
本文将为您介绍如何在敏感数据识别页面,新建数据识别任务,对规则识别不准确的数据进行手动修正。
手动修正的数据结果,在第2天才会生效展示。
背景信息
DataWorks支持您对数据识别规则识别不准确的敏感数据进行手动修正,手动修正数据的使用逻辑如下图所示。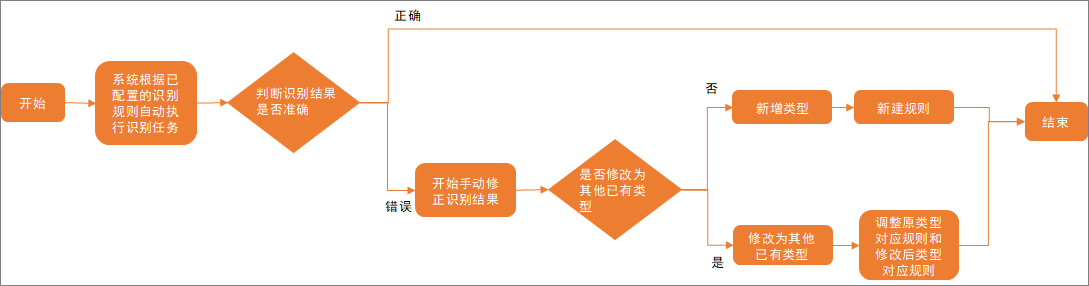
新建识别任务
-
进入数据识别规则。详情请参见:进入数据识别规则页面。
-
单击识别任务页签,进入识别任务页面。
-
启动敏感数据识别任务。
-
配置敏感数据识别任务。
在开启敏感数据识别任务对话框,配置任务类型、扫描方式及范围,可配置实时任务、定时任务或手动新建识别任务。
-
选择配置实时任务。
实时任务配置对话框中包含识别账号、扫描方式及数据范围等配置项。参数说明如下。
参数
描述
识别账号
配置通过主账号或某个子账号抽样及扫描数据。通过选择的当前账号对数据进行抽样和扫描,账号权限不同,可抽样的数据范围会有所不同。
说明通过子账号进行识别,使用的子账号需要先获得MaxCompute项目空间的权限。
实时识别
仅ODPS支持实时识别,当ODPS元数据发生变更(新增表、字段、字段变更),数据保护伞将针对变更的元数据自动启动敏感数据识别。
数伞实时获取元数据变更信息。如果是新增表或字段引起的元数据变更,新的表及字段可能暂无内容,因此仅会使用元数据进行敏感数据识别。
-
选择配置定时任务。参数说明如下。
参数
描述
任务执行
需手动开启任务执行。
后续识别任务扫描及更新策略
含两种选择:
-
仅针对发生变更的规则,以及变更规则受影响的数据及无结果数据,重新扫描并更新结果。
-
全部数据重新扫描并结果全覆盖。
可勾选手动修正结果不覆盖。
识别账号
配置通过主账号或某个子账号抽样及扫描数据。通过选择的当前账号对数据进行抽样和扫描,账号的权限不同,可抽样及扫描的数据范围存在差异。
说明通过子账号进行抽样及扫描,使用的子账号需要先获得MaxCompute项目空间的权限。
内容识别
配置敏感数据识别规则中的内容识别及元数据识别是否生效。勾选后,相应规则才会生效。
说明若不勾选内容识别,则数据保护伞将不会对数据进行抽样和扫描,敏感数据识别规则中的内容识别规则将不生效,但是字段名称、字段注释规则依然生效。
抽样数量
配置内容识别的抽样数量,建议数量大于100。
当勾选内容识别后,需配置该参数。
扫描频次及扫描时间
定义定时任务的扫描周期。
仅当任务类型选择定时任务时,需配置该参数。
扫描频次可选一周一次或一天一次。一周一次自定义范围为周一至周五。时间范围为0:00-23:59。
扫描范围
配置敏感数据识别任务扫描的数据范围。
-
全量:扫描当前租户所授权账号下的全部数据。
-
部分数据:可选择扫描指定项目空间下的表数据。
说明-
项目空间范围默认为全部数据引擎的所有项目空间。
-
目前支持选择扫描ODPS、EMR、HOLO项目的指定表的数据。
-
表名总长度为
0~100,字符不限,不填代表扫描全部表。 -
支持
.*通配符。例如,.*name表示以name为后缀;private.*表示以private为前缀。 -
多个表名或字段名请用英文逗号(,)分隔。
-
-
选择部分数据,即可添加多个项目空间/数据库扫描范围,最终扫描范围取多个范围的并集。
-
用户需在页面左侧手动选择项目空间。
-
用户选中项目空间后,页面右侧会展示该项目空间/数据库范围内的数据表,可手动勾选或一键全选,默认选择该数据库范围内的所有数据表。
-
项目空间/数据库范围、数据表均支持关键字搜索。数据表关键字搜索功能,需先选择项目空间,在指定项目空间内进行搜索。
-
-
-
-
选择配置手动任务,即新建识别任务。参数说明如下。
参数
描述
识别任务扫描及更新策略
含两种选择:
-
仅针对发生变更的规则,以及变更规则受影响的数据及无结果数据,重新扫描并更新结果。
-
全部数据重新扫描并结果全覆盖。
可勾选手动修正结果不覆盖。
识别账号
配置通过主账号或某个子账号抽样及扫描数据。通过选择的当前账号对数据进行抽样和扫描,账号的权限不同,可抽样及扫描的数据范围存在差异。
说明通过子账号进行抽样及扫描,使用的子账号需要先获得MaxCompute项目空间的权限。
内容识别
配置敏感数据识别规则中的内容识别及元数据识别是否生效。勾选后,相应规则才会生效。
