
Asight Compute GUI工具
通过acu 命令行工具在Target端生成.acurep报告文件之后,可以拷贝到Host端,通过Asight Compute GUI工具打开。
UI 功能亮点
通过配置各种metric性能指标,进行多样化的展示(表格、图表等)。
支持详细的Memory Workload结构层次图和表格的展示。
通过Baselines功能,在不同的kernel与报告之间,可以直接比较性能结果来定位差异。
Raw Page提供pdf/png/csv格式文件的导出,可通过export csv导出相关格式的原始报告数据,进行后处理分析。
利用Project explorer可方便管理报告,支持批量打开和删除选定的报告。
支持Dock Widget,可以将报告拖出主窗口,方便在不同的窗口和屏幕查看报告,如下图所示。
可以通过拖拽tab的方式实现dock:
还可以通过右键菜单中的Detach/Attach选项:
1. Details Page
Details Page是kernel启动期间采集的所有metrics数据的主页面。它被分成单独的section进行展示。每个section都有一个header table来展示该section主题包含的主要metrics。section通常还有至少一个可展开/折叠的section body,body中以表格或图表的形式展示了更详细的metrics。如下图所示:
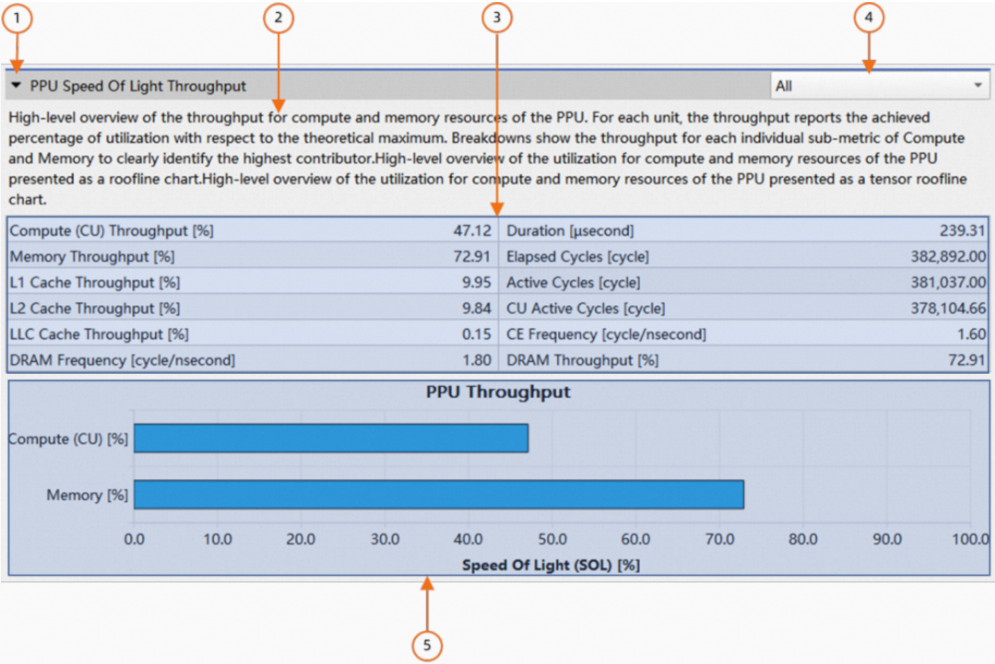
展开/折叠section body
section描述
header table
切换section body
section body
将鼠标悬停在表格或图表上会详细显示该metrics的具体数值和详细信息,以及相关的名词解释,如下图所示:

Details Page提供了多种主题的section,涵盖计算负载,缓存命中,以及Warp调度等多个维度,通过分析这些metrics,可以全方位地查探kernel的运行情况,找出瓶颈和优化点。
以下分别介绍每个section。
1.1 Speed Of Light Throughput Section
该section提供了kernel运行过程中PPU的计算资源和内存资源利用率的概览,分别从计算和访存的角度展示了该kernel吞吐量相对于理论值的百分比。对kernel的分析工作通常从该section开始,来确定该kernel的性能受限于计算还是访存。
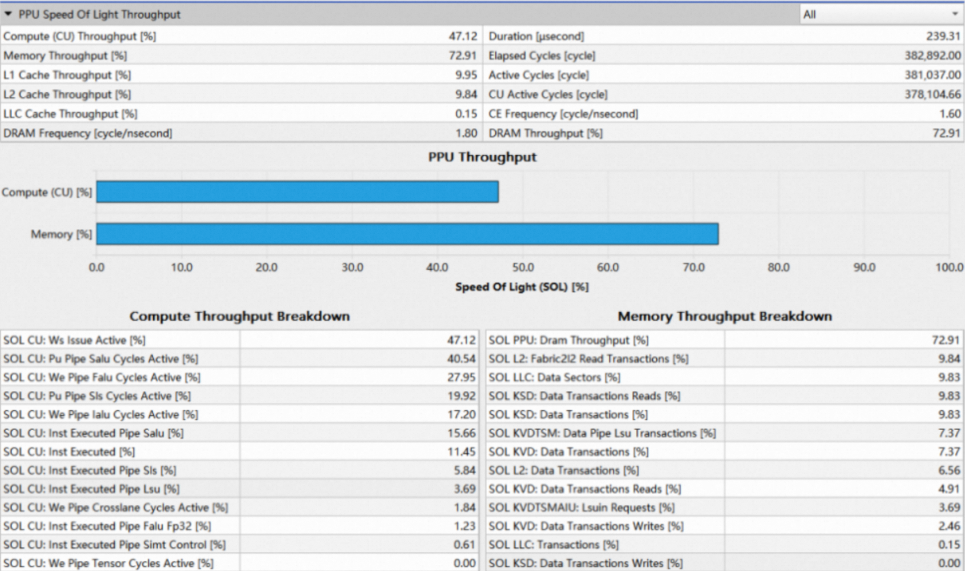
1.1.1 Header Table

Header table展示了PPU各单元吞吐的利用率以及kernel执行的周期数等总览信息,具体含义如下:
项目 | 详细信息 |
Compute (CU) Throughput | 计算单元的整体吞吐利用率 |
Memory Throughput | 内存单元的整体吞吐利用率 |
L1 Cache Throughput | L1缓存的吞吐利用率 |
L2 Cache Throughput | L2缓存的吞吐利用率 |
LLC Cache Throughput | LLC缓存的吞吐利用率 |
DRAM Throughput | DRAM的吞吐利用率 |
Duration | kernel执行的耗时 |
Elapsed Cycles | kernel执行过程中PPU经历的周期数 |
Active Cycles | kernel执行过程中PPU活动的周期数 |
CU Active Cycles | kernel执行过程中CU活动的周期数 |
CE Frequency | CE的运行频率 |
DRAM Frequency | DRAM的运行频率 |
1.1.2 PPU Throughput Bar Chart

Bar Chart中分别显示了计算和内存单元的吞吐百分比,两个category分别对应header table中的Compute (CU) Throughput和Memory Throughput。
通过图表可以容易看出kernel的性能是受限于计算还是访存,并采取不同的优化策略。通常根据性能瓶颈,kernel可以分为以下三种类型:
计算受限型kernel
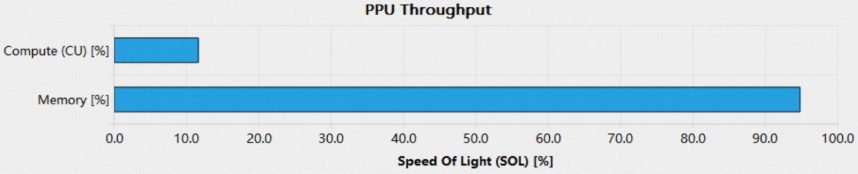
当一个kernel使得PPU的某个计算单元吞吐接近理论最大值时(通常大于80%),kernel的性能受限于该类型的计算单元,称其为计算受限型kernel,如下图所示:

