
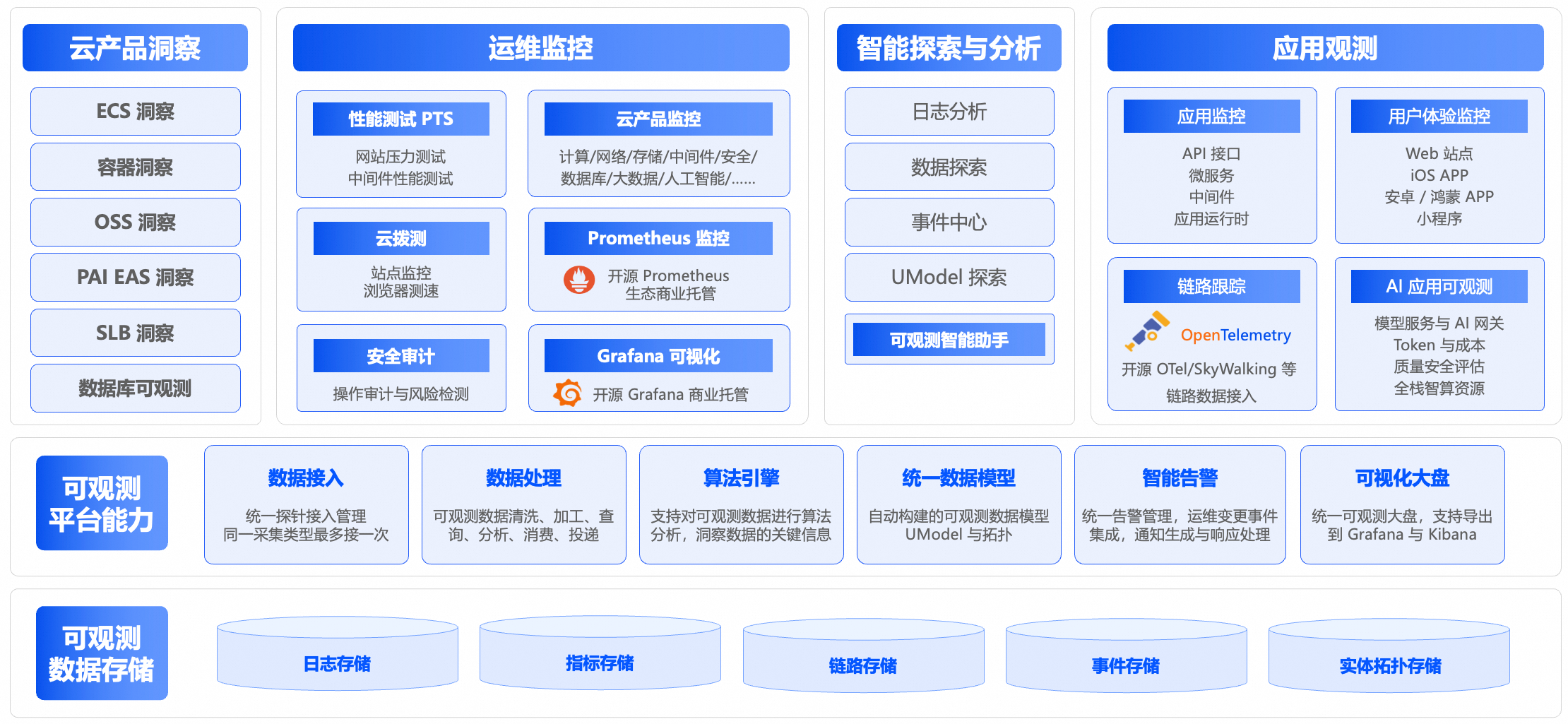
阿里云云监控2.0是融合日志服务SLS、云监控CMS、应用实时监控服务ARMS产品后全新升级的一站式可观测平台,可将指标、链路、日志、事件汇集于统一视图。基于 UModel 建模与观测图谱,结合可视化和告警能力,实现资源自动关联与智能诊断,提供从基础设施到应用层的全链路、端到端的统一观测,快速发现并解决潜在问题,提高运维效率。广泛适用于微服务、容器、云产品等复杂场景。
云监控2.0借助AI增强的跨域智能洞察,能够实时分析和预测系统性能,提前识别异常情况,并提供智能化的故障诊断和优化建议,帮助企业在 AI-native 时代以更智能、更高效、更低成本的方式构建全栈可观测体系,为业务稳定性与安全性保驾护航。
功能体验
阿里云Playground提供了云监控2.0主要功能的演示环境,便于您快速了解及体验云监控2.0。
请访问 Playground Demo 演示环境,默认进入工作空间。
产品优势
一站式融合观测
云监控2.0深度整合了原云监控(CMS)、日志服务(SLS)和应用实时监控服务(ARMS)的核心能力,将指标、日志、链路、事件等多种数据源融于一体。您无需再部署和维护多套独立的监控工具,即可在一个统一的平台上实现从底层基础设施到上层应用的全方位、端到端观测,显著降低了监控体系的复杂度和管理成本。
数据统一建模
基于 UModel (Universal Observability Model)将指标(Metrics)、日志(Logs)、链路(Traces)、变更(Changes)等数据孤岛全面打通,构建起IT系统的全景数字视图。让人、程序和AI都能够理解和分析可观测数据,从而构建真正的全栈可观测能力,提升问题定位效率。
AI 驱动智能分析
以统一的可观测数据模型为基石,通过使用机器学习技术进行深度模式识别与关联分析,实现精准的异常检测、趋势预测和智能告警降噪。同时利用大语言模型的能力,将复杂的可观测数据转化为深度洞察,实现革命性的“对话式运维”——用自然语言与智能助手对话,快速定位、分析和处理问题。
开放兼容,拥抱主流生态
云监控2.0全面拥抱开源技术生态,原生支持Prometheus、Grafana、OpenTelemetry,Elasticsearch等业界主流标准和工具。这使得您现有的监控资产和技术栈可以平滑迁移和接入,无论是云原生应用还是混合云环境,都能实现无缝的统一监控,为您提供了一个灵活、开放、无厂商锁定的解决方案。
基本概念
在使用云监控前,您需要了解以下基本概念。
术语 | 说明 |
工作空间(WorkSpace) | 工作空间(WorkSpace)是云监控2.0中用于表示一组资源集合的抽象层,为企业团队提供统一的管理和资源分组数据隔离能力,所选地域用于存储工作区接入的数据和配置信息。通过使用工作空间,可以创建多个独立的资源环境,每个资源环境都可以拥有自己的对象集(如云服务、基础设施、服务端和前端应用、中间件等),每个组内的资源是相互隔离的,这可防止不同组之间的资源冲突,提高资源使用的安全性。
|
应用(App) | 可观测App是对WorkSpace下的数据源进行读写操作的载体,在WorkSpace中可以打开或隐藏,App通常是对于某一特定场景的可观测领域知识的呈现。具有以下特点:
|
实体(Entity) | 实体Entity是指可观测的实体对象,例如一个容器集群或者一台ECS服务器,对应一个实体Entity。 |
模型(Umodel) | UModel是一个可观测数据模型定义规范,用于定义各类可观测对象的模型,包括日志、指标、Trace、实体等,以及这些可观测对象之间的关联关系,以实现可观测数据的统一定义和管理。 |
功能特性
功能特性 | 描述 |
全栈数据采集与监控 |
|
智能分析与诊断 |
|
可视化与报表 |
|
告警与通知管理 |
|
开放与集成能力 |
|
安全与高可用 |
|
成本优化功能 |
|
跨地域统一管理 | 支持对分布在多个地域的资源实施集中监控和管理,简化运维工作流程。 |
应用场景
场景 | 场景描述 | 方案优势 |
场景一:全栈统一监控与实时观测图谱 | 企业需同时监控混合云环境中的物理服务器、容器集群、微服务应用及数据库等资源,但传统工具分散导致运维效率低。云监控2.0通过统一采集指标(如CPU、内存)、链路(如API调用链)、日志(如错误日志)及事件(如配置变更),构建端到端观测图谱,实现跨资源、跨服务的全局状态可视化。 |
|
场景二:智能异常检测与故障预测 | 在流量突增或复杂架构下,人工识别潜在故障难度高。云监控2.0基于机器学习模型分析历史数据,实时预测系统容量瓶颈、服务响应延迟等风险,并提前触发预警。 |
|
场景三:从客户端到服务端,端到端全链路追踪(APM) | 微服务架构下,单次用户请求可能涉及数十个服务调用和前后端调用,性能瓶颈难以追踪。云监控2.0结合全链路追踪与代码级诊断,向上链接用户体验、向下链接基础设施,构建全栈观测图谱,精准分析慢查询、死锁等问题。 |
|
场景四:安全合规与威胁洞察 | 企业需实时监控登录异常、数据泄露等安全事件,并满足等保合规审计要求。云监控2.0通过日志实时分析、行为模式识别,快速发现潜在威胁。 |
|
场景五:资源优化与成本管理 | 云资源使用不透明易导致资源浪费。云监控2.0分析资源利用率,推荐弹性伸缩策略与闲置资源释放方案。 |
|
场景六:智能告警与自动化运维 | 传统告警易出现误报或信息过载。云监控2.0通过告警降噪、动态阈值及分级通知机制,提升告警精准度,并支持自动化修复动作。 |
|
场景七:开源可观测组件托管与智能化运维 | 企业在混合云或多云环境中广泛使用开源可观测工具(如Prometheus、Grafana、OpenTelemetry),但面临以下挑战:
|
|
可观测应用列表
应用类型 | 应用名称 | 描述(中文) |
常驻 | 告警中心 | 集中管理所有告警信息 |
常驻 | 所有功能 | 集中管理所有应用及其相关服务 |
常驻 | 接入中心 | 提供各种观测对象和数据的接入与管理 |
常驻 | 实体探索 | 探索不同观测对象的状态和性能 |
常驻 | 云产品监控 | 提供阿里云服务的基础监控指标查询与告警服务 |
应用可观测 | 应用监控 | 对应用程序性能进行实时监控与故障诊断 |
应用可观测 | 用户体验监控 | 专注于Web、移动端App和小程序场景的监控 |
应用可观测 | AI应用可观测 | 提供AI应用的全栈一体化可观测能力 |
运维监控 | Prometheus服务 | Prometheus全托管云服务,实现高性能监控系统 |
运维监控 | 问题响应 | 将告警事件聚合成问题并进行管理 |
运维监控 | 云拨测 | 模拟用户请求,主动监控网络质量、服务可用性及用户体验 |
运维监控 | 数据库可观测 | 为数据库服务提供一站式可观测能力 |
运维监控 | 日志审计 | 记录并审查操作日志 |
云产品洞察 | PAI洞察 | 为人工智能平台PAI提供一站式全栈可观测能力 |
云产品洞察 | 容器洞察 | 深入分析 Kubernetes 集群的运行状态 |
云产品洞察 | ECS 洞察 | 弹性计算服务的高级监控功能 |
智能探索与分析 | UModel Explorer | Entity & Umodel 调试工具 |
智能探索与分析 | Data Explorer | 探索和分析各种监控指标、数据 |
智能探索与分析 | 事件中心 | 统一管理各类事件信息 |
智能探索与分析 | 仪表盘 | 展示关键指标的综合仪表板 |
智能探索与分析 | 日志探索 | 提供日志数据探索/分析服务 |