您在使用数据传输服务DTS(Data Transmission Service)时。如果收到DTS返回的错误信息,可查阅常见报错匹配解决方案。如果您没有收到具体的错误信息,请根据问题分类匹配问题和解决方案。
问题分类
常见问题分为如下几种类型:
若您有其他疑问或需求,可以通过钉钉(钉钉通讯客户端下载地址)进入到DTS客户交流钉钉群(群号:68325004196或68640008972),进行咨询。
计费问题
DTS如何计费?
DTS提供包年包月和按量付费两种计费方式。关于计费方式的更多信息,请参见计费概述。
如何查看DTS账单?
查看DTS账单的操作,请参见查看账单。
实例暂停后是否还会扣费?
迁移实例暂停期间不收费。
在数据同步实例暂停期间,无论数据库是否可以正常连接,实例仍将继续收取费用。这是因为在此期间,DTS仅暂停向目标库中写入数据,但仍然会消耗CPU、内存等资源,以尝试进行持续地连接数据库并拉取源库的日志,以便在重启实例后能够快速恢复运行。
为什么数据同步的价格要高于数据迁移的价格?
因为数据同步具有更多的高级特性,例如支持在线调整同步对象、支持配置MySQL数据库之间的双向数据同步;且数据同步基于内网传输,可以保证更低的网络延时。
账户欠费有什么影响?
账户欠费的影响,请参见到期或欠费说明。
如何提前释放包年包月的任务?
释放包年包月的操作,请参见退订包年包月实例。
包年包月任务是否可以转成按量计费?
可以。转换方式,请参见转换计费方式。
按量计费任务是否可以转成包年包月?
数据同步或订阅任务可以。转换方式,请参见转换计费方式。
数据迁移任务的付费方式仅支持为按量计费。
为什么DTS任务突然开始收费了?
可能是因为实例的免费时间到期。DTS任务针对目标库是阿里云自研数据库引擎的任务有一定的优惠政策的,一段时间内免费,若免费时间到期就会开始收费。
为什么已经释放的任务还在收费?
DTS按量付费的任务是按天推送账单的,由于释放任务的那一天使用了DTS,所以还会收取当天的费用。
按量付费是如何收费的?
DTS按量付费仅会在增量任务正常运行期间进行计费(包含增量同步任务暂停期间,不包含增量迁移任务暂停期间)。更多信息,请参见计费方式。
DTS是否收取流量费用?
部分DTS任务会收取公网流量和数据流量费用,与源库和目标库的地域无关。目标库的接入方式为公网IP的迁移任务会收取公网流量费用,按行抽样进行全字段校验模式的全量校验任务会根据校验的数据量收取数据流量费用。更多信息,请参见计费项。
源库为MySQL的数据订阅任务是否收取数据流量费,取决于您选择的数据订阅配置费类型。
DTS是否支持节省计划?
不支持,您可以考虑采用Serverless实例来降低成本。更多信息,请参见什么是DTS Serverless实例。
性能和规格问题
不同实例规格有什么区别?
不同实例规格的区别,请参见数据迁移链路规格说明和数据同步链路规格说明。
是否支持升级实例规格?
支持。请在实例列表中找到目标实例,在实例右侧单击 ,然后单击升级。
,然后单击升级。
DTS升级规格后,不支持降配。
是否支持降级实例规格?
DTS暂不支持降级实例规格。
同步或迁移数据所需时间是多久?
由于DTS的传输性能受DTS内部、源端和目标端数据库实例的负载、待传输的数据量、DTS实例是否存在增量任务、网络等多种因素影响,所以无法预估DTS任务所需的时间,若对性能有较高要求,建议选择性能上限较大的规格。关于规格的更多信息,请参见数据迁移链路规格说明和数据同步链路规格说明。
如何查看数据迁移或数据同步任务的性能信息?
查看性能的方法,请参见查看增量迁移链路状态和性能或查看同步链路状态和性能。
为什么在控制台找不到指定的DTS实例?