计算受限型kernel的计算指令远多于访存,要进一步提升性能,可以查看Compute Workload Analysis section,找出利用率最高的计算单元pipeline:
考虑将该种类型的计算转换为其他类型
检查是否有多余计算,减少计算量
利用查找表代替计算
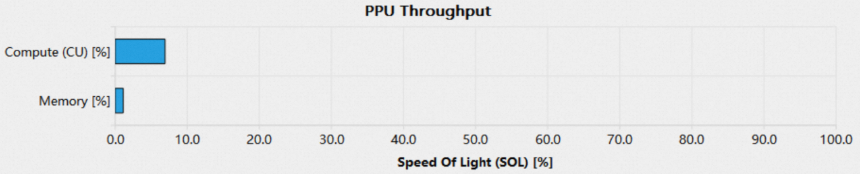
访存受限型kernel
当一个kernel使得PPU的某个内存单元吞吐接近理论最大值时(通常大于80%),kernel的性能受限于访存,称其为访存受限型kernel,如下图所示:
访存受限型kernel运行时多数时间都在等待数据,要进一步提升性能,可以查看Memory Workload Analysis section,优化各种内存子系统的使用:
确保合并访问global memory
充分利用各层次内存,如共享内存,各层次cache
充分复用数据,减少访存指令
利用实时计算代替查找表
延迟受限型kernel
当一个kernel在计算和访存都无法接近理论峰值时,称该kernel为延迟受限型,如下图所示:
对于延迟受限型kernel,首先应该通过Launch Statistics section查看kernel的启动配置,确保grid足够大;另一方面查看Scheduler Statistics section和Warp State Statistics section,检查是否有其他潜在原因导致每个线程大多数时间都在等待而不是执行。
要提升延迟受限型kernel的性能:
确保有足够多的block填满PPU,争取实现最大的占有率。
增加每个线程的工作量,例如每个线程处理多个输入元素。
1.1.3 Breakdown Tables
Breakdown Tables分为两种,分别展示了PPU计算和内存各个单元的吞吐百分比,如下图所示:
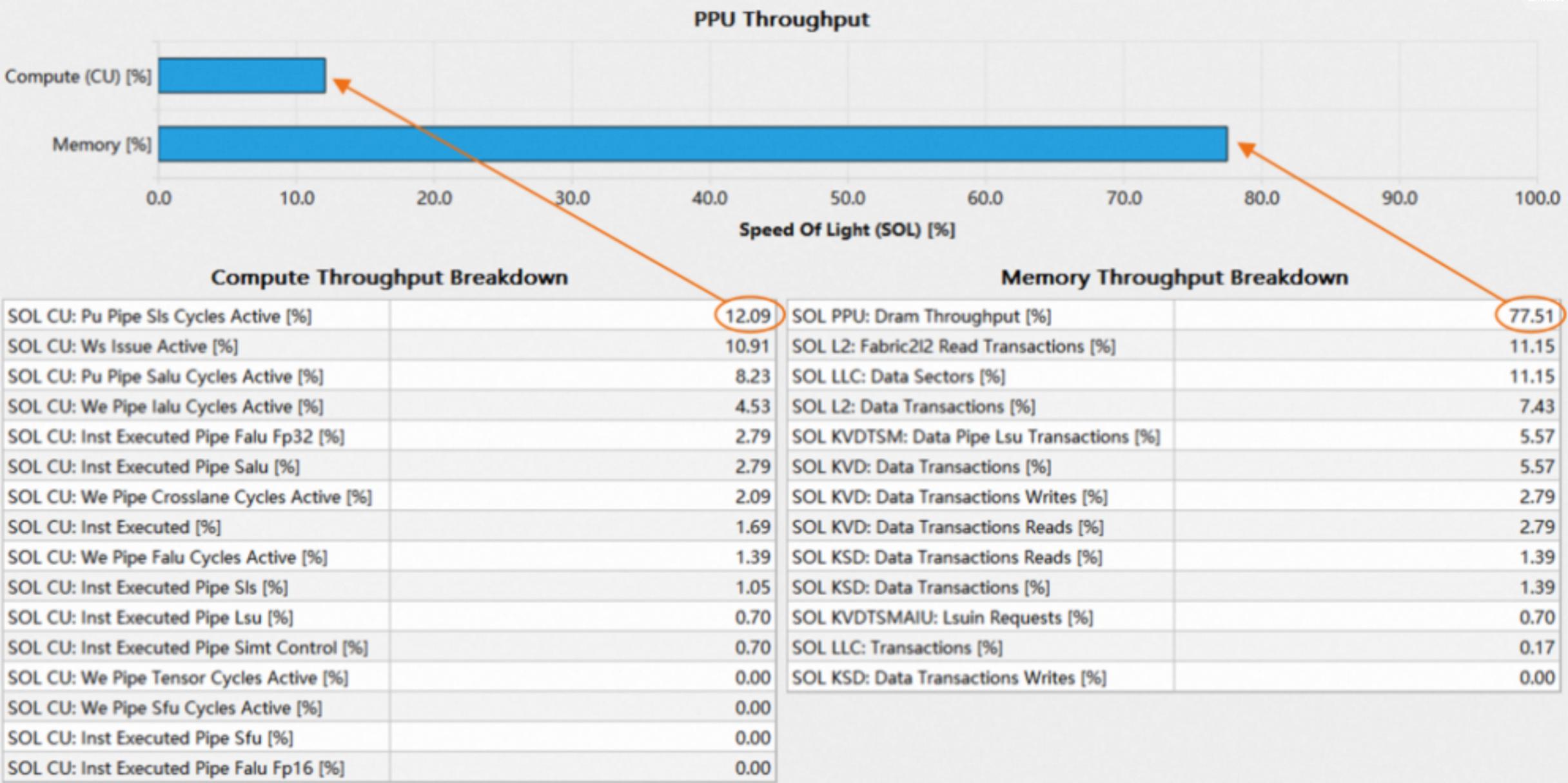
在breakdown table中,展示了当前子系统所有单元的吞吐百分比,并按照降序排列,可以方便地查看当前kernel具体受限于哪个单元。将最繁忙单元的吞吐率视为当前子系统的吞吐率,并在bar chart中展示。
1.1.4 Roofline Chart
Kernel需要数据来进行计算,因此其性能不仅取决于PPU的计算速度,还取决于PPU向kernel提供数据的速度。为了更直观地表示kernel所达到的性能,Asight Compute提供了roofline chart,将PPU的峰值计算性能和内存带宽与一个叫做 "算术强度 "的指标(工作和内存流量之间的比值)结合到一个图表中,一个典型的roofline chart如下图所示:
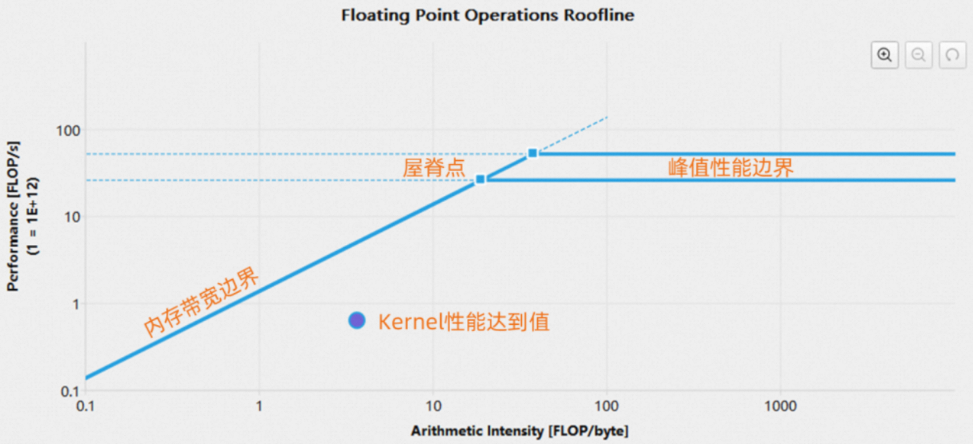
纵坐标轴:纵坐标轴代表每秒浮点运算数(FLOPS),对于PPU而言这个数值会非常大,为了方便展示,坐标轴刻度以对数的方式呈现。
横坐标轴:横坐标轴代表“算术强度”,是工作(FLOP/s)和内存流量(byte/s)之间的比值,其单位是FLOP/byte。坐标轴刻度也以对数的方式呈现。
内存带宽边界:是roofline的斜线部分,这个值由PPU的内存带宽决定。
峰值性能边界:是roofline的水平部分,这个值由PPU的峰值计算性能决定。
屋脊点:屋脊点是内存带宽边界与峰值性能边界的结合点。可参考该点分析kernel性能。
性能达到值:代表了kernel在当前算术强度下达到的性能。进行baseline比对时,也会显示baseline的性能值,该点的轮廓颜色代表了它是来自哪条baseline。
利用roofline chart可以直观地判断一个kernel是计算受限型还是访存受限型,如下图所示:
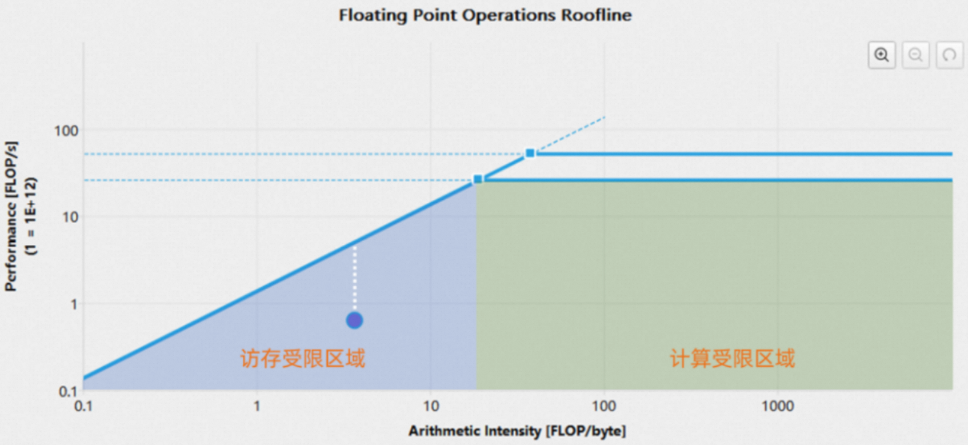
在上图中,屋脊点将roofline分为了两个区域:内存带宽边界下的蓝色阴影区域是访存受限区域;峰值性能边界下的绿色阴影区域时计算受限区域。根据kernel性能实现值所处的位置,可以判断kernel的性能限制因素。性能实现值到上方边界的距离(上图中为白色虚线),代表了性能优化的空间。实现值越接近上方边界,kernel性能越好。当一个kernel的实现值位于内存带宽边界时,只有增加算术强度才能进一步提高性能。为方便查看,roofline chart支持缩放平移操作:
放大:
Ctrl + 鼠标滚轮
鼠标左键框选放大
点击右上角的放大按钮
键盘“+”
缩小:
Ctrl + 鼠标滚轮
鼠标右键单击
点击右上角的缩小按钮
键盘“-”
复位:
点击右上角的复位按钮
键盘“Esc”
平移
Ctrl + 鼠标左键拖拽
1.2 Compute Workload Analysis Section
Compute Workload Analysis Section详细展示PPU计算单元的各种计算资源的性能数据,包含两类信息:
Instructions Per Clock(IPC):统计CU每一个周期的指令发出情况。
Pipe Utilization:CU各类pipeline的利用率。
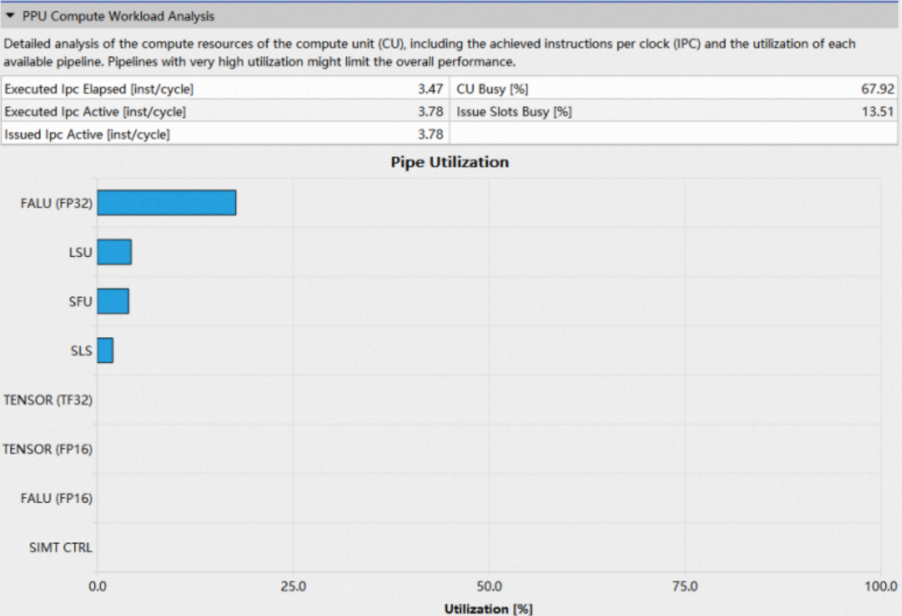
1.2.1 Header Table

Header table展示了CU利用率以及kernel执行过程中每活动周期执行的指令数等关键信息,具体含义如下:
项目 | 详细信息 |
Executed Ipc Elapsed | CU经过的周期内,每周期执行的指令数 |
Executed Ipc Active | CU活动的周期内,每周期执行的指令数 |
Issued Ipc Active | CU活动的周期内,每周期发出的指令数 |
CU Busy | CU的利用率 |
Issue Slots Busy | 指令发射槽的利用率 |
1.2.2 Pipe Utilization Bar Chart
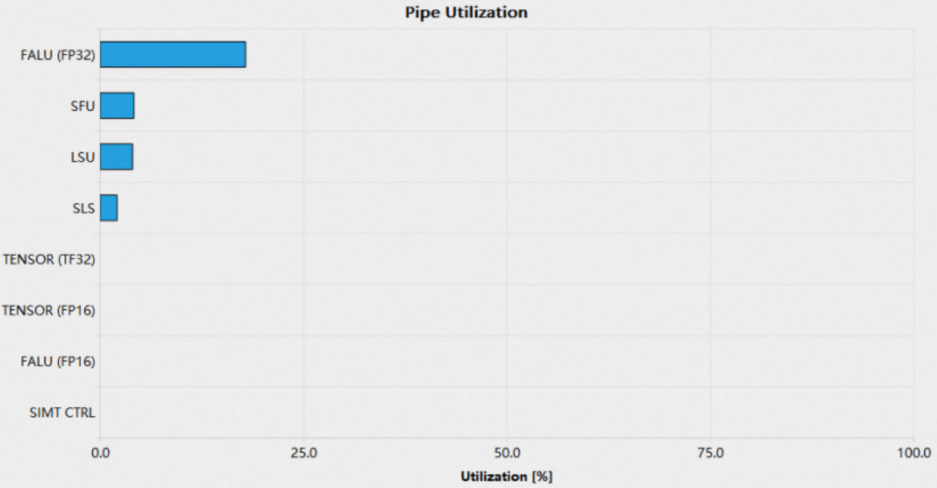
Pipe Utilization Bar Chart展示了kernel执行过程中PPU各计算pipe的利用率,常用的Pipeline信息如下:
pipe名称 | 描述 |
salu | 标量算术逻辑单元 |
valu | 矢量算术逻辑单元,包括ialu和falu两种 |
ialu | 整型算术逻辑单元 |
falu | 浮点型算术逻辑单元 |
sls | 标量加载/存储单元 |
sfu | 特殊函数单元 |
tensor | 张量计算单元 |
lsu | 矢量加载/存储单元 |
ffma | FP32 积和熔加运算 |
fadd | FP32 加法运算 |
fmul | FP32 乘法运算 |
hfma | FP16 积和熔加运算 |
hadd | FP16 加法运算 |
hmul | FP16 乘法运算 |
当所有的计算pipe的利用率都较低时(通常小于60%),可能当前kernel的启动配置过小,或者warp scheduler上没有足够的warp可供调度,可以查看Launch Statistics section和Scheduler Statistics section获取详细信息。当某一个计算单元的pipe利用率过高时(通常大于80%),该pipe可能是性能瓶颈,可以考虑平衡各pipe的利用率以提升性能。
1.3 Memory Workload Analysis Section
Memory Workload Analysis section详细展示了PPU各内存单元的性能数据。当PPU各内存单元被充分利用时,访存可能成为kernel的性能瓶颈,这可能是由于内存单元的利用率过高,内存带宽被耗尽,或者发出访存指令的吞吐量达到最大等。该section有两个section body:
Memory Chart
Memory Table
1.3.1 Header Table

Header table展示了PPU各内存单元的利用信息,如cache命中率,达到的带宽,访存pipe利用率等信息出,具体含义如下:
项目 | 详细信息 |
Memory Throughput | DRAM吞吐量,单位为byte/second |
Mem Busy | 访存吞吐利用率 |
KVD Hit Rate | Vector Data Cache命中率 |
KSD Hit Rate | Scalar Data Cache命中率 |
Max Bandwidth | 最大访存带宽利用率 |
L2 Hit Rate | L2 Cache命中率 |
LLC Hit Rate | Last Level Cache命中率 |
Mem Pipes Busy | 访存pipe利用率 |
LLC Compression Success Rate | Last Level Cache压缩成功率 |
LLC Compression Ratio | Last Level Cache数据压缩率 |
1.3.2 Memory Chart
1.3.2 Memory Chart
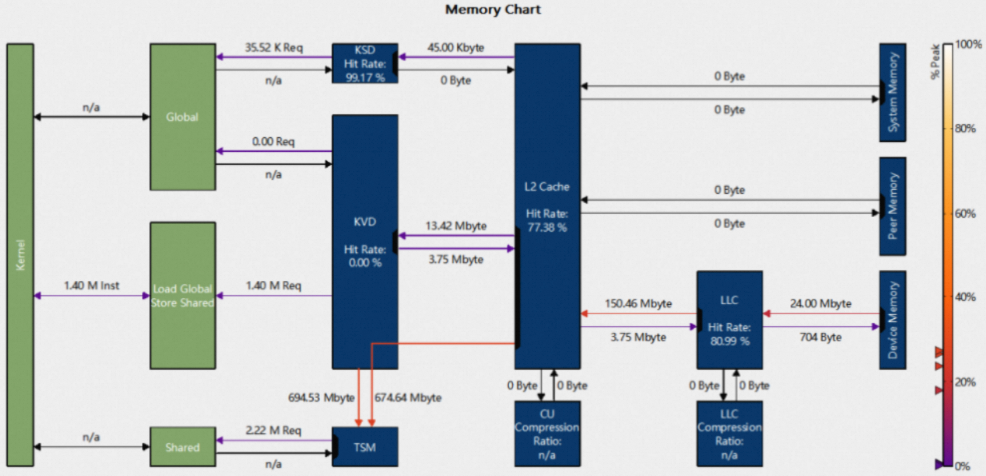
Memory Chart可视化展示各内存单元间的数据传输情况,包括cache命中率,instruction数,以及memory request数等:
逻辑单元(绿色部分),包括
Kernel:PPU上执行的kernel
Global:HGGC global memory
Local:HGGC local memory
Shared:HGGC shared memory
Load Global Store Shared:指令直接从global memory load到shared memory
物理单元(蓝色部分),包括:
L1 cache:包括KSD,KVD,TSM等单元
L2 cache和L2 Compression
LLC cache和 LLC Compression
System Memory:system(CPU)memory
Device Memory:device (PPU) memory
Peer Memory:其他PPU设备上的memory
链接
Kernel与其他逻辑单元之间的链接,代表各逻辑单元执行的指令的数量。例如Kernel和Global之间的链接表示全局内存空间的加载/存储的指令数量。
逻辑单元和物理单元之间的连接代表了由于相关指令而发出的请求(Req)的数量。
物理单元之间的连接代表了各单元间传输的数据量。
连接的箭头代表数据传输的方向,颜色代表了该链路的利用率百分比,右侧的图例代表了从0%到100%之间不同利用率的颜色。某些链路共享同一个数据端口,在图表中,端口用带颜色的梯形表示,其颜色代表了该端口的利用率。
1.3.3 Memory Table
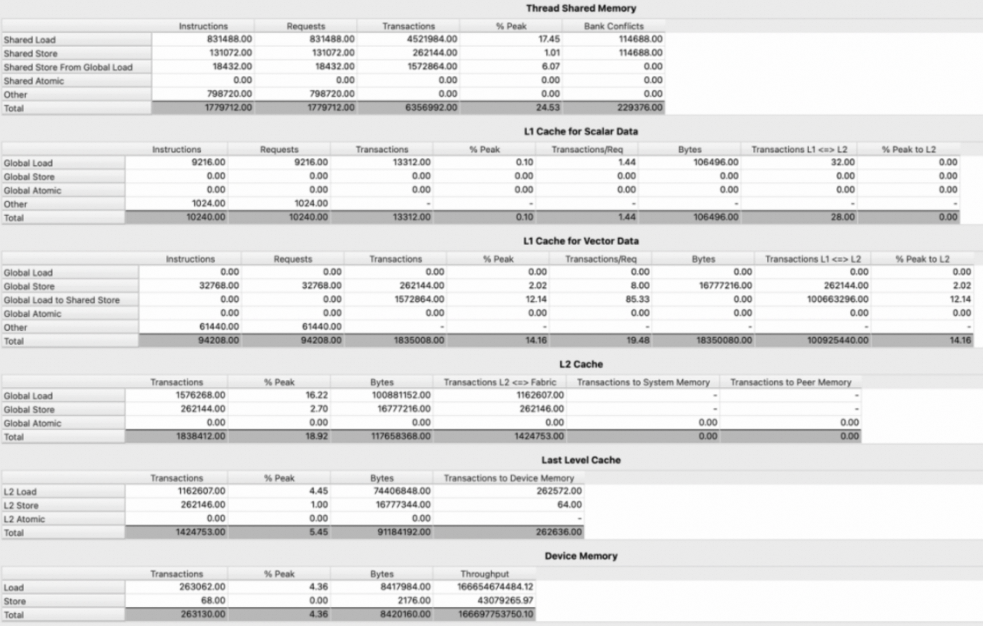
Memory table展示了了各种内存单元的详细指标,例如shared memory,cache,和device memory等。将鼠标悬停在表格条目上时,可以查看具体的metrics和详细信息。
1.4 Scheduler Statistics Section
Scheduler Statistics section展示了warp scheduler的warp调度情况,每个warp scheduler维护一个warp池,可以为其中的warp发出指令。warp池的大小受kernel启动配置的限制,最多16个warp。每个周期,warp scheduler都会检查每个warp的状态。根据warp状态的不同,将warp分为以下4类:
Active Warp:一个warp只要可以被warp scheduler调度,就处于Active状态,直到warp执行完最后一条指令。
Eligible Warp:可以发射下一条指令的warp,比如某个计算指令所需的数据都已就绪。
Stalled Warp:由于各种原因而不能发射下一条指令的warp,比如等待barrier,等待上一条指令的执行结果等。
Selected Warp:被选中执行下一条指令的eligible warp。
下图展示了各状态warp的关系:
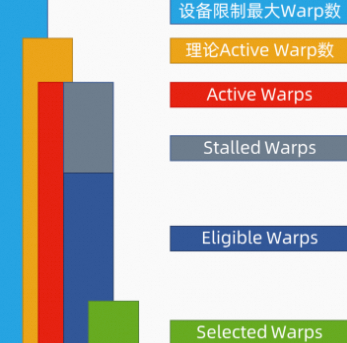
由上图可知,active的warp个数不会超过理论active warp个数,即Device Limit>= Theoretical Active Warps>= Active Warps。
根据是否可以发射下一条指令,active warp被分为stalled warp和eligible warp,即Active Warps = Stalled Warps+ Eligible Warps。
每个周期,warp scheduler会从eligible warps选择一个warp发射下一条指令,在没有eligible warp的周期中,不发出任何指令,影响kernel性能。
1.4.1 Header Table

Header table展示了warp scheduler的指令发出情况,具体含义如下:
项目 | 详细信息 |
Active Warps Per Scheduler | 每个周期,平均每个warp scheduler中的active warps数量,取值范围:[0, 16] |
Eligible Warps Per Warp Execution | 每个周期,平均每个warp scheduler中的eligible warps数量,小于Active Warps Per Scheduler |
Issued Warps Per Scheduler | 每个周期,平均每个warp scheduler发射的warp个数,理想值为1 |
No Eligible | 是一个百分比,代表没有eligible warps的周期数占整个活动周期数的比例。没有eligible warp可用,warp scheduler就不会发射指令 |
One or More Eligible | 是一个百分比,代表至少有一个eligible warps的周期数占整个活动周期数的比例,理想值为100%。 One or More Eligible= 1 - No Eligible |
1.4.2 Warps Per Scheduler Bar Chart
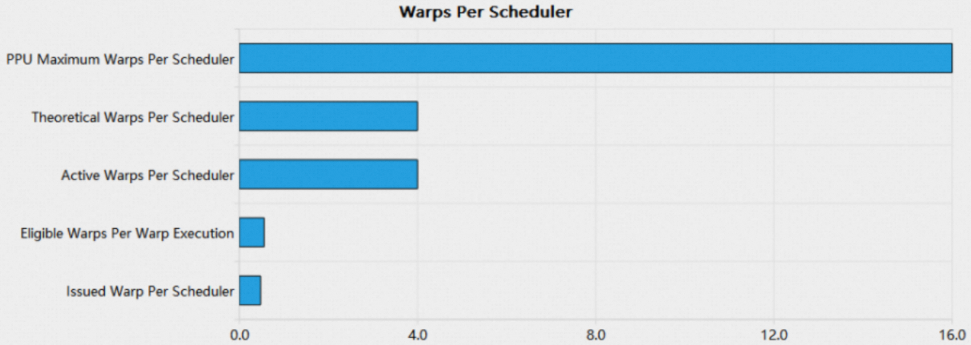
Warps Per Scheduler bar chart以柱状图的形式展示了每个周期,每个warp scheduler上平均各状态warp的数量。
理想情况下,每个周期,warp scheduler可以发出一条指令,当Issued Warps Per Scheduler较低时(通常小于0.6),说明PPU资源没有被很好的利用,导致kernel性能不佳。Issued Warps Per Scheduler数值较低的直接原因是eligible warps数量不足,要提升kernel性能,可以:
查看Occupancy section,确保kernel的高占有率,使其theoretical active warps的值为16。
查看Warp State Statistics section,找到最主要的stall reason,减少warp花在该stall reason的时间,提高eligible warps数量。
避免因为负载不均衡导致的warp执行时间差异。
1.5 Warp State Statistics Section
Warp State Statistics section展示了kernel执行过程中,warp执行每条指令花费的平均周期数,这个周期数决定了执行两条指令之间的延迟,周期数越高,则需要更多的warp并行来隐藏延迟。Section中还展示了在执行指令的周期中,active warps的状态统计。Warp状态描述了当前周期warp能否准备好发出下一条指令,以及相关的原因。
1.5.1 Warp Stall Reasons
PPU将active warps的状态分为15种,如下表所示:
Warp状态 | 详细信息 |
Instruction Fetch | 等待指令的获取。如果kernel的规模很小,不到一个完整的wave,这种stall会比较常见;如果代码中有频繁的分支跳转,指令缓存命中率低,也会出现这种stall |
Compute Dependency | 等待其所依赖的上一条计算指令的完成 |
Memory Dependency | 等待其所依赖的上一条访存指令的完成 |
Memory Throttle | 因为memory指令队列满而stall,这种stall在memory管道利用率很高时出现 |
Not Selected | 等待warp scheduler调度。该状态下的warp属于eligible warps,由于另一个eligible warps被warp scheduler选中,所以此warp的状态为Not Selected,如果此状态下的warp数量很多,意味着有充足的warp来掩盖延迟 |
Selected | 被warp scheduler选中,并发出了下一条指令。该状态下的warp属于selected warp |
Stall Pipe Busy | 因为相关的功能单元pipe繁忙而stall |
Stall Sleeping | 因为warp处于sleep状态而stall |
Stall Sync | 因为等待其他warp到达同步点而stall。这种stall通常是因为在barrier之前的代码分支导致的,可能导致某些warp花费较长时间等待其他warp。如果可能,尽量减少block内的代码分支。 |
Stall SALU Control | 因为等待上一条scalar控制指令而stall,或者SCTL pipe繁忙 |
Stall SIMT Control | 因为等待上一条SIMT指令而stall |
Stall SREG Read | 因为等待SREG读取而stall,或者SREG port繁忙 |
Stall Fence Sys | 因为等待fence.sys指令而stall |
Stall AMC | 因为电源AMC而stall |
Stall Others | 因为其他硬件原因而stall |
1.5.2 Header Table

Header table中项目具体含义如下:
项目 | 详细信息 |
Warp Cycles Per Issued Instruction | 对于每条发出的指令,warp花费的平均周期数 |
Warp Cycles Per Executed Instruction | 对于每条执行的指令,warp花费的平均周期数 |
Avg. Active Threads Per Warp | 平均每个warp活动的线程数 |
执行每条发出指令的平均周期数(Cycles Per Issued Instruction,CPI),是衡量kernel性能的重要指标。
1.5.3 Warps Per Scheduler Bar Chart
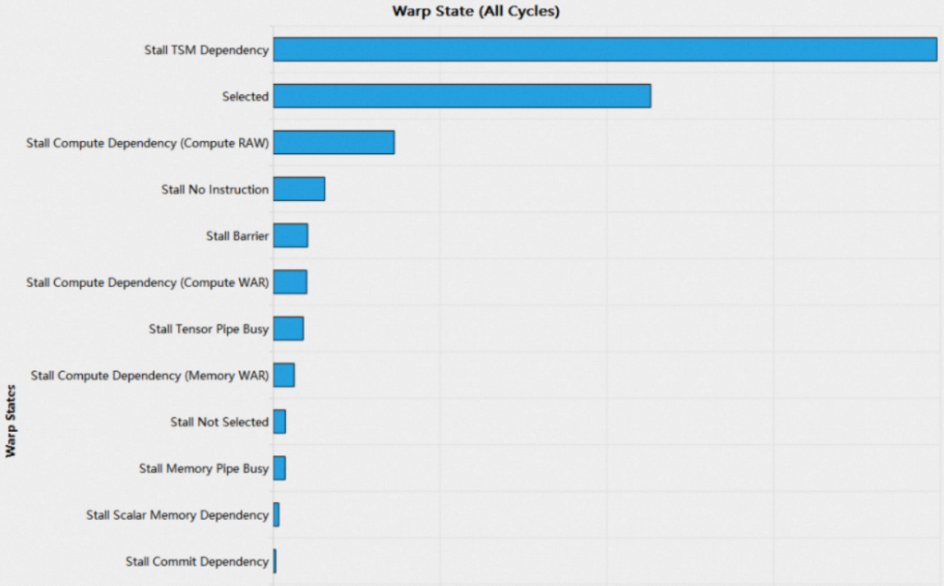
Warps Per Scheduler bar chart列出了所有的warp stall reason,并按照降序排列。所有的warp stall reason周期加起来等于Warp Cycles Per Issued Instruction。Warp stall是无法避免的,只有在Warp State Statistics section中No Eligible值较高时,才会考虑warp stall reason。
1.6 Instruction Statistics Section
本section可查看执行低级汇编指令(SASS)的相关统计信息。
1.6.1 Header Table

Header table中项目具体含义如下:
项目 | 详细信息 |
Executed Instructions | kernel执行过程中执行的指令数 |
Issued Instructions | kernel执行过程中发出的指令数 |
Avg. Executed Instructions Per Scheduler | 平均每个warp scheduler执行的指令数 |
Avg. Issued Instructions Per Scheduler | 平均每个warp scheduler发出的指令数 |
1.6.2 Executed Instruction Mix Bar Chart
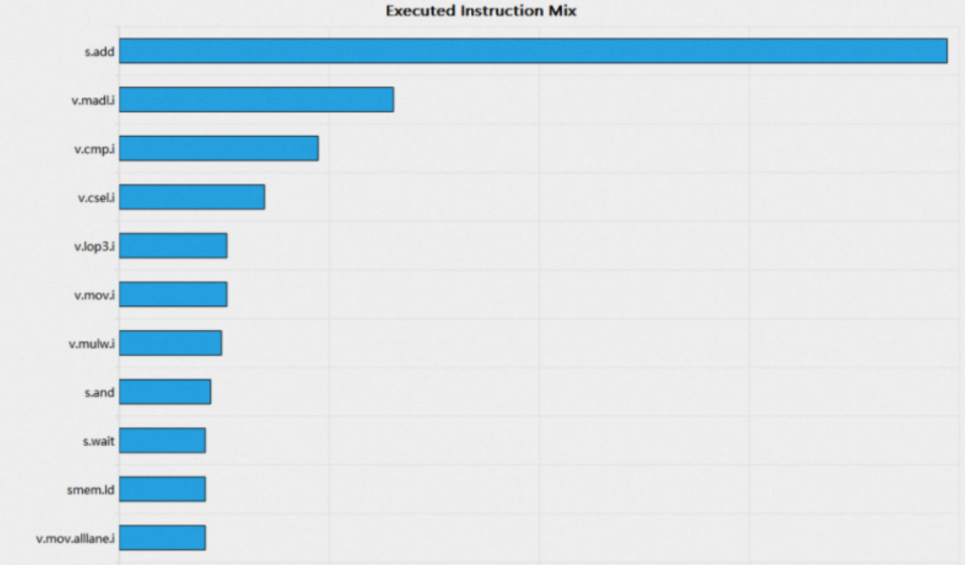
Executed Instruction Mix bar chart列出了每个kernel执行的各项指令,并且按指令执行数降序排列。可以通过该bar chart查看fused指令(例如fma)和non-fused指令(例如add,mul)的数量,如果non-fused指令占比较高,可以考虑将其转变为fused指令以提高指令吞吐。
1.7 ICNlink Section
本section可查看ICNlink利用率的概况,包括接收和发送的总的内存大小、链路的峰值利用率等。

Header table中项目具体含义如下:
项目 | 详细信息 |
Received Bytes | 通过ICN link接收的数据大小 |
Received Peak Utilization | ICN link接收数据的峰值利用率 |
Received Overhead Bytes | 通过ICN link接收的overhead数据大小 |
Received User Bytes | 通过ICN link接收的user数据大小 |
Transmitted Bytes | 通过ICN link发送的数据大小 |
Transmitted Peak Utilization | ICN link发送数据的峰值利用率 |
Transmitted Overhead Bytes | 通过ICN link发送的overhead数据大小 |
Transmitted User Bytes | 通过ICN link发送的user数据大小 |
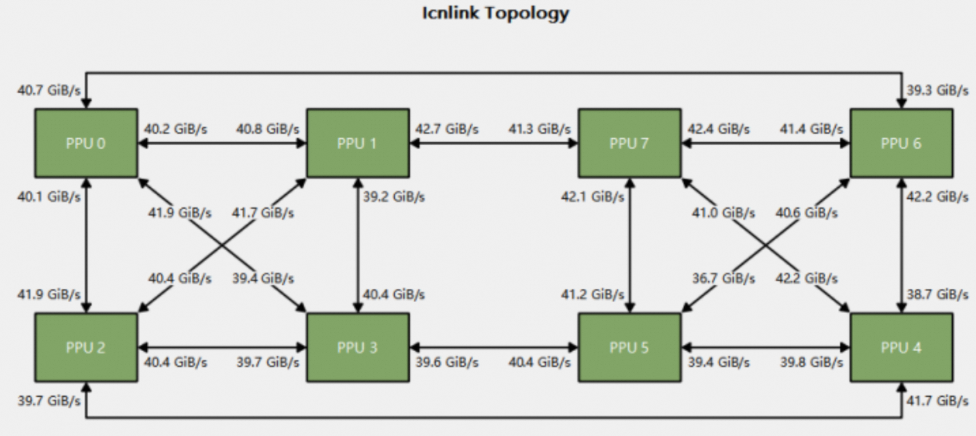
拓扑图直观地展示了各个device的连接情况以及数据传输情况:
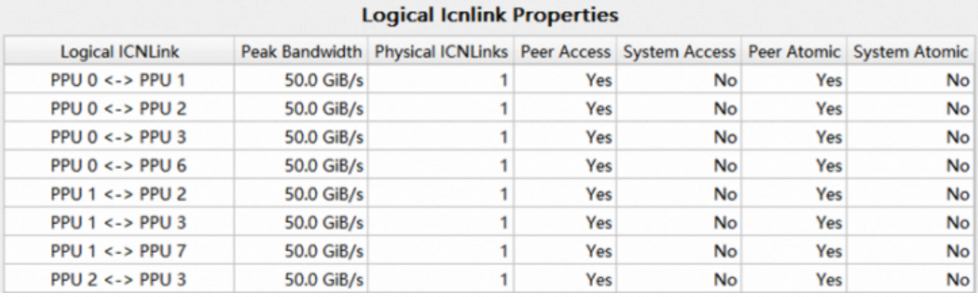
属性表格展示了ICNlink的属性, 包括峰值带宽,物理连接数量等信息:
吞吐表格则展示了当前range执行时ICNlink的吞吐, 带宽利用率和空闲时间:

在吞吐细节表格中,显示了每个device的port的收发数据细节:

1.8 Launch Statistics Section
本section可查看执行本kernel时使用的配置信息,包括grid size、block size以及执行本kernel所需的PPU资源信息等。

Header table中项目具体含义如下:
项目 | 详细信息 |
Grid Size | Grid中block的数量 |
Block Size | Block中thread的数量 |
Threads | Kernel启动的总thread数,等于Grid Size* Block Size |
Waves Per CU | 平均每个CU的Wave数量 |
Registers Per Thread | 每个线程使用的寄存器数量 |
Static Shared Memory Per Block | 每个block使用的静态分配的共享内存大小 |
Dynamic Shared Memory Per Block | 每个block使用的动态分配的共享内存大小 |
Kernel的启动配置直接影响占有率的大小,为保证kernel性能,考虑:
Warp中有32个线程,Block Size应该为32的倍数。
Grid Size应该远大于CU的数量,如果block的数量比CU小,会导致部分CU没有负载,考虑减少Block Size或者增加Grid Size。
通过Waves Per CU,判断是否有拖尾效应(Tail Effect)。PPU上能够同时执行的block数被称为一个wave,如果Waves Per CU的值不为整数,则说明PPU执行的最后一个wave不能填满PPU,导致占有率降低,性能下降。考虑调整Block Size使得Waves Per CU的值接近整数。
1.9 Occupancy Section
Occupancy section展示了kernel执行的占有率信息。占有率是一个CU上active warp数与最大可同时运行的Warp数的比值,当有足够多的Warp时,PPU可以利用Warp的切换掩盖延迟,高占有率是Kernel高效执行的必要条件。目前每个CU上理论最大active warp数为64个。一个CU上active warp数受到如下3个因素的限制:
Block尺寸
每个Thread使用的Register数量
每个Block使用的Shared Memory尺寸
1.9.1 Header Table

Header table中项目具体含义如下:
项目 | 详细信息 |
Theoretical Occupancy | 理论占有率,根据kernel的启动配置计算出来的理论值 |
Theoretical Active Warps per CU | 理论每个CU上活动的warp数,根据kernel的启动配置计算出来的理论值 |
Achieved Occupancy | 实际占有率,由于取的是各CU的平均值,可能与理论值有差距 |
Achieved Active Warps Per CU | 实际每个CU上活动的warp数,由于取的是各CU的平均值,可能与理论值有差距 |
Block Limit Registers | 当前寄存器数量限制下,每个CU上block的最大数量 |
Block Limit Shared Mem | 当前共享内存尺寸限制下,每个CU上block的最大数量 |
Block Limit Warps | 在active warp数量最大为64的限制下,每个CU上block的最大数量 |
Block Limit CU | 在CU上管理的最大block数的限制下,每个CU上block的最大数量 |
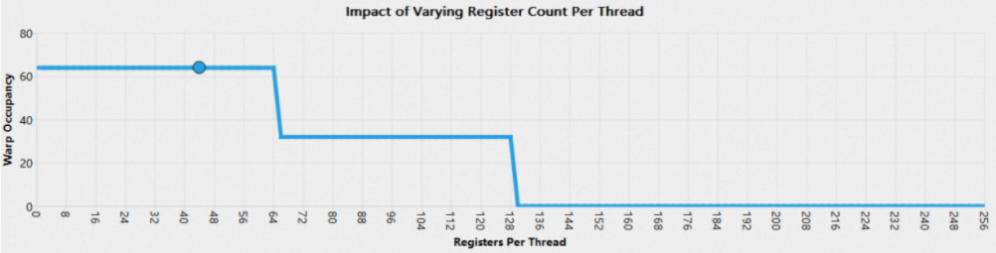
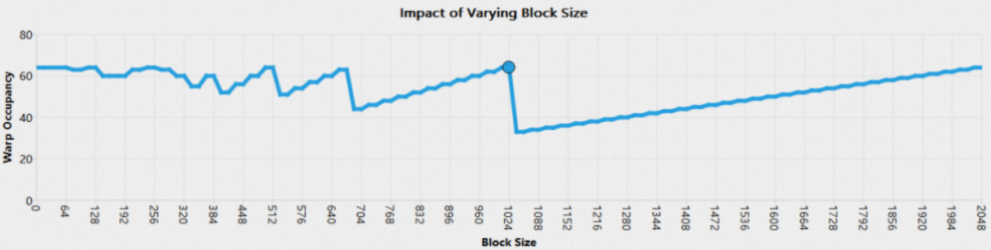
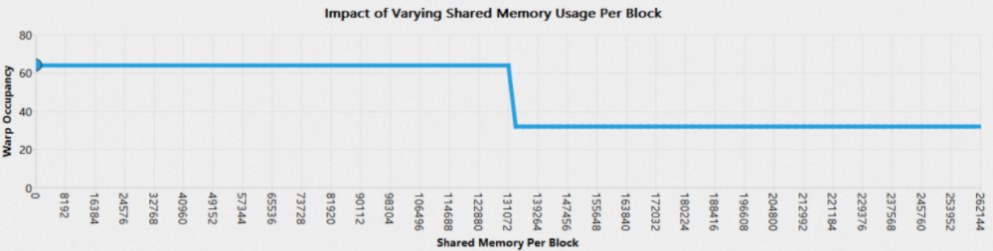
1.9.2 Occupancy Line Chart
Occupancy Section以3个折线图分别反映了上述3个条件对Occupancy值的影响。折线图的横坐标表示某条件的理论取值上限,纵坐标表示在其余2个条件的值固定为实际值时,该条件对应的Occupancy的理论值。折线上的圆点表示当前实际值,将鼠标悬停在点上可以查看具体值。
1.10. Source Counters Section
Source Counters section可以辅助找到kernel代码中的性能问题。此section提供3个表格,每个表格分别显示当前kernel的所有汇编代码行中,指定metric(stall reasons/inst executed/ thread inst executed)值最高的几行,点击后可跳转至source page查看详情,方便用户快速定位到有性能瓶颈的代码:
Warp Stall Sampling (All Samples)
Most Instructions Exected
Most Thread Instructions Executed
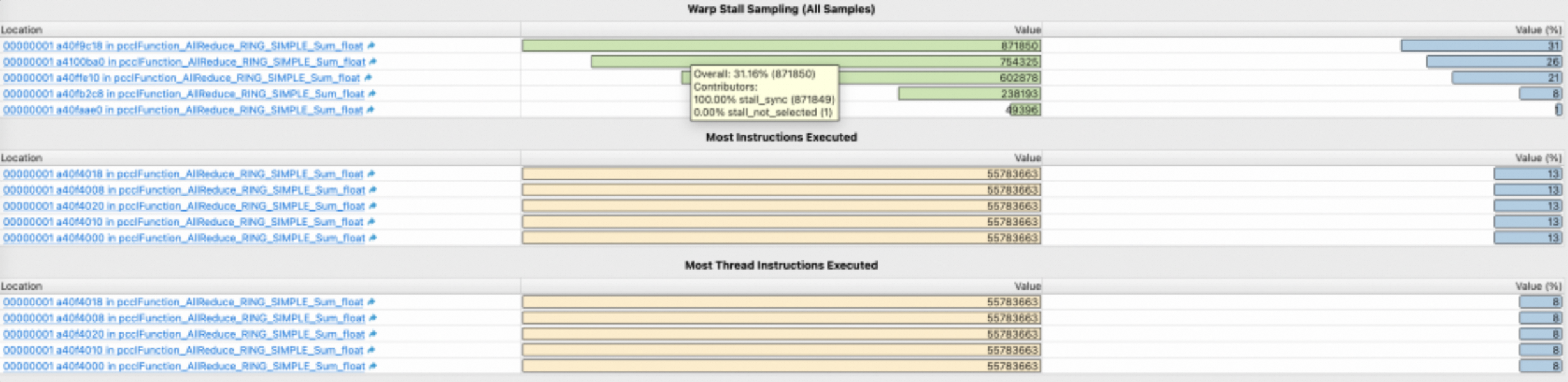
表格第一列为相关代码行的地址和所属function的名称,点击后可跳转到Source Page查看详情。
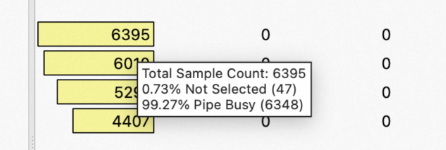
表格第二列为该行代码的metric的值。鼠标悬放到单元格,可以从tooltip查看该metric的构成情况,比如Warp Stall Sampling表,tooltip为具体每个stall reason的值以及占比。
表格第三列为该行代码的metric值占所有行的metric总值的百分比。
2. Source Page
Source Page主要是显示源代码与汇编代码之间的关联,同时还包括一些与源代码相关联的metric信息,包括通过PC sampling采集的各种stall reasons,以及通过指令统计得到的指令执行次数metrics。如果应用程序通过-G或者-lineinfo编译配置参数进行编译,程序内部会附带debug信息,当解析报告时,可以将源代码与汇编进行关联。
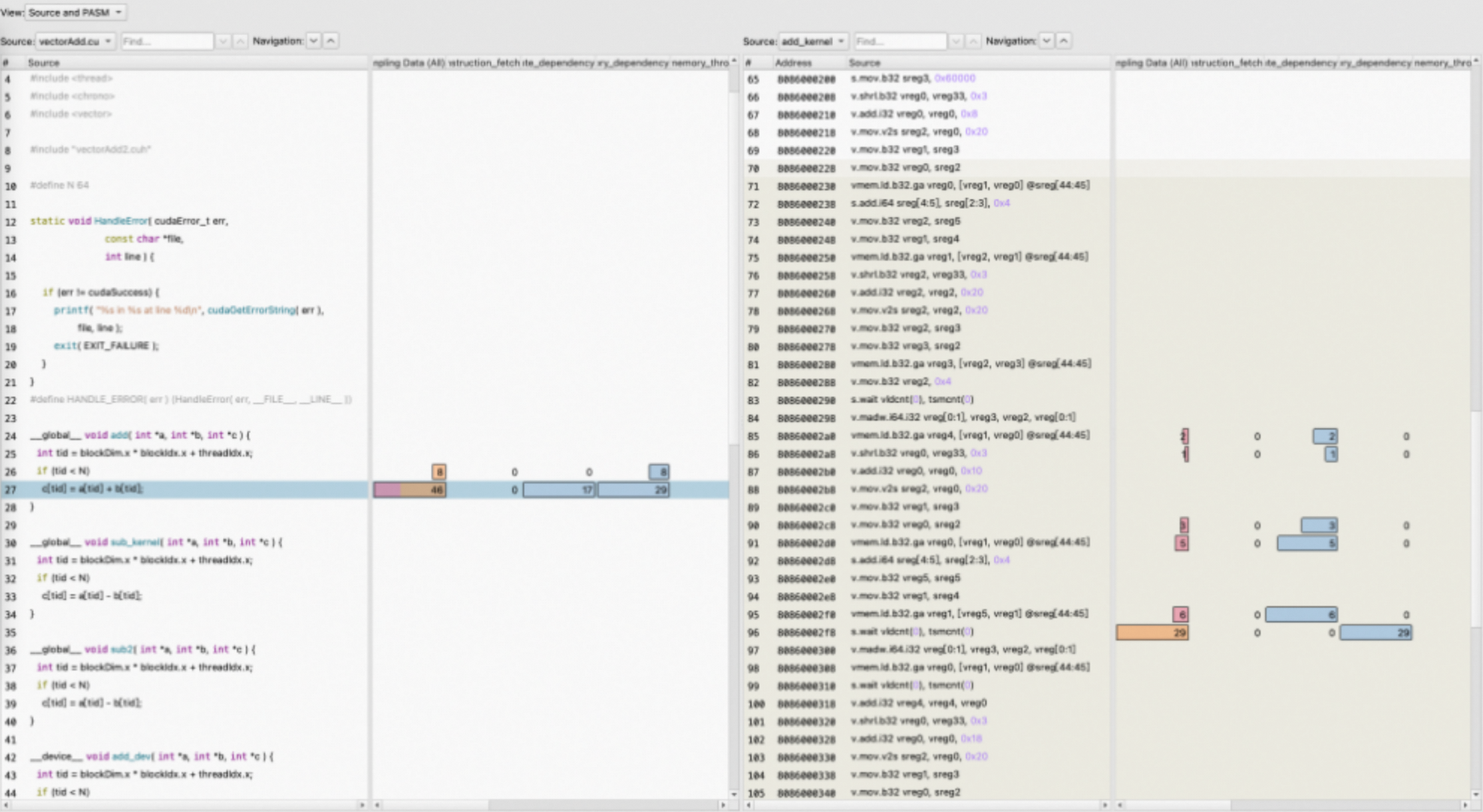
可以在Source and PASM界面点击左侧源代码行,右侧汇编会高亮显示与之相关联的代码行。反之,右侧点击汇编,左侧源代码会高亮与之相关联的代码行。
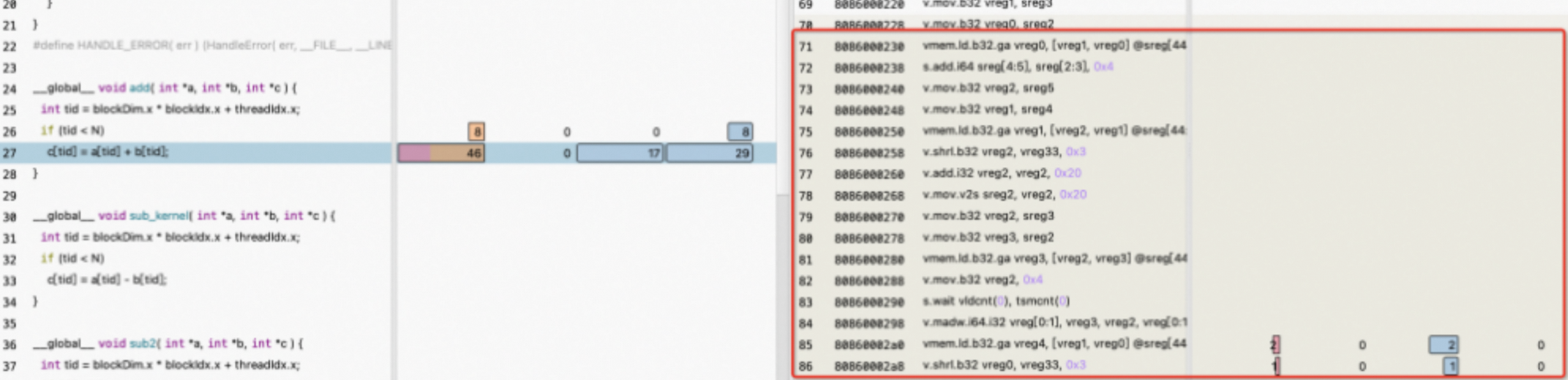

Warp Stall Sampling (All Cycles) metric汇总了各种类型的stall reasons,可以通过鼠标悬停,了解当前代码行对应的stall reason的汇总信息。
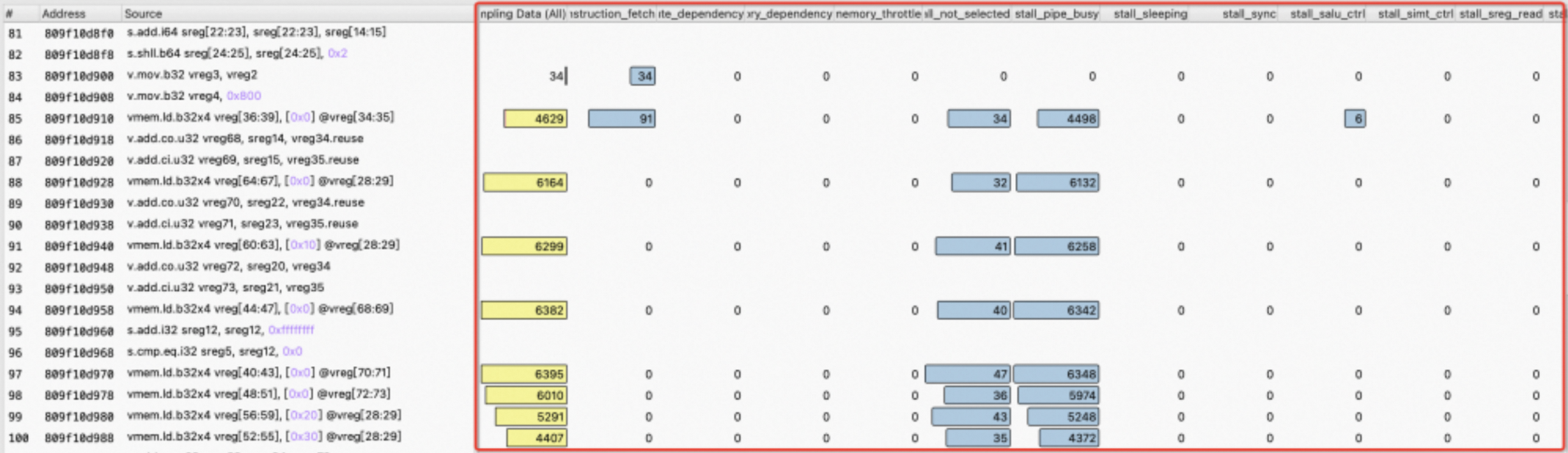
Instruction Executed以及Thread Instruction Executed汇总不同指令执行的warp数和thread数。

2.1 基本功能
View下拉菜单
可以使用该下拉菜单,在Source,PASM以及Source and PASM这三个界面切换显示状态。
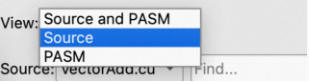
Source下拉菜单
可以通过该下拉菜单,在不同source code之间切换显示。
Metric显示格式切换按钮
提供3种metric显示样式调节按钮,对指令统计、stall reasons类型的metric列生效:

相对值/绝对值按钮
默认选相对值,metric值以相对总值的百分比形式显示(总值是全局还是局部取决于第三个选项)。

数字缩写/原值按钮
此选项仅当第一个选项选了绝对值时,才启用。
默认选缩写,比如23456为原值,23K为缩写。
局部、全局范围按钮
局部 指的是计算相对值时,分母是当前source的所有代码行的metric总值。
全局 指的是计算相对值时,分母是所有source的代码行的metric总值。
默认选全局。


