
元表是通过数据管理的跨存储类型表,开发过程中所用到的输入表、输出表、维表可以通过创建元表进行创建和管理。本文为您介绍如何创建及管理元表。
功能优势
元表具有以下优势:
安全可靠:通过元表可以有效避免直接编写原生Flink DDL语句导致的敏感信息泄露问题。
提升效率和体验:通过一次建表,可多次引用。您无需重复编写DDL语句,无需进行繁杂的输入、输出、维表映射。简化开发,提升效率和体验。
资产血缘:通过元表可以维护上下游的资产血缘信息。
元表作用
使用元表,您可以实现以下应用场景:
平台化:统一维护所有实时元表和相关Schema信息。
资产化:统一配置和管理实时研发过程中的表。
元表页面介绍
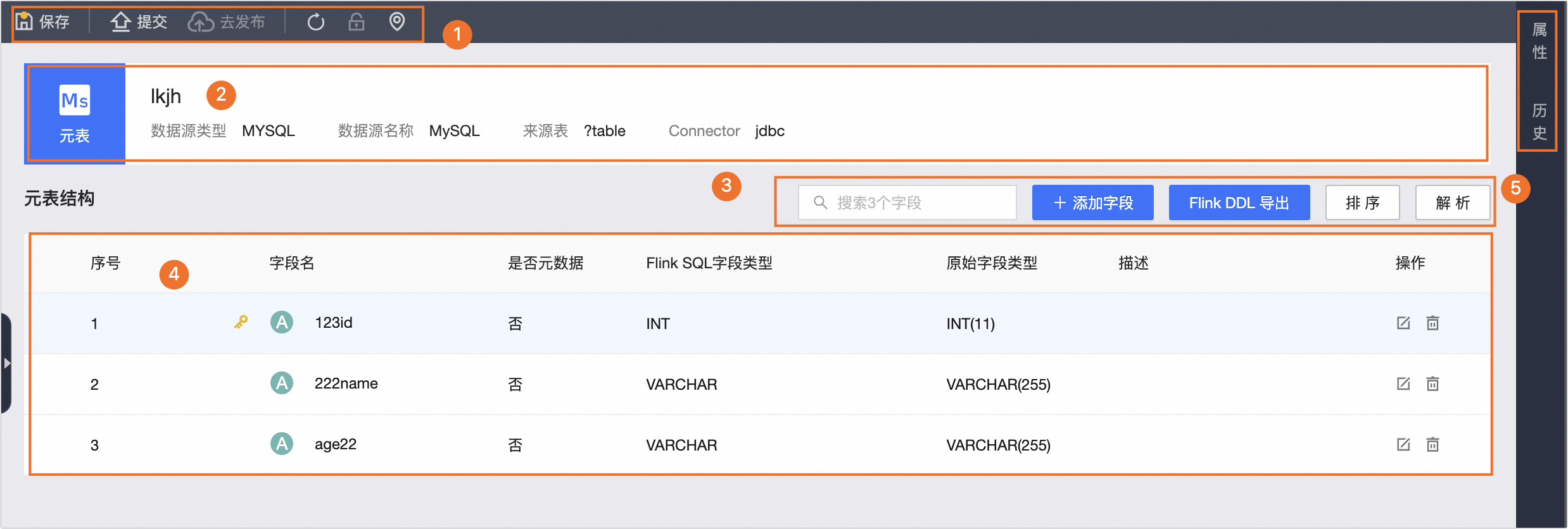
区域 | 描述 |
①操作栏 | 支持保存、提交、去发布、刷新、编辑锁、定位操作。 |
②元表基本信息 | 元表的基本信息,包括元表的名称、数据源类型、数据源名称、来源表名称、Connector名称。 说明
|
③操作元表结构 | 支持搜索表字段、添加字段、Flink DDL导出、排序和解析操作。添加字段支持以下方式。
|
④元表字段列表 | 为您展示系统解析到的元表字段。包括序号、字段名、是否元数据、Flink字段类型、原始字段类型、描述以及支持编辑和删除操作。 |
⑤配置元表 | 支持配置元表的属性和查看元表的历史版本。 |
操作步骤
步骤一:新建元表
在Dataphin首页,在顶部菜单栏选择研发 > 数据开发。
在顶部菜单栏选择项目后,在左侧导航栏选择数据处理 > 表管理。
单击表管理列表中的
 新建图标,打开新建表对话框。
新建图标,打开新建表对话框。在新建表对话框,配置参数。
参数
描述
表类型
选择元表。
元表名称
填写元表的名称。命名规则如下:
仅支持英文字母大小写、数字、下划线(_),且不能以数字开头。
不能超过64个字符。
数据源
Dataphin支持的实时数据源及创建的表类型详情,请参见Dataphin支持的实时数据源。
您也可以自定义实时数据源类型,具体操作,请参见新建自定义数据源类型。
选择数据源后,您还需根据数据源类型,配置对应信息。配置说明,请参见附录:元表数据源配置参数
来源表
输入或选择来源表。
说明当数据源选择为Hive时,还可选择Hudi或paimon表。在来源表下拉列表中,Hudi表后有
 图标标识、paimon表后有
图标标识、paimon表后有 图标标识。
图标标识。当数据源选择为Log Service、DataHub、Kafka、Elasticsearch、Redis、RabbitMQ时,不支持配置来源表。
选择目录
默认选择为表管理。同时您也可以在表管理页面创建目标文件夹后,选择该目标文件夹为元表的目录。操作方法如下:
在页面左侧表管理列表上方单击
 图标,打开新建文件夹对话框。
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称并根据需要选择目录位置。
单击确定。
描述
填写简单的描述,1000个字符以内。
单击确定,完成元表的创建。
步骤二:添加字段
