
通过即席查询您可以根据当前的业务情况自定义并执行查询语句和下载查询的数据。例如,当完成计算任务开发后,您可以通过即席查询验证计算任务是否符合预期。本文为您介绍如何新建即席查询并下载结果数据。
背景信息
即席查询任务使用您当前项目下所设置的计算源进行数据查询。在使用Hadoop计算源时,支持开启Impala任务,开启后除支持创建Hive SQL即席查询任务外,还支持创建Impala SQL即席查询任务。因Impala基于内存计算,Impala SQL即席查询相对于Hive SQL即席查询具备更好的查询响应。同时Dataphin支持Impala SQL和Hive SQL任务类型的快速切换,对于历史任务无需再次编写相同的查询代码。具体操作,请参见附录:切换任务类型。
前提条件
创建Impala SQL即席查询需在Hadoop计算源中开启Impala任务。具体操作,请参见创建Hadoop计算源。
若您需下载即席查询的结果数据,在您开始执行操作前,请确认您已开启项目下载数据的权限,并已开启当前项目的下载(完整数据下载和样例数据下载)。具体操作,请参见管理项目空间的权限和计算源、数据下载配置。
使用限制
未购买查询加速时,即席查询不支持使用查询加速。
新建即席查询
在Dataphin首页的顶部菜单栏中,选择研发 > 数据研发。
在顶部菜单栏选择项目(Dev-Prod模式还需选择环境)。
在左侧导航栏选择即席查询,在即席查询列表中单击
 图标。支持创建计算引擎即席查询和数据库SQL即席查询。
图标。支持创建计算引擎即席查询和数据库SQL即席查询。在新建即席查询对话框中,配置以下参数。
说明若您的计算引擎为Hadoop并开启了Impala任务,支持新建Hive SQL即席查询和Impala SQL即席查询。
参数
描述
名称
填写即席查询名称。
长度不超过256个字符,不支持竖线(|)、正斜线(/)、反斜线(\)、半角冒号(:)、半角问号(?)、尖括号(<>)、星号(*)和半角引号(")。
描述
填写对即席查询的简单描述。
选择目录
选择任务所存放的目录,默认为临时代码。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
 图标,打开新建文件夹对话框。
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称并根据需要选择目录位置。
单击确定。
数据源类型
选择SQL任务的数据源类型。可选数据源类型详情请参见Dataphin支持的数据源中的离线研发-数据库SQL列。
说明仅创建数据库SQL即席查询时,支持配置此参数。
数据源
选择用于即席查询的数据源。若无可选数据源,可以单击+新建数据源进行新建。
说明仅创建数据库SQL即席查询时,支持配置此参数。
Catalog
数据源类型为Presto、Trino时,配置数据源后,还需要配置Catalog。
Database/Schema
数据源类型为MySQL、PostgreSQL、AnalyticDB for PostgreSQL、Oracle、Presto、GaussDB(DWS)、Microsoft SQL Server、ClickHouse、Hologres、Doris、openGauss、StarRocks、DM、OceanBase(Oracle租户模式)、SelectDB、Trino、PolarDB-X2.0时,配置数据源后,还需要配置Schema。