备注:对于Source View(源码)来说,source即源码文件,对PASM View(汇编码)来说,source即function。例如下面的例子,该kernel源码总共有两个source,saxpy.cu和vector_functions.hpp。对于saxpy.cu的某行代码,其inst_executed这个metric的值为5,而saxpy.cu的所有代码行的inst_executed总值为40,vector_functions.hpp的所有代码行的inst_executed总值为60。在局部+相对模式下,表格中显示的值为5/40 = 12.5%;在全局+相对模式下,表格中显示的值为5/100 = 5%;而在绝对模式中,局部/全局模式会被忽略,表格中直接显示原值5。
每次打开报告后,默认使用上述选项的默认值。在Options中可以改变前两种选项的默认值:

在Options中修改这两项默认值不会在已打开的source page中生效。
Find栏
界面提供了查找功能,当想要快速查找Source中某一段代码时,可以键入相关关键字,通过上下按钮查找上一条/下一条记录。
Navigation栏
Navigation栏是为了快速定位到与汇编代码存在关联的代码行上,并通过上下按钮进行上一条/下一条记录的切换。

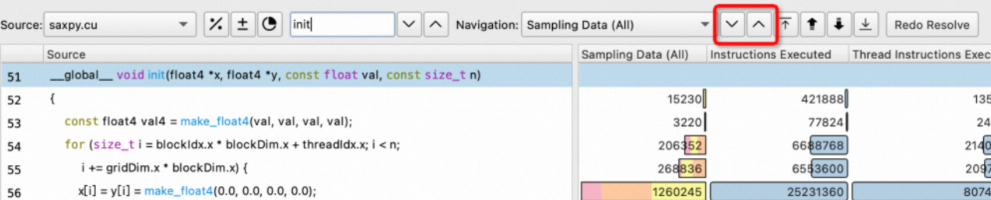
Metric排序按钮
Source Page metric排序功能用于快速找到所有行中,指定metric的最大/次大/次小/最小的一行代码。例如希望找到某个metric最大的代码行,首先在metric下拉列表中选择相应的metric,再点击选择最大按钮,就能找到最大的一行,若想找到更小的一行,则再点击选择次小按钮。
图中从左到右依次为选择最大/次大/次小/最小按钮。
右键菜单
Source Page中的表格支持以下右键菜单功能:
Copy:复制选择的内容到剪贴板。
Copy as CSV:以CSV格式复制选择的内容到剪贴板。
Select All:选中表格的所有内容。

2.2 导入源码
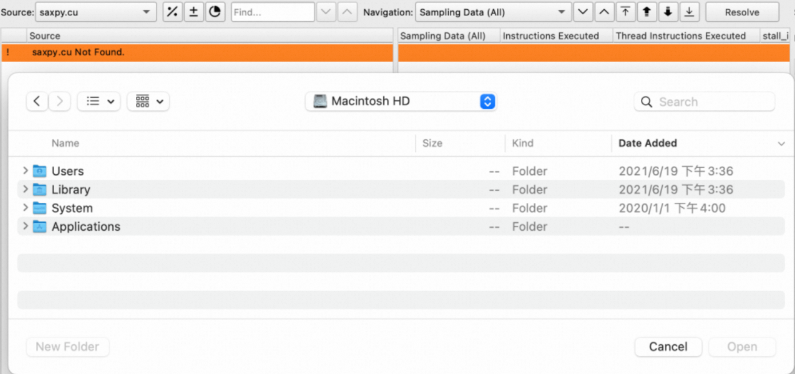
Resolve
acurep报告中默认是没有保存相关源码的,所以会提示当前源代码文件没有找到,需要点击Resolve来指定源代码目录。

Redo Resolve
在已导入source file的情况下,Source View提供Redo Resolve按钮,通过按钮可重新选择并导入file。

Source Lookup
在通过Resolve按钮指定了源码路径后,后续每次打开该报告都会在指定的路径载入源码,如果想要改变源码路径,可以使用Source Lookup功能。Tools->Options...->Source Lookup可以进入到Source Location管理菜单,在该界面,可以通过勾选决定是否启用之前已经加入的Source Loaction。
还可以通过小菜单按钮,添加、删除和调整加载源代码顺序。

2.3 查看性能问题的标记(Source Markers)
Source Page不仅可以提供每一行汇编码、源码的stall reasons、指令执行次数,还能在有性能问题(如代码中存在过多的F16/BF16全局内存原子操作指令等)的代码行左侧做标记,鼠标悬停在标记上可以看到具体的性能问题,这种标记称为Source Markers。同时,在Source Page底部提供Source Markers表,以代码文件为单位汇总了所有source markers。
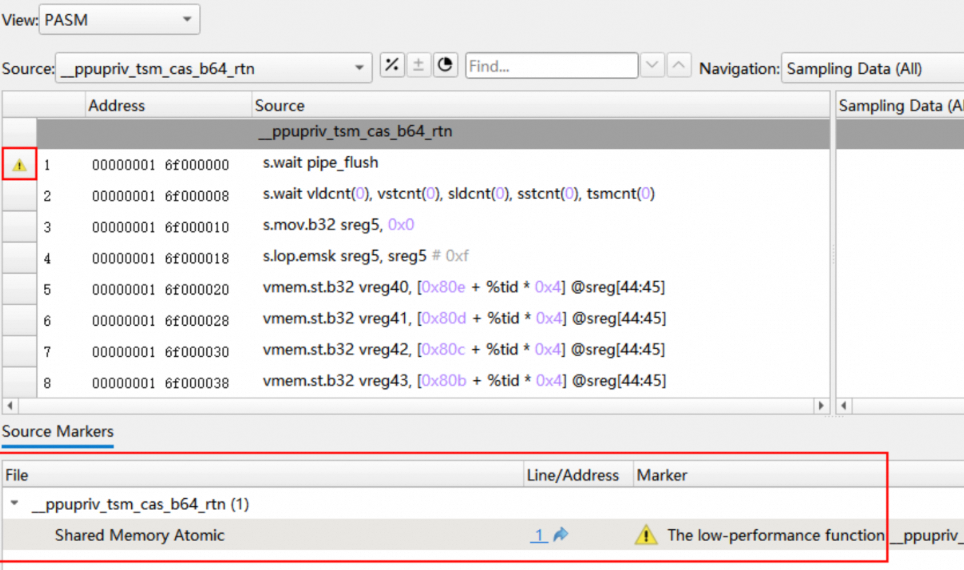
3. Raw Page
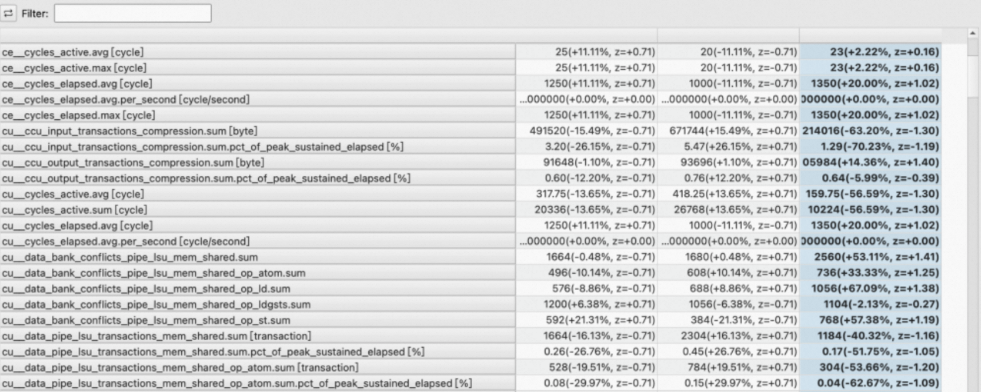
Raw Page显示收集到的所有kernel launch的metrics信息。

排序
点击metric列可以对该列进行排序。
筛选
在Filter输入框输入关键词,可以过滤掉不包含该关键词的metrics列。
转置
Raw Page支持表格转置的功能,提供metrics作为行,kernels作为列的浏览视角。
kernels间比较
双击表格内容会将对应的kernel切换为当前kernel。
添加baselines之后,表格中的值更新为差值形式:
<focus value> (<difference to baselines average [%]>, z=<standard score>) (<number of values>)

导出
可以通过右上角的菜单,将Raw Page中的表格导出到CSV等格式。
多实例metric格式更改
多实例类型的metric,在表格中有两种显示方式,在Options中可以配置以下方式显示:
not instanced:totalValue {instanceCount}如12 {3}
加baseline之后,多了totalValue跟其他baseline的差异,如12 (+0.00%){3}
instanced:totalValue {value1; value2; ...}如12 (2; 4; 6),
加baseline之后,多了totalValue跟其他baseline的差异,如12 (+0.00%)(2; 4; 6)