Dataphin元表支持以下三种添加字段方式:
当元表数据源选择Hive,且来源表为paimon表时,字段列表将通过元数据获取,不可编辑。
通过SQL导入的方式添加字段
在实时元表页面,单击+添加字段,选择SQL导入。
在SQL导入对话框中,编写SQL代码。
说明Dataphin将根据您的数据源类型提示对应的参考示例,您可在窗口中单击参考示例
 查看对应代码示例。
查看对应代码示例。完成代码编写后,您可单击格式化
,一键调整您的代码的格式。若您勾选同时导入with参数中的参数值,with的参数中的值将一并导入。
MySQL数据源代码示例如下:
create table import_table ( retailer_code INT comment '' ,qty_order VARCHAR comment '' ,cig_bar_code INT comment '' ,org_code INT comment '' ,sale_reg_code INT comment '' ,order_date TIMESTAMP comment '' ,PRIMARY KEY(retailer_code) ) with ( 'connector' = 'mysql' ,'url' = 'jdbc' ,'table-name' = 'ads' ,'username' = 'dataphin' );单击确定,完成字段的添加。
通过批量导入的方式添加字段
在实时元表页面,单击+添加字段,选择批量导入。
在批量导入对话框中,根据批量导入格式编写SQL代码。
批量导入格式
字段名||字段类型||描述||是否主键||是否元数据示例
ID||INT||描述||false||false name||INT||描述||false||false
单击确定,完成字段的添加。
通过单行添加的方式添加字段
在实时元表页面,单击+添加字段,选择单行添加。
在单行添加对话框中,配置参数。
参数
描述
是否元数据
默认为否,若选择是,则无需填写是否主键及原始字段类型,需要选择Flink SQL字段类型。
字段名
输入字段名称。
仅支持英文字母大小写、数字、下划线(_)、半角句号(.),且不能以数字开头。
是否主键
请根据业务需求选择该字段是否为主键。
说明若您的数据源为Kafka且Connector为Kafka时,则选择是否消息键。
若您的数据源为HBase时,则选择RowKey。
字段类型和原始字段类型
HBase没有原始字段类型,需要选择Flink SQL字段类型。此外,若该字段不是RowKey,则需填写列簇。
若元表的Flink SQL字段类型与原始字段类型为多对一,则需选择Flink SQL字段类型。由Flink SQL字段类型映射出原始字段类型,此时原始字段类型只作展示,无法进行编辑,例如Kafka。
如果此种数据源的Flink SQL字段类型与原始字段类型为一对多,则先选择原始字段类型,选择原始字段类型后允许编辑,可手动添加精度,例如MySQL、Oracle、PostgreSQL、Microsoft SQL Server、Hive等数据源。
单击确定,完成字段的添加。
步骤三:配置元表属性
