
在本实验中,您将体验基于OpenLake House环境下的零售电子商务数据开发与分析场景,通过DataWorks实现面向多引擎协同开发、可视化工作流编排和数据目录管理等。同时实践Python编程及调试,并使用Notebook进行与AI联动的交互式数据探索与分析。
背景介绍
DataWorks简介
DataWorks是智能湖仓一体数据开发治理平台,内置阿里巴巴15年大数据建设方法论,深度适配阿里云MaxCompute、E-MapReduce、Hologres、Flink、PAI 等数十种大数据和AI计算服务,为数据仓库、数据湖、OpenLake湖仓一体数据架构提供智能化ETL开发、数据分析与主动式数据资产治理服务,助力“Data+AI”全生命周期的数据管理。自2009年起,DataWorks不断对阿里巴巴数据体系进行产品化沉淀,服务于政务、金融、零售、互联网、汽车、制造等行业,使数以万计的客户信赖并选择DataWorks进行数字化升级和价值创造。
DataWorks Copilot简介
DataWorks Copilot是您在DataWorks的智能助手,在DataWorks,您可以自由选择用DataWorks默认模型、Qwen3-235B-A22B、DeepSeek-R1-0528或Qwen3-Coder大模型来完成相关Copilot产品操作。借助DeepSeek-R1的深度推理能力,DataWorks Copilot可以帮助您通过自然语言交互完成更为复杂的SQL代码生成、优化、测试等操作,显著提升ETL开发和数据分析效率。
DataWorks Notebook简介
DataWorks Notebook是智能化交互式数据开发和分析工具,能够面向多种数据引擎开展SQL或Python分析,即时运行或调试代码,获取可视化数据结果。同时,DataWorks Notebook能够与其他任务节点混合编排为工作流,提交至调度系统运行,助力复杂业务场景的灵活实现。
注意事项
使用限制
OpenLake只支持数据湖构建(DLF)2.0版本。
数据目录只支持数据湖构建(DLF)2.0版本。