说明若不勾选内容识别,则数据保护伞将不会对数据进行抽样和扫描,敏感数据识别规则中的内容识别规则将不生效,但是字段名称、字段注释规则依然生效。
抽样数量
配置内容识别的抽样数量,建议数量大于100。
当勾选内容识别后,需配置该参数。
扫描范围
配置敏感数据识别任务扫描的数据范围。
-
全量:扫描当前租户所授权账号下的全部数据。
-
部分数据:可选择扫描指定项目空间下的表数据。
说明-
项目空间范围默认为全部数据引擎的所有项目空间。
-
目前支持选择扫描ODPS、EMR、HOLO项目的指定表的数据。
-
表名总长度为
0~100,字符不限,不填代表扫描全部表。 -
支持
.*通配符。例如,.*name表示以name为后缀;private.*表示以private为前缀。 -
多个表名或字段名请用英文逗号(,)分隔。
-
-
选择部分数据,即可添加多个项目空间/数据库扫描范围,最终扫描范围取多个范围的并集。
-
用户需在页面左侧手动选择项目空间。
-
用户选中项目空间后,页面右侧会展示该项目空间/数据库范围内的数据表,可手动勾选或一键全选,默认选择该数据库范围内的所有数据表。
-
项目空间/数据库范围、数据表均支持关键字搜索。数据表关键字搜索功能,需先选择项目空间,在指定项目空间内进行搜索。
-
-
-
-
-
单击开启,启动扫描任务。
启动后,任务状态将变更如下:
-
实时任务:变更为开启中。
-
定时任务:变更为开启中。到达任务配置的扫描时间后,平台将按照相关配置进行敏感数据识别。
-
新建识别任务:变更为任务进度条,待进度达到100%后表示任务扫描完成。进度计算方式为=(本次任务中已识别的表数量/本次任务中全部要识别的表数量) × 100%。
说明-
识别规则修改后,新规则将在下一次定时任务(非实时)中启用,若需要实时触发新任务,您需要手动新建识别任务。
-
扫描任务结束后,任务状态将更新为无任务。
-
-
手动修正识别结果
-
进入数据识别规则。详情请参见:进入数据识别规则页面。
-
单击识别结果页签,进入识别结果页面。
-
手动修正识别结果不准确的数据。
操作
描述
筛选引擎类型
在识别结果页面的筛选区域,您可以通过下拉选择数据引擎。
说明目前支持对ODPS、EMR、CDH_HIVE、HOLO引擎中的敏感字段识别结果进行修正。
筛选
在区域②,您可以通过筛选条件过滤需要查询的识别结果。
可以根据项目空间、表名、字段名等条件进行筛选,还支持您单击展开查看更多筛选条件,进一步通过分类、分级、敏感字段类型等条件进行筛选。
-
分类:当前租户默认分类分级模板中的分类信息。详情请参见:配置敏感数据分类分级。
-
分级:当前租户默认分类分级模板中的分级信息。
修正单个数据
在上图的区域③为您展示识别结果列表,您可以单击显示字段设置勾选您需要关注的字段信息,刷新识别结果列表详情。列表默认为您展示项目空间、表名称、字段名称、分类、分级、敏感字段类型、是否手动修正、最新更新时间。
对于敏感字段类型识别结果有误的字段,单击右侧敏感字段类型列的下拉框,列表中为您展示当前租户下默认分类分级模板中已发布的敏感字段类型。您可以查看已有的敏感字段类型是否满足需求:
-
满足需求:则选择其他已有敏感字段类型,并单击右侧的
 图标进入数据识别规则页面修改原敏感字段类型对应的识别规则和修改后的敏感字段类型对应的识别规则,以保证后续识别的准确性。
图标进入数据识别规则页面修改原敏感字段类型对应的识别规则和修改后的敏感字段类型对应的识别规则,以保证后续识别的准确性。 -
不满足需求:您可以单击右侧的
图标进入数据识别规则页面,或滑动至下拉框底部,单击管理敏感字段类型,默认跳转至数据识别规则页面并打开新建敏感字段类型弹窗,新增敏感字段类型,并配置识别规则。详情请参见:配置数据识别规则并执行识别任务。
批量修正数据
选中需要批量修正的字段,单击区域④的批量修正按钮,弹出批量修正识别结果对话框,敏感字段类型下拉框列表中为您展示当前租户下默认分类分级模板中已发布的敏感字段类型,您可以选择正确的敏感字段类型,单击保存,完成批量修正识别结果的操作。
-
导出识别结果
对于系统识别有结果的数据,支持单击导出识别结果,将筛选条件下的识别结果导出至本地。
-
导出识别结果:单击
 ,自动为您导出当前筛选条件下的识别结果。说明
,自动为您导出当前筛选条件下的识别结果。说明最多支持导出10万条数据。