多实例类型的metric目前主要有3类:
指令执行次数:inst_executed、thread_inst_executed
指令分类:sass__inst_executed_per_opcode
stall reason:pu__pcsamp_warps_issue_stalled*
4. Summary Page
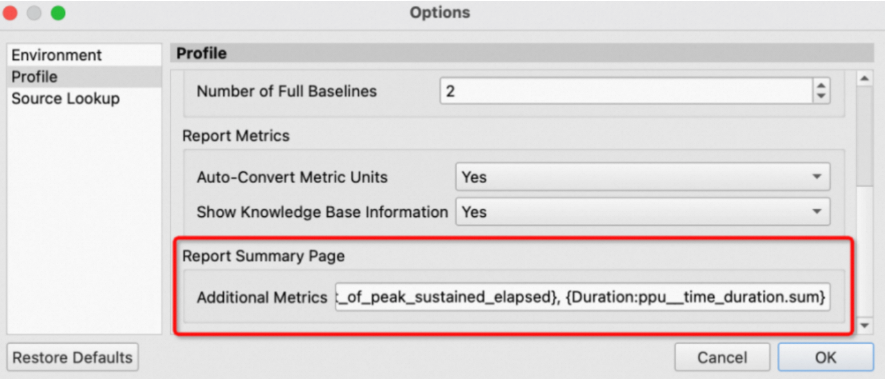
Summary Page显示收集到的所有kernel launch的重点关注的metrics信息,提供概览metrics的视角,方便从概要的metrics信息中确定需要进一步分析的kernel。本页面默认显示ID、Time、API Call ID、Function Name、Demangled Name、Process、Device Name、Grid Size、Block Size。可以在 Tools->Options->Profile->Report Summary Page选项中进行设置,新增额外显示的metric。填写格式为{customized_name:metric_name},metric_name为metric的原始名称,customized_name为显示名称。metrics间以逗号分隔。
Summary Page的排序、筛选、转置、kernels间比较、导出功能与Raw Page相似,此外,双击Summary Page表格内容会跳转到Details Page以供查看详细的metrics信息。
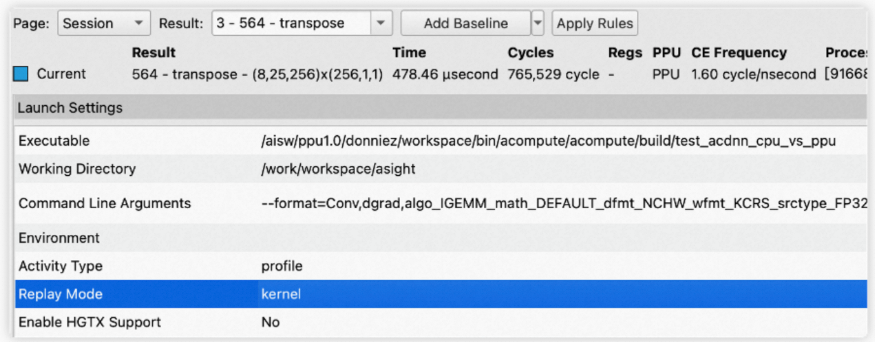
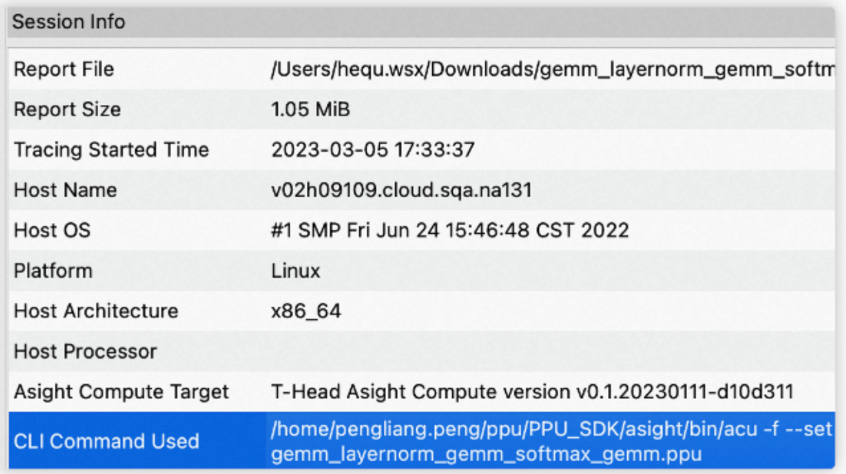
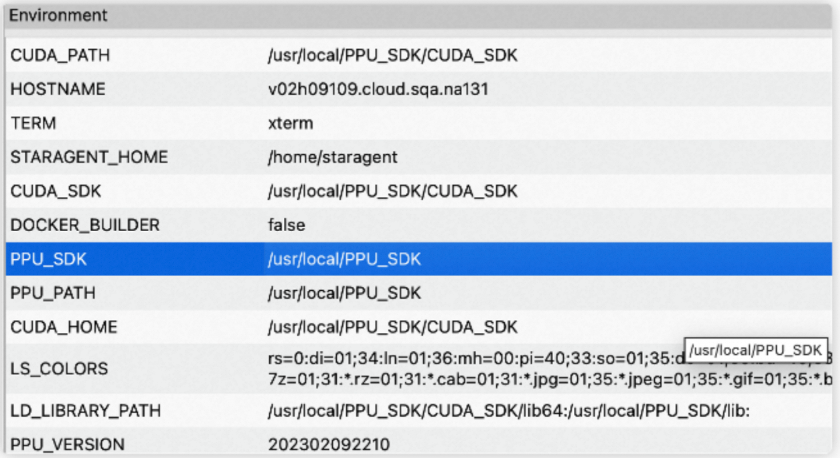
Session Page显示报告的一些基本信息,包括Launch Settings、Session Info、Processes、Environment、Device Attributes五组信息。切换kernel时,Session Page会高亮该kernel对应的device attributes。
Launch Settings
Session Info
Environment
Processes
Device Attributes
5. Baseline
Asight Compute提供Baseline对比功能,可以将多个kernel的profile结果进行对比,并且支持跨报告。Baseline管理界面如下所示:
将当前kernel添加为baseline
baseline的图例,在图表中baseline的颜色与图例相同
basline的名字,鼠标悬停时,可以重命名baseline
在不同的类型的UI中,baseline的表现形式不同。
图表中的Baseline
图表中除了当前kernel之外,还会显示baseline,其颜色与baseline的图例相同,如下图所示:

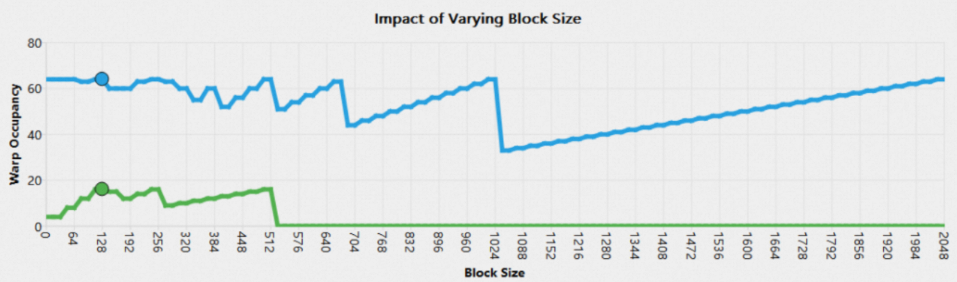
图表中的tooltip也会显示baseline的详细信息。
表格中的Baseline
当有一条baseline时,表格中会显示当前kernel的metrics与baseline对应metrics的差值百分比,如下图所示:

当有超过一条baseline时,表格中除了会显示metrics的差值百分比之外,还会显示标准分z(Standard Score)如下图所示:

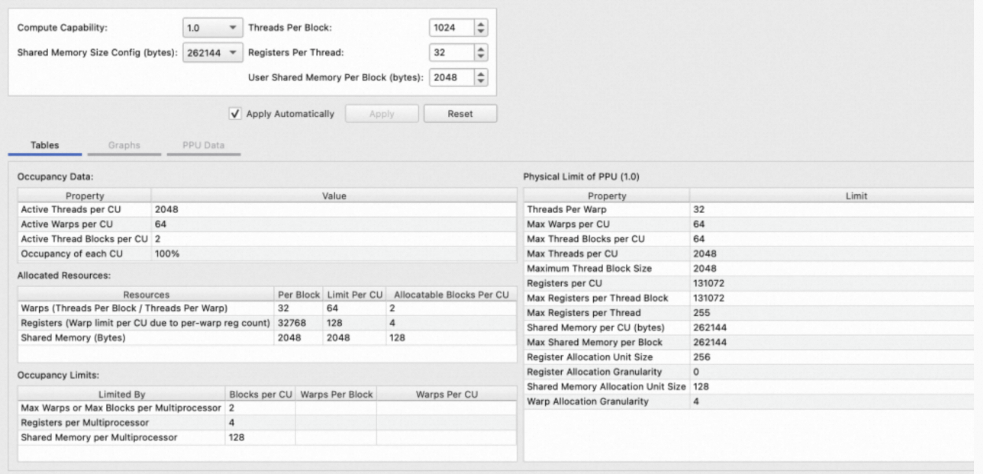
6. Occupancy Calculator Page
Occupancy Calculator Page可以计算指定配置下的占有率,并支持保存为文件供下次打开查看。此页面包含输入表单和结果图表两部分,其中结果图表又分为Tables、Graphs、GPU Data三个部分:
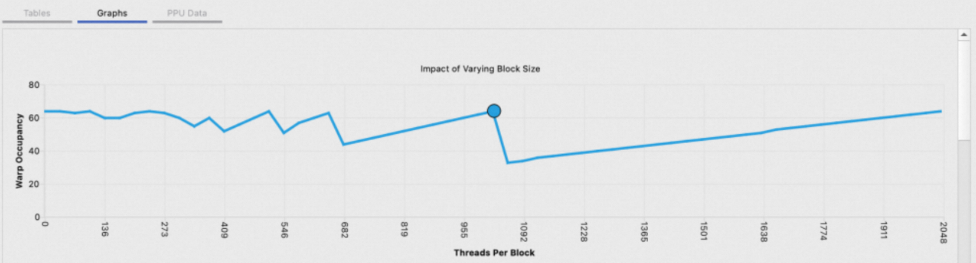

通过以下3种方式会新建/打开一个计算器:
点击报告顶部的Occupancy Calculator按钮。
点击Occupancy section旁边的计算器按钮。
通过File -> Open菜单打开文件时,选择.ncu-occ文件可打开此前保存的occ文件。


7. Metric Details Widget
勾选主菜单View->Metric Details或者点击报告顶部的Metric Details按钮,可以在应用右侧打开Metric Details Widget。在打开的报告中,点击Details page、Raw page、Summary page中的metric,可以在Metric Details Widget窗口中查看metric的详细信息。Metric Details Widget也提供搜索功能,可以查找当前报告中某个metric的详细信息。


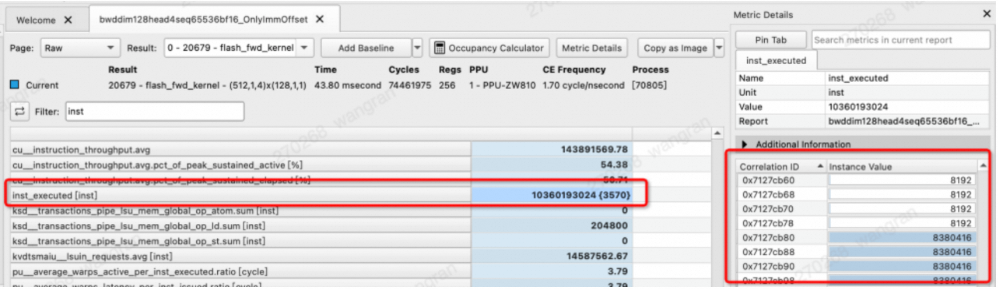
metric详细信息包括以下部分:
metric information,包括metric name、unit、value、report。
additional information,包括metric description、knowledgebase entry。
instance List,对于具有多instance的metric,instance list可以查看具体每一个instance的值。例如,打开Raw Page,选择inst_executed这个metric,可以看到每一个汇编码地址对应的指令执行次数值。除了指令执行次数的metric(inst_executed、thread_inst_executed)之外,指令统计metric(sass__inst_executed_per_opcode)、stall reason metric(pu__pcsamp_warps_issue_stalled*)也属于多instance metric。
点击报告中的metric或搜索某个metric后,默认会在第一个tab(Default Tab)中显示该metric的详细信息。可以通过Pin Tab按钮将Default Tab中的metric固定到一个新的独立的tab中(Pinned Tab),方便将多个metrics暂存并在它们之间切换进行对比。