
acu命令行工具
Asight Compute提供了命令行工具Asight Compute CLI(下面简称acu),可以在不使用GUI工具的情况下对目标应用进行性能分析,并输出报告文件。此报告可以拷贝到其他平台,后续由GUI工具进行解析展示。
acu主要功能:
支持采集应用在PPU上执行时的性能数据,并汇总为各项指标(metric)输出,如:
理论峰值相关指标
计算工作负载
内存工作负载
Warp调度器统计
Warp运行状态和指令Stall原因统计
指令统计
ICN链路相关指标
支持以set、section和metric三种粒度指定采集的metric集合。
当需要采集的metric列表超过PPU设备能力时,支持自动replay应用程序以获取所有性能数据。
支持Application Replay模式
支持Kernel Replay模式
支持Range Replay模式
支持Application Range Replay模式
支持指定性能数据采集范围,并支持多种kernel过滤方式。
可指定采集的PPU设备
可指定采集的Context ID和Stream ID
可指定采集的Kernel名称
可通过cudaProfilerStart/Stop(), hggcProfilerStart/Stop()指定采集的范围
指定采集kernel的个数
指定跳过kernel的个数
支持PC Sampling模式。
1. 采集性能数据
1.1 查看支持的metric
可通过指定metric集合,来指定性能数据的采集范围。指定metric集合可以通过三种粒度:
metric: 衡量PPU某方面性能的一个指标,是acu可指定采集范围的最小粒度。
section: 由多个逻辑相关的metrics的组成,acu内置了多种section,也可通过创建 / 修改一个section文件来自定义section。
set: 由一个或者多个section组成,是acu可指定采集范围的最大粒度。
1.1.1 查询metric set信息
可通过--list-sets命令行选项,查看当前acu支持的metrics set的详细信息,显示的表格说明如下:
root@d29fb2dd227a:/# acu --list-sets
------------ ----------------------------------------------------------------------------- --------- -------------------
Identifier Sections Enabled Estimated Metrics
------------ ----------------------------------------------------------------------------- --------- -------------------
default Occupancy,MemoryWorkloadAnalysis,SpeedOfLight,SpeedOfLight_TensorRooflineC- yes 314
hart,ComputeWorkloadAnalysis,SpeedOfLight_RooflineChart,LaunchStats
detailed MemoryWorkloadAnalysis_Tables,SchedulerStats,Occupancy,SourceCounters,Memo- no 520
ryWorkloadAnalysis,SpeedOfLight,WarpStateStats,SpeedOfLight_TensorRoofline-
Chart,InstructionStats,ComputeWorkloadAnalysis,SpeedOfLight_RooflineChart,-
LaunchStats
full Icnlink_Tables,MemoryWorkloadAnalysis_Tables,InternalDebug,SchedulerStats,- no 821
Occupancy,Icnlink_Topology,SourceCounters,MemoryWorkloadAnalysis,Professio-
nal,SpeedOfLight,WarpStateStats,SpeedOfLight_TensorRooflineChart,MemoryWor-
kloadAnalysis_Chart,InstructionStats,ComputeWorkloadAnalysis,SpeedOfLight_-
RooflineChart,LaunchStats,Icnlink
systems Systems no 0 Identifier列: metrics set的名称,此名称可作为
--set选项的参数来指定采集哪个set。Sections列:set包含的section列表,可通过查看section列表,以确定此set是否满足采集需求。
Enabled列: set是否被使能,默认使能default set。
Estimated Metrics列: set内包含的metrics个数,个数可用来评估采集引入的overhead的相对大小。
注意:set的详细信息在不同的版本,可能会有差异,以实际查询到结果为准。
1.1.2 查询metric section信息
可通过--list-sections命令行选项,查看支持的section列表,section在GUI中显示的名称,以及section文件的预置路径,默认显示default set包含的section信息。显示的表格说明如下:
root@d29fb2dd227a:/# acu --list-sections
---------------------------------- ------------------------------------------------- --------- --------------------------------------------------
Identifier Display Name Enabled FileName
---------------------------------- ------------------------------------------------- --------- --------------------------------------------------
InstructionStats Instruction Statistics no /usr/sections/InstructionStatistics.section
MemoryWorkloadAnalysis Memory Workload Analysis yes /usr/sections/MemoryWorkloadAnalysis.section
MemoryWorkloadAnalysis_Chart Memory Workload Analysis Chart no /usr/sections/MemoryWorkloadAnalysis_Chart.sect-
ion
MemoryWorkloadAnalysis_Tables Memory Workload Analysis Tables no /usr/sections/MemoryWorkloadAnalysis_Tables.sec-
tion
SchedulerStats Scheduler Statistics no /usr/sections/SchedulerStatistics.section
SpeedOfLight_RooflineChart PPU Speed Of Light Roofline Chart yes /usr/sections/SpeedOfLight_RooflineChart.section
SpeedOfLight_TensorRooflineChart PPU Speed Of Light Roofline Chart (Tensor Core) yes /usr/sections/SpeedOfLight_TensorRooflineChart.-
section
ComputeWorkloadAnalysis PPU Compute Workload Analysis yes /usr/sections/ComputeWorkloadAnalysis.section
Icnlink ICNLink no /usr/sections/Icnlink.section
InternalDebug Debug PPU All Metrics no /usr/sections/InternalDebug.section
SpeedOfLight PPU Speed Of Light Throughput yes /usr/sections/SpeedOfLight.section
WarpStateStats Warp State Statistics no /usr/sections/WarpStateStatistics.sectionIdentifier列: metrics section的名称,后续可通过
--section选项指定此名称以指定采集范围。Display Name列:本section在Asight Compute中显示的名称。
Enabled列: 本section是否被使能。
FileName列: 本section对应的section文件存放路径。
注意:section的详细信息在不同的版本,可能会有差异,以实际查询到结果为准。
另外,也可通过--set选项查看指定set的section信息,Enabled列的值为yes表示该section在指定的set中可用:
root@eb8b441561f7:~# acu --set=full --list-sections
---------------------------------- ------------------------------------------------- --------- --------------------------------------------------
Identifier Display Name Enabled FileName
---------------------------------- ------------------------------------------------- --------- --------------------------------------------------
InstructionStats Instruction Statistics yes /usr/sections/InstructionStatistics.section
MemoryWorkloadAnalysis_Chart Memory Workload Analysis Chart yes /usr/sections/MemoryWorkloadAnalysis_Chart.sect-
ion
MemoryWorkloadAnalysis_Tables Memory Workload Analysis Tables yes /usr/sections/MemoryWorkloadAnalysis_Tables.sec-
tion
ComputeWorkloadAnalysis PPU Compute Workload Analysis yes /usr/sections/ComputeWorkloadAnalysis.section
Icnlink ICNLink no /usr/sections/Icnlink.section
InternalDebug Debug PPU All Metrics yes /usr/sections/InternalDebug.section
MemoryWorkloadAnalysis Memory Workload Analysis yes /usr/sections/MemoryWorkloadAnalysis.section
SchedulerStats Scheduler Statistics yes /usr/sections/SchedulerStatistics.section
SpeedOfLight PPU Speed Of Light Throughput yes /usr/sections/SpeedOfLight.section
SpeedOfLight_RooflineChart PPU Speed Of Light Roofline Chart yes /usr/sections/SpeedOfLight_RooflineChart.section
SpeedOfLight_TensorRooflineChart PPU Speed Of Light Roofline Chart (Tensor Core) yes /usr/sections/SpeedOfLight_TensorRooflineChart.-
section
WarpStateStats Warp State Statistics yes /usr/sections/WarpStateStatistics.section注意:set包含哪些section,在不同的版本,可能会有差异,以实际查询到结果为准。
指定section文件搜索路径
acu支持指定section文件的搜索路径,如果指定了搜索路径,则查询到的section为路径下的所有以.section为后缀的文件。有两种指定方式:
--section-folder:指定section文件的搜索路径,acu在此文件夹内搜索以.section为后缀的文件,不递归搜索子文件夹。--section-folder-recursive:指定section文件的搜索路径,acu在此文件夹和所有子文件内递归搜索以.section为后缀的文件。
例如,查看/usr/custom的section信息:
acu --list-sections --section-folder=/usr/custom/1.1.3 查询metric列表
可通过--list-metrics命令行选项,查询支持的metric列表。默认情况下查询default set所包含的metric列表,可以通过--section或者--set查询指定section或者set所包含的metric。
查询section包含的metric列表
通过--section查询指定section所包含的metric。
root@d29fb2dd227a:/# acu --section SpeedOfLight --list-metrics
breakdown:cu__throughput.avg.pct_of_peak_sustained_elapsed
breakdown:ppu__compute_memory_throughput.avg.pct_of_peak_sustained_elapsed
ce__cycles_active.max
ce__cycles_elapsed.avg.per_second
ce__cycles_elapsed.max
cu__cycles_active.avg
cu__throughput.avg.pct_of_peak_sustained_elapsed
dram__cycles_elapsed.avg.per_second
l1__throughput.avg.pct_of_peak_sustained_active
l2__throughput.avg.pct_of_peak_sustained_elapsed
llc__throughput.avg.pct_of_peak_sustained_elapsed
ppu__compute_memory_throughput.avg.pct_of_peak_sustained_elapsed
ppu__dram_throughput.avg.pct_of_peak_sustained_elapsed
ppu__time_duration.sum查询set包含的metric列表
通过--set查询指定set所包含的metric
root@d29fb2dd227a:/# acu --set=default --list-metrics
breakdown:cu__throughput.avg.pct_of_peak_sustained_elapsed
breakdown:ppu__compute_memory_throughput.avg.pct_of_peak_sustained_elapsed
ce__cycles_active.max
ce__cycles_elapsed.avg.per_second
ce__cycles_elapsed.max
cu__cycles_active.avg
cu__inst_executed.avg.pct_of_peak_sustained_active
cu__inst_executed.avg.per_cycle_active
cu__inst_executed.avg.per_cycle_elapsed
cu__inst_executed_pipe_falu_fp16.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_falu_fp32.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_lsu.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_sfu.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_simt_control.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_sls.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_tensor_fp16.avg.pct_of_peak_sustained_active
cu__inst_executed_pipe_tensor_tf32.avg.pct_of_peak_sustained_active
cu__instruction_throughput.avg.pct_of_peak_sustained_active
cu__memory_throughput.avg.pct_of_peak_sustained_elapsed
cu__throughput.avg.pct_of_peak_sustained_elapsed
dram__bytes.sum.peak_sustained
dram__bytes.sum.per_second
dram__cycles_elapsed.avg.per_second
ksd__transaction_hit_rate.pct
kvd__transaction_hit_rate.pct
l1__throughput.avg.pct_of_peak_sustained_active
l2__throughput.avg.pct_of_peak_sustained_elapsed
l2__transaction_hit_rate.pct
llc__average_lcu_input_transaction_success_rate.pct
llc__average_lcu_output_transaction_compression_achieved_rate.ratio
llc__throughput.avg.pct_of_peak_sustained_elapsed
llc__transaction_hit_rate.pct
ppu__compute_memory_access_throughput.avg.pct_of_peak_sustained_elapsed
ppu__compute_memory_request_throughput.avg.pct_of_peak_sustained_elapsed
ppu__compute_memory_throughput.avg.pct_of_peak_sustained_elapsed
ppu__dram_throughput.avg.pct_of_peak_sustained_elapsed
ppu__time_duration.sum
pu__cycles_elapsed.avg.per_second1.1.4 查询metric描述信息
可通过执行acu --query-metrics,查询metric的描述信息,例如:
root@0549cf16bb85:~# acu --query-metrics
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Metric Name Type Unit Metric Description
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ce__cycles_active.avg Counter cycle # of cycles active on CE across CEs
ce__cycles_active.max Counter cycle # of cycles active on CE across CEs
...
dram__bytes_read.sum Counter byte # of bytes read from DRAM
dram__bytes_read.sum.pct_of_peak_sustained_elapsed Counter % # of bytes read from DRAM
dram__bytes_read.sum.per_second Counter byte/second # of bytes read from DRAM
...
l2__transaction_hit_rate Ratio unitless (0.x) hit rate of L2 cacheable requests
l2__transaction_hit_rate.pct Ratio % (0.x) hit rate of L2 cacheable requests
...
Metric Name列:查询metric的name
Type列:metric的类型,有三种:
Counter:PPU的原始counter
Ratio:两个Counter的比值
Throughput:由一组Counter组成,计算每一个Counter占PPU峰值的百分比,其中,最大的百分比即为Throughput
Unit列:metric的单位
Metric Description列:metric的描述信息
Tips:在Asight Compute GUI中,可通过鼠标悬停在性能指标名字上的方式,或打开Metric Details页面,查看对应的metric和相关描述信息:
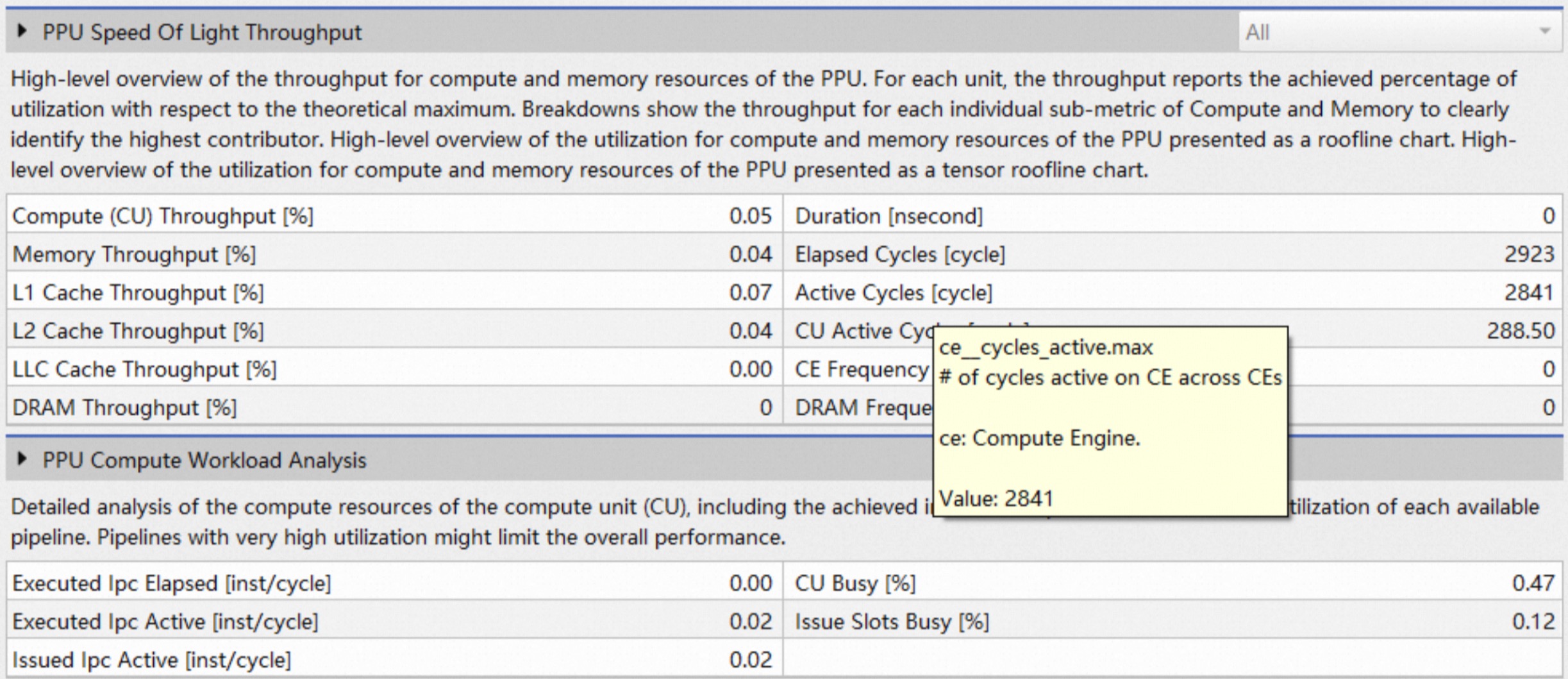
1.2 指定采集的metric集合
可选择set、section和metric中的一种粒度,来指定采集的metric集合。
三种粒度的组合效果描述如下:
若
--set--section--metrics三个选项都没有指定,则生效的metric集合为default set。若指定
--section或者--metrics,则通过--set指定的set无效。--section和--metrics选项可混合使用,生效的metric集合为两者的并集。
Tips:粒度越大,采集的metric也就越多。当需要采集的metric个数超过PPU能力上限时,应用程序可能会被replay多次以采集所有metric数据,从而导致acu的profile耗时增加。
1.2.1 指定采集的set
通过--set选项可指定使能的metric set,基本规则如下:
只允许一个set被使能。
若无
--set被指定,并且--section或--metrics也没被指定,默认使能default set。
例如,使能detailed set,可通过下面命令:
acu -o test_report -f --set="detailed" ./cuda_test 10默认使能的default set不是所有metric的集合,比如内存吞吐量的metric就不在default set。如果有需要采集内存吞吐量等相关的metric,可使能full set,以采集所有metric,命令如下:
acu -o test_report -f --set="full" ./cuda_test 101.2.2 指定采集的section
通过--section选项可指定使能的metric section,基本规则如下:
每个
--section指定一个section的匹配规则section规则匹配方式有两种:
精准匹配:指定section的Identifier,只有Identifier完全匹配的section才会被使能(可通过
--list-sections选项查看section的Identifier)。正则匹配:指定正则表达式,规则语法为
regex:<expression>。所有Identifier能匹配正则表达式<expression>的section都将被使能。
如果同时指定多个
--section匹配规则,只有最后设置的section规则生效。
举例:通过正则表达式"regex:.*WorkloadAnalysis"使能所有以WorkloadAnalysis结尾的section,这样,ComputeWorkloadAnalysis、MemoryWorkloadAnalysis等section都会被使能:
acu --section="regex:.*WorkloadAnalysis" python test_linear.py举例:依次指定SpeedOfLight和SchedulerStats两个精准匹配规则,只有sectionSchedulerStats会被采集:
acu --section SpeedOfLight --section SchedulerStats python test_linear.pyTips:由于正则表达式语法可能会被linux shell处理,使用正则表达式指定section时,建议用""包裹参数,例如:--section="regex:.*Analysis.*"
1.2.3 指定采集的metric
通过--metrics选项可指定使能的metric列表,基本规则如下:
多个metric名字之间通过,分隔,可通过
--list-metrics查看支持的metric 名称列表。如果同时指定多个
--metrics选项,只有最后设置的metric列表生效。如果同时指定
--section,那么,该section包含的metric和--metrics指定的metric都会被采集。--metrics的名称规则匹配方式有两种:精准匹配,包含3种情况:
指定metric全名。
指定metric group全名:语法为group:<group name>,本metric group内的所有metric都将被采集。
指定breakdown全名:语法为breakdown:<metric name>,本metric拆分的所有子metric都将被采集并计算。
正则匹配:语法为regex:<expression>,所有名称能匹配正则表达式<expression>的metric将被采集。
Tips:
metric group和breakdown可通过
--list-metrics命令行选项查询。由于正则表达式语法可能会被linux shell处理,使用正则表达式指定metric时,建议用""包裹参数,例如:
--metrics="regex:dram.*"。
举例:采集ce__cycles_active.max和dram__bytes.sum.per_second2个metric,命令如下:
acu --metrics=ce__cycles_active.max,dram__bytes.sum.per_second python test_linear.py举例:采集groupmemory__chart包含的所有metric,命令如下:
acu --metrics="group:memory__chart" python test_linear.py举例:采集并计算 cu__throughput.avg.pct_of_peak_sustained_elapsed和ppu__compute_memory_throughput.avg.pct_of_peak_sustained_elapsed两个metric的所有子metric的值(不计算这两个metric的值),命令如下:
acu --metrics=breakdown:cu__throughput.avg.pct_of_peak_sustained_elapsed,breakdown:ppu__compute_memory_throughput.avg.pct_of_peak_sustained_elapsed python test_linear.py举例:指定正则表达式,采集包含cycles_elapsed的所有metric(比如:ce__cycles_elapsed.avg.per_second和ce__cycles_elapsed.max),命令如下:
acu --metrics="regex:cycles_elapsed.*" python test_linear.py举例:指定正则表达式,采集所有以dram开头metric(比如:ram__bytes.sum.peak_sustained和dram__bytes.sum.per_second会被采集,ppu__dram_throughput.avg.pct_of_peak_sustained_elapsed不会被采集),命令如下:
acu --metrics="regex:^dram.*$" python test_linear.py1.3 指定Replay模式
由于在PPU上同时可采集的 Performance Counter(硬件)个数是有上限的,当需要采集Performance Counter(所有metric依赖的)个数超过上限时,acu需要重播(replay)kernel多次(重播一次称为一个pass),并且每次重播需设置不同的counter配置,以保证所有metric数据被采集。
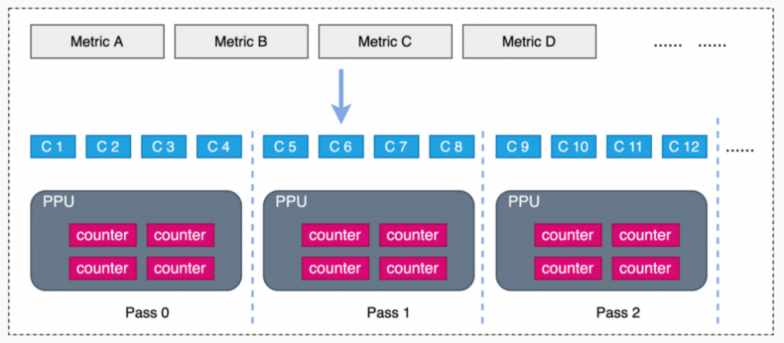
acu支持多种重播(replay)模式,默认采用 kernel replay模式采集数据,可通过--replay-mode选项指定replay模式:
Replay模式 | 模式说明 | Profiling对象 | 程序执行次数 | 保存/恢复内存 | Overhead | 不适用场景 |
kernel | 在一次程序执行中,依次分别对每个kernel进行replay | Kernel | 1次 | 是 |
| Kernel必须concurrent执行 |
application | 多次执行应用程序,一次程序执行对应一次repaly,并依次采集每个kernel的性能指标 | Kernel | 多次 | 否 | 多次应用程序启动耗时 |
|
range | 在一次程序执行中,依次分别对每个Range(包含kernel launch,HGGC API调用)进行replay | Range | 1次 | 是 |
|
|
app-range | 多次执行应用程序,一次程序执行对应一次repaly,并依次采集每个Range(包含kernel launch,HGGC API调用)的性能指标 | Range | 多次 | 否 | 多次应用程序启动耗时 | 程序的执行行为不确定 |
由于每种replay模式对应用程序的影响方式各有不同(或改变程序中kernel的执行顺序,或引入一些性能损耗),需要根据应用程序的具体实现,选择适合本应用程序的replay模式。
举例:使用kernel replay模式采集性能数据。
acu --replay-mode kernel python test_linear.py1.3.1 Kernel Replay模式
Kernel Replay模式是在一次应用程序执行过程中,通过对每个kernel执行多次的方式,采集所有metric数据。在kernel第一次执行前备份PPU设备内存,后续在每一次replay kernel前恢复第一个pass备份设备内存。
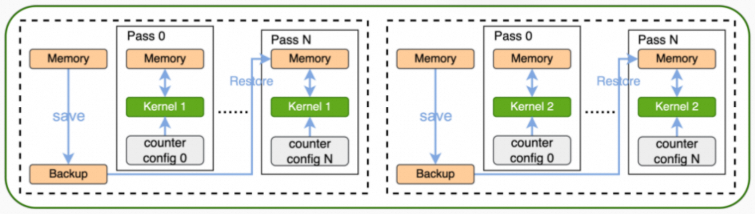
Kernel Replay模式的主要特点如下:
replay在一次应用程序执行中完成。
按照kernel粒度采集性能数据。
应用程序的kernel被强制串行执行。
kernel执行前,存在内存备份/恢复操作,将增加整个应用执行耗时。
内存备份将消耗设备内存资源。
因为Kernel Replay在profiling时会对kernel强制串行化,所以,并不是所有程序都适用,下面详说明其适用/不适用场景。
适用场景
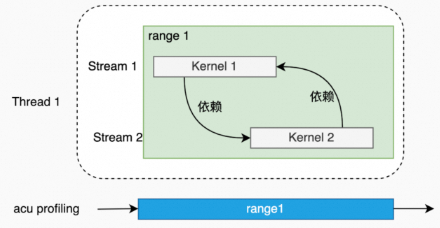
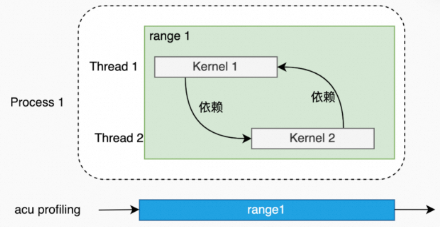
单进程,单线程(所有kernel在一个线程里依次launch)。
单进程,多线程(多个线程里的kernel不相互依赖)。
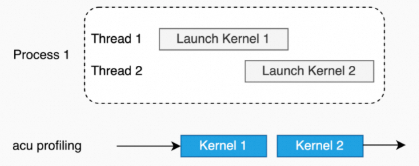
多进程(多个进程里的kernel不相互依赖)。

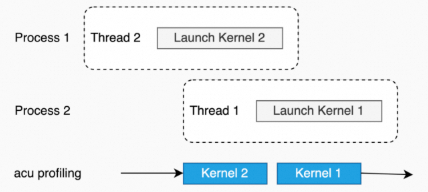
不适用场景
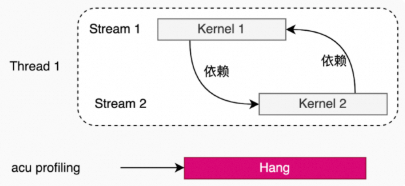
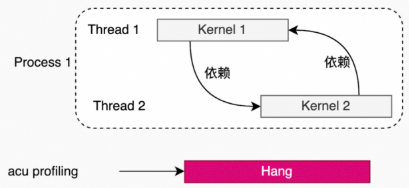
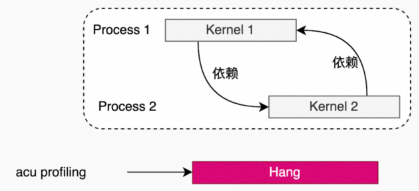
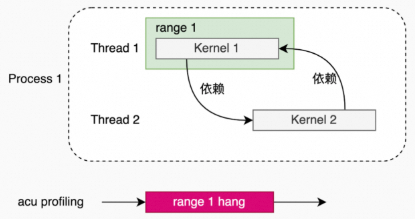
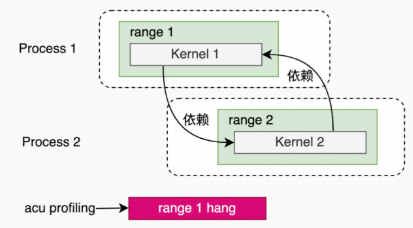
如果kernel之间有依赖关系,在使用Kernel Replay时,会出现hang的情况。
单进程,单线程(kernel之间有依赖关系)。
例子:pccl-tests(1个进程,1个线程,2个rank)。
acu --set full -f -o all_reduce_2_ranks_2M ./build/all_reduce_perf -g 1 -t 2 -n 1 -w 0 -b 2M -e 2M -c 0单进程,多线程(多个线程里的kernel存在依赖关系)。
例子:pccl-tests(1个进程,2个线程,每1个线程一个rank)。
acu --set full -f -o all_reduce_2_ranks_2M ./build/all_reduce_perf -g 1 -t 2 -n 1 -w 0 -b 2M -e 2M -c 0多进程(多个进程里的kernel存在依赖关系)
例子:pccl-tests(2个进程,每1个进程1个线程,每1个线程1个rank)。
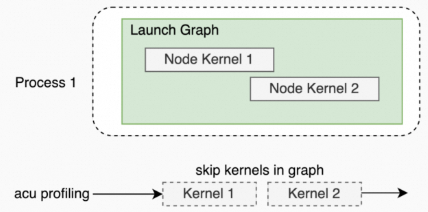
ncu --set full --replay-mode kernel --target-processes all -o all_reduce_perf_kernel_p2_t1_g1 mpirun -np 2 --allow-run-as-root ./build/all_reduce_perf -g 1 -t 1 -n 1 -w 0 -b 2M -e 2M -c 0Graph场景(被HGGC Graph launch起来的kernel)。
目前版本仅支持graph作为整体进行profiling,默认情况下,graph内kernel都会被acu忽略,所以,报告中也无法查询这些kernel的性能数据。
1.3.2 Application Replay模式
Application Replay模式是通过多次执行应用程序的方式,采集所有metric数据。由于是重复启动应用程序,Application Replay模式不需要对每个kernel做内存的备份和恢复,但是需要保证应用程序在多次执行中行为尽可能保持一致(比如:kernel的名称 / 数量 / 执行顺序等)。
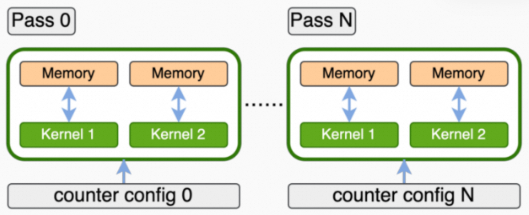
Application Replay模式的主要特点如下:
应用程序被执行多次,以保证所有metric数据被采集。
按照kernel粒度采集性能数据。
应用程序kernel之间强制串行执行。
若应用程序host端存在大量耗时操作(如初始化),多次replay将增加执行耗时。
适用/不适用场景
因为Application Replay和Kernel Replay一样,在profiling时会对kernel强制串行化,所以,Kernel Repaly的适用/不适用场景说明一样适用于Application Replay。具体请参考Kernel Replay的:适用场景和不适用场景。
由于Application Replay是跨应用程序的replay,一个kernel的metric数据分散在多次应用程序执行中,这就存在一个跨应用程序kernel如何匹配的问题,acu针对这种情况,提供了--app-replay-mode和--app-replay-match两个命令行选项。
kernel匹配模式
acu提供--app-replay-mode选项,可以在Application Replay做kernel匹配时,指定是否严格检查应用多次执行的行为一致,有两种模式:
app-replay-mode可选值 | 模式描述 |
strict | 默认值,每次应用程序执行中的所有kernel都要和应用程序第一次执行中的所有kernel匹配。在任何一个pass中,如果匹配失败,则中断profiling流程。 |
relaxed | 不要求跨应用程序的所有kernel全部匹配,只输出能匹配的kernel的metric数据 |
Tips:如果一个程序在strict模式下无法生成报告,这说明应用程序的执行行为是不确定的,可以尝试relaxed模式,但最终生成的报告可能缺失某些kernel的性能数据。
kernel匹配策略
acu提供--app-replay-match选项,可以在Application Replay做kernel匹配时,指定kernel匹配策略(满足什么条件才认为是同一个kernel)。支持下面3种匹配策略:
app-replay-match可选值 | 匹配策略描述 |
name | kernel按照以下顺序匹配:
|
grid | 默认值, kernel按照以下顺序匹配:
|
all | kernel按照以下顺序匹配:
|
举例:使用application replay模式采集性能数据,宽松模式匹配,使用grid匹配策略进行匹配:
acu --replay-mode application --app-replay-mode relaxed --app-replay-match grid python test_linear.py1.3.3 Range Replay模式
Range Replay模式是在一次应用程序执行过程中,通过对一个Range(包含kernel launch和HGGC API调用)执行多次的方式,采集所有metric数据,并且metric数据跟整个range相关,而不再是其中的某个kernel。Range Replay会捕获range中的kernel launch和HGGC API调用,并执行必要的Host和Device内存的保存和恢复。
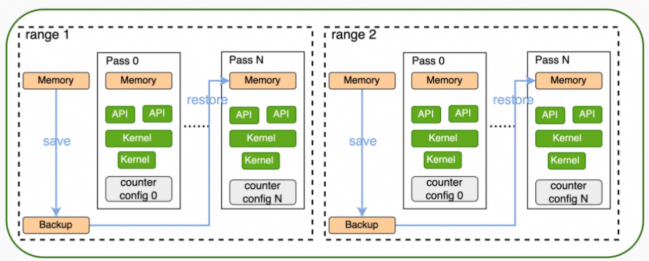
Range Replay模式的主要特点如下:
replay在一次应用程序执行中完成。
按照range粒度采集性能数据,非Kernel粒度。
range内的多个kernel可并行执行,不做强制做串行化。
replay range存在内存备份 / 恢复操作,将增加应用执行耗时。
range范围内只有部分HGGC API允许被使用。
range replay仅replay PPU Device侧的行为,Host端应用行为不会replay。
应用程序通过hg(gc)ProfilerStart和hg(gc)ProfilerStop定义range,并保证acu可以在range开始时同步所有context。
一个range内仅支持采集1个PPU设备上的性能数据。
range的定义
Range replay需要在应用程序中指定性能分析的range(范围)。一个range由起始和结束标记定义,包含在这些标记之间从任何CPU线程启动的所有HGGC API调用和内核。应用程序负责在线程之间插入适当的同步,以确保捕获到预期的API调用集合。可以使用以下两种选项之一设置range:
Profiler Start/Stop API
使用hg(gc)ProfilerStart设置起始标记,并使用hg(gc)ProfilerStop设置结束标记,这是Asight Compute range定义的默认选项。
hggcProfilerStart();
/* code for profiling, include HGGC API and Kernels */
hggcProfilerStop();HGTX range
使用HGTX include表达式来定义range。range捕获从第一个HGGC API调用开始,并在匹配到表达式的最后一个API调用处结束。如果指定了多个表达式,则在任何一个表达式匹配时都定义一个range。因此,可以使用多个表达式方便地捕获和分析同一应用程序执行的多个range。 应用程序必须使用HGTX API进行range的标记,以使表达式能够匹配。
hgtxRangeId_t r1 = hgtxRangeStartA("Range 1");
/* code for profiling, include HGGC API and Kernels */
hgtxRangeEnd(r1);适用场景
虽然Range Replay也可以在Kernel Replay的3个适用场景中运行,但Range Replay主要是为解决并行执行的多个kernel的profiling问题的(也就是Kernel Replay的不适用场景中的1,2两种情况)。
单进程,单线程(依赖的kernel在同一个range内)。
例子:pccl-tests(1个进程,1个线程,2个rank)。
acu --set full --replay-mode range -o all_reduce_perf_range_p1_t1_g2 ./build/all_reduce_perf -g 2 -n 1 -w 0 -b 2M -e 2M -c 0单进程,多线程(依赖的kernel在同一range内)。
例子:pccl-tests(1个进程,1个线程,2个rank)。
acu --set full --replay-mode range -f -o all_reduce_2_ranks_2M ./build/all_reduce_perf -g 1 -t 2 -n 1 -w 0 -b 2M -e 2M -c 0
不适用场景
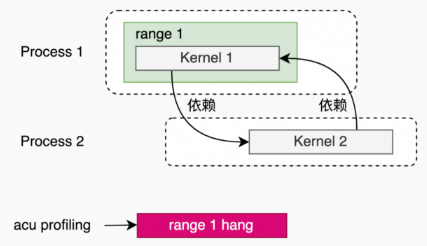
Range Replay的range是进程级的,所以,如果kernel在不同的线程,并相互依赖,那么,需要保证range包含这些相互依赖的kernel,否则,会发生hang。
另外,Range Replay会对range强制串行化,所以,一个进程内的range依赖其他进程的kernel或者range的话,会发生hang的情况。
单进程,多线程(相互依赖的kernel 没有在一个同一个range)。
多进程(一个进程内的range和另外一个进程的kernel存在依赖)。
例子:pccl-tests(2个进程,每1个进程1个线程,每1个线程1个rank,只在1个rank上定义了range)。
acu --set full --replay-mode range --target-processes all -o all_reduce_perf_range_p2_t1_g1 mpirun -np 2 --allow-run-as-root ./build/all_reduce_perf -g 1 -t 1 -n 1 -w 0 -b 2M -e 2M -c 0 -j 0多进程(一个进程内的range和另外一个进程的range存在依赖)。
例子:pccl-tests(2个进程,每1个进程1个线程,每1个线程1个rank,2个rank上都定义了range)。
acu --set full --replay-mode range --target-processes all -o all_reduce_perf_range_p2_t1_g1 mpirun -np 2 --allow-run-as-root ./build/all_reduce_perf -g 1 -t 1 -n 1 -w 0 -b 2M -e 2M -c 0
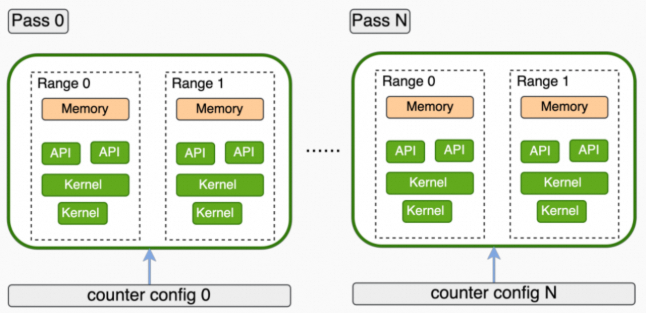
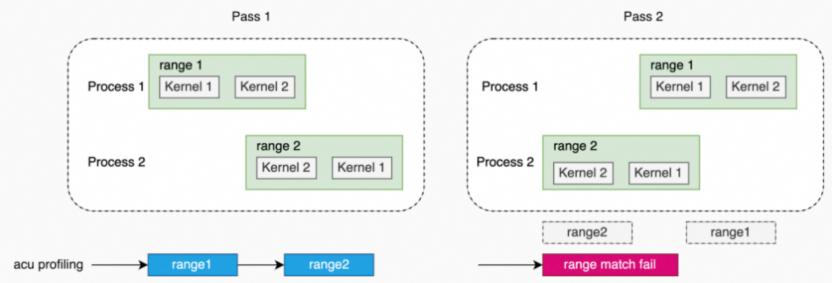
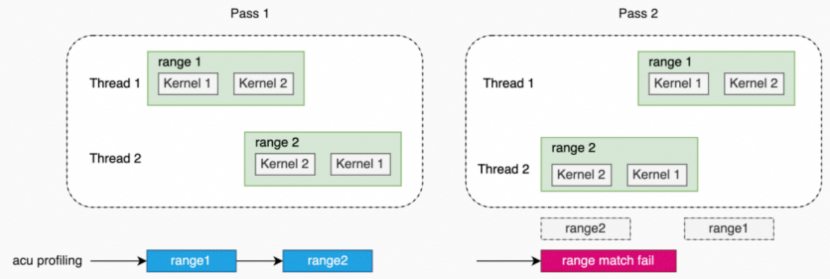
1.3.4 Application Range Replay
在Application Range Replay模式下,所有请求的metrics被分组为一个或多个pass。与Range Replay类似,metrics不是与单个kernel关联,而是与整个选择的range关联。工具无需对工作负载(kernel,graph等)串行化,所以,支持对需要并发执行的工作负载进行性能分析。
与Range Replay不同的是,每一个range不需要先被显式捕获(captured)再执行多次,而是将整个应用程序重新运行多次(每一次程序执行对应一个pass),并在每次应用程序执行中,采集每一个range的metrics数据。这样做的好处是:不需要跟踪和捕获每个range的应用程序状态(比如:不需要对memory进行保存和恢复),因为range的正确执行由应用程序本身处理。range的定义跟Range Replay一样,并且需要用户保证range工作负载执行的确定性。
适用场景
Application Range Replay 可以解决Range Replay不能解决的Range Replay,只需保证仅有一个进程定义range。
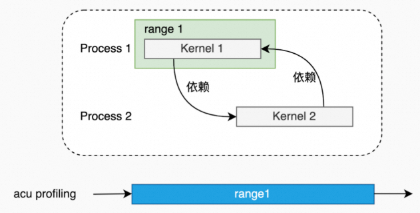
例子:pccl-tests(2个进程,每1个进程1个线程,每1个线程1个rank,只在1个rank上定义了range)。
acu --section Icnlink --replay-mode app-range --target-processes all mpirun -np 2 --allow-run-as-root ./build/all_gather_perf -g 1 -t 1 -n 1 -w 0 -b 512M -e 512M -c 0 -q 1 -s 1 -j 0不适用场景
应用程序包含多个进程,每个进程都定义range,如果这些range中的kernel存在依赖,那么,会发生hang.
另外,这些range在每次replay时,如果执行顺序无法保证,多次replay得到的这些性能数据可能无法按range进行匹配,从而,导致无报告生成。
多进程(2个range,其中一个进程的range依赖另一个进程的range)。
多进程(2个range,不相互依赖,但是2个range的执行顺序无法保证)。
多线程(2个range,不相互依赖,但是2个range的执行顺序无法保证)。
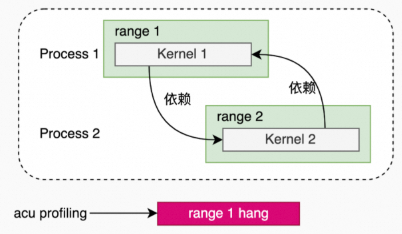
1.3.5 Graph Profiling
Graph Profiling功能是把HGGC graph作为单个工作负载实体进行性能分析,而不是对graph中的每个kernel node进行性能分析。
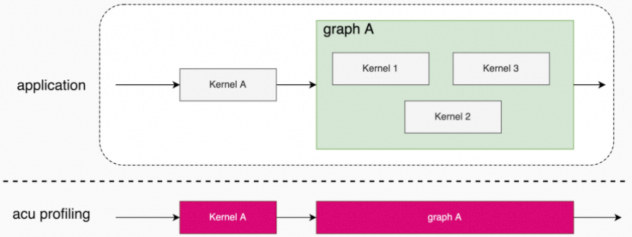
该功能可以通过选项--graph-profiling graph打开。
此模式的主要使用场景包括:
graph中包含了必须并发执行的kernel node。
需要更准确地分析包含多个kernel node的graph的性能。
启用Graph Profiling时,需要注意的是:
必须在
--replay-mode kernel下才能使用,而且默认情况下此功能关闭。某些性能指标,比如指令统计相关的指标,将不可用。
2. 控制采集过程
2.1 指定采集设备
通过--devices可指定使能采集的PPU设备列表
设备由序号(PPU设备上电后从0开始的索引)指定
多个PPU设备通过逗号","分隔
若不指定,默认允许在所有PPU设备上采集数据。
举例:抓取PPU设备1和2上运行的性能数据:
acu --devices 1,2 python test_linear.py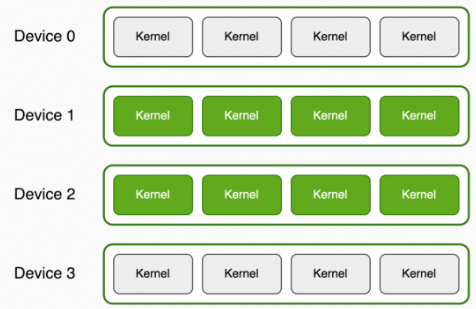
注意:range replay模式下,--devices只允许指定1个PPU设备。
2.2 指定采集时间范围
通过--profile-from-start选项可指定metric采集是否从应用程序启动开始,对于Application Replay/Kernel Replay模式生效。支持的选项说明如下:
profile-from-start可选值 | 策略描述 |
on或者yes (默认值) | 从应用启动开始采集性能数据 |
off或者no | 从profiler start API开始采集性能数据,直到profiler stop API停止性能数据采集。profiler start/stop API参见下文描述。 |
acu支持的profiler start/stop API组合如下:
cudaProfilerStart/Stop
hggcProfilerStart/Stop
cuProfilerStart/Stop
hgProfilerStart/Stop
举例:指定采集从profiler start API开始,到profiler stop API截止,命令如下:
acu --profile-from-start off python test_linear.py如果应用程序中cu(da)ProfilerStart()和cu(da)ProfilerStop()定义的采集的范围如下图所示,那么,第一个range(3个kernel)和第2个range(1个kernel)的性能数据将被采集:
disable-profiler-start-stop
通过--disable-profiler-start-stop选项,可指定忽略profiler start/stop API。
如果指定了
--disable-profiler-start-stop选项,--profile-from-start选项会被忽略,性能数据的采集会从应用程序启动时开始。
2.3 过滤Kernel
acu支持多种过滤方式来确定是否对程序中kernel进行性能数据的采集。
这些kernel级别的过滤方式仅对Application Replay/Kernel Replay模式生效。
2.3.1 指定kernel名称基准
可以通过--kernel-name-base指定包含--kernel-name选项或者--kernel-id选项中的kernel name基准。它支持的可选项包括 function、mangled、demanged默认值是function。
function不带参数和模板的function名称,例如 foo。demangleddemangled function名称,包括参数和模板,例如foo(float*,int,int)。mangledmangled function名称,编译器生成的mangled kernel名称,例如 _S4_S4_9TileShapeS4_S4_iSC。
举例:指定kernel的function名称作为过滤基准,采集所有function名称包含foo的kernel的性能数据,命令如下:
acu --kernel-name-base function --kernel-name regex:foo -o cuda_test ./cuda_test 12.3.2 指定kernel名称
可以通过--kernel-name设置要匹配的kernel名称的表达式,kernel名称要匹配的基准取决于--kernel-name-base的值,具体请查看--kernel-name-base相关描述。--kernel-name支持如下方式指定:
通过kernel名称指定:采集名称与指定名称完全匹配的kernel。
通过正则表达式指定:语法为regex:<expression>,采集名称与正则表达式匹配的所有kernel。
由于正则表达式语法可能会被linux shell处理,使用正则表达式指定kernel-name时,建议用""包裹参数,例如:--kernel-name="regex:^.*foo$"
举例:匹配所有名为Bar的kernel。
acu --kernel-name Bar ./cuda_test 1
举例:匹配所有包含字符串"Bar"的kernel,例如Bar和FooBar。
acu --kernel-name "regex:Bar" ./cuda_test 1
举例:匹配所有包括字符串"foo"或"bar"的kernel,例如foo、foobar、_bar2。
acu --kernel-name "regex:foo|bar" ./cuda_test 12.3.3 指定kernel ID
可以通过--kernel-id指定kernel id表达式。只有kernel的id与指定的表达式匹配,此kernel的性能数据才会被采集。kernel-id表达式的语法格式为context-id:stream-id:[name-operator:]kernel-name:invocation-nr,字段间通过冒号:分隔,字段若不提供可填为空,表示对此字段不加过滤,5个字段含义描述如下:
context id:指定kernel的 context ID。
stream id: 指定kernel的stream ID。
name-operator: 用于修饰下个字段kernel-name的描述符,可选(缺剩时不需要携带
:)当前仅支持填写为regex,表示kernel-name为正则表达式格式。
kernel-name: kernel名称的表达式,kernel名称要匹配的基准取决于
--kernel-name-base的值,具体请查看--kernel-name-base相关描述当name-operator为regex:采集名称与正则表达式匹配的所有kernel。
当name-operator为空:采集名称与指定名称完全匹配的kernel。
invocation-nr:指定此kernel的第几次调用
指定多次调用可以通过正则表达式定义。
调用次数+1的条件是,上述的context-id / stream-id / kernel name等条件均匹配。
由于正则表达式语法可能会被linux shell处理,使用正则表达式指定kernel-id时,建议用""包裹参数,例如:--kernel-id="::regex:^.*foo$"
举例:不指定context / stream id,匹配kernel名称为Foo的第2次调用
acu --kernel-id ::Foo:2 ./cuda_test
举例:匹配所有kernel的第3次调用,以及调用次数以5结尾的调用
acu --kernel-id "::::.*5|3" ./cuda_test举例:匹配所有以“foo”结尾的kernel
acu --kernel-id "::regex:^.*foo$" ./cuda_test举例:匹配所有不以“foo”开头的kernel
acu --kernel-id "::regex:^(?!foo)" ./cuda_test举例:匹配所有在conxtex 1, stream 3上的kernel的第5次调用
acu --kernel-id 1:3::5 ./cuda_test2.3.4 指定采集kernel的个数
可以通过--launch-count指定需要profile的kernel个数的上限,并且只有满足--kernel-name和--kernel-id中的过滤条件的kernel才会被统计计数。
Range Replay也支持该参数,只是统计的是range的个数
举例:只采集2个kernel的性能数据,后续kernel的性能数据不会被采集
acu --launch-count 2 ./cuda_test
2.3.5 指定跳过kernel的个数
可以通过--launch-skip设置profile之前忽略掉的kernel个数,并且只有满足--kernel-name和--kernel-id中的过滤条件的kernel才会被统计计数。
Range Replay也支持该参数,只是统计的是range的个数举例:先跳过1个kernel,然后采集后续所有kernel的性能数据
acu --launch-skip 1 ./cuda_test
举例:先跳过1个kernel,然后采集2个kernel的性能数据,剩下kernel的性能数据不会被采集
acu --launch-skip 1 --launch-count 2 ./cuda_test
2.3.6 指定匹配前跳过kernel的个数
可以通过--launch-skip-before-match设置profile之前忽略掉的kernel个数,不管是否满足过滤条件,所有kernel都会被统计计数。
举例:无条件跳过2个kernel后,然后采集所有kernel名称包含Foo的kernel
acu --launch-skip-before-match 2 --kernel-name regex:Foo ./cuda_test
举例:不论kernel名称是否匹配,先跳过2个kernel(黑色),在所有匹配(kernel名字包含Foo)的kernel中,先跳过2个kernel(红色),然后采集2个kernel(绿色)的性能数据,剩下kernel的性能数据不会被采集
acu --launch-skip-before-match 2 --launch-skip 2 --launch-count 2 --kernel-name regex:Foo ./cuda_test
2.3.7 指定采集个数达到后,是否退出程序
通过指定--kill选项,决定是否在launch-count达到后,退出程序。默认为yes
举例:采集2个kernel的性能数据,然后退出程序。
acu --launch-count 2 --kill yes ./cuda_test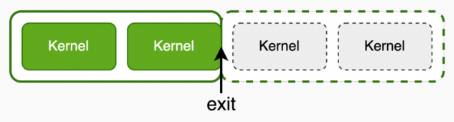
举例:采集2个kernel的性能数据,程序继续执行直至结束,后续kernel的性能数据不再采集
acu --launch-count 2 --kill no ./cuda_test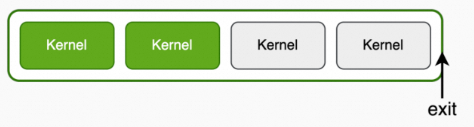
2.4 指定报告名
默认情况下,只支持输出.acurep格式文件,用于前端GUI展示分析。使用-o指定报告名字,不需要指定后缀,acu会自动添加.acurep后缀。如果未指定-o,则会默认使用 --page=details 输出到屏幕。
2.5 以 page/csv格式输出到屏幕
除了将结果存储在报告文件中,acu 还支持使用不同的页面(page)格式打印结果到屏幕。这些页面对应于用户界面报告中的相应page。如果没有显式的指定输出文件,默认情况下会打印details格式的页面。要选择不同的页面,或者在结果存储到指定文件的同时打印到屏幕,请使用--page=<Page>命令。目前,acu支持以下页面:details, raw。如果没有指定--page选项,但是设置了 -o指定了输出文件,则不会有结果打印到控制台。除了page格式,acu还支持csv格式的输出。使用 --csv 可以将屏幕输出格式装换为csv 格式。
2.6 导入报告文件
用 --import 选项,可以导入现有报告,并且把内容输出到控制台。可以搭配 --page <page>选项使用。
2.7 HGTX过滤
--hgtx-include <configuration> --hgtx-exclude <configuration>
使用这些命令选项可以只对满足配置条件的kernel进行采样。通过这些选项,用户可以选择指定范围内的kernel。
使用HGTX过滤功能必须指定--hgtx选项,同时用户可以一次或多次指定--hgtx-include和--hgtx-exclude选项。
HGTX范围配置有两种类型:HgtxRangeStart/End and HgtxRangePush/Pop,两种类型的配置语法介绍如下。
Start-End Ranges
Quantifier
Description
Example
,
Delimiter between range names
Range A,Range B
Range B,Range A,Range C
@
Specify domain name. If not mentioned, assuming <default domain>
Domain A@Range A
Domain B@Range B,Range Z
acu --hgtx --hgtx-include "Domain A@Range A" hgtx_filtering_test在Domain A@Range A范围内的kernel会被采样。
acu --hgtx --hgtx-include "Range A,Range B" hgtx_filtering_test同时在Range A和Range B范围内的kernel会被采样。
acu --hgtx --hgtx-include "Range A" --hgtx-include "Range B" hgtx_filtering_test在Range A或者在Range B范围内的kernel会被采样。
acu --hgtx --hgtx-exclude "Range A" hgtx_filtering_test除了Range A范围内的kernel都会被采样。
acu --hgtx --hgtx-include "Range B"--hgtx-exclude "Range A" hgtx_filtering_test在Range B范围内,但不在Range A范围内的kernel会被采样。
Push-Pop Ranges
Quantifier
Description
Example
/
Delimiter between range names
Range A/Range B
Range A/*/Range B
Range A/
[
Range is at the bottom of the stack
[Range A
[Range A/+/Range Z
]
Range is at the top of the stack
Range Z]
Range C/*/Range Z]
+
Only one range between the two other ranges
Range B/+/Range D
*
Zero or more range(s) between the two other ranges
Range B/*/Range Z
@
Specify domain name. If not mentioned, assuming <default domain>
Domain A@Range A
Domain B@Range A/*/Range Z]
acu --hgtx --hgtx-include "Domain A@Range A/" hgtx_filtering_test在Domain A@Range A范围内的kernel会被采样。
acu --hgtx --hgtx-include "[Range A" hgtx_filtering_test在Range A范围内,同时Range A为栈底的kernel会被采样。
acu --hgtx --hgtx-include "Range A/*/Range B" hgtx_filtering_test同时在Range A和Range B范围内,并且Range A和Range B之间有0个或多个Range的kernel会被采样。
acu --hgtx --hgtx-exclude "Range A/*/Range B" hgtx_filtering_test除了同时在Range A和Range B范围内,并且Range A和Range B之间有0个或多个Range的kernel会被采样。
acu --hgtx --hgtx-include "Range A/" --hgtx-exclude "Range B]" hgtx_filtering_test在Range A范围内,但不在以Range B为栈顶范围内的kernel会被采样。
其他配置
--hgtx-include DomainA@RangeA,DomainB@RangeB// 无效的配置单个HGTX配置,多个Range只需要指定一个Domain。不支持同一个HGTX配置里有不同的Domain。
--hgtx-include "Range A\[i\]"名字中的限定符'@' ',' '[' ']' '/' '*' '+' 可以被'\'转义。'Range A\[i\]'是指名字为'Range A[i]'的范围。
--hgtx-include "Range A"// Start/End 配置--hgtx-inlcude "Range A/"// Push/Pop 配置--hgtx-inlcude "Range A]"// Push/Pop 配置如果名字里包含'\',需要使用'\\\\',同时在限定符前不要使用'\\\\'。
包含或排除单个Push/Pop配置内,在结尾处使用'/',不要使用'['或']'。
--hgtx-include "Range A/*/RangeB"Push/Pop配置中的顺序很重要,示例中Range A在Range B的下面
2.8 acu支持使用多实例运行
acu 支持以多实例的方式启动,可以在同一个terminal session/(docker container)内启动多个acu来做采集,每个acu独立输出不同的报告,此方式可以有限使用mpirun命令。由于acu的采集只能工作在一个PPU设备上, 当有多个acu实例在运行时,需要用户保证每个acu实例中的目标应用程序独占一张PPU设备。如果acu在采集时,发现当前的采集设备有其它应用也在使用,会有如下的日志信息输出:
The application running on the device[0], may affect the metrics results of profiling.
Running application list: xxxxxxxxxx 如果出现以上错误信息,当前acu的采集会继续,但采集到的数据可能是错误的,有可能包含了其它应用中运行的kernel数据。
使用mpirun命令来做acu采集有两种方式,分别为:
mpirun放到acu后面,作为目标应用来启动,命令格式如下:
acu -o your_report mpirun -np 8 <your_target_application>此方式只有一个acu实例被启动,但是mpirun可能会fork出多个应用进程,在此方式下,所有fork出的进程中的kernel数据都会被采集,且合并输出到一个报告文件中。
mpirun放到acu前面,acu作为mpirun的启动程序来启动,命令格式如下:
mpirun -np 8 acu -o mpi_repot_%p <your_target_application>此方式下,会有8个acu实例被启动,每一个acu实例会启动一个<your_target_application>进程做profiling。最后输出8份报告
此命令组合方式仅适用于kernel replay与range replay两个模式下, 目标应用中不能有pccl API.
以上命令中,acu有个关键参数:
-o: 此处使用通配符 %p,%p代表使用<your_target_application> 的 pid来替换,以保证每个acu实例输出的报告名不重复,以避免重名报告造成的互相覆盖。 更多的通配符可以查看 acu --help 中的 -o,--export 一项的说明
2.9 Cache Control
cache-control可选值 | 策略描述 |
none | 默认值。在profiling过程中不刷新任何PPU缓存。 如果仅仅是单个kernel replay来收集metrics时,该模式下可以提高性能并可以更好地重现应用程序行为和metrics结果。但是,某些metrics结果将取决于之前的PPU工作以及多次replay之间的差异,这样的话可能导致metrics值的波动。 |
all | 在profiling过程中,在每次kernel replay之前刷新所有PPU缓存。 在这种没有无效的缓存的情况下,虽然应用程序的执行环境中的metrics值可能略有不同,但可以在replay过程中以及在目标应用程序的多次profiling运行之间稳定重现metrics结果。 |
在Kernel Replay时,可能需要多次replay kernel以便收集所有请求的metrics。虽然 Asight Compute 的checkpoint可以保存和恢复由kernel访问的PPU设备的内存数据,但是无法做保存和恢复 L1、L2以及LLC缓存数据。因为缓存可能已经被kernel最近一次访问的数据给填充了。同样,第一次replay收集的硬件perf counter值可能取决于在profiling kernel launch之前执行了哪些kernel,这些因素都可能导致后续replay过程的性能比第一次replay时更好或更差。
为了使硬件perf counter值采集时更加稳定准确,Asight Compute 提供了--cache-control all参数,让用户可以在每次replay kernel之前刷新所有PPU缓存。因此,在每次replay中,kernel将可以访问一个干净的缓存,行为就好像kernel是在完全隔离的状态下执行的一样。
但这种模式下的行为也存在副作用,特别是在profiling较大应用程序执行中的某一个kernel,且收集的数据针对缓存为重点的metrics,可能会不利于性能分析。这种情况下,用户就需要考虑使用--cache-control none来关闭工具对任何硬件缓存的刷新。
同样,在Application Replay中,由于kernel访问的内存无需通过checkpoint进行保存和恢复,所以每次kernel launch只会在应用程序进程的生命周期中执行一次。所以Application Replay也是可以通过--cache-control none来关闭工具对任何硬件缓存的刷新。除非说应用程序需要在特定kernel launch之前,达到干净缓存的状态,那我们也可以通过设置cache control来实现。
当设置--cache-control all后,并不代表着cache刷新的行为会被perf counter统计出来,如下图,memory D2H的行为并不会体现在memory chart中llc到dram的write bytes数据结果上。
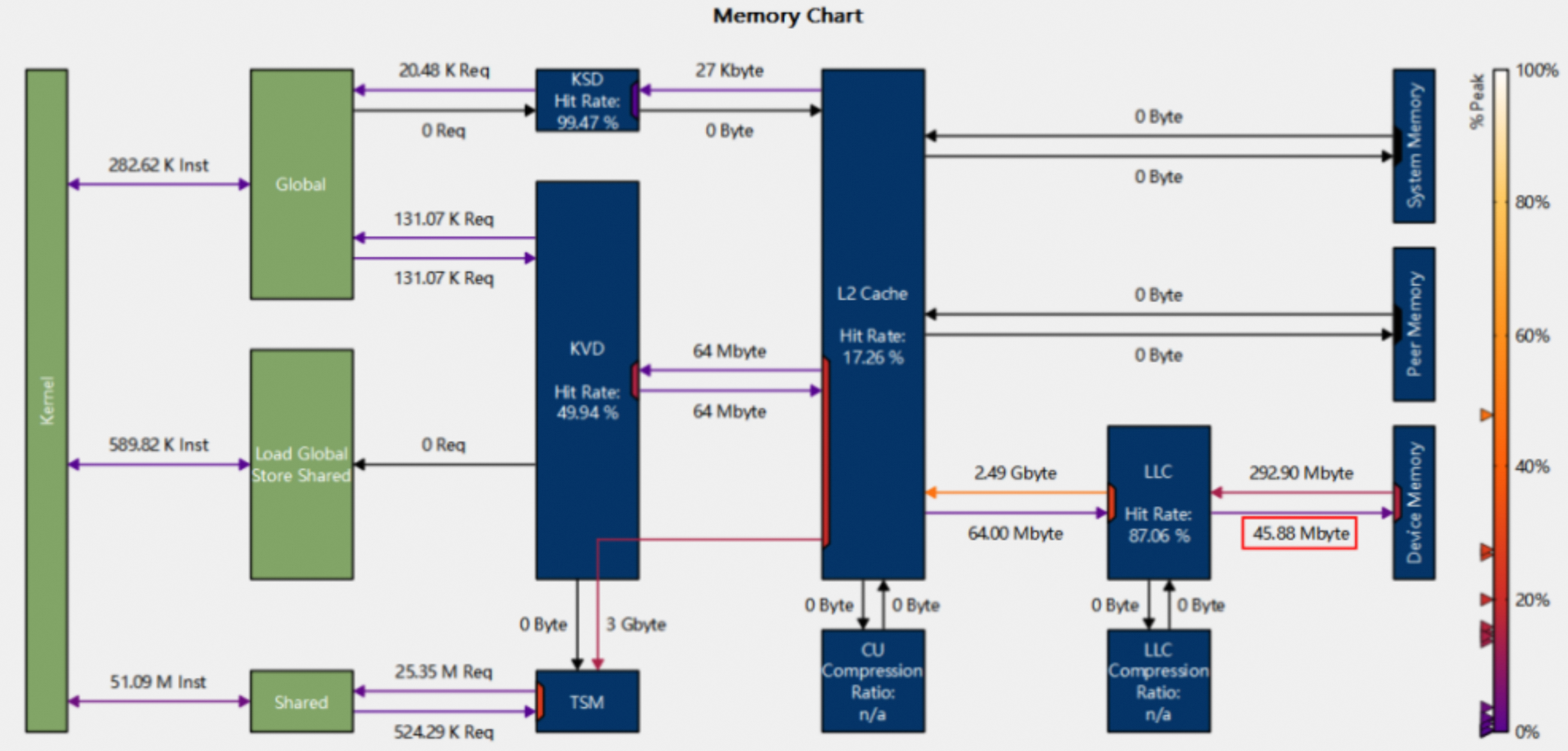
如果想了解llc到dram实际写入多少数据。我们可以通过修改应用程序代码,扩大profiling range的范围,通过在kernel launch前增加cudaProfilerStart,kernel launch之后memory D2H调用后面增加cudaProfilerStop。这样当前profiling range就会包含实际memory D2H的行为了,然后使用--replay-mode range,通过Range Replay即可收集到相关metrics数据了。
2.10 Clock Control
此功能用于控制性能分析过程中PPU时钟的行为。
对于许多metrics来说,它们的值直接受到当前PPU CU和内存时钟频率的影响。比如下面场景,
如果分析的Kernel在应用程序中有其他Kernel在它之前执行,则 PPU可能已经处于较高的时钟频率,导致kernel的执行时间和其他一些metrics将会受到影响。
如果Kernel是应用程序中启动的第一个Kernel,PPU时钟频率通常会较低。
由于acu会进行kernel replay,metrics的值可能会受采集它的pass的影响,因为后面的pass将导致更高的时钟频率。
为了减轻这种不确定性,acu尝试将PPU时钟频率限制为其基本值(通过--clock-control base)。这样,metrics的值受Kernel在应用程序中的位置,以及所在pass的影响就会小很多。
然而,在某些场景下,用户可能不需要将时钟频率固定到基本值。比如,用户已经使用外部工具(ppu-msi等)固定了时钟频率。为了解决这个问题,用户可以通过设置--clock-control none选项来指定acu不固定任何时钟频率。
clock-control可选值 | 描述 |
base | 在性能分析期间,CU 和内存时钟被锁定到各自的基本频率。 当前CU的base clock为900MHz。 |
none | 默认值 在性能分析期间,acu不会更改 CU 或内存频率。 |
reset | 重置所有或所选设备(通过--devices指定设备)的 CU 和内存时钟,然后退出。 如果由于acu意外退出导致 PPU 时钟处于锁定状态,请使用此选项。 |
热调节(hermal throttling)会导致PPU 时钟频率发生变化,该行为无法由acu控制
clock-control的行为需要sudo权限,否则会中断性能分析,并提示权限警告在采用
--clock-control base时,acu会在应用程序结束时,reset PPU clocks,并不会回退到开始性能分析前的clocks(比如通过ppu-smi设定的clocks)
3. PC Sampling
PC Sampling功能支持对warp调度器的状态进行周期性采样。在固定的周期间隔内,每个采样器会选择一个active warp,并输出指令的PC地址和对应的warp调度状态。acu默认开启PC Sampling功能。所以,通过GUI工具打开report,就可以查看采样数据。
3.1 GUI展示
PC Sampling的采样数据会分别在Details Page和Source Page展示。
3.1.1 Details Page
在Details Page的Source Counterssection中,Wrap Stall Sampling表会展示5条计数最高的stall reason数据,包括:
源码位置
stall reason 计数
stall reason 占比
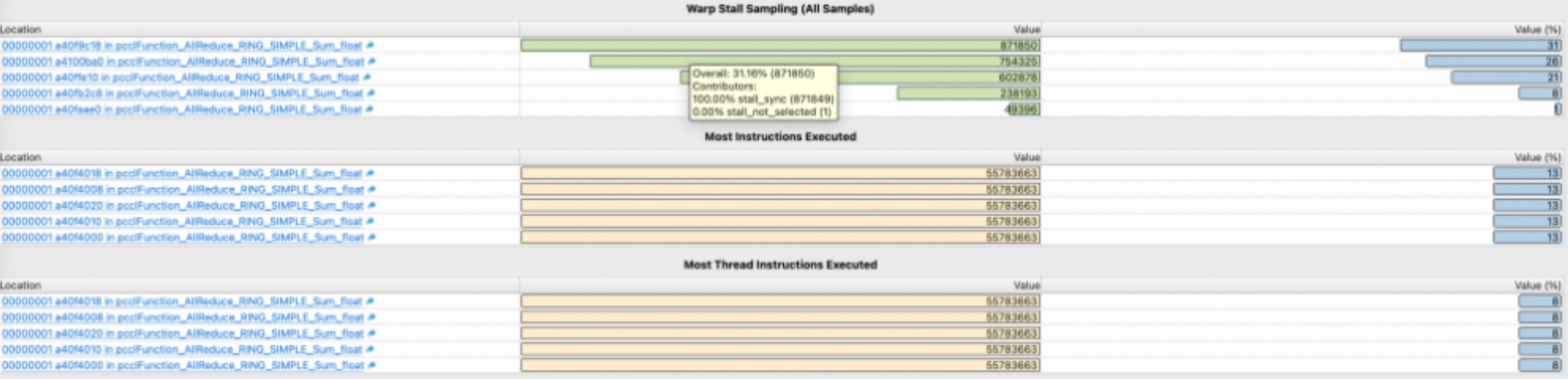
详细的stall reason,请参考warp stall reason介绍。
3.1.2 Source Page
在Source Page,会以柱状图的形式展示stall reason数据,Source View和PASM View都会逐行展示当前代码行(或指令)对应的所有stall reason的数值和总和数值。

3.2 指定采样周期间隔
采样周期间隔可以由用户指定。如果在采样过程中发现采样的数据很少,以致无法进行有效分析时,可以通过--sampling-interval设置更小的采样周期间隔。
最小的采样周期不低于128 cycles(2^7),而最大的不得高于65536 cycles(2^16),不满足要求的采样周期将不会设置成功。
--sampling-interval在[0..9]范围内取值。实际采样周期为 2 ^ (7 + 选取值)cycles。
如果设置为auto(默认),则会基于当前环境配置自动选择最高采样频率,以避免采样数据过少,或者缓冲区溢出情况的发生。
举例:设置采样周期间隔为256 cycles进行pc sampling 采样
acu --sampling-interval 1 -o cuda_test ./cuda_test举例:设置自动选择最高采样频率进行pc sampling
acu --sampling-interval auto -o cuda_test ./cuda_test4. 指令统计
指令统计功能可统计kernel function、device function等函数的指令执行信息。该功能默认开启。要关闭指令统计功能,需要在启动acu之前,设置环境变量:export ASIGHT_FEATURE_INSTRUCTION_COUNT=0。除了graph(也即--graph-profiling graph场景下),指令统计支持在所有replay模式下,对kernel或者range进行profiling。
Workload Type | Instruction Level Source |
Kernel | ✅ |
Range | ✅ |
Graph | ❌ |
acu增加一个单独的pass,用于收集指令执行信息以及解析function的汇编指令。指令统计功能会在采集过程中,收集每条指令执行的warp次数,以及每条指令执行的线程次数。指令统计信息会以不同的形式在GUI工具内展示
4.1 Source Page展示
GUI打开包含指令统计信息的报告,切换到Source Page,可以看到Source View和PASM View里都有Instructions Executed和Thread Instructions Executed两列数据。
Instructions Executed 统计每个独立warp中指令执行的次数,与每个warp内参与的线程数量无关。
Thread Instructions Executed: 统计指令被所有线程执行的次数。

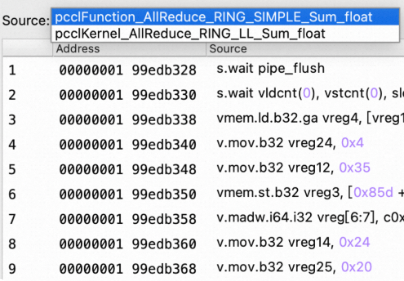
另外,有了指令统计功能,GUI还可以展示kernel function调用的device function的汇编指令信息和源码关联信息,详情请看source Page
4.2 Details Page展示
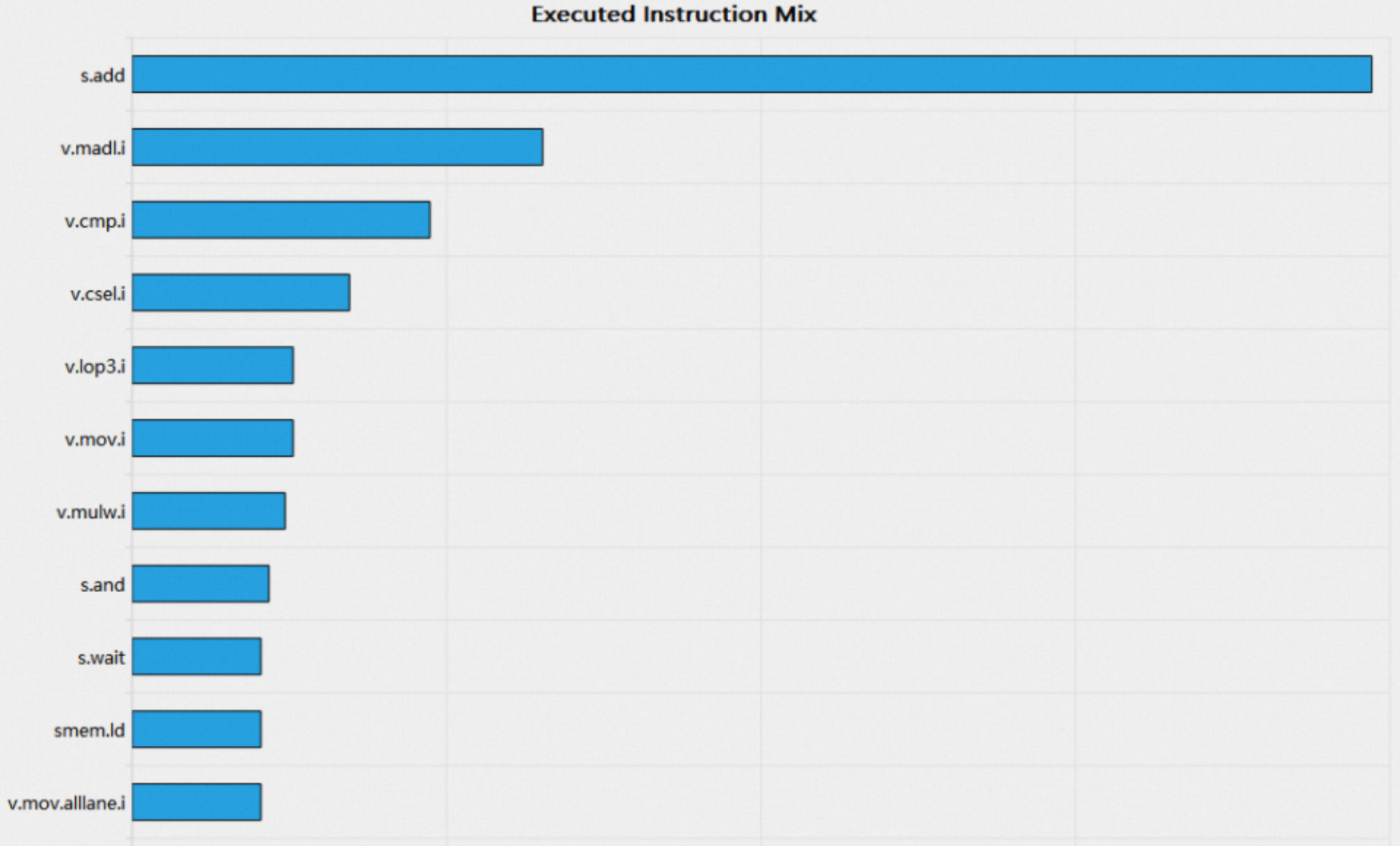
在Details页面的Instruction Statistics Section下,新增柱状图用于显示指令执行的分布,详情请查看Executed Instruction Mix Bar Chart:
在Details页面的Source Counters Section下新增了Most Instruction Executed与Most Thread Instruction Executed信息的展示,详情请查看Source Counter Secton:
