
数据集成目前支持将ApsaraDB for OceanBase、MySQL、Oracle、PolarDB等源头的数据整库实时同步至Hologres。本文以MySQL为源端、Hologres为目标端场景为例,为您介绍如何将MySQL整个数据库的数据全量+增量同步至Hologres。
前提条件
注意事项
MySQL同步数据至Hologres时,目前仅支持将数据写入分区表子表,暂不支持写入数据至分区表父表。
操作步骤
一、选择同步任务类型
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏单击同步任务,然后在页面顶部单击新建同步任务,进入同步任务的创建页面,配置如下基本信息。
数据来源和去向:
MySQL→Hologres新任务名称:自定义同步任务名称。
同步类型:
整库实时。同步步骤:选中全量同步和增量同步。
二、网络与资源配置
在网络与资源配置区域,选择同步任务所使用的资源组。您可以为该任务分配任务资源占用CU数。
来源数据源选择已添加的
MySQL数据源,去向数据源选择已添加的Hologres数据源后,单击测试连通性。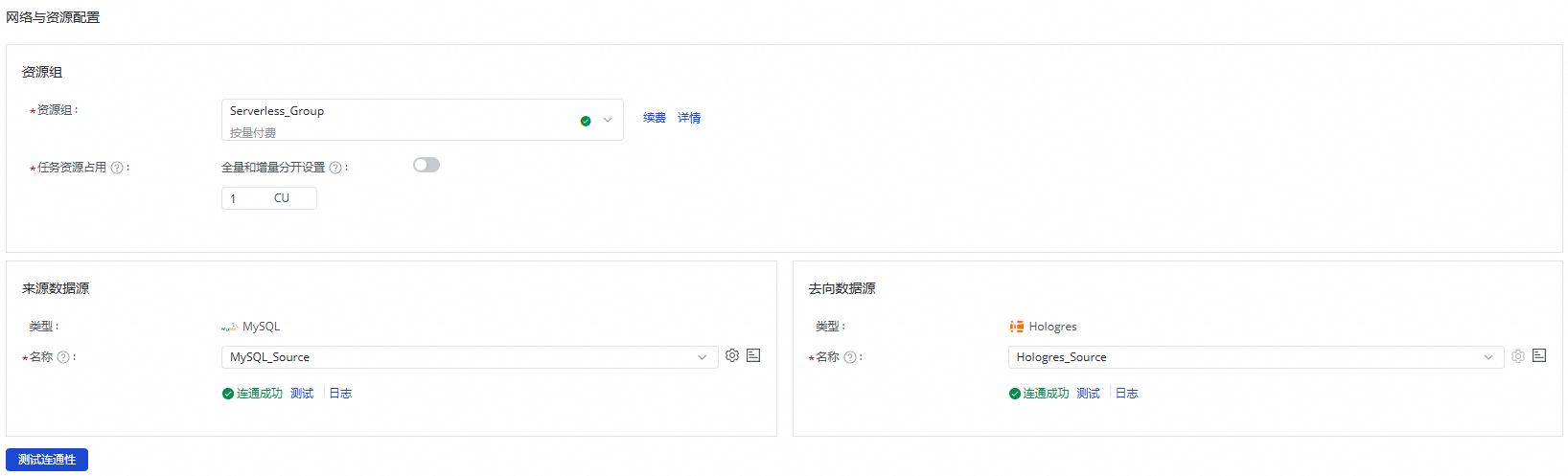
确保来源数据源与去向数据源均连通成功后,单击下一步。
三、选择要同步的库表
此步骤中,您可以在源端库表区域选择源端数据源下需要同步的表,并单击![]() 图标,将其移动至右侧已选库表。
图标,将其移动至右侧已选库表。
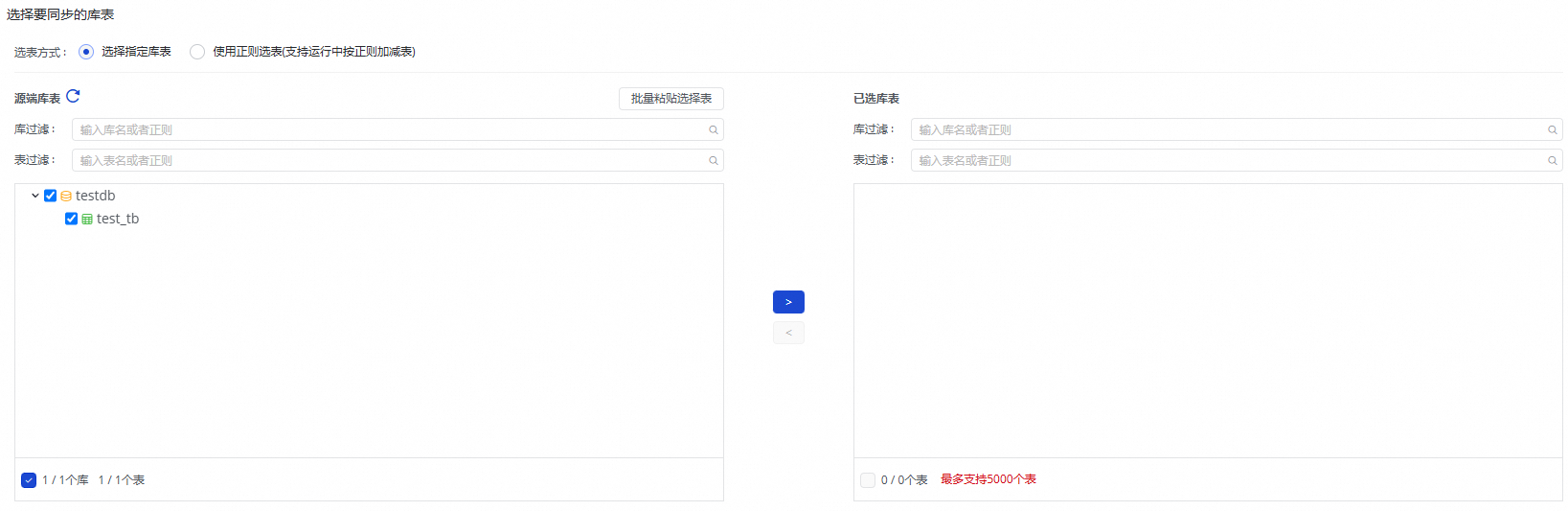
选择指定库表:
在源端库表的库过滤和表过滤中,可通过输入库名或表名的特征信息筛选需要同步的库表。勾选所有需要同步的库表数据,单击
 图标,将其移动至已选库表区域。
图标,将其移动至已选库表区域。在已选库表的库过滤和表过滤中,可通过输入库名或表名的特征信息筛选无需同步的库表。勾选所有无需同步的库表数据,单击
 图标,将其移动至源端库表区域。
图标,将其移动至源端库表区域。
使用正则选表(支持运行中按正则加减表):
通过库过滤和表过滤里面配置的正则表达式筛选表信息。单击确认选择您所需同步的库表数据。
说明例如,若需筛选同步库名前缀为
a且表名前缀为order的库表信息,可在库过滤框中输入a.*,在表过滤框中输入order.*。
四、目标表映射
在上一步骤选择完需要同步的表后,将自动在此界面展示当前待同步的表,但目标表的相关属性默认为待刷新映射状态,需要您定义并确认源表与目标表映射关系,即数据的读取与写入关系,然后单击刷新映射后才可进入下一步操作。您可以直接刷新映射,或自定义目标表规则后,再刷新映射。
您可以选中待同步表后,单击批量刷新映射,未配置映射规则时,默认表名规则为
${表名},若目标端不存在同名表时,将自动新建。您可以在目标Schema名映射自定义列,单击配置按钮可以自定义目标Schema名规则。
可以使用内置变量和手动输入的字符串拼接成为最终目标Schema名。其中,支持您编辑内置变量,例如,新建一个Schema名规则,将源库名增加后缀作为目标Schema名。
您可以在目标表名映射自定义列,单击编辑按钮可以自定义目标表名规则。
可以使用内置变量和手动输入的字符串拼接成为最终目标表名。其中,支持您编辑内置变量,例如,新建一个表名规则,将源表名增加后缀作为目标表名。
1. 编辑字段类型映射
同步任务存在默认的源端字段类型与目标端字段类型映射,您可以单击表格右上角的编辑字段类型映射,自定义源端表与目标端表字段类型映射关系,配置完后单击应用并刷新映射。
2. 编辑目标表结构并添加字段赋值
当目标表为待建立状态时,您可以为目标表在原有表结构基础上新增字段。操作如下:
为目标表添加字段
单表新增字段:单击目标表名列的
 按钮添加字段。
按钮添加字段。批量新增字段:选中待同步的所有表,在表格底部选择。
为字段赋值。您可以通过以下操作为上述步骤中新增的字段赋值。
单表赋值:单击目标表字段赋值列的配置按钮,为目标表字段赋值。
批量赋值:在列表底部选择为目标表中相同的字段批量赋值。
说明在赋值时支持赋值常量与变量,您可通过
 图标切换赋值模式。
图标切换赋值模式。
3. 配置DML规则
数据集成提供默认DML处理规则,同时,您可以根据业务需要在此界面对写入目标表的DML命令定义处理规则。
单表定义规则:单击表格DML规则配置列的配置,对目标表单独定义DML规则。
批量定义规则:选中待同步的所有表,在列表底部选择。
4. 自定义高级参数
如果需要对任务做精细化配置,达到自定义同步需求,可以单击自定义高级参数列的配置,修改高级参数。
请在完全明白对应参数的含义情况下再进行修改,以免产生不可预料的错误或者数据质量问题。
5. 设置源端切分列
您可以在源端切分列中下拉选择源端表中的字段或选择不切分。
6. 是否执行全量同步
如果在选择同步任务类型时,同步步骤勾选了全量同步,您还可以在此处对指定表关闭全量同步。
五、报警配置
为避免任务出错导致业务数据同步延迟,您可以对同步任务设置报警策略。
单击页面右上方的报警配置,进入实时子任务报警设置页面。
单击新增报警,配置报警规则。
说明此处定义的报警规则,将对该任务产生的实时同步子任务生效,您可在任务配置完成后,进入实时同步任务运行与管理界面查看并修改该实时同步子任务的监控报警规则。
管理报警规则。
对于已创建的报警规则,您可以通过报警开关控制报警规则是否开启,同时,您可以根据报警级别将报警发送给不同的人员。
六、高级参数配置
同步任务提供部分参数可供修改,您可以按需对该参数值进行修改,例如通过最大连接数上限限制,避免当前同步方案对数据库造成过大的压力从而影响生产。
请在完全了解对应参数含义的情况下再进行修改,以免产生不可预料的错误或者数据质量问题。
单击界面右上方的高级参数配置,进入高级参数配置页面。
在高级参数配置页面修改相关参数值。
七、DDL能力配置
来源数据源会包含许多DDL操作,您可以根据业务需求,在界面右上方单击DDL能力配置,进入DDL能力配置页面,对不同的DDL消息设置同步至目标端的处理策略。
不同DDL消息处理策略请参见:DDL消息处理规则。
八、资源组配置
您可以单击界面右上方的资源组配置,查看并切换当前的任务所使用的资源组。
九、执行同步任务
完成所有配置后,单击页面底部的完成配置。
在界面,找到已创建的同步任务,单击操作列的启动。
单击任务列表中对应任务的名称/ID,查看任务的详细执行过程。
同步任务运维
查看任务运行状态
创建完成同步任务后,您可以在同步任务页面查看当前已创建的同步任务列表及各个同步任务的基本信息。
您可以在操作列启动或停止同步任务,在更多中可以对同步任务进行编辑、查看等操作。
已启动的任务您可以在执行概况中看到任务运行的基本情况,也可以单击对应的概况区域查看执行详情。
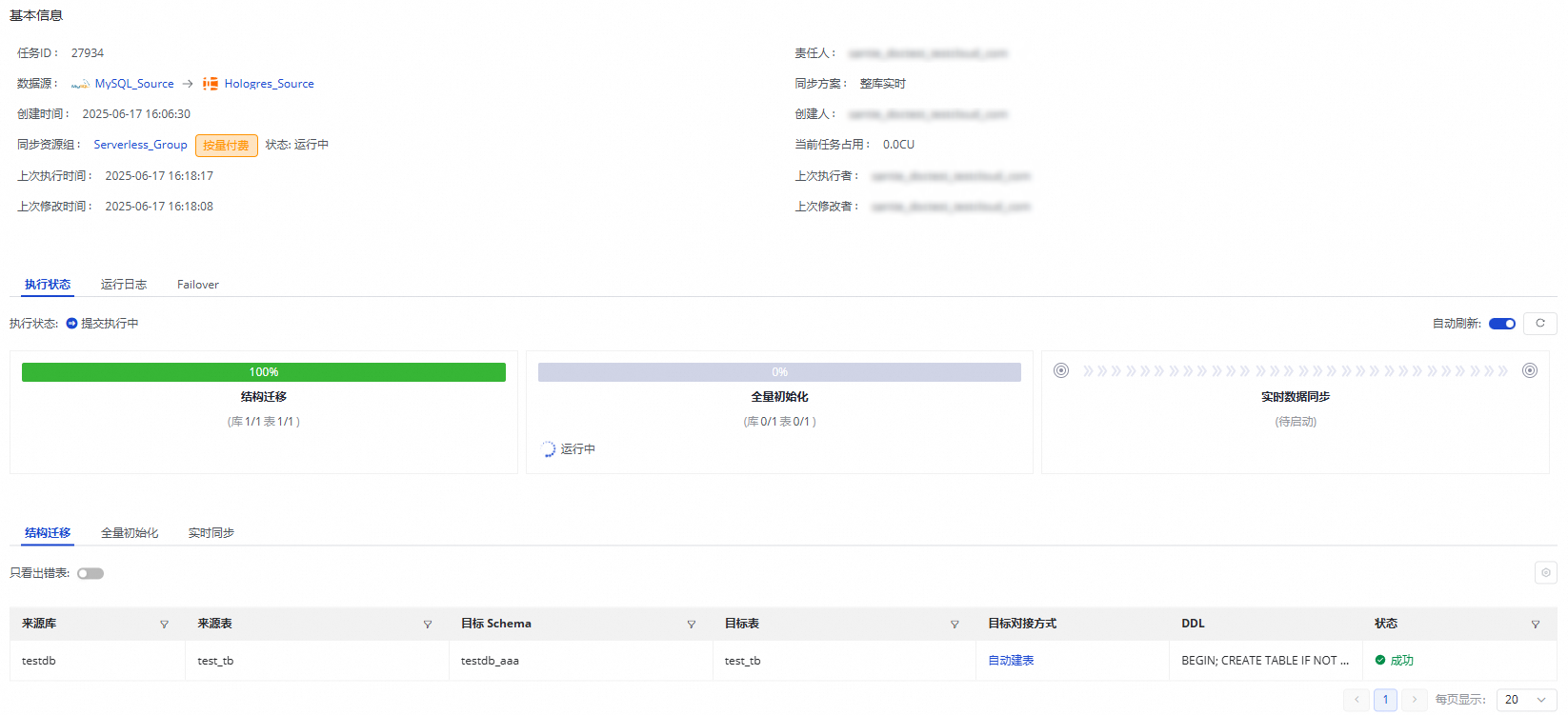
MySQL到Hologres的整库实时同步任务分为三个步骤:
结构迁移:包含目标表的创建方式(已有表/自动建表),如果是自动建表,会展示DDL语句。
全量初始化:包含离线同步的表信息、同步的进度、以及写入的条数。
实时数据同步:包含实时同步的统计信息(实时的进度、DDL记录、DML记录和报警信息)。
任务重跑
在某些特殊情况下,如果您需要增减表、修改目标表Schema信息或者表名信息时,您还可以单击同步任务操作列的重跑,系统会将新增的表或有变更的表进行同步,之前同步过的表或者未修改的表将不会再进行同步。
不修改任务配置,直接单击重跑操作,重新运行全量初始化+实时同步。
编辑任务,进行增减表操作,单击完成配置。这个时候任务的操作列会显示应用更新,单击应用更新会直接触发修改后的任务重跑。新增的表才会进行同步,之前同步过的表不会再同步。