可能原因:若指定的DTS实例为包年包月实例,则该实例已到期释放。
账号的资源组选择错误,建议选择为账号全部资源。
实例的地域选择错误,请核实所选择的地域是否为目标实例所属的地域。
实例的任务类型选择错误,请核实当前任务列表页面是否为目标实例的任务类型。例如,同步实例只会显示在同步任务列表。
实例因过期或欠费被释放。DTS实例到期或欠费后,数据传输任务将停止服务,如果7天内还未充值成功,系统将释放并删除该实例,更多信息请参见到期或欠费说明。
预检查问题
为什么Redis逐出策略检查项有告警?
如果目标端的数据逐出策略(maxmemory-policy)配置为noeviction以外的值,可能导致目标端的数据与源端不一致。关于数据逐出策略详情,请参见Redis数据逐出策略介绍。
增量数据迁移时Binlog相关的预检查项失败,如何处理?
检查源库Binlog是否正常,详情请参见源库Binlog检查。
数据库连接问题
源端数据库连接失败,如何处理?
检查源库信息和设置是否正常,详情请参见源库连接性检查。
目标端数据库连接失败,如何处理?
检查目标库信息和设置是否正常,详情请参见目标数据库连接性检查。
源或目标实例位于DTS暂不支持的地区,如何进行数据迁移和同步?
如果是数据迁移任务,您可以为数据库实例(如RDS MySQL)申请公网地址,以公网IP接入,实例地区可以选择DTS支持的地区,并将对应地区的DTS服务器IP地址段添加到实例的白名单中。需要添加的IP白名单,请参见添加DTS服务器的IP地址段。
如果是数据同步任务,由于数据同步暂不支持将数据库实例作为公网IP接入,因此DTS暂不支持这些地区的数据同步。
数据同步问题
DTS支持哪些数据库实例的同步?
DTS支持各种数据源之间的数据同步,如关系型数据库管理系统(RDBMS)、NoSQL数据库、联机分析处理(OLAP)数据库。支持同步的数据库实例,请参见同步方案概览。
数据迁移和数据同步的区别是什么?
数据迁移和数据同步的区别如下表所示:
对比项 | 数据迁移 | 数据同步 |
适用场景 | 主要用于上云迁移,例如将本地数据库、ECS上的自建数据库或第三方云数据库迁移至阿里云数据库。 | 主要用于两个数据源之间的数据实时同步,适用于异地多活、数据灾备、跨境数据同步、查询与报表分流、云BI及实时数据仓库等场景。 |
支持的数据库 | 请参见迁移方案概览。 | 请参见同步方案概览。 |
支持的数据库部署位置(接入方式) |
|
说明 数据同步基于内网传输,可以保证更低的网络延时。 |
功能特性差异 |
|
|
计费方式 | 仅支持按量付费。 | 支持按量付费和包年包月。 |
计费规则 | 仅在增量数据迁移正常运行期间计费(不包含增量数据迁移暂停期间),结构迁移和全量数据迁移期间不计费。 |
|
对于某些数据同步不支持的数据库(例如MongoDB实例),您可以通过增量数据迁移的方式来实现数据同步。
数据同步的工作原理是什么?
数据同步的工作原理,请参见产品架构及功能原理。
如何计算同步延迟?
同步延迟是指同步到目标数据库中的最新数据的时间戳,与源数据库的当前时间戳之间的差值。单位为毫秒。
正常情况的延迟在1000毫秒以内。
数据同步任务是否可以修改同步对象?
数据同步任务是否可以增加新表进行同步?
可以。增加新表的方法,请参见新增同步对象。
如何修改运行中的同步任务的表和字段等同步对象?
当同步任务的全量同步阶段结束,进入增量数据同步阶段后可以修改同步对象。修改同步对象的方法,请参见新增同步对象和移除同步对象。
暂停同步任务后过一段时间再重启,是否会导致数据不一致?
