兼容版,使用相同的SQL语句多次进行查询时,查询返回的结果存在不一致的情况。
原因分析
导致社区兼容版集群同一SQL多次查询,返回结果不一致的主要原因有2个,具体原因及分析如下:
多分片集群多次查询的目标表是本地表。
社区兼容版的多分片集群在建表时,除了创建本地表,还需要创建分布式表。此类集群,数据写入流程大概如下:
当有数据写入时,数据会先写入到分布式表中,然后由分布式表将数据分发到不同分片上的本地表进行存储。
查询数据时,查询的表类型不同,数据来源也会不同,具体如下:
查询分布式表:分布式表会将各个分片上本地表的数据聚合起来一起返回。
查询本地表:每次查询只会返回随机分片上本地表的数据,这种情况下,就会出现每次查询结果与上一次不一致的现象。
双副本集群在创建表时没有使用
Replicated*系列引擎。社区兼容版的双副本集群在建表时需使用Replicated*系列引擎,例如ReplicatedMergeTree引擎。Replicated*系列引擎可实现副本之间的数据同步。
如果双副本集群在创建表时没有使用Replicated*系列引擎,副本之间数据没有相互同步,则多次查询也会出现结果不一致的现象。
解决方案
确定集群类型。
您需根据集群信息判断集群是多分片集群、双副本集群还是多分片双副本集群。具体操作如下:
在页面左上角,选择社区版实例列表。
在集群列表中,单击目标集群ID,进入集群信息页面。
查看集群属性的系列和配置信息的节点组个数。判断集群类型,具体逻辑如下:
节点组个数大于1:多分片集群。
系列等于高可用版:双副本集群。
上述2个条件都满足:多分片双副本集群。
根据集群类型,选择处理方法。
多分片集群
检查查询的表类型,如果是本地表,您需查询分布式表。
如果没有创建分布式表,您需创建分布式表。如何创建分布式表,请参见创建表。
双副本集群
查看目标表的建表语句,其引擎是不是
Replicated*系列引擎,如果不是,需要重新创建表。如何建表,请参见创建表。多分片双副本集群
检查查询的表类型。
如果是本地表,您需查询分布式表。如果没有创建分布式表,您需创建分布式表。
如果查询的是分布式表,您需检查分布式表对应的本地表的引擎是不是
Replicated*系列引擎,如果不是,您需重新创建本地表,其引擎使用Replicated*系列引擎。如何建表,请参见创建表。
问题描述
云数据库ClickHouse社区兼容版,使用相同的SQL语句多次进行查询时,查询返回的结果存在不一致的情况。
原因分析
导致社区兼容版集群同一SQL多次查询,返回结果不一致的主要原因有2个,具体原因及分析如下:
多分片集群多次查询的目标表是本地表。
社区兼容版的多分片集群在建表时,除了创建本地表,还需要创建分布式表。此类集群,数据写入流程大概如下:
当有数据写入时,数据会先写入到分布式表中,然后由分布式表将数据分发到不同分片上的本地表进行存储。
查询数据时,查询的表类型不同,数据来源也会不同,具体如下:
查询分布式表:分布式表会将各个分片上本地表的数据聚合起来一起返回。
查询本地表:每次查询只会返回随机分片上本地表的数据,这种情况下,就会出现每次查询结果与上一次不一致的现象。
双副本集群在创建表时没有使用
Replicated*系列引擎。社区兼容版的双副本集群在建表时需使用Replicated*系列引擎,例如ReplicatedMergeTree引擎。Replicated*系列引擎可实现副本之间的数据同步。
如果双副本集群在创建表时没有使用Replicated*系列引擎,副本之间数据没有相互同步,则多次查询也会出现结果不一致的现象。
解决方案
确定集群类型。
您需根据集群信息判断集群是多分片集群、双副本集群还是多分片双副本集群。具体操作如下:
在页面左上角,选择社区版实例列表。
在集群列表中,单击目标集群ID,进入集群信息页面。
查看集群属性的系列和配置信息的节点组个数。判断集群类型,具体逻辑如下:
节点组个数大于1:多分片集群。
系列等于高可用版:双副本集群。
上述2个条件都满足:多分片双副本集群。
根据集群类型,选择处理方法。
多分片集群
检查查询的表类型,如果是本地表,您需查询分布式表。
如果没有创建分布式表,您需创建分布式表。如何创建分布式表,请参见创建表。
双副本集群
查看目标表的建表语句,其引擎是不是
Replicated*系列引擎,如果不是,需要重新创建表。如何建表,请参见创建表。多分片双副本集群
检查查询的表类型。
如果是本地表,您需查询分布式表。如果没有创建分布式表,您需创建分布式表。
如果查询的是分布式表,您需检查分布式表对应的本地表的引擎是不是
Replicated*系列引擎,如果不是,您需重新创建本地表,其引擎使用Replicated*系列引擎。如何建表,请参见创建表。
为何ClickHouse社区兼容版集群使用optimize命令强制数据合并后,ReplacingMergeTree引擎仍未去重?
问题描述
ClickHouse的ReplacingMergeTree引擎表在数据合并过程中,会对主键相同的数据执行去重操作。使用以下命令进行强制数据合并后,仍可查找到主键相同的重复数据。
optimize TABLE <table_name> FINAL ON cluster default;原因分析
ReplacingMergeTree引擎的去重仅作用于单节点。若主键相同的数据因分片表达式sharding_key未显式指定(默认rand()随机分配)而分散到不同节点,则无法保证整查询整个集群时数据不重复,因为ReplacingMergeTree引擎无法跨节点去重。
解决方案
重新创建本地表和分布式表,在创建分布式表时,将分片表达式sharding_key设置为本地表的主键。建表语法请参见CREATE TABLE。
分布式表和本地表都需要重新创建。如果只重建分布式表,也只能对新插入的数据起效,存量数据依然无法去重。
问题描述
ClickHouse的ReplacingMergeTree引擎表在数据合并过程中,会对主键相同的数据执行去重操作。使用以下命令进行强制数据合并后,仍可查找到主键相同的重复数据。
optimize TABLE <table_name> FINAL ON cluster default;原因分析
ReplacingMergeTree引擎的去重仅作用于单节点。若主键相同的数据因分片表达式sharding_key未显式指定(默认rand()随机分配)而分散到不同节点,则无法保证整查询整个集群时数据不重复,因为ReplacingMergeTree引擎无法跨节点去重。
解决方案
重新创建本地表和分布式表,在创建分布式表时,将分片表达式sharding_key设置为本地表的主键。建表语法请参见CREATE TABLE。
分布式表和本地表都需要重新创建。如果只重建分布式表,也只能对新插入的数据起效,存量数据依然无法去重。