
FAQ & 已知问题
FAQ
1. 减少测试环境差异
使用acu进行性能分析时,为了多次采集之间的测试环境差异,可通过设置设备为独占模式,禁止其他程序在acu采样过程中运行。
# 设置设备为独占模式
ppu-smi -c EXCLUSIVE_PROCESS
# 恢复设备为默认模式
ppu-smi -c DEFAULT可通过锁定设备频率,减少设备调频对acu采样的影响:
# 锁定设备频率到1.5GHz
ppu-smi -lpc 1500
# 解除频率锁定
ppu-smi -rpc2. 目标应用已经结束,但acu没有收到目标应用退出消息而卡死
有些目标应用程序在启动后,会fork出很多的子进程。在目标程序主进程退出后,还有子进程一直存在不退出,acu此时就会一直等待子进程,看到的现象会误以为acu卡死。
确认此场景方法:
安装pstree工具。
在acu出现卡死现象后,在另一个终端中输入命令:
pstree <acu_pid>,确认是否有目标应用fork出的进程出现在了此命令的列表中。如果有就说明有fork出的子进程不退出。
规避方法:
在acu命令中使用--wait primary参数,让acu仅等待目标应用的主进程退出。
3. 报错:Device is not ready for profiling
这个报错大概率是PPU性能数据采集资源PCM被其他应用占用,导致acu无法采集。可能是其它asys或者acu应用正在采集,也可能是其它采集PPU运行指标的监控程序正在后台运行。
请运行
sudo lsfo /dev/alixpu和dmesg --level=err,crit,alert,emerg命令,查询哪个应用在占用PPU PCM请运行
ppu-smi,查询当前环境的Driver Version(KMD版本)如果KMD版本低于1.4.0,需要找手动停止步骤1 查询到的PCM占用程序,重新运行acu。
如果KMD版本大于或者等于1.4.0,可以用PPU-SMI 临时关闭其它应用的采集功能。请参考下面命令,更详细说明请参考设置性能监控输出状态。
#查询性能监控GPM stream状态,如果PCM被占用,acu无法采集时,期望返回ENABLED ppu-smi gpm -g #临时禁止GPM stream功能,让acu可正常采集 ppu-smi gpm -s DISABLED #查询性能监控采集状态,期望返回DISABLED ppu-smi gpm -g #此时acu应该可以正常使用 #acu采集完成后,恢复GPM steam状态 ppu-smi gpm -s ENABLED #查询性能监控采集状态,期望返回ENABLED ppu-smi gpm -g
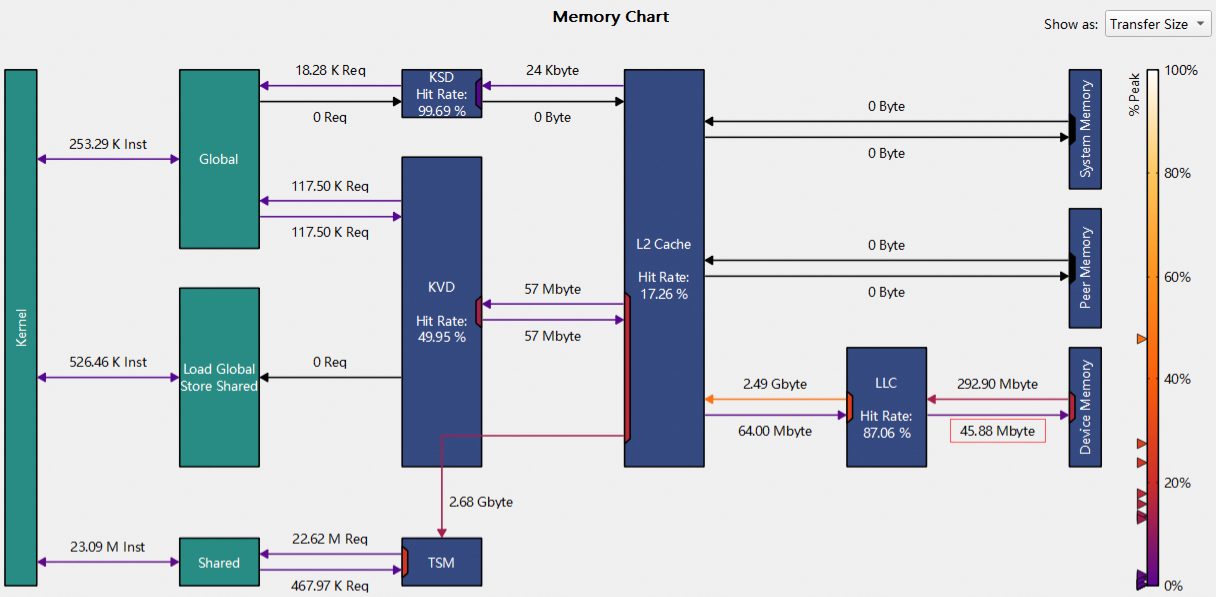
4. LLC向DRAM写入数据偏少
如下图,memory D2H的行为中 L2向LLC写入了64M数据,但LLC仅向DRAM写入了45.88M数据。
造成这种数据不匹配的情况,是因为驱动层在将数据写入LLC后,就认为已经到DRAM了,随即结束kernel的执行。kernel执行结束后,counter的采集也会停止。但LLC向DRAM写入数据不受外部的控制,时机不确定,所以LLC向DRAM写入数据的counter会少一部分记录。
已知问题
PPU SDK v1.2.0:acu采集包含订阅hgpti的应用程序时可能崩溃。
不支持采集使用hggcLaunchCooperativeKernelMultiDevice的应用程序。
当
acu -o选项指定报告输出位置的文件IO读写速率很低时,acu报告文件可能生成不完整。--profile-from-start不支持跨进程控制采集时间范围。应用程序编译需包含
-pthread选项,否则可能导致acu运行崩溃。若acu采集过程中被打断,已采集的跟踪信息可能无法正确展示。
Warp State Statistics中Avg. Active Threads Per Warp [inst]值会偏低。
Range Replay模式下,capture和replay memory相关API(详细列表如下)还不稳定,可能影响数据的准确性。
# HGGC runtime API hggcMemcpy2D, hggcMemcpy2DArrayToArray, hggcMemcpy2DArrayToArray_ptds, hggcMemcpy2DAsync, hggcMemcpy2DAsync_ptsz, hggcMemcpy2DFromArray, hggcMemcpy2DFromArrayAsync, hggcMemcpy2DFromArrayAsync_ptsz, hggcMemcpy2DFromArray_ptds, hggcMemcpy2DToArray, hggcMemcpy2DToArrayAsync, hggcMemcpy2DToArrayAsync_ptsz, hggcMemcpy2DToArray_ptds, hggcMemcpy2D_ptds, hggcMemcpy3D, hggcMemcpy3DAsync, hggcMemcpy3DAsync_ptsz, hggcMemcpy3DPeer, hggcMemcpy3DPeerAsync, hggcMemcpy3DPeerAsync_ptsz, hggcMemcpy3DPeer_ptds, hggcMemcpy3D_ptds, hggcMemcpyArrayToArray, hggcMemcpyArrayToArray_ptds, hggcMemcpyAsync, hggcMemcpyAsync_ptsz, hggcMemcpyFromArray, hggcMemcpyFromArrayAsync, hggcMemcpyFromArrayAsync_ptsz, hggcMemcpyFromArray_ptds, hggcMemcpyFromSymbol, hggcMemcpyFromSymbolAsync, hggcMemcpyFromSymbolAsync_ptsz, hggcMemcpyFromSymbol_ptds, hggcMemcpyPeer, hggcMemcpyPeerAsync, hggcMemcpyToArray, hggcMemcpyToArrayAsync, hggcMemcpyToArrayAsync_ptsz, hggcMemcpyToArray_ptds, hggcMemcpyToSymbol, hggcMemcpyToSymbolAsync, hggcMemcpyToSymbolAsync_ptsz, hggcMemcpyToSymbol_ptds, hggcMemcpy_ptds, hggcMemset, hggcMemset2D, hggcMemset2DAsync, hggcMemset2DAsync_ptsz, hggcMemset2D_ptds, hggcMemset3D, hggcMemset3DAsync, hggcMemset3DAsync_ptsz, hggcMemset3D_ptds, hggcMemsetAsync, hggcMemsetAsync_ptsz, hggcMemset_ptds, hggcStreamAttachMemAsync, hggcStreamAttachMemAsync_ptsz, hggcHostAlloc, hggcMalloc, hggcMalloc3D, hggcMalloc3DArray, hggcMallocArray, hggcMallocHost, hggcMallocManaged, hggcMallocMipmappedArray, hggcMallocPitch, hggcFree, hggcFreeArray, hggcFreeHost, hggcFreeMipmappedArray, hggcLaunch, hggcLaunch_ptsz, hggcLaunchKernel_ptsz, hggcLaunchCooperativeKernel_ptsz, hggcLaunchCooperativeKernelMultiDevice, # Hggc Driver API hgMemcpyHtoD, hg64MemcpyHtoD, hgMemcpyDtoH, hg64MemcpyDtoH, hgMemcpyDtoD, hg64MemcpyDtoD, hgMemcpyDtoA, hg64MemcpyDtoA, hgMemcpyAtoD, hg64MemcpyAtoD, hgMemcpyHtoA, hgMemcpyAtoH, hgMemcpyAtoA, hgMemcpy2D, hgMemcpy2DUnaligned, hgMemcpy3D, hg64Memcpy3D, hgMemcpyHtoDAsync, hg64MemcpyHtoDAsync, hgMemcpyDtoHAsync, hg64MemcpyDtoHAsync, hgMemcpyDtoDAsync, hg64MemcpyDtoDAsync, hgMemcpyHtoAAsync, hgMemcpyAtoHAsync, hgMemcpy2DAsync, hgMemcpy3DAsync, hg64Memcpy3DAsync, hg64Memcpy2D, hg64Memcpy2DUnaligned, hg64Memcpy2DAsync, hgMemcpy_v2, hgMemcpyHtoD_v2, hgMemcpyHtoDAsync_v2, hgMemcpyDtoH_v2, hgMemcpyDtoHAsync_v2, hgMemcpyDtoD_v2, hgMemcpyDtoDAsync_v2, hgMemcpyAtoH_v2, hgMemcpyAtoHAsync_v2, hgMemcpyAtoD_v2, hgMemcpyDtoA_v2, hgMemcpyAtoA_v2, hgMemcpy2D_v2, hgMemcpy2DUnaligned_v2, hgMemcpy2DAsync_v2, hgMemcpy3D_v2, hgMemcpy3DAsync_v2, hgMemcpyHtoA_v2, hgMemcpyHtoAAsync_v2, hgMemcpy, hgMemcpyAsync, hgMemcpyPeer, hgMemcpyPeerAsync, hgMemcpy3DPeer, hgMemcpy3DPeerAsync, hgMemcpyHtoD_v2_ptds, hgMemcpyDtoH_v2_ptds, hgMemcpyDtoD_v2_ptds, hgMemcpyDtoA_v2_ptds, hgMemcpyAtoD_v2_ptds, hgMemcpyHtoA_v2_ptds, hgMemcpyAtoH_v2_ptds, hgMemcpyAtoA_v2_ptds, hgMemcpy2D_v2_ptds, hgMemcpy2DUnaligned_v2_ptds, hgMemcpy3D_v2_ptds, hgMemcpy_ptds, hgMemcpyPeer_ptds, hgMemcpy3DPeer_ptds, hgMemcpyAsync_ptsz, hgMemcpyHtoAAsync_v2_ptsz, hgMemcpyAtoHAsync_v2_ptsz, hgMemcpyHtoDAsync_v2_ptsz, hgMemcpyDtoHAsync_v2_ptsz, hgMemcpyDtoDAsync_v2_ptsz, hgMemcpy2DAsync_v2_ptsz, hgMemcpy3DAsync_v2_ptsz, hgMemcpyPeerAsync_ptsz, hgMemcpy3DPeerAsync_ptsz, hgMemsetD8, hg64MemsetD8, hgMemsetD16, hg64MemsetD16, hgMemsetD32, hg64MemsetD32, hgMemsetD2D8, hg64MemsetD2D8, hgMemsetD2D16, hg64MemsetD2D16, hgMemsetD2D32, hg64MemsetD2D32, hgMemsetD8Async, hg64MemsetD8Async, hgMemsetD16Async, hg64MemsetD16Async, hgMemsetD32Async, hg64MemsetD32Async, hgMemsetD2D8Async, hg64MemsetD2D8Async, hgMemsetD2D16Async, hg64MemsetD2D16Async, hgMemsetD2D32Async, hg64MemsetD2D32Async, hgMemsetD8_v2, hgMemsetD16_v2, hgMemsetD32_v2, hgMemsetD2D8_v2, hgMemsetD2D16_v2, hgMemsetD2D32_v2, hgMemsetD8_v2_ptds, hgMemsetD16_v2_ptds, hgMemsetD32_v2_ptds, hgMemsetD2D8_v2_ptds, hgMemsetD2D16_v2_ptds, hgMemsetD2D32_v2_ptds, hgMemsetD8Async_ptsz, hgMemsetD16Async_ptsz, hgMemsetD32Async_ptsz, hgMemsetD2D8Async_ptsz, hgMemsetD2D16Async_ptsz, hgMemsetD2D32Async_ptsz, hgMemSetAccess, hgStreamAttachMemAsync, hgStreamAttachMemAsync_ptsz, hgMemAlloc, hg64MemAlloc, hgMemAllocPitch, hg64MemAllocPitch, hgMemAllocHost, hgMemHostAlloc, hg64MemHostAlloc, hgMemAlloc_v2, hgMemAllocPitch_v2, hgMemHostAlloc_v2, hgMemAllocHost_v2, hgMemAllocAsync, hgMemAllocAsync_ptsz, hgMemAllocFromPoolAsync, hgMemAllocFromPoolAsync_ptsz, hgMemFree, hg64MemFree, hgMemFreeHost, hgMemFree_v2, hgMemAddressFree, hgMemFreeAsync, hgMemFreeAsync_ptszApp-Range Replay模式下开启指令统计功能,在多卡场景下由于只能开单线程,无法通过多线程进行加速,所以profiling相对会比较慢。
ICNlink Section中显示的logical icnlink throughput查询的是MAC层数据,所以会比实际用户通过icnlink所产生的收发数据要多。
Mac系统上,在打开报告时强制退出GUI,可能会出现crash或hang的问题。
当打开使用Asight Compute 1.5/1.6版本采集的报告时,会因为缺少
ws__we_warps_active.avg.per_cycle_active,导致在执行IssueSlotUtilizationrule时失败。Details Page中Memory Workload Analysis Section中的 TSM Table里的 % Peak 列的Metric数据偏小, 带宽使用了读写又向带宽。
当报告采集于真武810E平台,Kernel中有使用 MMA 指令, Details Page中Memory Workload Analysis Section中的 TSM, KSD, KVD, L2 表格中的 %peak 的 metric 偏小, 带宽使用的CU数量是PPU上的总CU数。