MySQL数据源为您提供读取和写入MySQL的双向通道,本文为您介绍DataWorks的MySQL数据同步的能力支持情况。
支持的MySQL版本
离线读写:
支持MySQL 5.5.x、MySQL 5.6.x、MySQL 5.7.x、MySQL 8.0.x,兼容Amazon RDS for MySQL、Azure MySQL、Amazon Aurora MySQL。
离线同步支持读取视图表。
实时读取:
数据集成实时读取MySQL数据是基于实时订阅MySQL实现的,当前仅支持实时同步MySQL 5.5.x、MySQL 5.6.x、MySQL 5.7.x、MySQL 8.0.x(非8.0新特性,比如functional index,仅兼容原有功能)版本的MySQL数据,兼容Amazon RDS for MySQL、Azure MySQL、Amazon Aurora MySQL。
重要如果需要同步DRDS的MySQL,请不要将DRDS的MySQL配置为MySQL数据源,您可以参考配置DRDS数据源文档直接将其配置为DRDS数据源。
使用限制
实时读
不支持同步MySQL只读库实例的数据。
不支持同步含有Functional index的表。
不支持XA ROLLBACK。
针对已经XA PREPARE的事务数据,实时同步会将其同步到目标端,如果XA ROLLBACK,实时同步不会针对XA PREPARE的数据做回滚写入的操作。若要处理XA ROLLBACK场景,需要手动将XA ROLLBACK的表从实时同步任务中移除,再添加表后重新进行同步。
仅支持同步MySQL服务器Binlog配置格式为ROW。
实时同步不会同步被级联删除的关联表记录。
对于Amazon Aurora MySQL数据库,需要连接到您的主/写数据库,因为AWS不允许在Aurora MySQL的只读副本上激活binlog功能。实时同步任务需要binlog来执行增量更新。
实时同步在线DDL变更仅支持通过数据管理DMS对MySQL表进行加列(Add Column)在线DDL变更。
离线读
MySQL Reader插件在进行分库分表等多表同步时,若要对单表进行切分,则需要满足任务并发数大于表个数这一条件,否则切分的Task数目等于表的个数。
支持的字段类型
各版本MySQL的全量字段类型请参见MySQL官方文档。以下以MySQL 8.0.x为例,为您罗列当前主要字段的支持情况。
字段类型 | 离线读(MySQL Reader) | 离线写(MySQL Writer) | 实时读 | 实时写 |
TINYINT | 支持 | 支持 | 支持 | 支持 |
SMALLINT | 支持 | 支持 | 支持 | 支持 |
INTEGER | 支持 | 支持 | 支持 | 支持 |
BIGINT | 支持 | 支持 | 支持 | 支持 |
FLOAT | 支持 | 支持 | 支持 | 支持 |
DOUBLE | 支持 | 支持 | 支持 | 支持 |
DECIMAL/NUMBERIC | 支持 | 支持 | 支持 | 支持 |
REAL | 不支持 | 不支持 | 不支持 | 不支持 |
VARCHAR | 支持 | 支持 | 支持 | 支持 |
JSON | 支持 | 支持 | 支持 | 支持 |
TEXT | 支持 | 支持 | 支持 | 支持 |
MEDIUMTEXT | 支持 | 支持 | 支持 | 支持 |
LONGTEXT | 支持 | 支持 | 支持 | 支持 |
VARBINARY | 支持 | 支持 | 支持 | 支持 |
BINARY | 支持 | 支持 | 支持 | 支持 |
TINYBLOB | 支持 | 支持 | 支持 | 支持 |
MEDIUMBLOB | 支持 | 支持 | 支持 | 支持 |
LONGBLOB | 支持 | 支持 | 支持 | 支持 |
ENUM | 支持 | 支持 | 支持 | 支持 |
SET | 支持 | 支持 | 支持 | 支持 |
BOOLEAN | 支持 | 支持 | 支持 | 支持 |
BIT | 支持 | 支持 | 支持 | 支持 |
DATE | 支持 | 支持 | 支持 | 支持 |
DATETIME | 支持 | 支持 | 支持 | 支持 |
TIMESTAMP | 支持 | 支持 | 支持 | 支持 |
TIME | 支持 | 支持 | 支持 | 支持 |
YEAR | 支持 | 支持 | 支持 | 支持 |
LINESTRING | 不支持 | 不支持 | 不支持 | 不支持 |
POLYGON | 不支持 | 不支持 | 不支持 | 不支持 |
MULTIPOINT | 不支持 | 不支持 | 不支持 | 不支持 |
MULTILINESTRING | 不支持 | 不支持 | 不支持 | 不支持 |
MULTIPOLYGON | 不支持 | 不支持 | 不支持 | 不支持 |
GEOMETRYCOLLECTION | 不支持 | 不支持 | 不支持 | 不支持 |
数据同步前准备:MySQL环境准备
在DataWorks上进行数据同步前,您需要参考本文提前在MySQL侧进行数据同步环境准备,以便在DataWorks上进行MySQL数据同步任务配置与执行时服务正常。以下为您介绍MySQL同步前的相关环境准备。
准备工作1:确认MySQL版本
数据集成对MySQL版本有要求,您可参考上文支持的MySQL版本章节,查看当前待同步的MySQL是否符合版本要求。您可以在MySQL数据库通过如下语句查看当前MySQL数据库版本。
SELECT version();准备工作2:配置账号权限
建议您提前规划并创建一个专用于DataWorks访问数据源的MySQL账号,操作如下。
可选:创建账号。
操作详情请参见创建MySQL账号。
配置权限。
离线
在离线同步场景下:
在离线读MySQL数据时,此账号需拥有同步表的读(
SELECT)权限。在离线写MySQL数据时,此账号需拥有同步表的写(
INSERT、DELETE、UPDATE)权限。
实时
在实时同步场景下,此账号需要拥有数据库的
SELECT、REPLICATION SLAVE、REPLICATION CLIENT权限。
您可以参考以下命令为账号添加权限,或直接给账号赋予
SUPER权限。如下执行语句在实际使用时,请替换'同步账号'为上述创建的账号。-- CREATE USER '同步账号'@'%' IDENTIFIED BY '密码'; //创建同步账号并设置密码,使其可以通过任意主机登录数据库。%表示任意主机。 GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '同步账号'@'%'; //授权同步账号数据库的 SELECT, REPLICATION SLAVE, REPLICATION CLIENT权限。*.*表示授权同步账号对所有数据库的所有表拥有上述权限。您也可以指定授权同步账号对目标数据库的指定表拥有上述权限。例如,授权同步账号对test数据库的user表拥有上述权限,则可以使用GRANT SELECT, REPLICATION CLIENT ON test.user TO '同步账号'@'%';语句。说明REPLICATION SLAVE语句为全局权限,不能指定授权同步账号对目标数据库的指定表拥有相关权限。
准备工作3:(仅实时同步需要)开启MySQL Binlog
数据集成通过实时订阅MySQL Binlog实现增量数据实时同步,您需要在DataWorks配置同步前,先开启MySQL Binlog服务。操作如下:
如果Binlog在消费中,则无法被数据库删除。如果实时同步任务运行延迟将可能导致源端Binlog长时间被消费,请合理配置任务的延迟告警,并及时关注数据库的磁盘空间。
Binlog至少保留72小时以上,避免任务失败后因Binlog已经消失,再启动无法重置位点到故障发生前而导致的数据丢失(此时只能使用全量离线同步来补齐数据)。
检查Binlog是否开启。
使用如下语句检查Binlog是否开启。
SHOW variables like "log_bin";返回结果为ON时,表明已开启Binlog。
如果您使用备用库同步数据,则还可以通过如下语句检查Binlog是否开启。
SHOW variables LIKE "log_slave_updates";返回结果为ON时,表明备用库已开启Binlog。
如果返回的结果与上述结果不符:
开源MySQL请参考MySQL官方文档开启Binlog。
阿里云RDS MySQL请参考RDS MySQL日志备份开启Binlog。
阿里云PolarDB MySQL请参考开启Binlog开启Binlog。
查询Binlog的使用格式。
使用如下语句查询Binlog的使用格式。
SHOW variables LIKE "binlog_format";返回结果说明:
返回ROW,表示开启的Binlog格式为ROW。
返回STATEMENT,表示开启的Binlog格式为STATEMENT。
返回MIXED,表示开启的Binlog格式为MIXED。
重要DataWorks实时同步仅支持同步MySQL服务器Binlog配置格式为ROW。如果返回非ROW请修改Binlog Format。
查询Binlog完整日志是否开启。
使用如下语句查询Binlog完整日志是否开启。
show variables like "binlog_row_image";返回结果说明:
返回FULL,表示Binlog开启了完整日志。
返回MINIMAL,表示Binlog开启了最小日志,未开启完整日志。
重要DataWorks实时同步,仅支持同步开启了Binlog完整日志的MySQL服务器数据。若查询结果返回非FULL,请修改binlog_row_image的配置。
OSS binlog读取授权配置
在添加MySQL数据源时,如果配置模式为阿里云实例模式,且RDS MySQL实例地域与DataWorks项目空间在同一地域,您可以开启支持OSS binlog读取,开启后,在无法访问RDS binlog时,将会尝试从OSS获取binlog,以避免实时同步任务中断。
如果选择的OSS binlog访问身份为阿里云RAM子账号或阿里云RAM角色,您还需参考如下方式配置账号授权。
阿里云RAM子账号
登录RAM 访问控制-用户控制台,找到需要授权的子账号。具体操作:
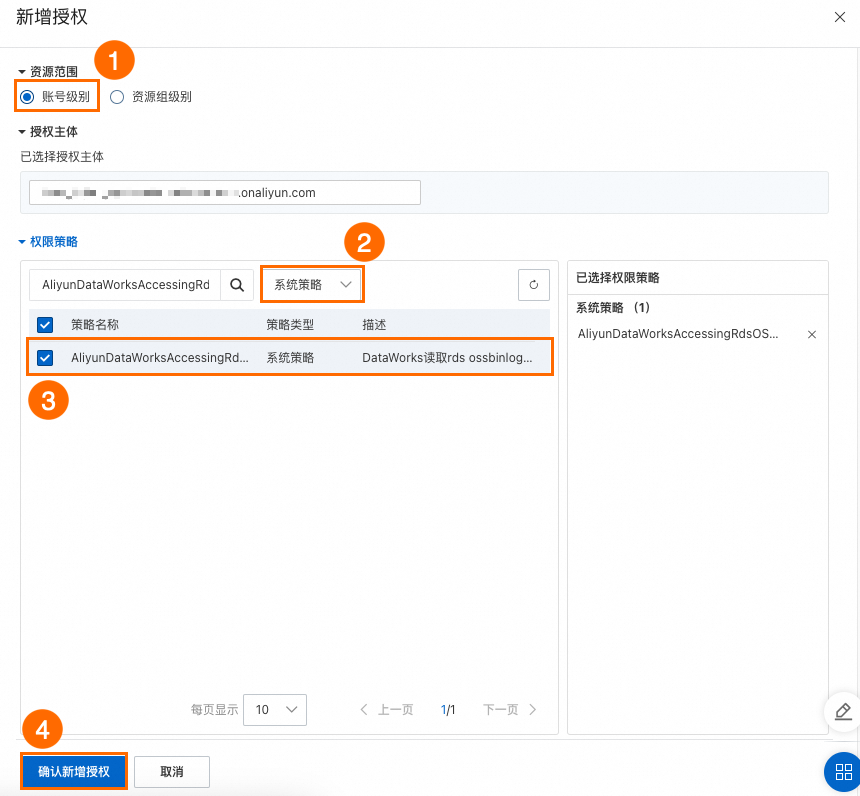
单击操作列的添加权限。
配置如下关键参数后,单击确认新增授权。
资源范围:账号级别。
权限策略:系统策略。
策略名称:
AliyunDataWorksAccessingRdsOSSBinlogPolicy。
阿里云RAM角色
登录RAM 访问控制-角色控制台,创建一个RAM角色。具体操作,请参见创建可信实体为阿里云账号的RAM角色。
关键参数:
选择可信实体类型:阿里云账号。
角色名称:自定义。
选择信任的云账号:其他账号,填写DataWorks工作空间所属的云账号。
为创建好的RAM角色精确授权。具体操作,请参见为RAM角色授权。
关键参数:
权限策略:系统策略。
策略名称:
AliyunDataWorksAccessingRdsOSSBinlogPolicy。
为创建好的RAM角色修改信任策略。具体操作,请参见修改RAM角色的信任策略。
{ "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "<DataWorks使用者主账号的云账号ID>@cdp.aliyuncs.com" ] } } ], "Version": "1" }
创建数据源
在进行数据同步任务开发时,您需要在DataWorks上创建一个对应的数据源,操作流程请参见创建并管理数据源,详细的配置参数解释可在配置界面查看对应参数的文案提示。
数据同步任务开发:MySQL同步流程引导
数据同步任务的配置入口和通用配置流程可参见下文的配置指导。
单表离线同步任务配置指导
操作流程请参见通过向导模式配置离线同步任务、通过脚本模式配置离线同步任务。
脚本模式配置的全量参数和脚本Demo请参见下文的附录:MySQL脚本Demo与参数说明。
单表实时同步任务配置指导
操作流程请参见DataStudio侧实时同步任务配置。
整库离线、整库(实时)全增量、整库(实时)分库分表等整库级别同步配置指导
操作流程请参见数据集成侧同步任务配置。
常见问题
更多其他数据集成常见问题请参见数据集成常见问题。
附录:MySQL脚本Demo与参数说明
离线任务脚本配置方式
如果您配置离线任务时使用脚本模式的方式进行配置,您需要按照统一的脚本格式要求,在任务脚本中编写相应的参数,详情请参见通过脚本模式配置离线同步任务,以下为您介绍脚本模式下数据源的参数配置详情。