本文主要介绍了在EMR Serverless Spark环境下有效集成与利用DLF 2.0 Catalog的步骤,帮助您实现高效的元数据管理及数据读写操作。
前提条件
已创建DLF 2.0数据目录。如未创建,详情请参见创建数据目录。
步骤一:绑定DLF 2.0 Catalog
单击创建工作空间,填写配置信息。详情请参见创建工作空间。
DLF作为元数据服务默认开启,在下拉列表中选择DLF 2.0的Catalog。
勾选服务协议,单击创建工作空间,完成工作空间创建和Catalog绑定。
步骤二:Catalog授权
登录数据湖构建控制台。
在Catalog列表页面,单击Catalog名称。
单击权限页签,单击授权。
选择对用户授权,在授权用户下拉列表中选择AliyunEMRSparkJobRunDefaultRole。
预置权限类型选择Data Editor,单击确定。
步骤三:读写数据
创建数据库
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的数据开发,进入开发目录。
在开发目录页签下,单击新建。
在弹出的对话框中,输入名称,类型选择SQL > SparkSQL,然后单击确定。
创建开发任务详情,请参见SQL开发快速入门。
运行以下SQL,创建数据库。
说明SQL会话的引擎版本需为esr-2.3 (Spark 3.4.2, Scala 2.12)及以上。
CREATE DATABASE IF NOT EXISTS spark_demo;
创建数据表
运行以下SQL,创建数据表。
USE spark_demo;
CREATE TABLE IF NOT EXISTS average_clicks_by_consumption (
pvalue_level INT,
average_clicks FLOAT
)
USING paimon TBLPROPERTIES (
'format' = 'parquet',
'metastore.partitioned-table' = 'true',
'primary-key' = 'date,pvalue_level'
)
PARTITIONED BY (date STRING);插入数据
运行以下SQL,插入数据。
INSERT INTO average_clicks_by_consumption (date, pvalue_level, average_clicks)
VALUES
('2023-04-01', 1, 100.5),
('2023-05-01', 2, 150.2),
('2023-06-01', 3, 200.1);查询数据
运行以下SQL,查询数据。
SELECT * FROM average_clicks_by_consumption;步骤四:在DLF中查看元数据
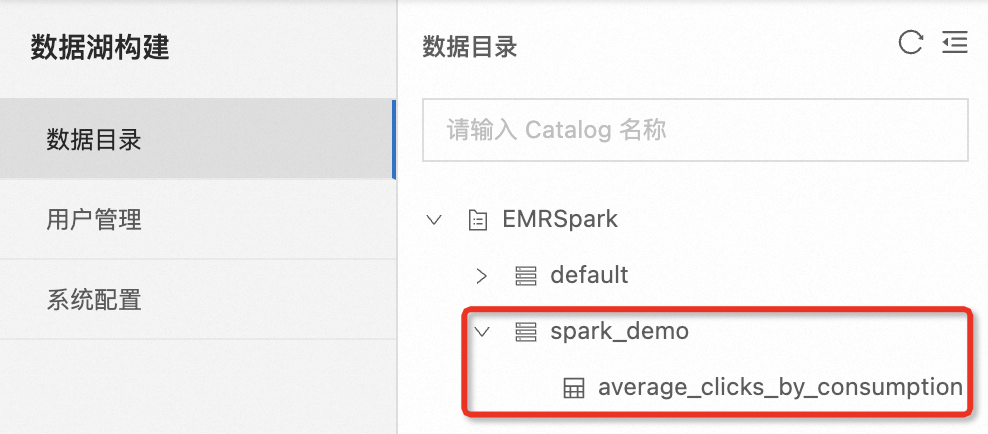
当您运行成功之后,您可在数据湖构建控制台看到新增的库、表元数据信息。其中EMRSpark是本例中的示例Catalog名称。
该文章对您有帮助吗?