若同步任务暂停期间源库有变化,则可能会导致源库与目标库数据不一致。待同步任务重启并将增量数据同步到目标库后,目标库数据将与源库一致。
删除增量同步任务源库中的数据,目标库中已同步的数据是否会删除?
若增量同步任务所需同步的DML操作没有勾选delete,则目标库中数据不会被删除,否则目标库中已同步的数据会被删除。
Redis间的同步,目标Redis实例的数据会被覆盖么
相同Key的数据会被覆盖。DTS会在预检查阶段对目标端进行检查,如果目标端的数据不为空会报错。
同步任务是否支持过滤部分字段或数据?
支持。通过映射功能可以过滤无需同步的列,通过指定SQL Where条件可以过滤待同步数据。更多信息,请参见同步或迁移部分列和通过SQL条件过滤任务数据。
同步任务是否可以转为迁移任务?
不可以,不同类型的任务不支持相互转换。
是否可以只同步数据不同步结构?
可以。在配置同步任务步骤时,不勾选库表结构同步即可。
数据同步实例的源和目标端数据不一致,可能原因有哪些?
数据不一致的可能原因如下:
配置任务时没有清空目标端数据,且目标端有存量数据。
配置任务时只选择了增量同步模块,没有选择全量同步模块。
配置任务时只选择了全量同步模块,没有选择增量同步模块,且任务结束后源端数据有变更。
目标端有除了DTS任务以外的数据写入。
增量写入存在延迟,增量数据还没有全部写入目标端。
数据同步任务是否可以修改源库在目标库的名称?
可以。修改源库在目标库名称的方法,请参见设置同步对象在目标实例中的名称。
是否支持DML或DDL操作的实时同步?
支持,关系数据库之间的数据同步支持的DML操作为INSERT、UPDATE、DELETE,支持的DDL操作为CREATE、DROP、ALTER、RENAME、TRUNCATE。
不同场景下支持的DML或DDL操作有所区别,请在同步方案概览中选择符合业务场景的链路,在具体链路配置文档中查看支持的DML或DDL操作。
只读实例是否可以作为同步任务的源实例?
同步任务默认包含增量数据同步,因此有如下两种情况:
实例为记录事务日志的只读实例(如RDS MySQL 5.7或8.0版本),可以作为源实例。
实例为不记录事务日志的只读实例(如RDS MySQL 5.6版本),不可以作为源实例。
DTS是否支持分库分表的数据同步?
支持,例如将MySQL、PolarDB MySQL中的分库分表同步到云原生数据仓库 AnalyticDB MySQL 版中,以实现多表归并。
为什么同步任务结束后目标实例比源实例的数据量小?
若同步过程中进行了数据过滤,或者源实例内表碎片较多,迁移完成后目标实例的数据量可能会小于源实例。
跨账号数据同步任务,是否支持双向同步?
当前仅RDS MySQL实例间、PolarDB MySQL版集群间、Tair(企业版)实例间,支持跨账号的双向同步任务。
DTS是否支持跨境的双向同步任务?
不支持。
为什么双向同步任务的一个数据库中增加了记录后,另一个数据库里没有增加?
可能是未配置反向任务。配置反向任务的步骤,请参见RDS MySQL实例间的双向同步的步骤11。
为什么同步任务增量显示一直没有到100%?
DTS增量同步是持续将源端的变更实时同步到目标端,且不会主动结束,即不存在100%的完成状态。如果您不需要继续实时同步,请在DTS控制台结束任务。
为什么增量同步任务不能同步数据?
如果DTS实例只配置了增量同步任务,则DTS只会同步任务启动之后的增量数据,任务启动前的数据不会同步至目标库。建议配置任务时同时勾选增量同步、库表结构同步和全量同步,以保障数据一致性。
同步RDS数据库的全量数据时,是否会对源库RDS的性能有影响?
会影响源库的查询性能。有如下三种方法可以减少DTS任务对源库的影响:
提高源库实例的规格。
先暂停DTS任务,等源库负载降低后再重启任务。
调小DTS任务的速率。调整速率的方法,请参见调整全量迁移速率。
为什么源库为PolarDB-X 1.0的同步实例不显示延迟?
源库为PolarDB-X 1.0的实例是分布式任务,而DTS监控的指标只在子任务中存在,因此源为PolarDB-X 1.0的实例不显示延迟信息。您可以单击实例ID,在实例任务管理的子任务详情中查看延迟信息。
为什么多表归并任务报错DTS-071001?
可能是在多表归并任务运行时,在源库进行了Online DDL操作,对源库的表结构等进行了修改,且未手动在目标库进行相应的修改。
在旧版控制台配置任务时添加白名单失败,如何处理?
请使用新版控制台配置任务。
DTS数据同步过程中,源库执行了DDL操作导致任务失败,如何处理?
根据源库执行的DDL操作,手动在目标端执行DDL后重启任务。数据同步时,请勿对源库的同步对象使用pt-online-schema-change等类似工具执行在线DDL变更,否则会导致同步失败。如果除DTS以外的数据没有写入目标库,您可以使用数据管理DMS(Data Management)来执行在线DDL变更,或者可以通过修改同步对象移除受DDL影响的表。移除操作,请参见移除同步对象。
DTS数据同步过程中,目标库执行了DDL操作导致任务失败,如何处理?
如果在DTS进行增量同步过程中删除了目标库中的某一个库或表,导致任务异常,您可以采取如下两种方案恢复任务:
方法一:重新配置任务,待同步对象不选择导致任务失败的库或表。
方法二:修改同步对象,移除导致任务失败的库或表。具体操作,请参见移除同步对象。
同步任务释放后还可以恢复吗?重新配置任务能否保证数据一致性?
同步任务释放后不可以恢复。重新配置任务时,如果不选择全量同步,在任务释放到新任务启动这段时间新增的数据无法同步到目标库,无法保障数据一致性。如果业务对数据要求比较精确,您可以删除目标库的数据,然后重新配置同步任务,并在任务步骤同时选中库表结构同步和全量同步(默认已选中增量同步)。
DTS全量同步任务长时间没进度,如何处理?
若待同步的表为无主键的表,全量同步会非常慢。建议为源库待同步的表增加主键后再进行同步。
同名的表进行数据同步时,是否支持源表数据在目标表不存在时才进行传输?
支持。在配置任务时,您可以将目标已存在表的处理模式选择为忽略报错并继续执行。表结构一致的情况下,在全量同步期间目标库遇到与源库主键的值相同的记录时,源库中的该条记录不会同步至目标库中。
如何配置跨账号的同步任务?
您需要使用源实例所属的阿里云账号配置RAM授权,然后使用目标实例所属的阿里云账号(主账号)配置DTS任务。更多信息,请参见跨阿里云账号实现数据传输的配置示例。
无法选择DMS LogicDB实例,如何处理?
请确保实例所属的地域选择正确,若还是不能选择实例,则可能仅有一个实例,请继续配置其他参数。
SQL Server为源的同步任务,是否支持同步函数?
不支持。若同步对象选择的粒度为表,且其他对象(如视图、触发器、存储过程)也不会被同步至目标库。
数据同步任务报错,如何处理?
您可以根据报错信息,在常见报错中查看解决方法。
同步任务如何开启热点合并?
请参考修改参数值将trans.hot.merge.enable的值修改为true。
源库存在触发器时如何进行同步?
当同步对象为整个库,且库中的触发器(TRIGGER)会更新库内某个表时,可能导致源和目标库的数据不一致。同步操作,请参见源库存在触发器时如何配置同步或迁移作业。
DTS是否支持同步sys库和系统库?
不支持。
DTS是否支持同步MongoDB的admin和local库?
不支持,DTS不支持MongoDB的admin和local作为源和目标库。
双向同步任务的反向任务什么时候才能配置?
双向同步任务的反向任务需要正向的增量任务无延迟后才能配置。
PolarDB-X 1.0为源时,同步任务的源端PolarDB-X 1.0是否支持扩缩节点?
不支持。若源端PolarDB-X 1.0发生节点的扩缩容,您需要重新配置任务。
DTS同步到Kafka的数据可以保证唯一性吗?
不可以。由于写入到Kafka中的数据都是追加的形式,所以在DTS任务重启或重复拉取到源端日志的时候可能会有重复数据。DTS保证数据的幂等性,即数据是按顺序进行排列的,重复数据的最新值会排在后面。
DTS数据同步是否支持RDS MySQL至云原生数据仓库 AnalyticDB MySQL 版?
支持。配置方法,请参见RDS MySQL同步至云原生数据仓库 AnalyticDB MySQL 版 3.0。
为什么Redis间的同步任务不显示全量同步?
Redis间的同步支持全量数据同步和增量数据同步,合并显示为增量同步。
全量同步可以跳过吗?
可以。跳过全量同步后增量同步会继续向下进行,但是可能会报错,建议您不要跳过全量同步。
DTS是否支持定时自动同步?
DTS暂时还不支持定时启动数据同步任务。
同步过程中会不会把表中的碎片空间也一起同步过去?
不会。
从MySQL 8.0同步到MySQL 5.6需要注意什么?
您需要在MySQL 5.6中创建好数据库后再进行同步操作。建议源和目标库版本保持一致,或者从低版本同步到高版本以保障兼容性。如为高版本同步至低版本,可能存在数据库兼容性问题。
是否可以将源库中的账号同步至目标库?
当前仅RDS MySQL实例间的同步任务支持同步账号,其余同步任务暂不支持。
是否可以配置跨账号的双向同步任务?
当前仅RDS MySQL实例间、PolarDB MySQL版集群间、Tair(企业版)实例间,支持跨账号的双向同步任务。
没有是否跨阿里云账号配置项的任务,您可以尝试使用CEN实现跨账号的双向同步任务。更多信息,请参见跨阿里云账号或跨地域访问数据库资源。
消息队列Kafka版为目标端时的参数如何配置?
请根据实际情况进行配置,部分特殊参数的配置方法请参见配置消息队列Kafka版实例的参数。
数据同步实例可以免费试用几个?
仅可免费试用1个同步实例,有效期3个月。更多信息,请参见阿里云免费试用。
数据迁移问题
执行数据迁移任务后,源库的数据是否还存在?
DTS数据迁移和同步是将源库的数据复制到目标库中,不会影响源端数据。
DTS支持哪些数据库实例的迁移?
DTS支持各种数据源之间的数据迁移,如关系型数据库管理系统(RDBMS)、NoSQL数据库、联机分析处理(OLAP)数据库。支持的迁移实例,请参见迁移方案概览
数据迁移的工作原理是什么?
数据迁移的工作原理,请参见产品架构及功能原理。
数据迁移任务是否可以修改迁移对象?
不可以。
数据迁移任务是否可以增加新表进行迁移?
不可以。
如何修改运行中的迁移任务的表和字段等迁移对象?
迁移任务不支持修改迁移对象。
暂停迁移任务后过一段时间再重启,是否会导致数据不一致?
若迁移任务暂停期间源库有变化,则可能会导致源库与目标库数据不一致。待迁移任务重启并将增量数据迁移到目标库后,目标库数据将与源库一致。
迁移任务是否可以转为同步任务?
不可以,不同类型的任务不支持相互转换。
是否可以只迁移数据不迁移结构?
可以。在配置迁移任务步骤时,不勾选库表结构迁移即可。
数据迁移实例的源和目标端数据不一致,可能原因有哪些?