单击确定,完成即席查询文件的创建。
(可选)您可配置并开启查询加速,开启后需选择加速方式。
MCQA:即MaxCompute MCQA加速查询。MCQA每一个租户下,作业数量与并发数有限制,可能会导致加速失败、执行报错,详情请参见查询加速(MCQA)。您可在管理中心 > 系统设置 > 研发平台 > 查询加速中禁用MCQA加速。
不同计算引擎的不同情况下,支持的加速方式不同。
当前租户使用MaxCompute计算引擎时:
若未购买查询加速,且已开启研发平台-查询加速时,此处加速方式为MCQA。
若已购买查询加速、已开启研发平台-查询加速、且当前项目对应的计算源未绑定加速源时,此处加速方式为MCQA。
若已购买查询加速,且项目对应的计算源已绑定加速源,此处加速方式可选择加速源或MCQA。
当前租户使用Hadoop计算引擎时:已购买查询加速,且项目计算源对应的集群已绑定加速源,Hive SQL、Impala SQL、Spark SQL即席查询任务此处加速方式为加速源。
根据项目的计算源、数据库SQL类型,编写查询数据的代码。
代码编写完成后,单击编辑器顶部的运行。
查询语句执行成功后,在控制台中查看运行结果数据。
下载结果数据
查询语句执行成功后,单击控制台右上角的
 图标,下载执行结果数据。
图标,下载执行结果数据。在数据下载对话框中,选择下载数据范围和下载数据格式。
下载数据范围:支持完整数据下载或样例数据下载。
完整数据下载:完整数据下载耗时可能较长,可关注消息中心消息或在运行记录查看下载进度。
重要完整数据下载会创建一个基于查询语句的临时表,Hadoop类型计算引擎下的Spark SQL即席查询,在完整数据下载创建临时表时将使用管理中心 > 系统设置 > 研发平台 > 表管理设置中的默认存储格式。
例如:表管理设置中默认存储格式为hudi,则创建临时表时增加
using hudi语句;表管理设置中默认存储格式为引擎默认,则创建临时表时将不限定存储格式。样例数据下载:所有查询语句默认返回部分数据,具体记录数可前往管理中心 > 规范设置 > 数据下载中设置。详情请参见数据下载配置。
下载数据格式:当下载数据范围选择为样例数据时,下载数据格式支持选择CSV或Excel格式;当下载数据范围选择为完整数据时,下载数据格式仅支持选择CSV。
单击确定,开始下载数据。
当下载数据范围选择为完整数据时,单击确定后将开始数据准备,完整数据准备完成后,再次单击确定开始完整数据下载。
附录:切换任务类型
项目的离线引擎为Hadoop计算源且已开启Impala任务。支持Impala SQL任务类型和Hive SQL任务类型的互相切换。
在即席查看列表中,选择目标Impala SQL类型或Hive SQL类型的任务,单击任务名称后的
 图标,选择修改类型。
图标,选择修改类型。在修改类型对话框中,选择修改后的类型。下图以Impala SQL任务类型切换为Hive SQL任务类型为例。
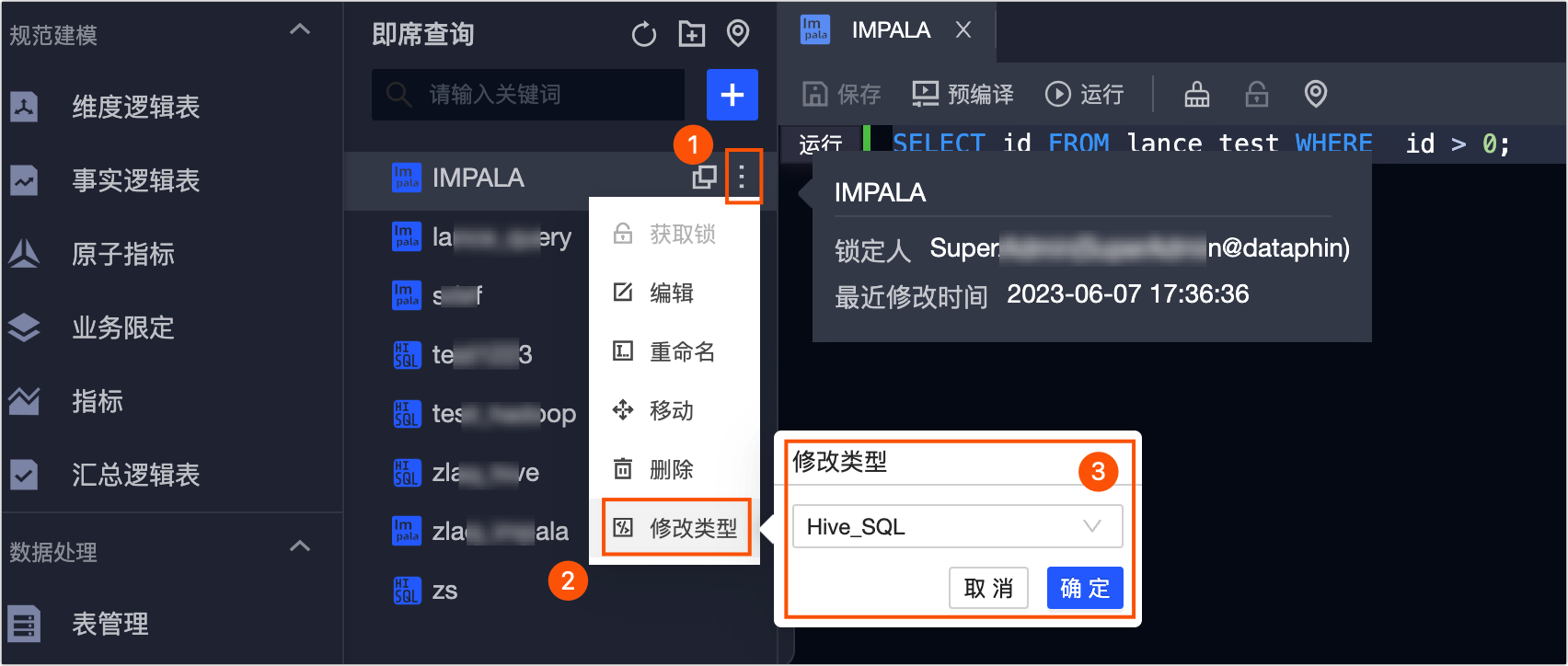
单击确定,即可完成任务类型切换。