Qwen3-235B-A22B/DeepSeek- R1模型支持地域:华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华南1(深圳)、西南1(成都)。
Qwen3-Coder模型支持地域为华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华北6(乌兰察布)、华南1(深圳)、西南1(成都)。
环境准备
- 说明
请选择参加数据开发(Data Studio)(新版)公测。
实验步骤
步骤一:数据目录管理
湖仓一体的数据目录管理能力,支持对DLF、MaxCompute、Hologres等进行数据目录管理及新建。
在Data Studio页面,单击页面左侧一级菜单
 ,进入数据目录功能。在数据目录左侧列表上找到您需要管理的元数据类型,单击添加项目(不同元数据类型按钮存在差异,本文以MaxCompute为例)。
,进入数据目录功能。在数据目录左侧列表上找到您需要管理的元数据类型,单击添加项目(不同元数据类型按钮存在差异,本文以MaxCompute为例)。您可以按需添加DataWorks工作空间中已创建的数据源,也可以在MaxCompute-项目页签下选择当前账号具有相关权限的MaxCompute项目。

添加项目后,即可在对应元数据类型下看到已添加的项目,您可以单击项目名称,进入数据目录详情页。
在数据目录详情页选择Schema后,单击任意表名可进入该表的详情页面查看表详情。
数据目录支持您可视化建表。
展开数据目录至指定Schema的表层级,单击右侧的
 ,进入新建表页面。
,进入新建表页面。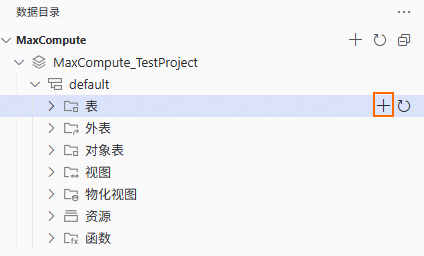
在新建表页面,您可以通过多种方式建表:
在区域①中填入表名、字段信息等。
在区域②中直接填入建表DDL语句。
单击页面顶部的发布,完成表创建。
步骤二:工作流编排
工作流(Workflow)支持以业务视角通过可视化拖拽的方式编排多种不同类型的数据开发节点,调度时间等通用参数无需单独配置,可以帮助您轻松管理复杂的任务工程。
在Data Studio页面,单击页面左侧一级菜单
 ,进入数据开发功能。在数据开发左侧列表中找到项目目录,单击项目目录右侧的
,进入数据开发功能。在数据开发左侧列表中找到项目目录,单击项目目录右侧的 ,选择新建工作流。
,选择新建工作流。进入工作流编辑功能界面前,请先输入工作流名称,单击确定,进入工作流编辑界面。
进入工作流编辑功能界面后,单击画布中央的拖拽或点击添加节点,然后在添加节点对话框中,指定节点类型为虚拟节点,自定义节点名称,单击确认。
从工作流编辑功能界面左侧的节点类型列表中找到自己需要的节点类型,并将其拖至画布中,在添加节点对话框中输入节点名称,单击确认。
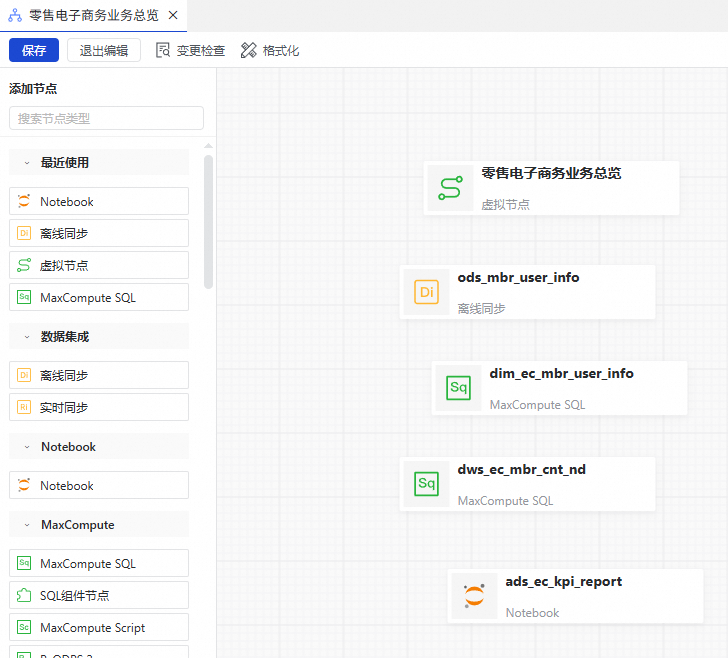
从工作流编辑功能界面右侧的画布上,找到需要建立依赖关系的两个节点,鼠标悬停到其中一个节点下边缘的中间位置,当鼠标变为+后,开始拖动鼠标,将箭头拖动至另一个节点后松开。设置依赖关系如下图所示后,在顶部工具栏单击保存。
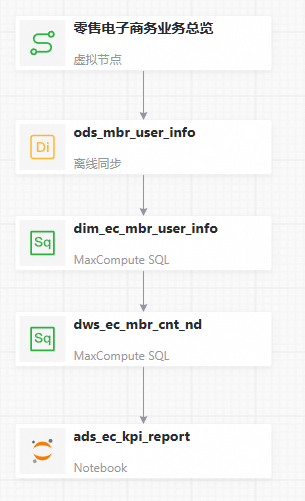
保存成功后,可按需对画布进行布局调整。
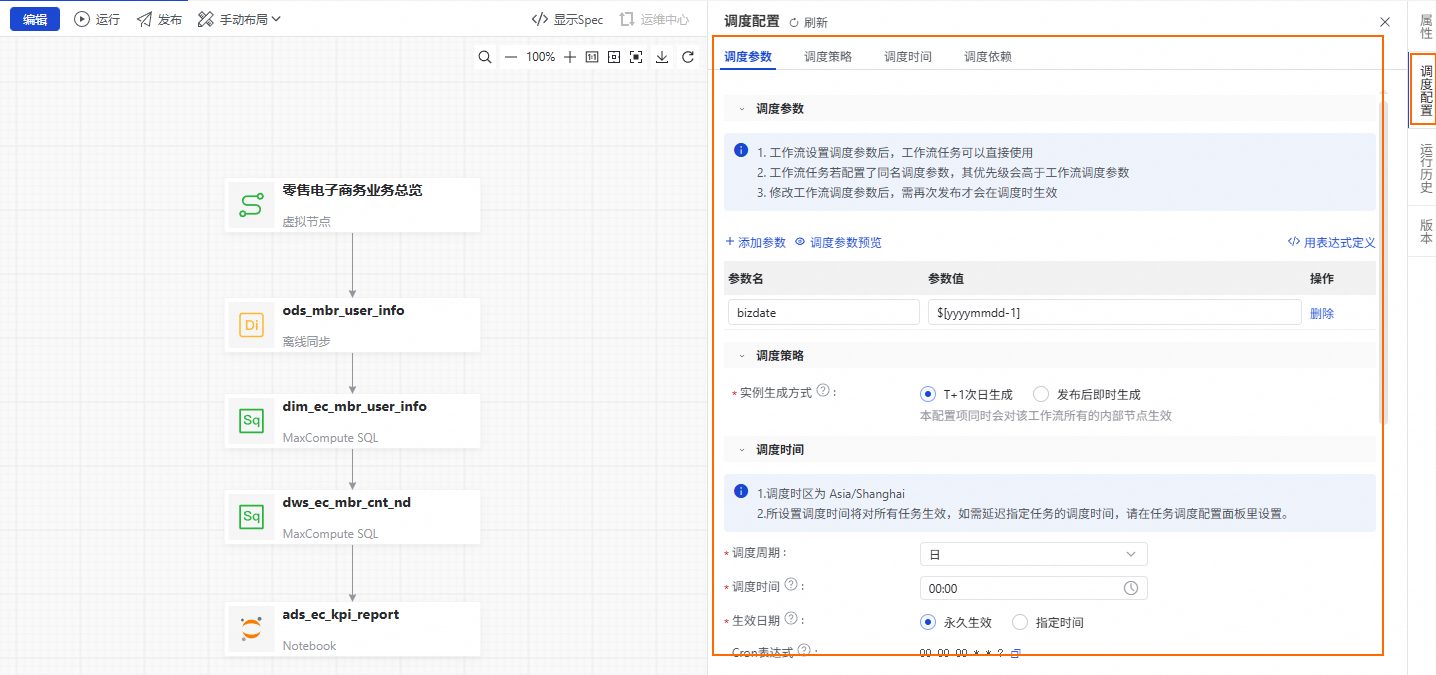
从工作流画布右侧找到并单击调度配置,在调度配置面板中,依次配置工作流的调度参数及节点依赖。单击调度参数中的添加参数,参数名输入框中输入bizdate,在参数值下拉列表中选择$[yyyymmdd-1]。
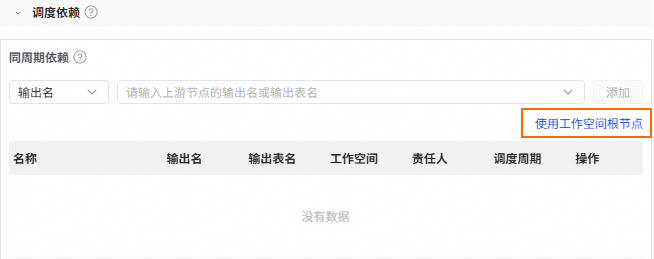
单击使用工作空间根节点,将工作空间根节点作为工作流的上游依赖。
单击工作流画布上方的发布,页面右下方会出现发布操作界面,单击上线发布内容操作界面中的开始发布生产后,依次进行检查和确认即可。

步骤三:多引擎协同开发
Data Studio支持数据集成、MaxCompute、Hologres、EMR、Flink、Python、Notebook、ADB等数十种不同引擎类型的节点的数仓开发,支持复杂的调度依赖,提供开发环境与生产环境隔离的研发模式。本实验以创建Flink SQL Streaming节点为例。
在Data Studio页面,单击页面左侧一级菜单
 ,进入数据开发功能界面。在数据开发功能界面左侧列表中找到项目目录,单击项目目录右侧的
,进入数据开发功能界面。在数据开发功能界面左侧列表中找到项目目录,单击项目目录右侧的 ,单击级联菜单中的Flink SQL Streaming进入节点编辑功能界面。在进入节点编辑功能界面前,请先输入节点名称,敲击回车键,等待即可。
,单击级联菜单中的Flink SQL Streaming进入节点编辑功能界面。在进入节点编辑功能界面前,请先输入节点名称,敲击回车键,等待即可。预设节点名称:
ads_ec_page_visit_log。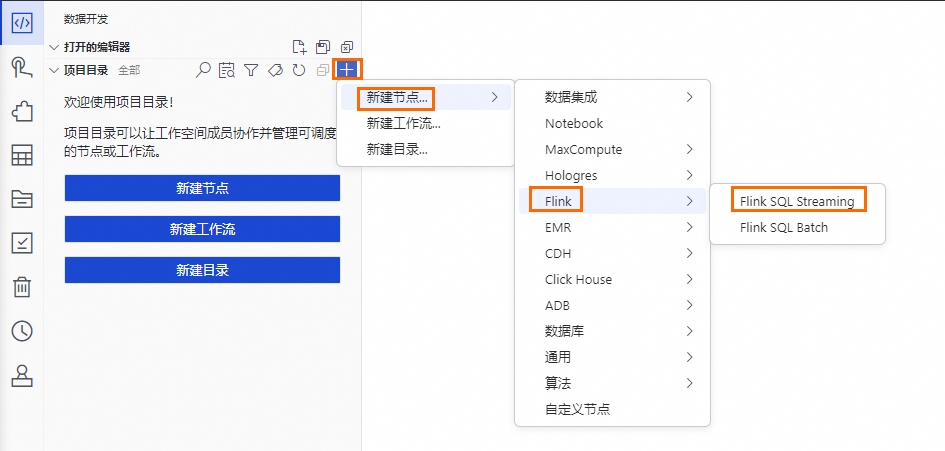
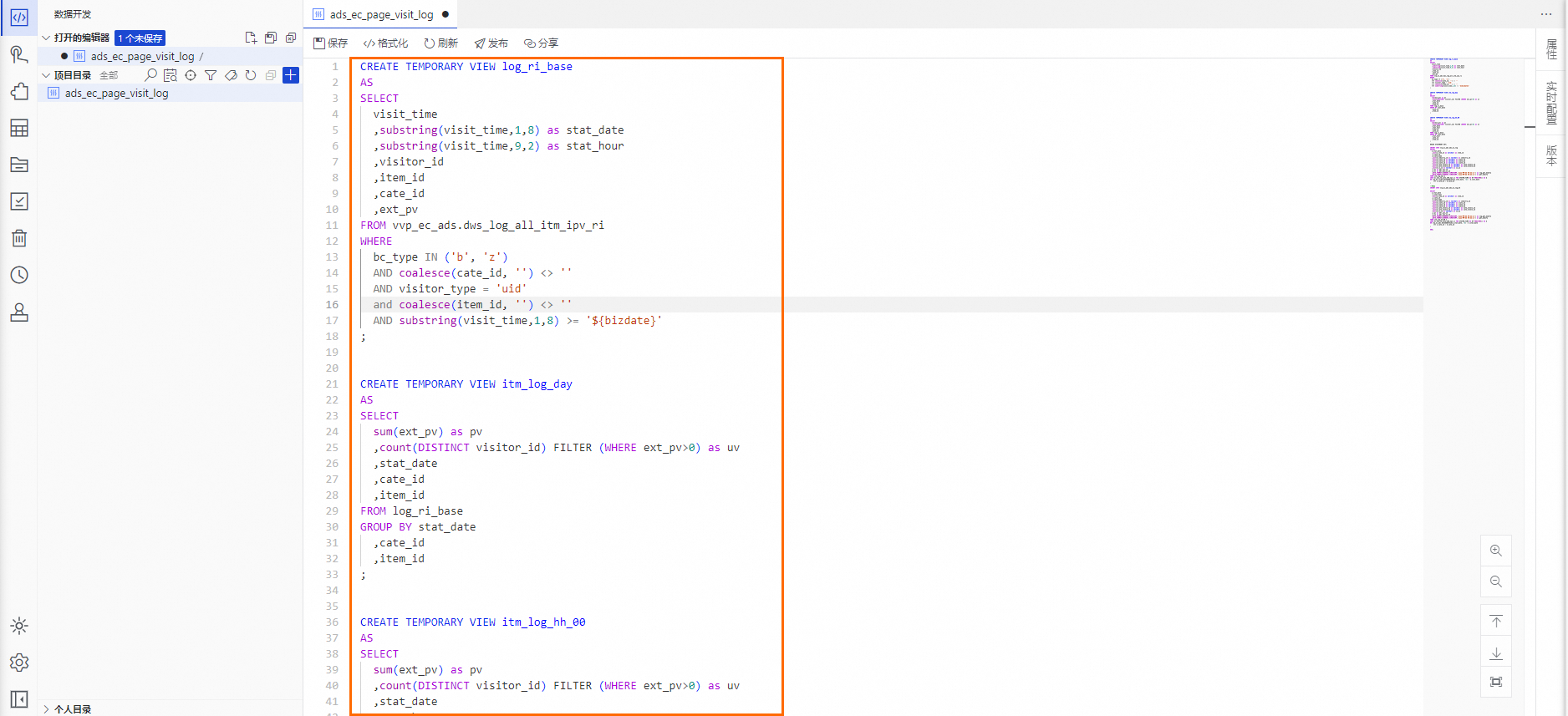
在节点编辑功能界面,将预设Flink SQL Stream代码粘贴到代码编辑器中。
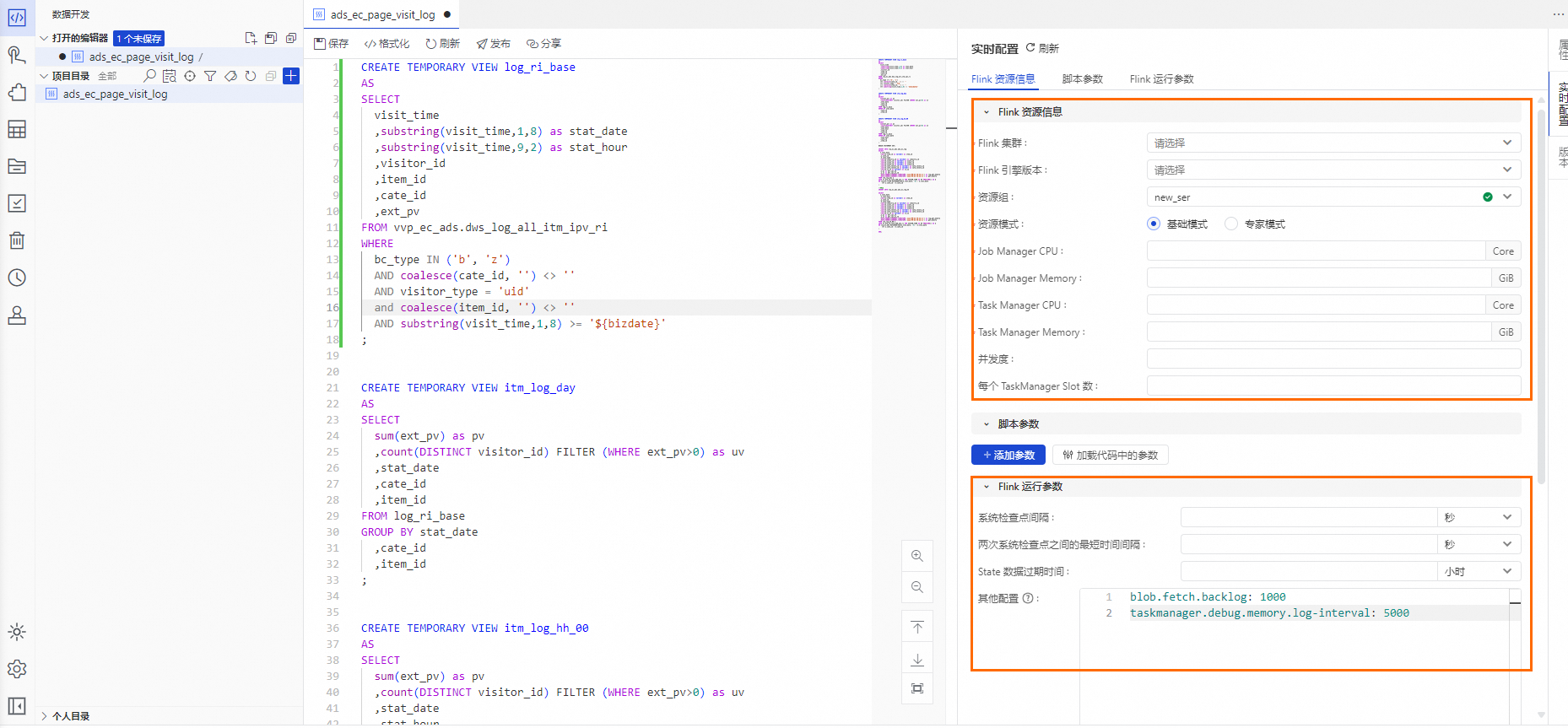
在节点编辑功能界面,单击代码编辑器右侧的实时配置,配置Flink资源信息、脚本参数及Flink运行参数相关参数信息。
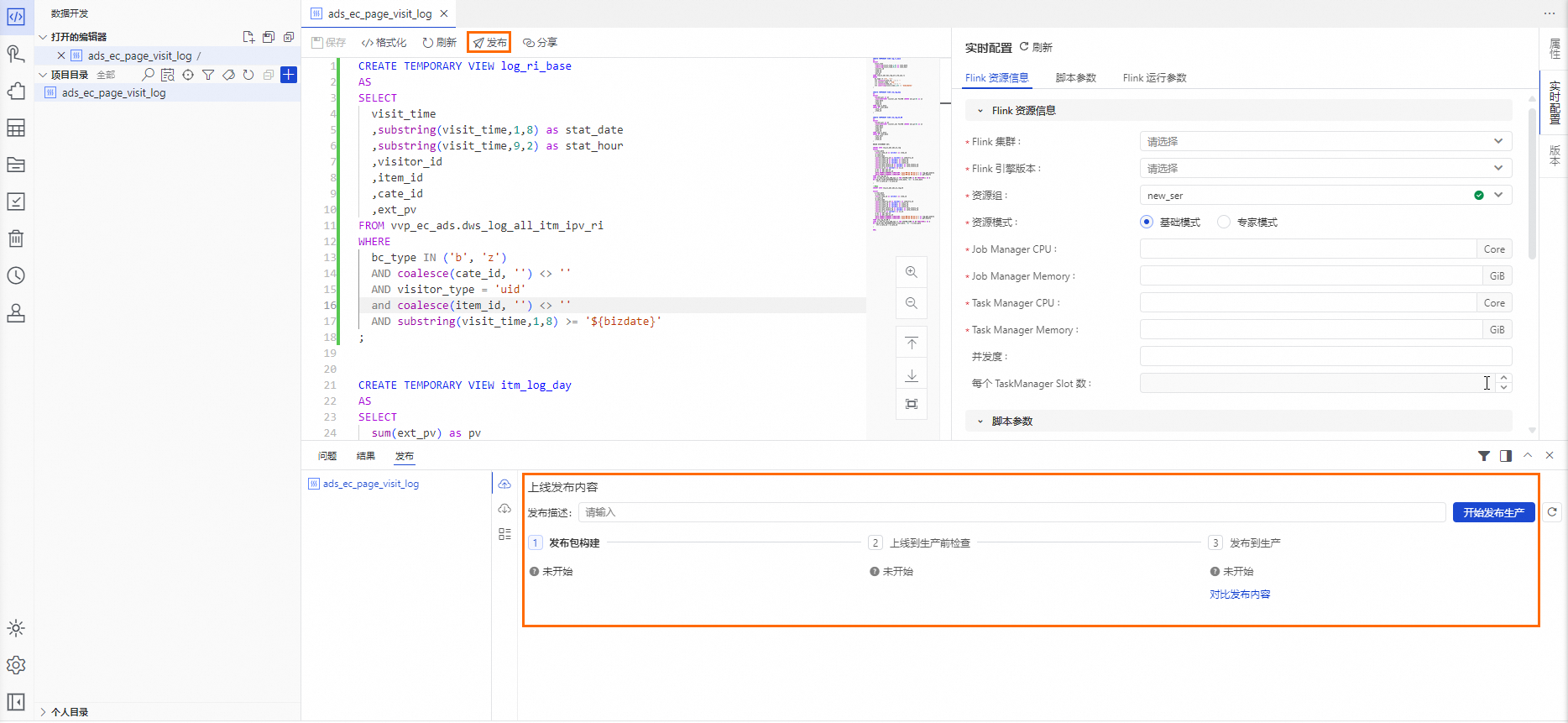
完成实时配置后,单击代码编辑器上方的保存,单击代码编辑器上方的发布,页面右下方会出现发布操作界面,单击上线发布内容操作界面中的开始发布生产后,依次进行检查和确认即可。
步骤四:进入个人开发环境
个人开发环境,支持自定义容器镜像,支持对接用户NAS,支持对接Git,支持Python编程与Notebook。
在Data Studio页面,单击页面顶部![]() ,在下拉菜单中选中您需要进入的个人开发环境,等待页面返回即可。
,在下拉菜单中选中您需要进入的个人开发环境,等待页面返回即可。
步骤五:Python编程与调试
DataWorks深度集成DSW,在进入个人开发环境后,Data Studio支持Python语言的编写、调试、运行及调度。
该步骤需要先完成步骤四:进入个人开发环境后方可开始。
在Data Studio页面,且已进入个人开发环境,单击
workspace目录,单击个人目录右侧的 ,在左侧列表上会新增一个未命名的文件,输入预设文件名称,敲击回车键,等待文件生成即可。
,在左侧列表上会新增一个未命名的文件,输入预设文件名称,敲击回车键,等待文件生成即可。预设文件名称:
ec_item_rec.py。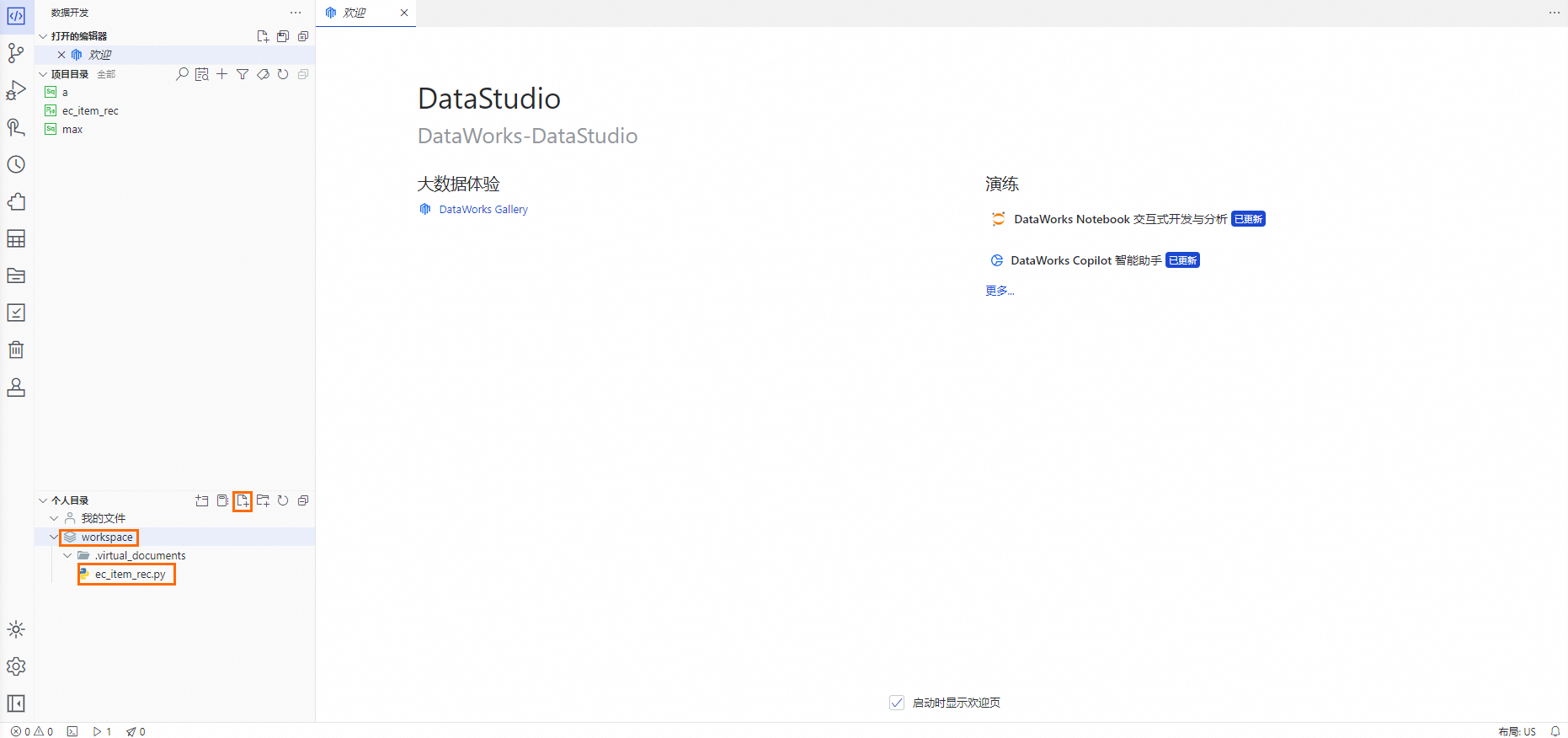
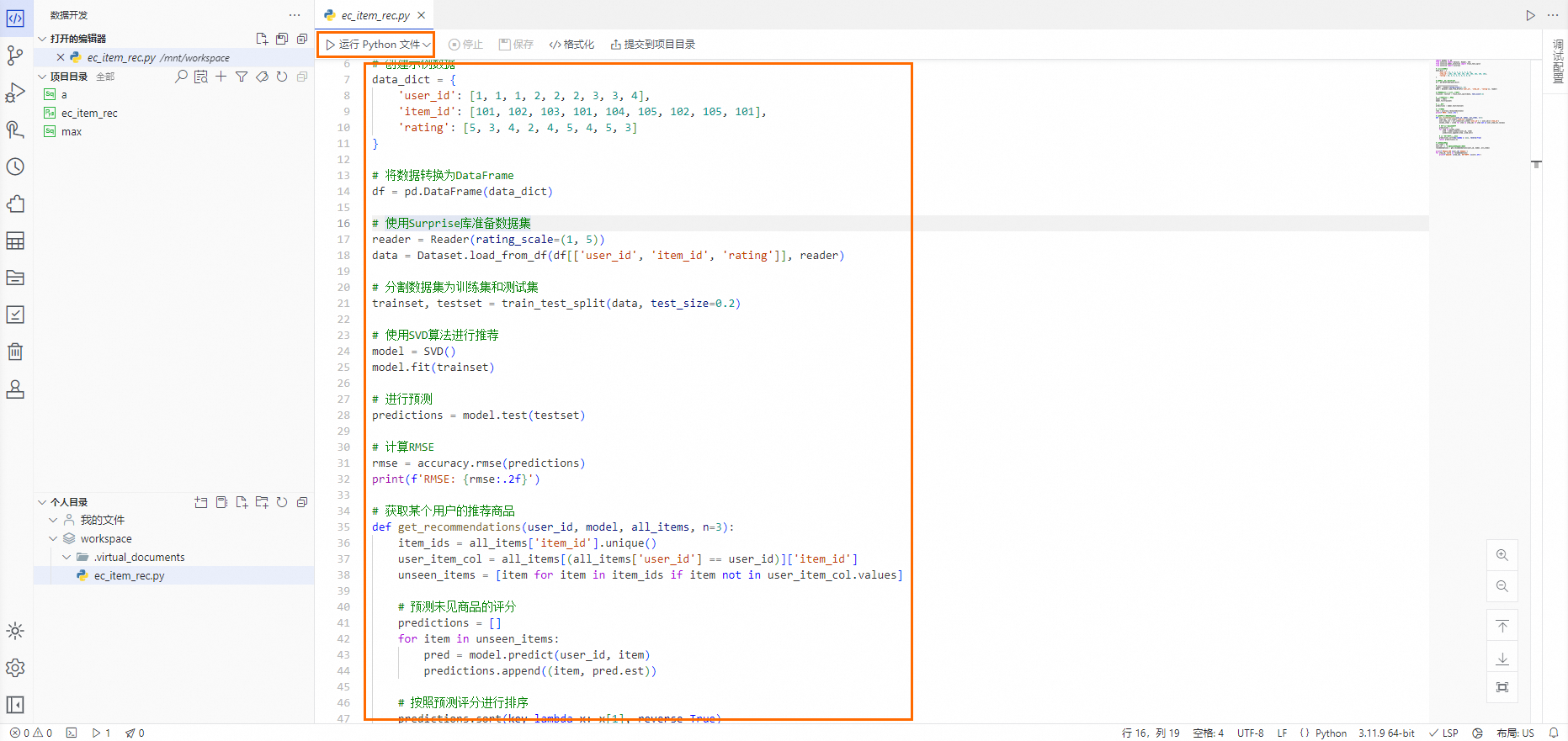
在Python文件编辑页面的代码编辑器中,先输入预设的Python代码,再单击代码编辑器上方的运行Python文件,在页面下方的终端中查询运行结果。
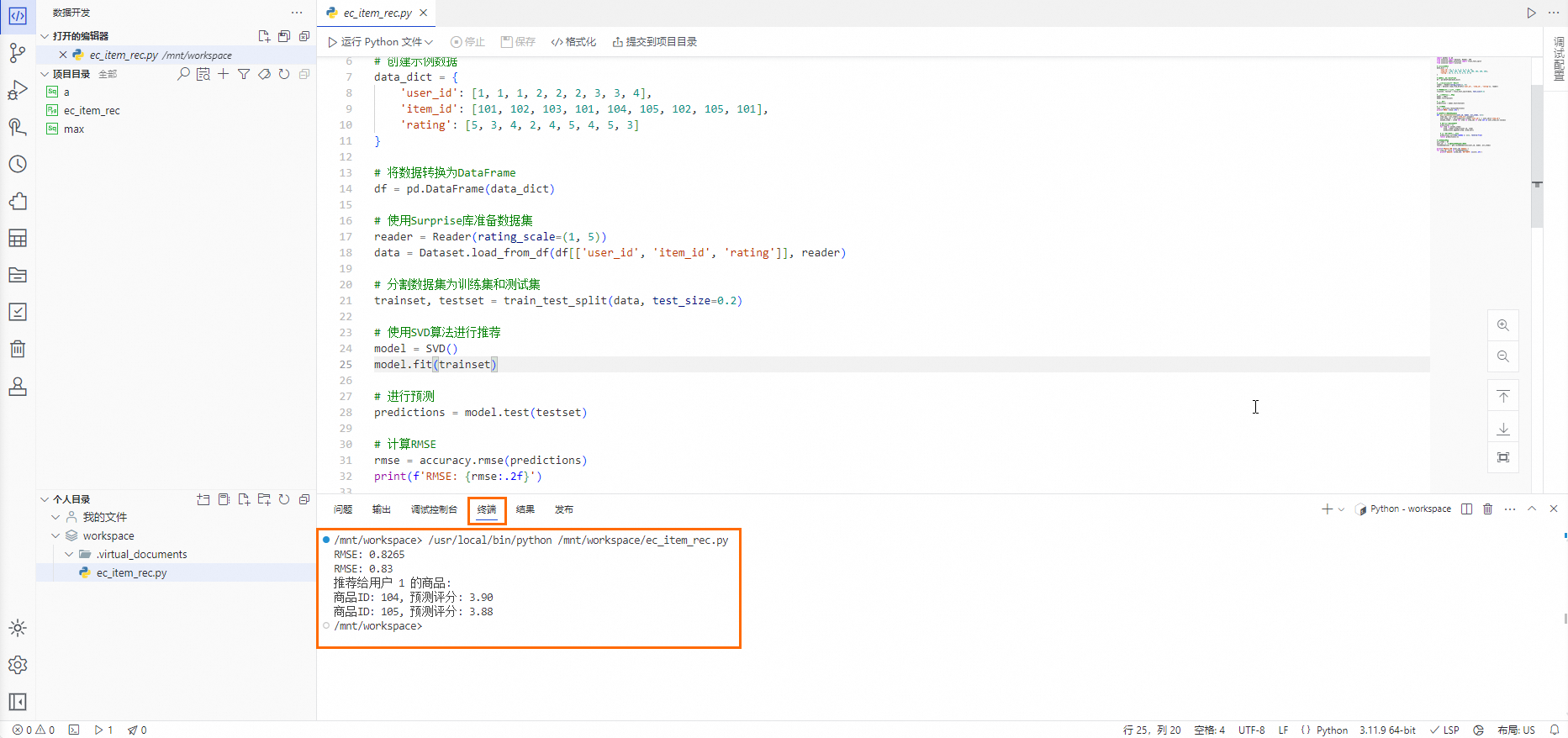
单击Python文件编辑页面的代码编辑器上方的调试Python文件,在代码编辑器中代码行号左侧可以单击生成断点,代码编辑器左侧面板上方单击
 进行代码调试。
进行代码调试。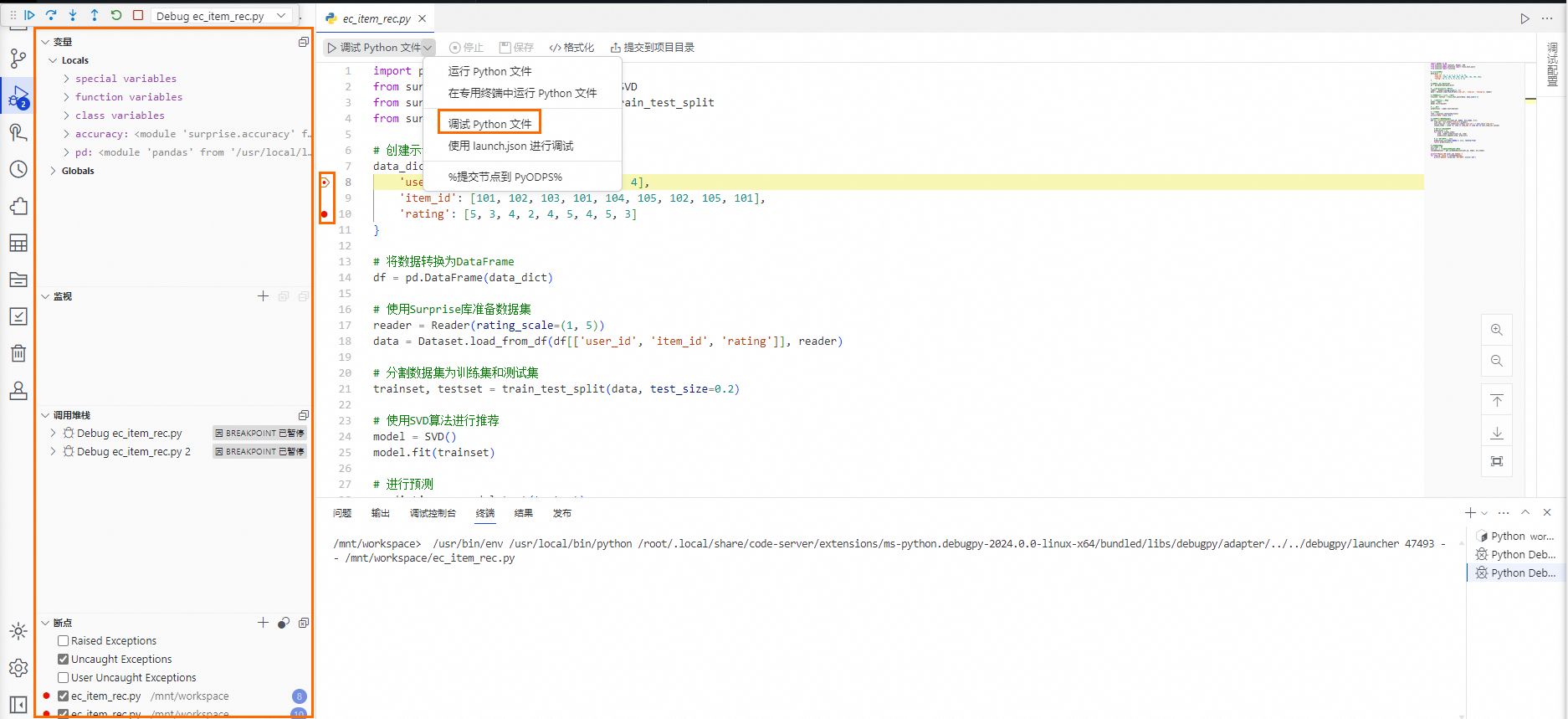
步骤六:Notebook数据探索
在进行Notebook数据探索时,Notebook数据探索相关操作是基于个人开发环境的,您需要先完成前面的步骤四:进入个人开发环境后方可开始。
新建Notebook
进入Data Studio > 数据开发。
在个人目录中,右键单击目标文件夹,选择新建Notebook。
输入Notebook名称,单击回车键 或 页面空白位置,使Notebook名称生效。
在个人目录中单击Notebook名称,即可打开并进入Notebook编辑页面。
Notebook使用
如下内容为独立操作步骤,不分先后顺序,可以按需体验。
Notebook多引擎开发
EMR Spark SQL
在DataWorks Notebook中单击
 按钮,新建SQL Cell。
按钮,新建SQL Cell。在SQL Cell中,输入以下语句,完成dim_ec_mbr_user_info 表的查询。
在SQL Cell右下角,选择SQL Cell类型为EMR Spark SQL,选择计算资源为
openlake_serverless_spark。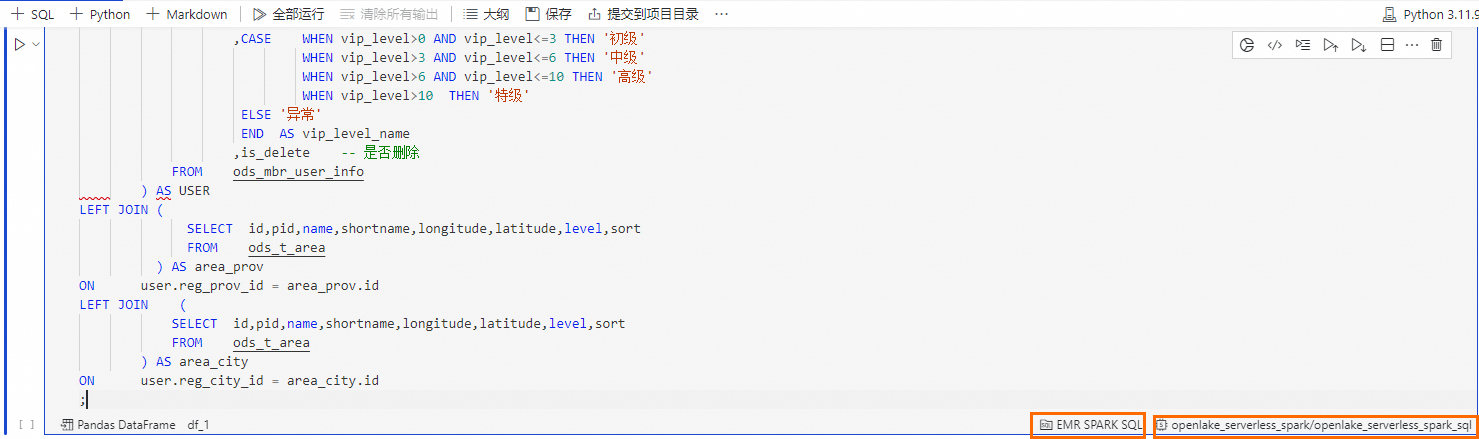
单击运行按钮,等待运行完成,查看数据结果。
StarRocks SQL
在DataWorks Notebook中单击
 按钮,新建SQL Cell,如下图:
按钮,新建SQL Cell,如下图:在SQL Cell中,输入以下语句,完成dws_ec_trd_cate_commodity_gmv_kpi_fy 表的查询。
在SQL Cell右下角,选择SQL Cell类型为StarRocks SQL,选择计算资源为
openlake_starrocks。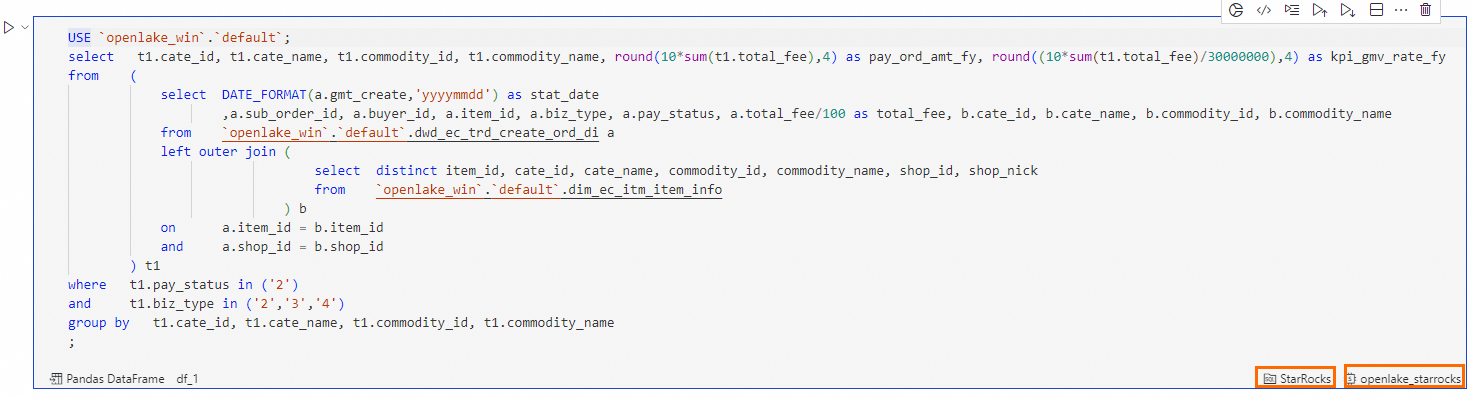
单击运行按钮,等待运行完成,查看数据结果。
Hologres SQL
在DataWorks Notebook中单击
按钮,新建SQL Cell。在SQL Cell中,输入以下语句,完成dws_ec_mbr_cnt_std 表的查询。
在SQL Cell右下角,选择SQL Cell类型为Hologres SQL,选择计算资源为
openlake_hologres。
单击运行按钮,等待运行完成,查看数据结果。
MaxCompute SQL
在DataWorks Notebook中单击
按钮,新建SQL Cell。在SQL Cell中,输入以下语句,完成dws_ec_mbr_cnt_std 表的查询。
在SQL Cell右下角,选择SQL Cell类型为MaxCompute SQL,选择计算资源为
openlake_maxcompute。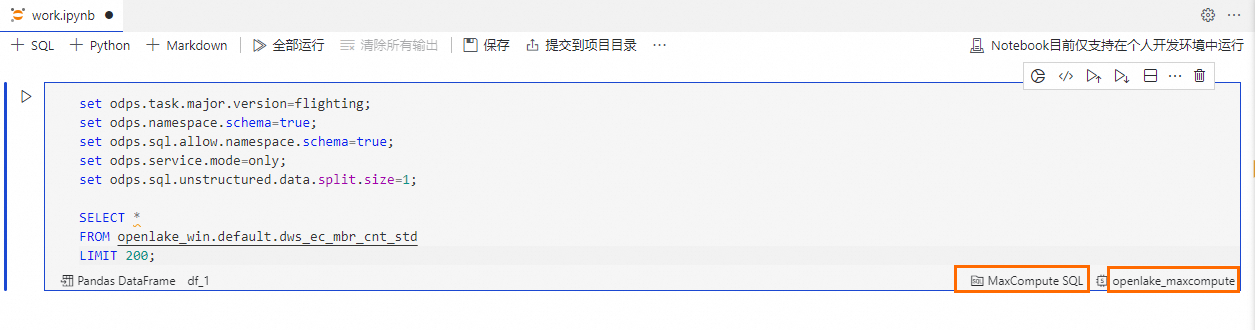
单击运行按钮,等待运行完成,查看数据结果。
Notebook交互式数据
在DataWorks Notebook中单击
 按钮,新建Python Cell。
按钮,新建Python Cell。在Python Cell右上角,单击
 按钮,呼出DataWorks Copilot智能编程助手。
按钮,呼出DataWorks Copilot智能编程助手。在DataWorks Copilot输入框中,输入以下需求,用于生成一个查询会员年龄的ipywidgets交互组件。
说明需求描述:使用Python,生成一个会员年龄的滑动条组件,取值范围从1到100,默认值为20,实时监测组件取值的变化,并将值保存到全局变量query_age中。
查看DataWorks Copilot生成的Python代码,单击接受按钮。

单击Python Cell的运行按钮,等待运行完成,查看交互组件的生成(运行Copilot生成的代码,或预设代码);同时,能够在交互组件中滑动选择目标年龄。

在DataWorks Notebook中单击
 按钮,新建SQL Cell。
按钮,新建SQL Cell。在SQL Cell中,输入以下查询语句,包含Python中定义的会员年龄变量
${query_age}。SELECT * FROM openlake_win.default.dim_ec_mbr_user_info WHERE CAST(id_age AS INT) >= ${query_age};在SQL Cell右下角,选择SQL Cell类型为Hologres SQL,选择计算资源为
openlake_hologres。
单击运行按钮,等待运行完成,查看数据结果。
在运行结果中,单击
 按钮,生成可视化图表。
按钮,生成可视化图表。
Notebook模型开发与训练
在DataWorks Notebook中单击
按钮,新建SQL Cell。在SQL Cell中,输入以下语句,完成ods_trade_order表的查询。
SELECT * FROM openlake_win.default.ods_trade_order;将SQL查询结果写入DataFrame变量中,单击df位置,自定义DataFrame变量名称(例如:
df_ml)。
单击SQL Cell的运行按钮,等待运行完成,查看数据结果。
在DataWorks Notebook中单击
 按钮,新建Python Cell。
按钮,新建Python Cell。在Python Cell中,输入以下语句,使用Pandas完成数据清洗和处理,并存入DataFrame的新变量
df_ml_clean中。import pandas as pd def clean_data(df_ml): # 生成新的一列:预估订单总额 = 商品单价 * 商品数量 df_ml['predict_total_fee'] = df_ml['item_price'].astype(float).values * df_ml['buy_amount'].astype(float).values # 将列 'total_fee' 重命名为 'actual_total_fee' df_ml = df_ml.rename(columns={'total_fee': 'actual_total_fee'}) return df_ml df_ml_clean = clean_data(df_ml.copy()) df_ml_clean.head()单击Python Cell的运行按钮,等待运行完成,查看数据清理结果。
在DataWorks Notebook中单击
按钮,再次新建Python Cell。在Python Cell中,输入以下语句,构建一个线性回归的机器学习模型,并进行训练和测试。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # 获取商品价格及总费用 X = df_ml_clean[['predict_total_fee']].values y = df_ml_clean['actual_total_fee'].astype(float).values # 准备数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=42) # 创建并训练模型 model = LinearRegression() model.fit(X_train, y_train) # 预测和评估 y_pred = model.predict(X_test) for index, (x_t, y_pre, y_t) in enumerate(zip(X_test, y_pred, y_test)): print("[{:>2}] input: {:<10} prediction:{:<10} gt: {:<10}".format(str(index+1), f"{x_t[0]:.3f}", f"{y_pre:.3f}", f"{y_t:.3f}")) # 计算均方误差MSE mse = mean_squared_error(y_test, y_pred) print("均方误差(MSE):", mse)单击运行按钮,等待运行完成,查看模型训练的测试结果。