数据不一致的可能原因如下:
配置任务时没有清空目标端数据,且目标端有存量数据。
配置任务时只选择了增量迁移模块,没有选择全量迁移模块。
配置任务时只选择了全量迁移模块,没有选择增量迁移模块,且任务结束后源端数据有变更。
目标端有除了DTS任务以外的数据写入。
增量写入存在延迟,增量数据还没有全部写入目标端。
数据迁移任务是否可以修改源库在目标库的名称?
可以。修改源库在目标库名称的方法,请参见库表列映射。
是否支持同一实例内的数据迁移?
支持。同一实例内数据迁移的方法,请参见不同库名间的数据同步或迁移。
是否支持DML或DDL操作的实时迁移?
支持,关系数据库之间的数据支持的DML操作为INSERT、UPDATE、DELETE,支持的DDL操作为CREATE、DROP、ALTER、RENAME、TRUNCATE。
不同场景下支持的DML或DDL操作有所区别,请在迁移方案概览中选择符合业务场景的链路,在具体链路配置文档中查看支持的DML或DDL操作。
只读实例是否可以作为迁移任务的源实
若迁移任务不需要进行增量数据迁移,则只读实例可以作为源实例;若迁移任务需要进行增量数据迁移,有如下两种情况:
实例为记录事务日志的只读实例(如RDS MySQL 5.7或8.0版本),可以作为源实例。
实例为不记录事务日志的只读实例(如RDS MySQL 5.6版本),不可以作为源实例。
DTS是否支持分库分表的数据迁移?
支持,例如将MySQL、PolarDB MySQL中的分库分表迁移到云原生数据仓库 AnalyticDB MySQL 版中,以实现多表归并。
迁移任务是否支持过滤部分字段或数据?
支持。通过映射功能可以过滤无需迁移的列,通过指定SQL Where条件可以过滤待迁移数据。更多信息,请参见同步或迁移部分列和过滤待迁移数据。
为什么迁移任务结束后目标实例比源实例的数据量小?
若迁移过程中进行了数据过滤,或者源实例内表碎片较多,迁移完成后目标实例的数据量可能会小于源实例。
为什么迁移任务显示已完成的值超过总数?
显示的总数为预估值,在迁移任务完成后会将总数调整为准确值。
数据迁移时目标数据库新增increment_trx表的作用是什么?
数据迁移时目标数据库新增一个increment_trx表,是DTS增量迁移在目标实例中创建的位点表,主要用于记录增量迁移的位点,解决任务异常重启后的断点续传问题。在迁移过程中请勿删除,否则会导致迁移失败。
数据迁移任务在全量迁移阶段是否支持断点续传?
支持。在全量迁移阶段暂停任务后重启任务,任务会从已经迁移完成的位置开始继续迁移,不需要重新开始。
如何将非阿里云实例迁移到阿里云?
将非阿里云实例迁移到阿里云的方法,请参见从第三方云迁移至阿里云。
如何将本地Oracle数据库迁移到PolarDB?
将本地Oracle数据库迁移到PolarDB的方法,请参见自建Oracle迁移至PolarDB PostgreSQL版(兼容Oracle)。
全量迁移阶段没完成的数据迁移任务是否可以暂停?
可以。
如何将RDS MySQL部分数据迁移到自建MySQL?
您可以在配置迁移任务过程中,根据需求在源库对象中选择待迁移的对象或在已选择对象中进行过滤。MySQL间的迁移操作类似,您可以参考自建MySQL迁移至RDS MySQL进行操作 。
同一个阿里云账号下的RDS实例如何迁移?
DTS支持RDS实例之间的迁移和同步,配置方法请参见迁移方案概览中的相关配置文档。
迁移任务启动后源库就有IOPS报警,此时如何保证源库业务稳定?
DTS任务运行时,若源库实例负载比较大,有如下三种方法可以减少DTS任务对源库的影响:
提高源库实例的规格。
先暂停DTS任务,等源库负载降低后再重启任务。
调小DTS任务的速率。调整速率的方法,请参见调整全量迁移速率。
为什么数据迁移任务无法选择名为test的数据库?
