数据保护伞基于敏感字段类型来配置敏感数据识别规则,规则配置完成后,即可用于识别租户内相应类型的敏感数据。DataWorks为您提供了多种内置敏感字段类型及识别规则,若内置规则不满足您的业务需要,您也可自定义敏感字段类型及识别规则。本文为您介绍如何新建敏感字段类型并配置数据识别规则。
背景信息
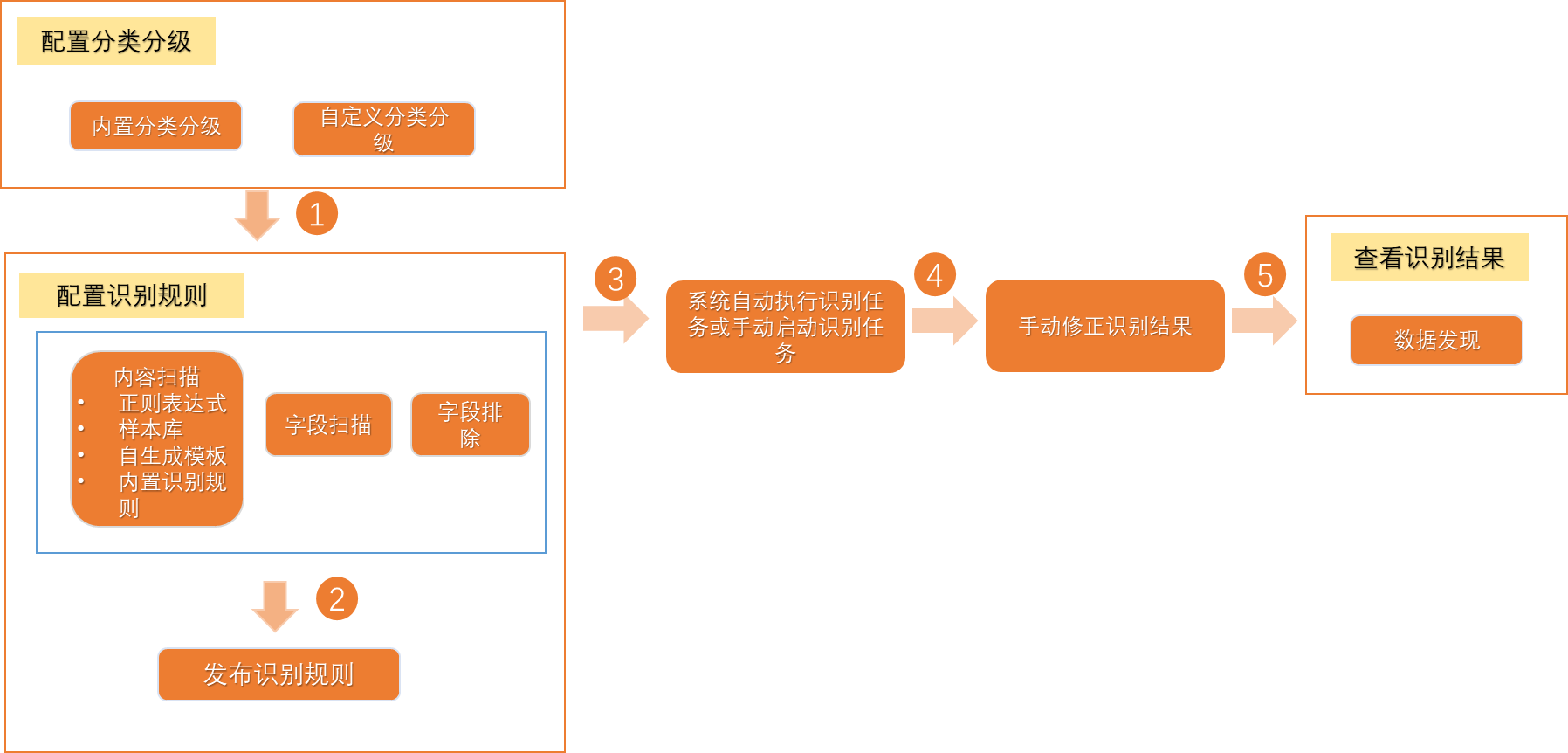
进入数据识别规则页面
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在右侧页面中单击进入安全中心。
单击左侧导航栏的,单击立即体验,进入数据保护伞。
说明若阿里云主账号已授权,则直接进入数据保护伞的首页。
若阿里云主账号未授权,则进入数据保护伞的授权页面。授权后才可使用保护伞的相关功能。
单击左侧导航栏的,进入数据识别规则页面。
步骤一:配置敏感字段所属分类
敏感字段类型需归属于某个数据分类下并定义相应的敏感级别。因此,新增敏感字段类型并配置敏感数据识别规则前,您需先完成敏感数据分类分级配置。
如果您是首次使用数据保护伞的新用户,进入数据识别规则页面后,会在左侧区域展示内置分类分级模板的默认分类,您可输入分类名称进行搜索;也可单击分类名称后的
 图标,执行添加同级分类、添加子分类、重命名和删除分类等操作。
图标,执行添加同级分类、添加子分类、重命名和删除分类等操作。如果您是已使用过数据保护伞的老用户,进入数据识别规则页面后,您可在左侧区域按需创建数据分类。
分类名称必须唯一,仅支持中英文、数字,长度限制1~30个字符。
删除分类时,请先确认该分类下是否有已发布的敏感字段识别规则。如果有,请将该分类下全部规则下架后再删除。详情请参见管理数据识别规则。
敏感数据分级配置,请参见配置敏感数据分类分级。
步骤二:配置敏感数据识别规则
敏感数据识别规则需基于敏感字段类型配置,本文以新增敏感字段类型并配置数据识别规则示例,介绍配置详情。您也可基于平台内置的敏感字段类型配置数据识别规则。
在数据识别规则页面,单击右上角的+敏感字段类型,新增敏感字段类型。
配置敏感字段类型的基本信息。
在基本信息页签,配置敏感字段的类型、分类分级等信息。
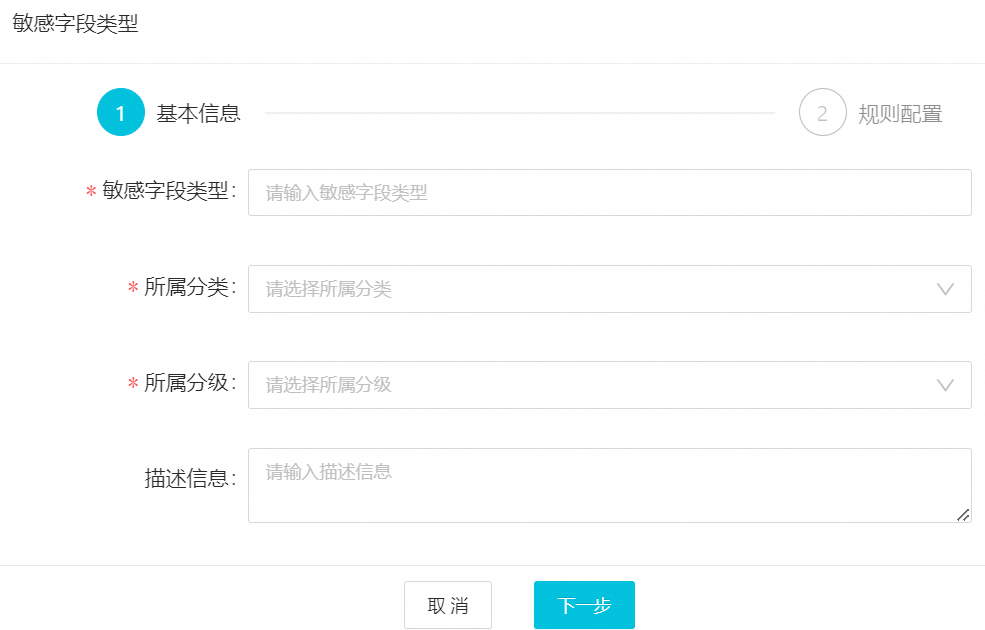
主要参数说明如下。
参数
描述
敏感字段类型
自定义敏感字段类型的名称,例如:姓名、身份证号、手机号等。名称必须唯一。
所属分类
选择敏感字段类型所属的分类。若现有分类不满足需求,请进入数据分类分级页面进行设置,详情请参见配置敏感数据分类分级。
所属分级
选择敏感字段类型所属的级别,数字越大,敏感级别越高。若现有分级不满足需求,请进入数据分类分级页面进行设置,详情请参见配置敏感数据分类分级。
单击下一步。
配置敏感字段类型的识别规则。
在规则配置页签,配置敏感字段识别规则及规则的命中条件,并测试规则准确性。
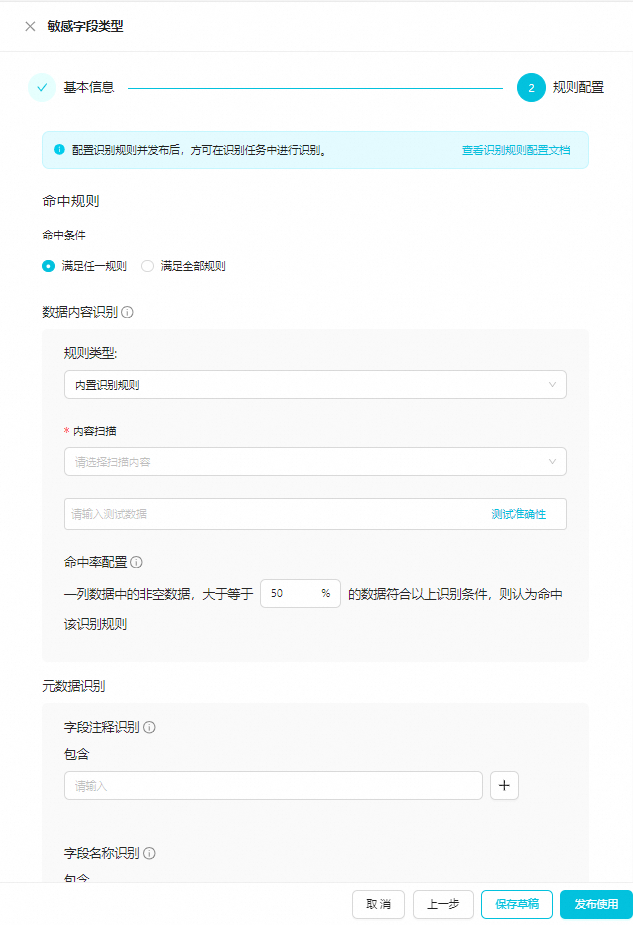
参数
描述
命中规则
在右侧下拉列表中选择识别规则的命中条件:
满足任一规则:满足
数据内容识别或字段名称识别中的任何一个条件,即可命中识别规则。满足全部规则:需同时满足
数据内容识别和字段名称识别的所有条件,才可命中识别规则。
说明命中规则仅对
数据内容识别和字段名称识别规则生效。数据内容识别
用于识别字段的内容(即字段的取值)。例如,
name字段取值为张三,则规则将识别张三。说明仅DataWorks专业版及以上版本,才可使用内容扫描功能。若您使用的是低版本的DataWorks,请升级至专业版及以上版本。升级详情,请参见DataWorks版本服务计费说明。
根据规则类型定义敏感数据识别规则的内容,用于匹配敏感数据文本。规则类型具体如下:
字段名称识别
用于识别字段的名称。例如,
name字段取值为张三,则规则将识别name。输入需要识别为敏感数据的字段,支持多个字段匹配,各字段间为
或关系。不同数据源的输入格式如下:EMR:
project.table.columnMaxCompute:
project.schema.table.column(schema不填则默认为default)。Hologres:
instance_id.project.table.column
输入格式中,任意一段都可使用*作为通配符。例如:
a.b.*:表示a项目的b表中所有字段都会被识别为敏感数据。
ab*.c*.salary:表示ab开头的项目中,c开头的表的所有salary字段都会被识别为敏感数据。
*cd.ef*.sa*ry :表示cd结尾的项目下,ef开头的表中,所有以sa开头、ry结尾的字段都会被识别为敏感数据。
字段注释识别
用于识别字段的注释。例如,配置手机号类型敏感字段对应的字段注释为手机号、联系方式。当识别到某数据的注释信息包含联系方式时,该数据将被识别为手机号。
在输入框中输入字段注释,字符长度0~100,字符不限,可添加多个输入框,最多10个。
字段排除
在输入框中输入需要排除的字段,符合字段排除规则的字段将不会被该识别规则命中。支持多个字段匹配,各字段间为
或关系。不同数据源的输入格式如下:EMR:
project.table.columnMaxCompute:
project.schema.table.column(schema不填则默认为default)。Hologres:
instance_id.project.table.column
输入格式中,任意一段都可使用*作为通配符。例如:
a.b.*:表示a项目的b表中所有字段都会被识别为敏感数据。
ab*.c*.salary:表示ab开头的项目中,c开头的表的所有salary字段都会被识别为敏感数据。
*cd.ef*.sa*ry :表示cd结尾的项目下,ef开头的表中,所有以sa开头、ry结尾的字段都会被识别为敏感数据。
命中率配置
用于自定义规则命中率,即配置一列数据中的非空数据,符合
数据内容识别条件的数据占比超过多少时(例如,50%),认为命中该识别规则。默认为50%。命中率的计算公式为:
100%*该列中命中识别规则的数据条数/该列数据的总条数。说明命中率仅对
数据内容识别规则生效。发布数据识别规则。
单击发布使用,即可发布当前数据识别规则。规则发布后,才可使用该规则在识别任务中识别相应敏感数据。
若您暂时无需使用该规则,也可单击保存草稿,保存数据识别规则。
若某列数据命中多个敏感字段类型的识别规则,规则的生效顺序如下:
当这些敏感字段类型的命中条件仅个数相同时,识别顺序为。
当这些敏感字段类型的命中条件个数和类型都相同时,优先命中分级等级高的敏感字段类型识别规则。
步骤三:授权并启动敏感数据识别任务
敏感数据识别规则配置完成后,您需要授权并启动敏感数据识别任务,启动后,平台才会基于敏感数据识别规则识别租户内的敏感数据。
为敏感数据识别任务授权。
单击敏感数据识别页面左上方的开启任务,按照界面指引授权。
说明敏感数据识别任务启动后,单击敏感数据识别页面右上角的授权记录,即可查看授权详情。
启动敏感数据识别任务。
配置敏感数据识别任务。
在开启敏感数据识别任务对话框,配置任务类型、扫描方式及范围。
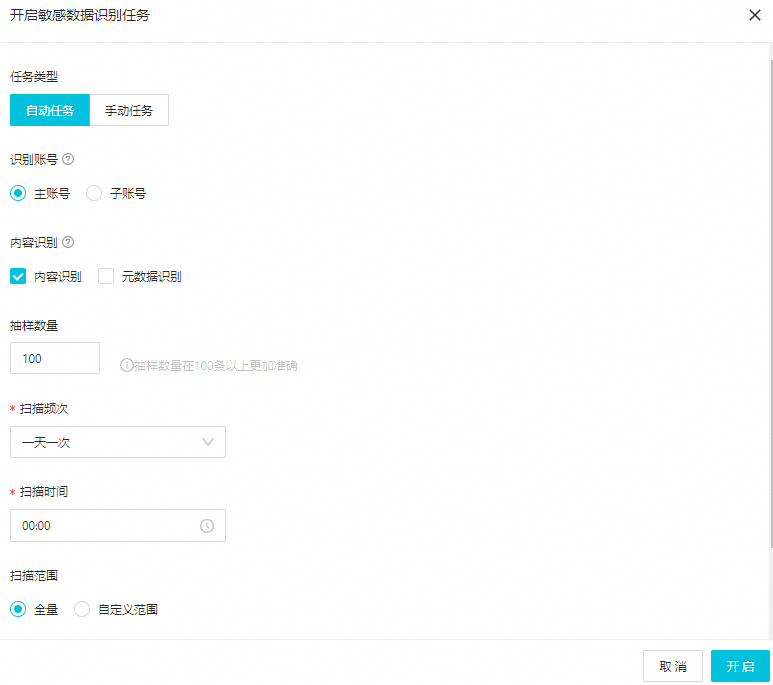
参数说明如下。
参数
描述
任务类型
选择敏感数据识别任务的执行类型。
自动任务:启动任务后,平台将按照任务定义的扫描范围及时间周期性自动执行。
手动任务:启动任务后,平台仅根据此次任务定义的扫描范围进行数据扫描。该类型为一次性任务,任务执行完成,则本次任务结束。
识别账号
配置通过主账号或某个子账号抽样及扫描数据。账号的权限不同,可抽样及扫描的数据范围存在差异。
内容识别
配置敏感数据识别规则中的内容识别及元数据识别是否生效。勾选后,相应规则才会生效。
说明若不勾选内容识别,则数据保护伞将不会对数据进行抽样和扫描,敏感数据识别规则中的内容识别规则将不生效,但是字段名称、字段注释规则依然生效。
抽样数量
配置内容识别的抽样数量,建议数量大于100。
当勾选内容识别后,需配置该参数。
扫描频次及扫描时间
定义自动任务的扫描周期。
仅当任务类型选择自动任务时,需配置该参数。
扫描范围
配置敏感数据识别任务扫描的数据范围。
全量:扫描当前租户所授权账号下的全部数据。
部分数据:可选择扫描指定项目空间下的表数据。
说明项目空间范围默认为全部数据引擎的所有项目空间。
目前仅支持选择扫描ODPS项目的指定表的数据。
表名总长度为
0~100,字符不限,不填代表扫描全部表。支持
.*通配符。例如,.*name表示以name为后缀;private.*表示以private为前缀。多个表名或字段名请用英文逗号(,)分隔。
选择部分数据,即可添加多个项目空间/数据库扫描范围,最终扫描范围取多个范围的并集。
单击开启,启动扫描任务。
启动后,任务状态将变更如下:
手动任务:变更为任务进度条,待进度达到100%后表示任务扫描完成。进度计算方式为=(本次任务中已识别的表数量/本次任务中全部要识别的表数量)*100%。
自动任务:变更为开启中。到达任务配置的扫描时间后,平台将按照相关配置进行敏感数据识别。
说明识别规则修改后,新规则将在下一次自动任务(非实时)中启用,若需要实时触发新任务,您需要手动启动任务。
扫描任务结束后,任务状态将更新为无任务。
管理数据识别规则
复制规则:若您需快速复制已有规则,可单击
 图标。新生成的规则名称默认添加后缀
图标。新生成的规则名称默认添加后缀-复制,且状态为草稿,您可按需配置。编辑规则:若您需修改规则信息,可单击
 图标。说明
图标。说明通过内置敏感字段类型配置的规则,不支持修改基本信息。
规则被修改后,历史规则命中的字段识别结果将被清理。
删除规则:若某规则后续无需再使用,可单击
 图标删除。重要
图标删除。重要删除某敏感数据类型的识别规则影响较大,请仔细阅读以下影响后再确认是否删除。
识别结果中该敏感字段类型的记录将会删除。详情请参见手动修正数据。
数据发现中的敏感数据分布信息将不统计该敏感字段类型。详情请参见敏感数据概况。
已配置的风险识别规则中有对应配置项的将会取消该敏感字段类型。详情请参见风险识别管理(旧版)
批量发布规则:规则发布后,平台才会使用该规则识别相应敏感数据。若规则较多,可通过批量功能发布。
在数据识别规则页面,单击批量发布,勾选需要发布的规则。
说明仅支持勾选草稿状态的规则。
单击发布。发布后,对应规则的状态将置为已发布。
说明若无需发布,可单击取消,该敏感字段即可恢复原始草稿状态。
批量下架规则:下架对应规则后,平台将不再进行该类敏感数据的识别。数据发现、手动修正数据等模块中的该类敏感字段类型的记录将会删除。执行下架操作前,请确认该敏感字段类型的识别规则是否被数据脱敏规则及风险识别规则引用,若已使用,则需先将数据脱敏规则置为失效,并取消风险识别规则中的引用。详情请参见创建数据脱敏规则和风险识别管理(旧版)。
在数据识别规则页面,单击批量下架,勾选需要下架的规则。
说明仅支持勾选已发布状态的规则。
单击下架。下架后,对应规则的状态将置为草稿。
说明若无需下架,可单击取消,该规则即可恢复原始已发布状态。
后续操作:查看任务执行记录
会保留近1周已完成任务的记录(不包含当前正在进行中的记录),您可查看任务的开始时间,结束时间,耗时,任务类型,责任人和数据范围等详情。