完成元表创建后,单击右侧属性按钮,可以配置元表基本信息、元表参数、引用信息和修改调试测试数据表。
参数
描述
基本信息
元表名称
默认为所创建的元表名称,不支持修改。
数据源
默认为所创建的数据源类型。
数据源参数
不同计算引擎支持不同数据源,不同数据源所需配置参数不同。更多信息,详情请参见附录:元表数据源配置参数。
描述
请输入对元表的描述,1000个字符以内。
元表参数
参数名称
根据数据源类型提供不同的元表参数,您可以下拉获取该数据源支持的元表参数及其对应的说明,也可以手动填写。若需新增参数,您可以单击添加参数。
参数个数不超过50个,参数名称只能是数字、英文字母大小写、下划线(_)、短划线(-)、半角句号(.)、半角冒号(:)、正斜线(/)。
参数值
参数值根据参数类型提供可选项,无可选项则需手动输入,不支持单引号。例如:参数名称:address,参数值:宁波。
操作
您可单击
删除对应参数。引用信息
Flink任务名
将为您展示引用此元表的Flink任务名称。
说明草稿态任务不计入引用信息。
任务调试时默认读取
设置任务调试时默认读取的数据表,支持选择生产表和开发表。
如果选择可读取生产表,调试时可读取对应的生产表数据,存在数据泄漏风险,请谨慎操作。
若设置了任务调试时默认读取生产表,则需申请个人账号的开发及生产数据源权限。如何申请数据源权限,请参见申请数据源权限。
说明Hive表、paimon表暂不支持调试。
开发环境测试时读取
设置任务测试时默认读取的数据表,支持选择生产表和开发表。
如果选择可读取生产表,测试时可读取对应的生产表数据,存在数据泄漏风险,请谨慎操作。
若设置了开发环境测试时默认读取生产表,则需申请个人账号的开发及生产数据源权限。如何申请数据源权限,请参见申请数据源权限。
开发环境测试时写入
支持选择当前来源表和其他测试表,如果选择其他测试表,则需要选择相应的表。
单击确定。
步骤四:提交或发布元表
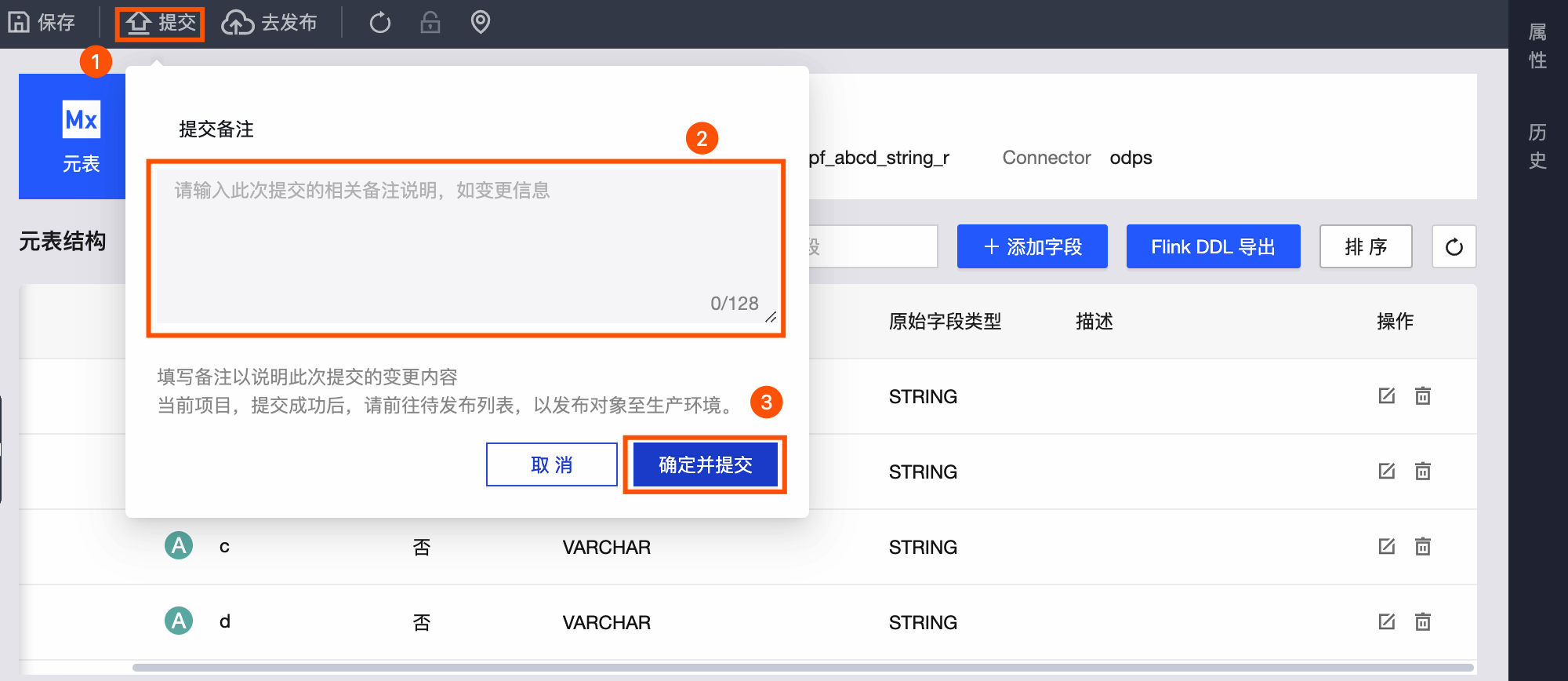
单击元表页面左上角菜单栏的提交。
在提交备注对话框中,填写备注信息。
单击确定并提交。
如果项目的模式为Dev-Prod,则您需要发布元表至生产环境。具体操作,请参见管理发布任务。
附录:元表数据源配置参数
数据源 | 配置 | 描述 |
MaxCompute |
| 来源表:数据的来源表。 blinkType:支持选择odps或continuous-odps。
|
| 来源表 | 来源表:数据的来源表。 |
SAP HAHA |
| 来源表:数据的来源表。 更新时间字段:在下拉选项中选择SAP HAHA表中为更新时间的字段(timestamp类型),或者填写HANA SQL时间字符串表达式,例如 |
| 来源topic | 来源topic:数据的来源topic。 |
|
|
|
Kafka |
|
|
Hudi |
|
|
Elasticsearch |
|
|
Redis | 无 | |
RabbitMQ |
|
|
TDH Inceptor |
|
|
后续步骤
完成元表创建后,您可以基于元表开发实时任务。更多信息,请参见: