
本文介绍如何在ACS集群中快速部署运行在PPU上的GLM-5推理服务。
准备工作
已完成首次使用容器计算服务,您需要开通容器计算服务ACS,并为其授权相应云资源的访问权限。
已开通CPFS服务。本文使用CPFS存储卷来持久化存储GLM-5模型文件。
创建ACS集群
本步骤介绍如何通过配置主要参数快速创建一个ACS集群。
关于创建ACS集群的详细配置参数说明,请参见创建ACS集群。
-
登录容器计算服务控制台,在左侧导航栏选择集群列表。
-
在集群列表页面,单击页面左上角的创建集群。
在创建集群页面,进行如下配置。其余配置项使用默认设置即可。
配置项
说明
示例值
集群名称
填写集群的名称。
ACS-PPU-Inference地域
选择集群所在的地域。
华北6(乌兰察布)单击确认配置,在满足所有依赖检查后,单击创建集群。
集群创建时间需要约5分钟。创建完成后,在集群列表页面,可以看到新创建的集群。
创建CPFS存储卷并下载模型
本步骤介绍如何新建CPFS文件系统作为GLM-5模型的持久化存储卷。
大语言模型因其庞大的参数量,需要占用大量的磁盘空间来存储模型文件,建议您创建CPFS存储卷、NAS存储卷或OSS存储卷来持久化存储模型文件。具体信息,请参见使用ACS快速构建大语言模型数据存储卷和使用CPFS静态存储卷。
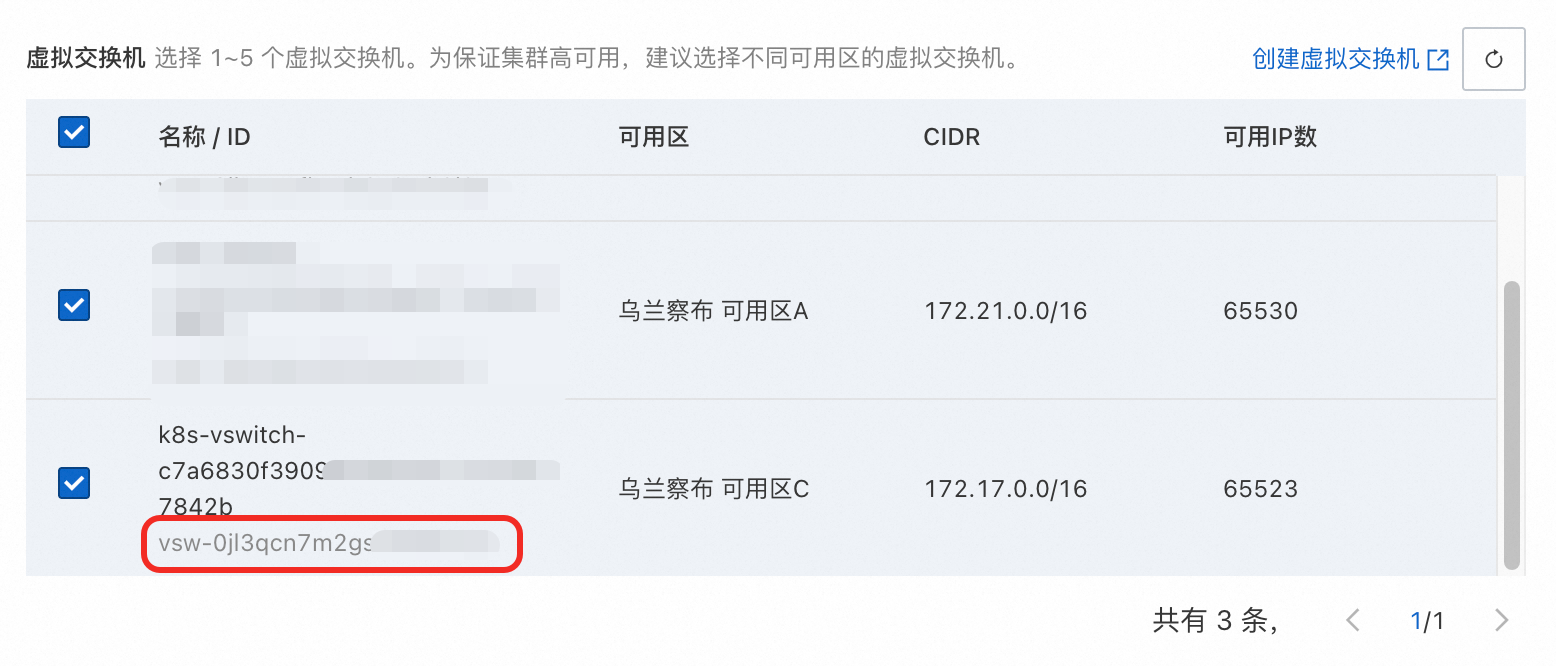
在集群列表页面,单击目标集群名称,进入基本信息页面,获取集群的VPC ID和交换机ID。
在网络区域的VPC部分,获取集群VPC ID。

在右侧控制面交换机部分,点击编辑。以乌兰察布可用区C为例,获取交换机ID。
创建CPFS文件系统,并记录文件系统信息。
文件系统ID:创建完成后,请记录文件系统ID,格式为
cpfs-*****ea13db*****。挂载地址:请使用上一步获取的ACS集群对应的VPC和交换机创建挂载点,生成挂载地址。创建完成后,请记录挂载点域名,格式为
cpfs-***-***.<RegionID>.cpfs.aliyuncs.com或cpfs-***-vpc-***.<RegionID>.cpfs.aliyuncs.com。
在容器计算服务控制台左侧导航栏,选择存储 > 存储卷,然后单击使用YAML创建资源。参考如下YAML,分别修改
server和volumeHandle为上一步获取的CPFS挂载地址和文件系统ID,单击创建。apiVersion: v1 kind: PersistentVolume metadata: name: glm-cpfs-pv labels: alicloud-pvname: glm-cpfs-pv spec: accessModes: - ReadWriteMany capacity: storage: 2Ti csi: driver: nasplugin.csi.alibabacloud.com volumeAttributes: mountProtocol: cpfs-nfs server: cpfs-29076ea13db*****-2937d3aa1973*****.cn-wulanchabu.cpfs.aliyuncs.com # 需替换为实际挂载地址 path: /share volumeHandle: cpfs-*****ea13db***** # 需替换为实际文件系统ID --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: glm-cpfs-pvc spec: accessModes: - ReadWriteMany selector: matchLabels: alicloud-pvname: glm-cpfs-pv resources: requests: storage: 2Ti出现创建成功的提示后,单击glm-cpfs-pvc右侧操作列的查看。当状态为Bound并且关联的存储卷为glm-cpfs-pv时,说明CPFS存储卷创建和绑定成功。
参考使用ACS快速构建大语言模型数据存储卷,创建临时工作负载并挂载CPFS存储卷,下载GLM-5 W8A8-INT8量化模型文件。
如何加速模型下载,请参考如何提升模型下载速度?
GLM-5 W8A8-INT8量化模型文件:https://art-pub.eng.t-head.cn/artifactory/generic-local/WEIGHT/GLM-5/
说明演示模型下载需要账密鉴权(复用PTG PIP的访问账密),可联系PDSA获取。
除了上述W8A8-INT8量化模型,还可使用PTG提供的QLean模型量化工具 (v0.1.0)自行量化。
部署GLM-5推理服务
本步骤介绍如何使用inference-xpu-pytorch推理镜像(vLLM框架)创建一个使用PPU GPU算力资源的工作负载,通过CPFS存储声明挂载GLM-5 W8A8-INT8量化模型文件,并关联到一个LoadBalancer类型的Service通过公网提供服务。
在左侧导航栏,选择,点击使用YAML创建资源,填入如下YAML,点击创建。
apiVersion: apps/v1 kind: Deployment metadata: labels: app: llm-test name: llm-test namespace: default spec: progressDeadlineSeconds: 6000 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: llm-test template: metadata: labels: alibabacloud.com/compute-class: gpu alibabacloud.com/gpu-model-series: PPU810E alibabacloud.com/compute-qos: default app: llm-test spec: containers: - command: - sh - -c - vllm serve /mnt/GLM-5-INT8/ --host 0.0.0.0 --port 8000 --tensor-parallel-size 16 --trust-remote-code --no-enable-prefix-caching # /mnt/GLM-5-INT8/ #为GLM-5量化模型在pod中的路径 image: acs-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:26.01-v2.0.0-vllm0.15.0-torch2.9-cu129-20260217-qwen3.5 #{region-id} imagePullPolicy: IfNotPresent name: llm-test resources: limits: cpu: 176 memory: 1800G alibabacloud.com/ppu: 16 ephemeral-storage: 200Gi requests: cpu: 176 memory: 1800G alibabacloud.com/ppu: 16 ephemeral-storage: 200Gi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /mnt #CPFS挂载路径 name: data - mountPath: /dev/shm name: cache-volume - mountPath: /ppu-data name: ephemeral dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: data persistentVolumeClaim: claimName: glm-cpfs-pvc #glm-cpfs-pvc为CPFS存储声明 - name: cache-volume emptyDir: medium: Memory sizeLimit: 500G - name: ephemeral emptyDir: sizeLimit: 200G --- apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "internet" service.beta.kubernetes.io/alibaba-cloud-loadbalancer-ip-version: ipv4 labels: app: llm-test name: svc-llm namespace: default spec: externalTrafficPolicy: Local ports: - name: serving port: 8000 protocol: TCP targetPort: 8000 selector: app: llm-test type: LoadBalancer出现创建成功的提示后,点击llm-test右侧操作列的查看,检查工作负载的创建状态。
从Pod达到Running状态到成功启动推理服务需要约30分钟,您可通过事件和日志查看当前创建信息。vLLM框架部署启动成功显示为
Application startup complete.。
测试推理服务
本步骤介绍如何在客户端通过弹性公网IP向推理服务发送请求,测试推理对话功能。
在ACS控制台中,在左侧导航栏,选择网络 > 服务,可以看到已创建的svc-llm服务,该服务的外部IP地址(External IP)即为推理服务的公网IP。

在本地执行以下
curl命令,验证推理服务对话功能。请将
<IP>修改为上一步中创建的服务的外部IP地址。curl http://<IP>:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/GLM-5-INT8/", "messages": [ { "role": "system", "content": "你是个友善的AI助手。" }, { "role": "user", "content": "请给我讲一个笑话。" } ] }'预期输出:
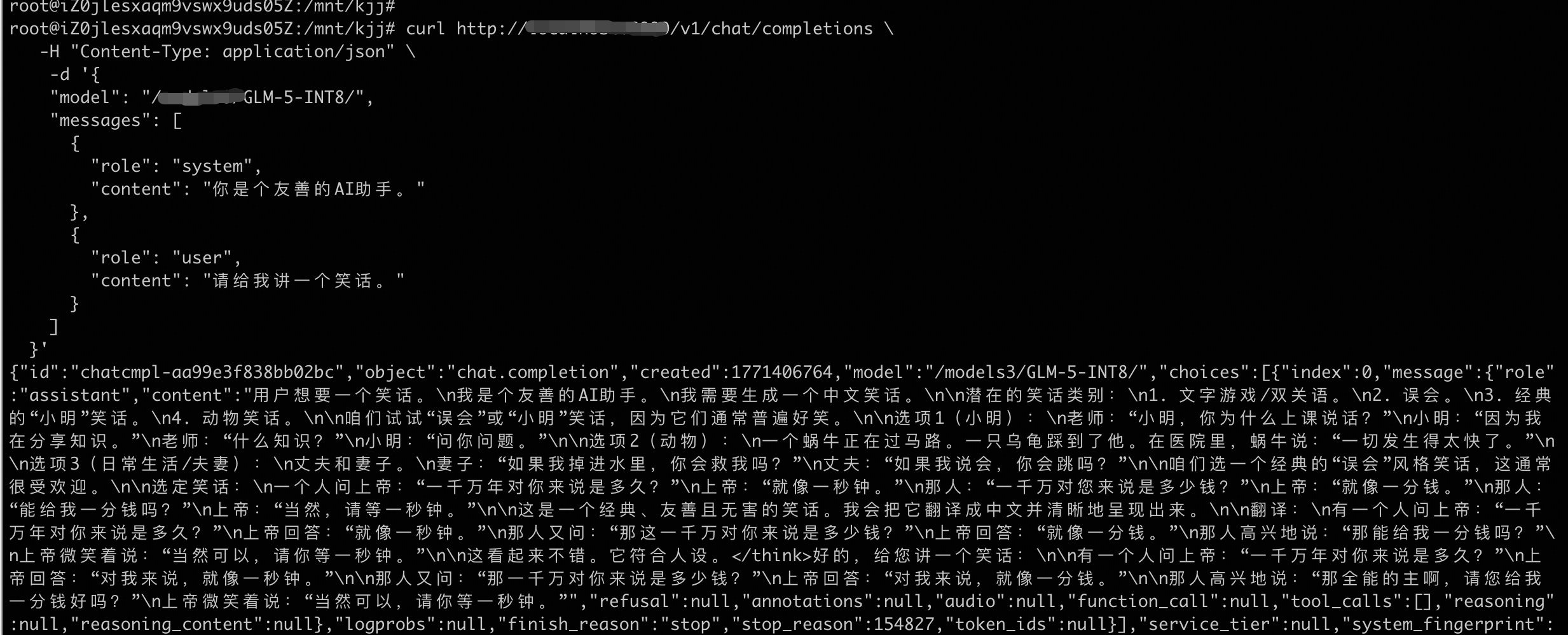
至此,在ACS集群中使用PPU部署GLM-5推理服务已完成。