
在PPU上从源码构建PIP软件包
本文为您介绍如何在PPU上从源码构建软件包,及出现的常见问题。
从0到1打通开源库
1. 甄别特定版本软件包是否已经在PIP repo上提供
在PYPI中搜索库名,例如:lmdeploy。
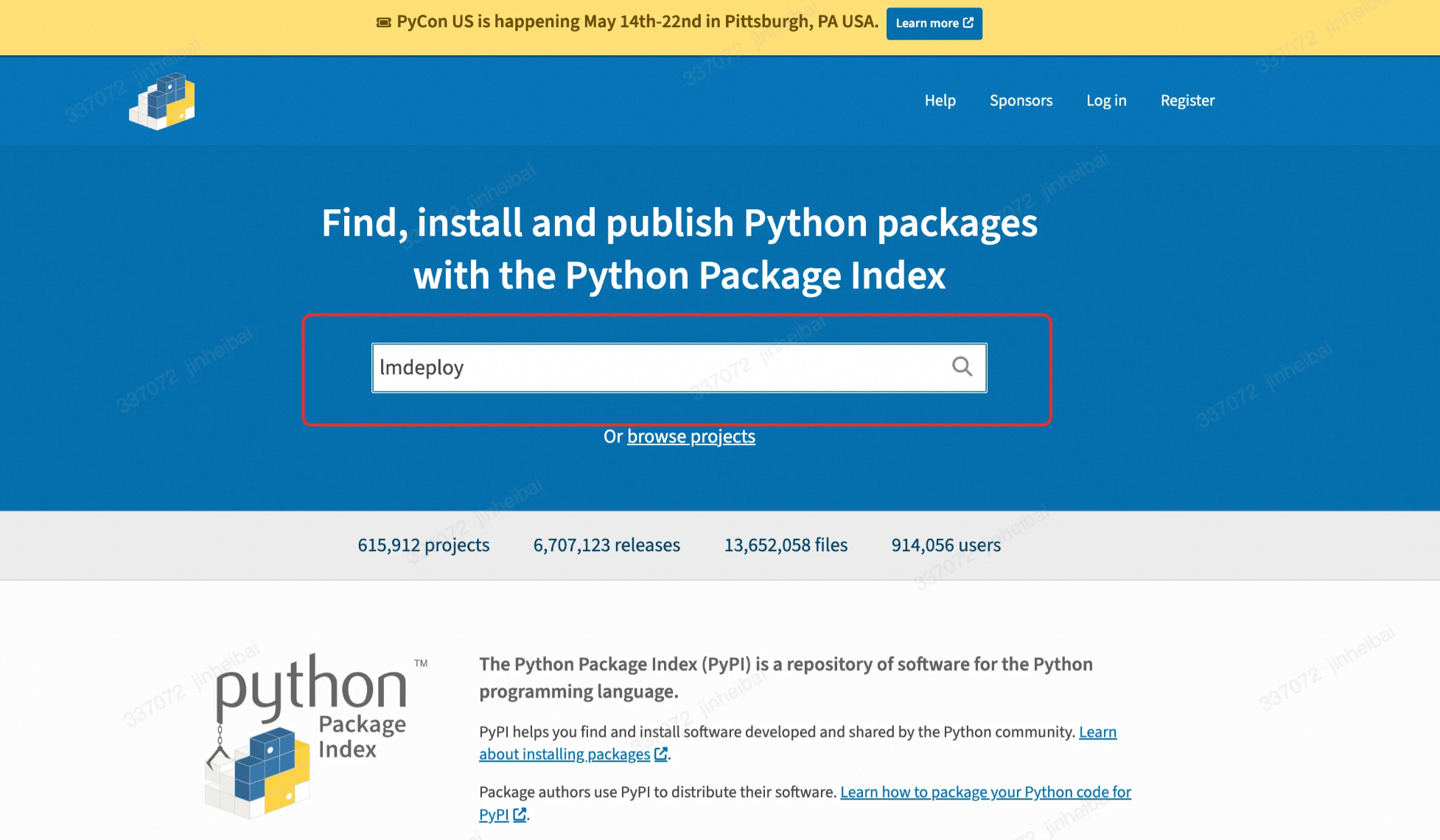
搜索结果中有24个lmdeploy关键词相关的库,找到和开源库Github对应的库。
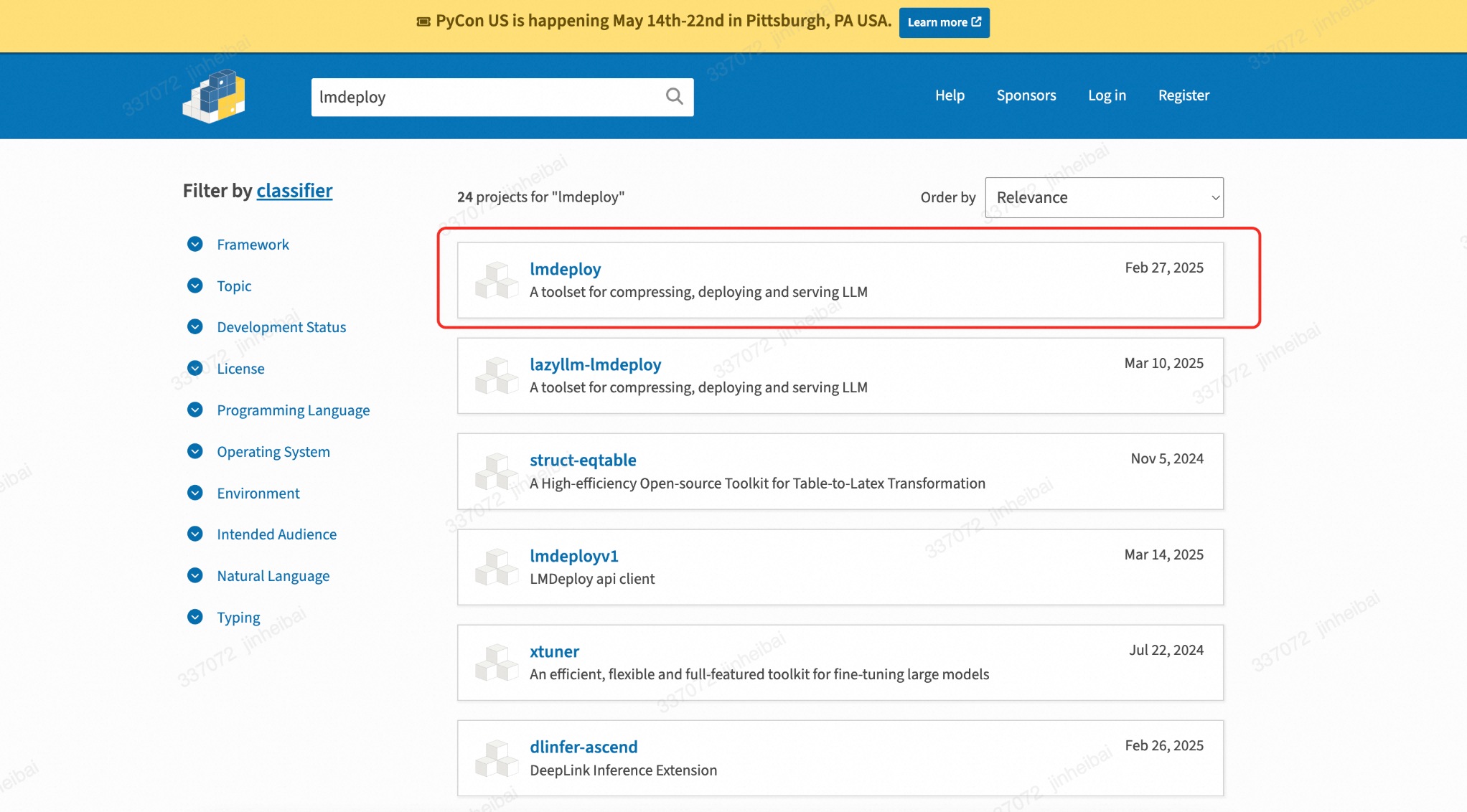
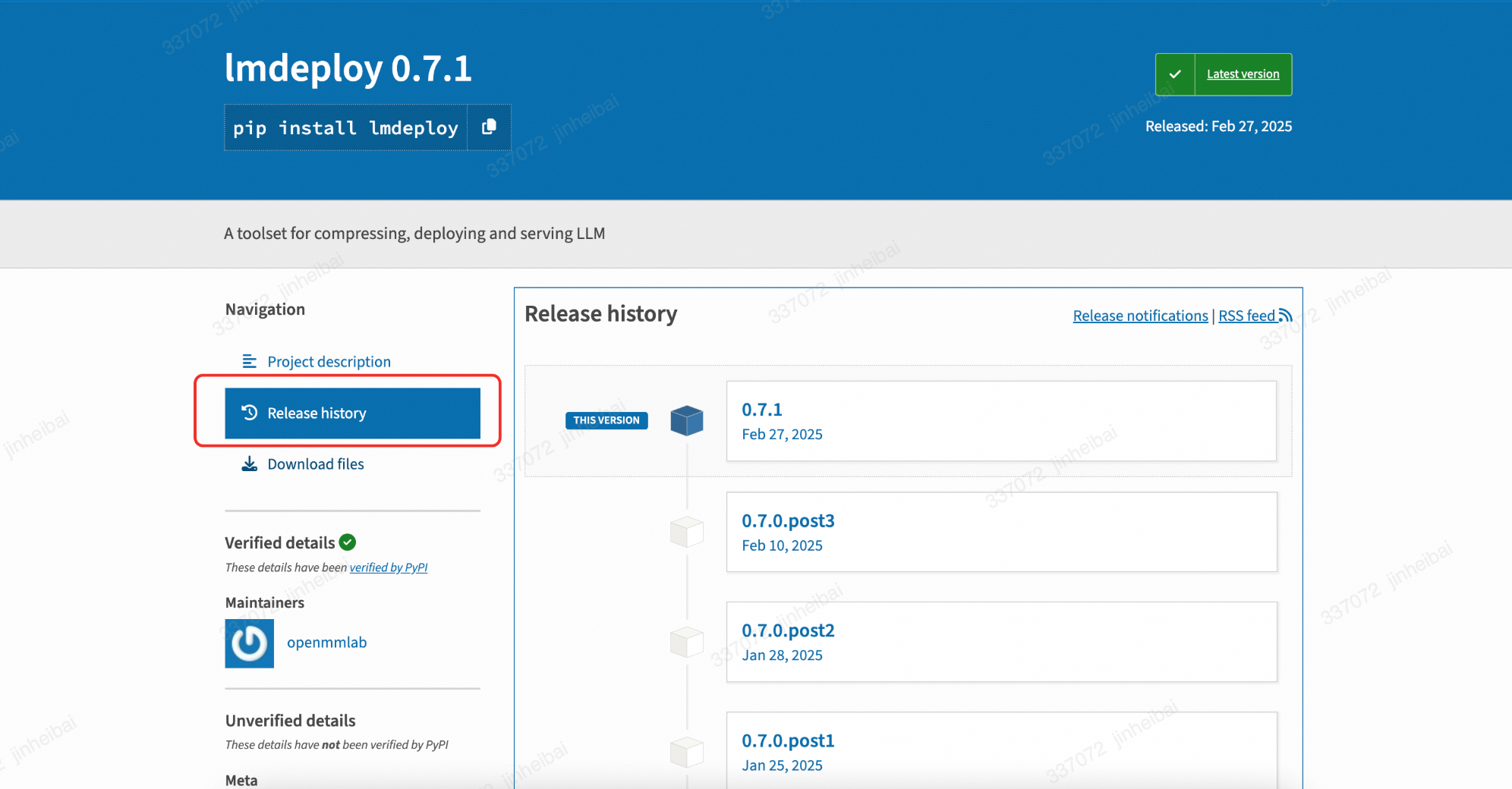
可以看到PYPI上lmdeploy已经支持到0.7.1版本。
2. 甄别库是否与Cuda相关
判断依据一:Readme包含关于当前开源库的简介,指出了当前库的功能,这可以作为最基本的判断条件。
判断依据二:GitHub中的Languages中是否包含Cuda。如果Cuda含量很高,基本上可以判定为是一个Cuda相关的开源库,需要纳入到PTG PIP源;如果Cuda含量仅2%,需要结合其他判定条件进行判断。
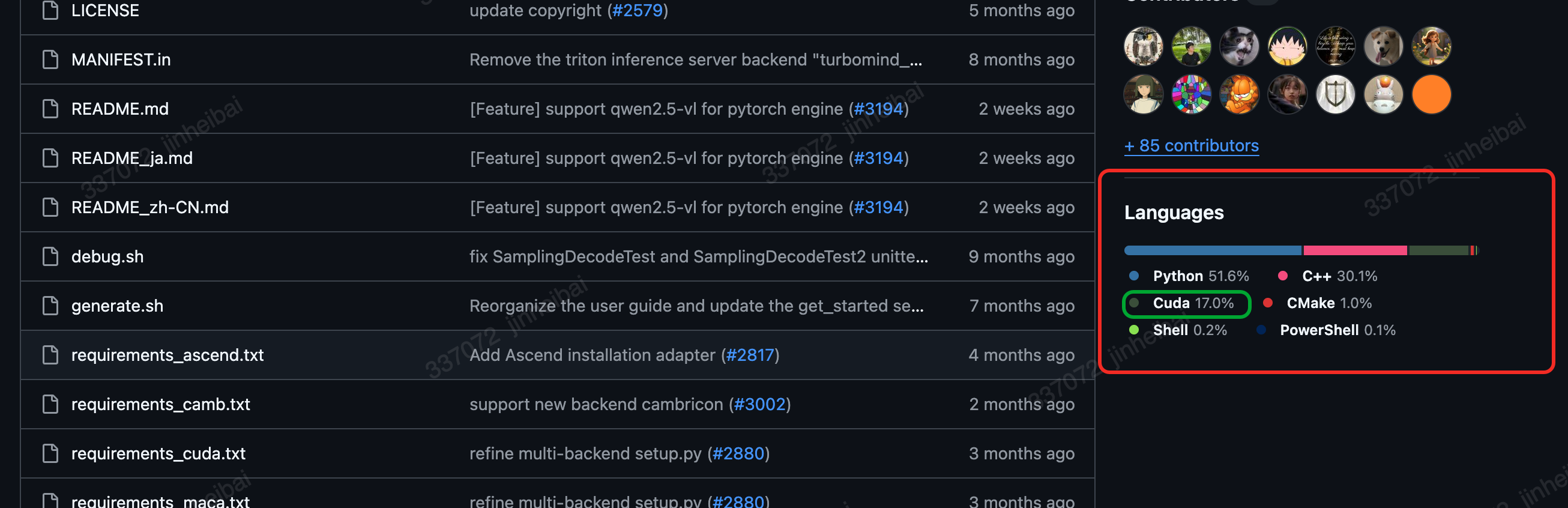
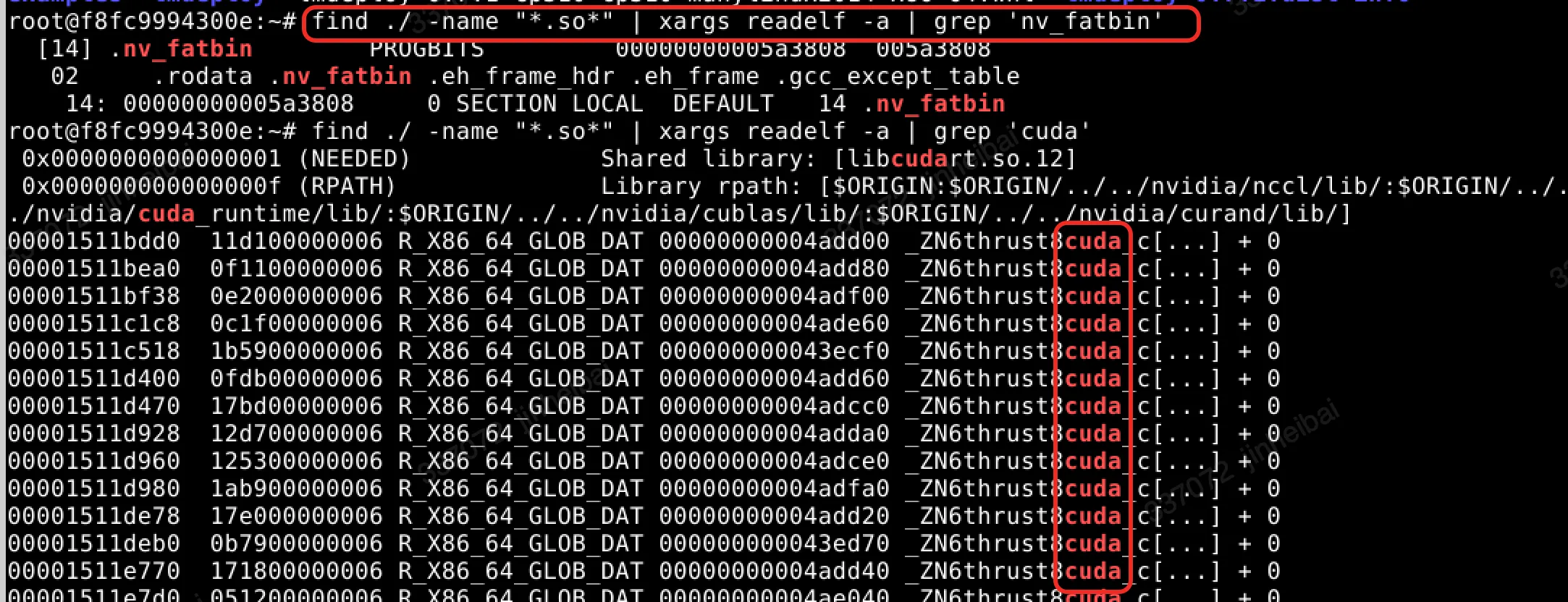
判断依据三:解压开源库对应的whl包,遍历全部文件是否包含.cu后缀。
wget https://files.pythonhosted.org/packages/b8/92/fa66b0684c0eace3a480498e70ad40a0f3784890a25b480ae05fb8d7a458/lmdeploy-0.7.1-cp310-cp310-manylinux2014_x86_64.whl unzip lmdeploy-0.7.1-cp310-cp310-manylinux2014_x86_64.whl find ./ -name "*.cu"判断依据四:解压开源库对应的whl包,遍历全部
.so文件,判断文件名是否包含如"cuda"、"nv_fatbin"等关键信息。find ./ -name "*.so*" | xargs readelf -a | grep 'nv_fatbin' find ./ -name "*.so*" | xargs readelf -a | grep 'cuda'
3. 开源库编译调通
3.1 编译依赖
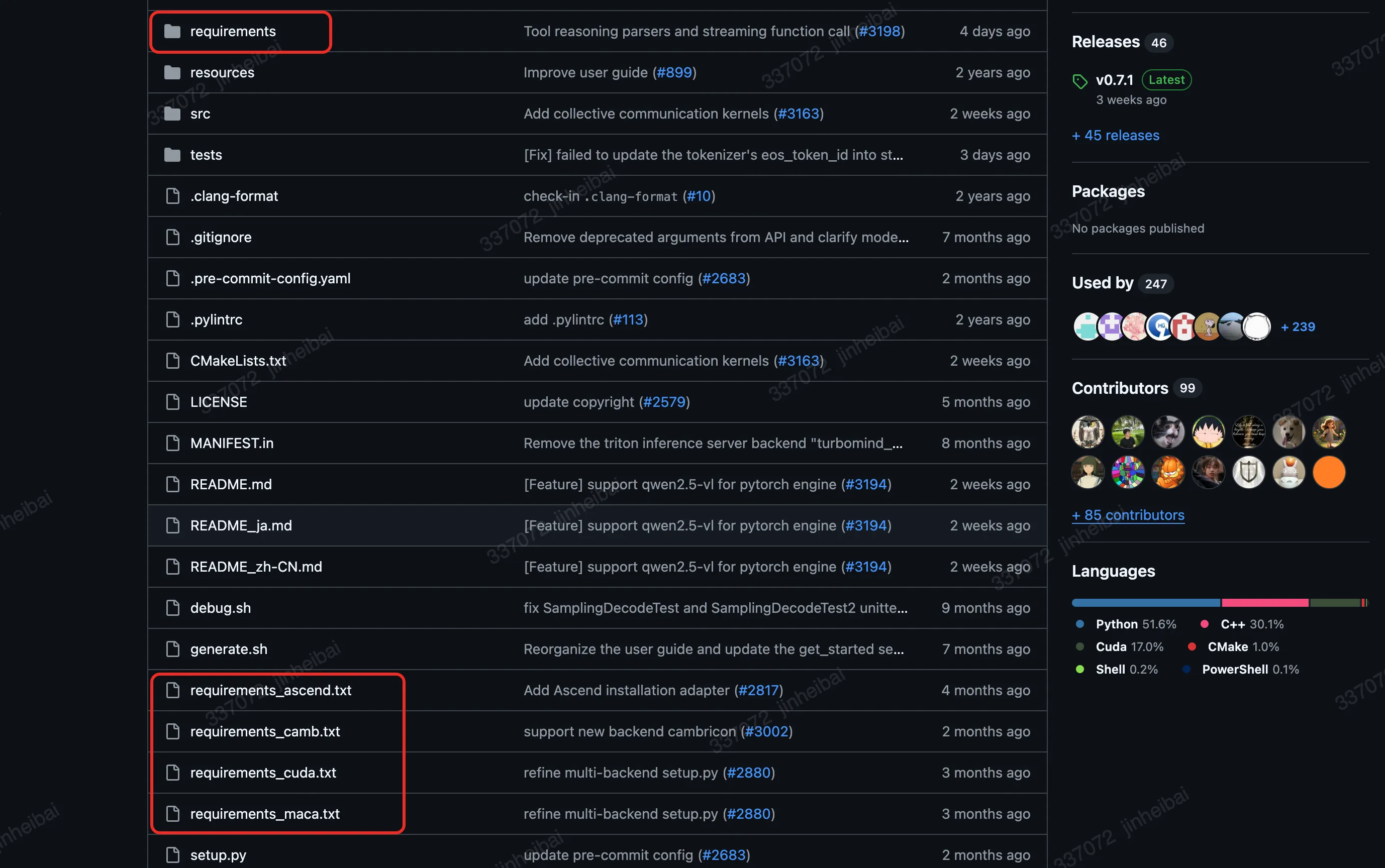
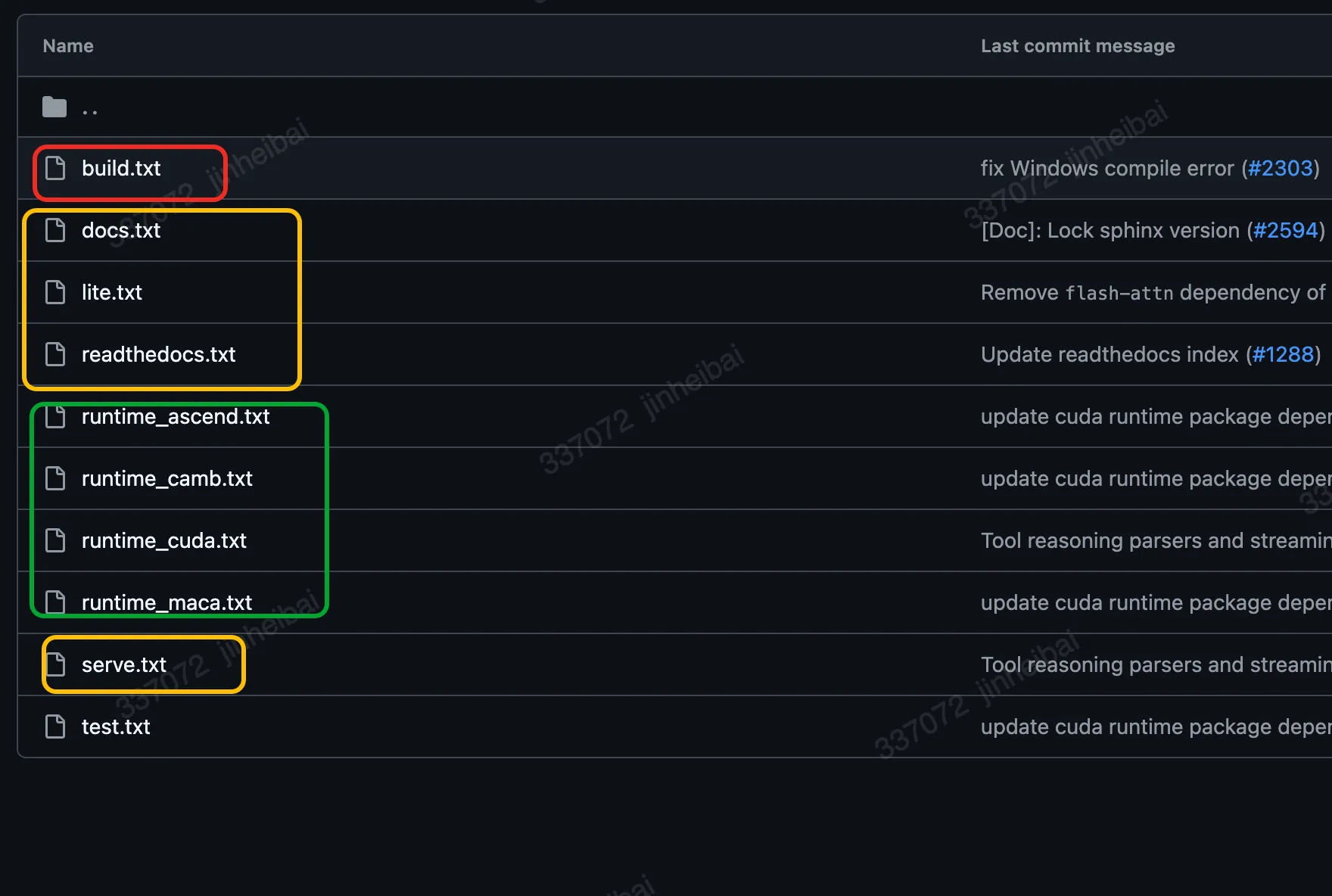
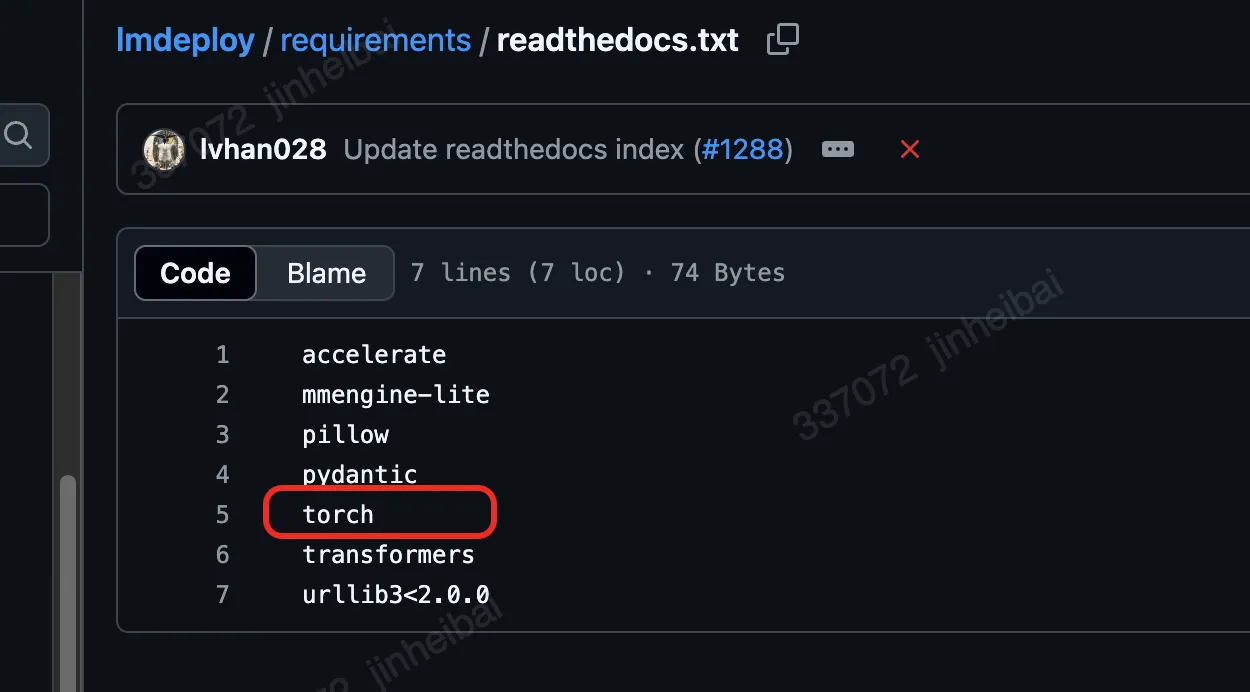
首先确认开源库的requirements,并安装编译所需要的依赖库。开源库的依赖信息通常在requirements相关的文件或目录中。以lmdeploy为例,requirements路径下的build.txt中的依赖库,是编译lmdeploy必须要用到的。readthedocs.txt、docs.txt、lite.txt、serve.txt也是需要重点关注的,编译过程中大概率会用到。带有runtime字样的相关依赖更多是测试阶段要用到的,编译也有可能会用到,这个因不同开源库而异。
依赖库安装可能是需要使用
apt-get,或pip install,还有可能是需要源码编译安装。建议借助Google或DeepSeek等工具进行搜索,以正确的方式安装依赖。注意:开源社区AI相关的开源库有很大一部分编译都依赖于PyTorch,需要重点关注开源库是否与PyTorch相关。lmdeploy的readthedocs.txt中就用到了PyTorch。
依赖库也要甄别是否为Cuda相关的库。如果是Cuda相关的库则需要先行打通该依赖库的编译,并加入到PTG PIP源。这里安装Cuda相关依赖有两种方法,一种是直接使用PTG PIP源中已经编译好的包,使用
pip install安装即可;另一种是在编译步骤中加入依赖库的编译,先编译并安装依赖库,再编译当前需要支持的开源库。requirements的信息也不会做到百分百准确,可能有一些依赖库在实际编译中是用不到的,有一些真正需要的依赖并没有包含在requirements中,在编译阶段报错才发现,这都是正常现象。
lmdeploy的依赖安装步骤如下,其中pybind11、rapidjson-dev在requirements信息里;rapidjson-dev和openmpi均为编译阶段报错,从错误中分析出是缺少依赖。
pip install torch==2.5.1+ppu1.4.2 #一定使用PTG PIP源上的pytorch,这里的1.4.2版本仅用作举例 pip install pybind11 apt update apt-get install rapidjson-dev #openmpi安装,按照官网文档是需要特定版本 wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.5.tar.gz tar xf openmpi-4.1.5.tar.gz cd openmpi-4.1.5 ./configure make -j make install cd ..
3.2 编译步骤
开源库的GitHub上已经提供了最简单的编译方法,如果是在NVIDIA的设备上,直接使用如下方法即可编译成功。
git clone -b v0.3.0 https://github.com/InternLM/lmdeploy.git cd ./lmdeploy python setup.py bdist_wheelsetup.py的方式会更简单,但是一旦编译报错,错误打印不够完整,很难暴露问题。这里更建议使用cmake编译,因为一个新的开源库放在PPU上打通,很大概率会报错,因此,应该尽可能收集问题、定位问题、解决问题。
git clone -b v0.3.0 https://github.com/InternLM/lmdeploy.git cd ./lmdeploy mkdir build && cd build cmake .. make -j cd ../ python setup.py bdist_wheel使用cmake编译lmdeploy的过程中暴露出来很多错误,我们通过Google + DeepSeek + 经验的方式,最终解决了这些错误,最终的编译脚本如下。
git clone -b v0.3.0 https://github.com/InternLM/lmdeploy.git cd ./lmdeploy #环境变量配置,为openmpi服务 export PATH=/usr/local/bin:$PATH export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH mkdir build && cd build cmake .. \ -DCMAKE_BUILD_TYPE=RelWithDebInfo \ -DCMAKE_EXPORT_COMPILE_COMMANDS=1 \ -DCMAKE_INSTALL_PREFIX=./install \ -DBUILD_PY_FFI=ON \ -DBUILD_MULTI_GPU=ON \ -DCMAKE_CUDA_FLAGS="-lineinfo" \ -DUSE_NVTX=ON \ -DNCCL_LIBRARIES=/usr/local/PPU_SDK/CUDA_SDK/lib64/libnccl.so make -j cd ../ python setup.py bdist_wheel
4. 开源库编译实战举例
一个使用.sh方式编译的开源库举例 | |
一个曲折的开源库打通历程 |
开源库单元测试常见问题汇总
1. import 错误
导致ImportError: cannot import name 'xxx'错误的原因主要包括:
名称不存在:尝试导入的函数、类或变量名在模块中未定义。
此问题一般通过
pip install对应的包可以解决。拼写或大小写,或者路径问题。
首先需要检查拼写问题,然后检查是否是该版本的对应文件有路径问题。python的import逻辑为:以
import aa.bb.cc为例,需要从python whl包的安装路径下,找到对应的包文件夹,依次确定aa路径、bb路径、cc文件都是否正确,部分开源包的某些版本天然存在这类问题。
2. cannot found xxx.so问题
遇到这类问题,首先需要检查echo $PYTHONPATH 的情况,确保当前路径和包安装路径下是否能找到对应的so,如果当前找不到,包安装路径找到了,通常是当前这个测试环境的某些依赖找到了源码的中对应python文件,这时候需要将tests文件夹从源码路径中移动到一个单独目录下(不建议改名,改名有时候会破坏一些依赖,同时强调一定要确保测试UT和编译代码同版本)。
3. triton不支持问题
triton不支持问题,表现形式比较多,以下是发现的一部分:
Cannot find a working triton installation。triton未安装
cannot compiled。 triton版本不匹配
cannot load xxx.ptx 。误安装了CUDA的triton包。
特别提醒,triton只能安装PTG内部编译的whl包,发现triton的版本没有ptgppusail等关键词的,有大概率是装错了triton包。
4. cublas、cusparse、cudnn等库支持报错
这三类的错误是算子库没有支持导致的,报错信息比较清晰,比如in function cublas_gemm: cuBLAS Error: an unsupported value or parameter was passed to the function。
5. 测试结果异常,立刻退出,无错误信息打印
这种情况需要本地调试一下,首先确认是否是随机性问题。目前的测试基本上都是用pytest来管理的,基本运行命令是pytest -v xxx.py::test_xxxa[abcdefg]这种格式,加-v选项是为了查看到底是哪一条失败了。以下为没有显示报错信息的检查步骤:
重新运行这一条测试命令,确保不是因为当时的环境问题,确保能复现。
如果能稳定复现的话,检查dmesg.log,查找当时运行时是否有exception信息或者ERROR信息报出。
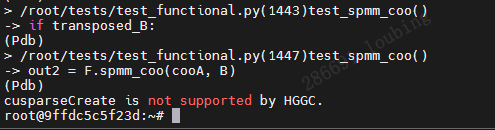
dmesg没有相关信息的话,使用命令
pytest -v xxx.py::test_xxxa[abcdefg] --trace来进行pdb的单步调试,能确保所有打印信息都能被采集到,有时候不单步调试看不到相关信息。上图是情况3下才能看到的错误,直接执行,这种打印信息是无法捕捉到的。实际上这一条的报错信息清晰地显示是cusparse不支持导致的,和上一条是同一个原因。
6. 精度问题&测试结果错误
这两类错误的信息比较相似,一般会有max、min、difference 等信息,给了两个数字的对比,类似
AssertionError: Outputs not close enough in tensor at idx=0. Location of the maximum difference: 2669 with 0.013854987919330597 vs 0.01314355805516243 (diff 0.0007114298641681671).具体是精度问题还是结果错误,最好给到开发确认。
7. Cmake版本不够
下载地址:https://cmake.org/files/dev/?C=M;O=D
bash cmake-3.28.4-linux-x86_64.sh --prefix=/usr/local --exclude-subdir