DTS数据迁移不支持迁移系统数据库,请选择业务自建的数据库进行迁移。
为什么源库为PolarDB-X 1.0的迁移实例不显示延迟?
源库为PolarDB-X 1.0的实例是分布式任务,而DTS监控的指标只在子任务中存在,因此源为PolarDB-X 1.0的实例不显示延迟信息。您可以单击实例ID,在实例任务管理的子任务详情中查看延迟信息。
为什么DTS无法迁移MongoDB数据库?
可能是因为待迁移的数据库为local或者admin,DTS不支持MongoDB的admin和local作为源和目标库。
为什么多表归并任务报错DTS-071001?
可能是在多表归并任务运行时,在源库进行了Online DDL操作,对源库的表结构等进行了修改,且未手动在目标库进行相应的修改。
在旧版控制台配置任务时添加白名单失败,如何处理?
请使用新版控制台配置任务。
DTS数据迁移过程中,源库执行了DDL操作导致任务失败,如何处理?
根据源库执行的DDL内容,手动在目标端执行DDL后重启任务。数据迁移时,请勿对源库的迁移对象使用pt-online-schema-change等类似工具执行在线DDL变更,否则会导致迁移失败。如果除DTS以外的数据没有写入目标库,您可以使用数据管理DMS(Data Management)来执行在线DDL变更。
DTS数据迁移过程中,目标库执行了DDL操作导致任务失败,如何处理?
如果在DTS进行增量迁移过程中删除了目标库中的某一个库或表,导致任务异常。您可以重新配置任务,待迁移对象不选择导致任务失败的库或表。
迁移任务释放后还可以恢复吗?重新配置任务能否保证数据一致性?
迁移任务释放后不可以恢复。重新配置任务时,如果不选择全量迁移,在任务释放到新任务启动这段时间新增的数据无法迁移到目标库,无法保障数据一致性。如果业务对数据要求比较精确,您可以删除目标库的数据,然后重新配置迁移任务,并在任务步骤同时选中库表结构迁移、增量迁移和全量迁移。
DTS全量迁移任务长时间没进度,如何处理?
若待迁移的表为无主键的表,全量迁移会非常慢。建议为源库待迁移的表增加主键后再进行迁移。
同名的表进行数据迁移时,是否支持源表数据在目标表不存在时才进行传输?
支持。在配置任务时,您可以将目标已存在表的处理模式选择为忽略报错并继续执行。表结构一致的情况下,在全量迁移期间目标库遇到与源库主键的值相同的记录时,源库中的该条记录不会迁移至目标库中。
如何配置跨账号的迁移任务?
您需要使用源实例所属的阿里云账号配置RAM授权,然后使用目标实例所属的阿里云账号(主账号)配置DTS任务。更多信息,请参见跨阿里云账号实现数据传输的配置示例。
数据迁移任务如何连接本地数据库?
您可以将本地数据库的接入方式选择为公网IP来配置迁移任务。示例操作,请参见自建MySQL迁移至RDS MySQL。
数据迁移失败并提示DTS-31008,如何处理?
您可以单击查看原因或者根据报错信息在常见报错中查看解决方法。
使用专线接入自建数据库时网络不通,如何处理?
请检查专线是否正确配置了DTS相关的IP白名单。需添加的IP白名单清单,请参见添加DTS服务器的IP地址段。
SQL Server为源的迁移任务,是否支持迁移函数?
不支持。若迁移对象选择的粒度为表,且其他对象(如视图、触发器、存储过程)也不会被迁移至目标库。
DTS全量迁移速度慢,如何处理?
可能是需要迁移的数据量比较大,请耐心等待。您可以进入任务详情页面,在任务管理的全量迁移模块查看迁移进度。
任务报内部错误,如何处理?
您可以通过钉钉(钉钉通讯客户端下载地址)进入到DTS客户交流钉钉群(群号:68325004196或68640008972),进行咨询。
结构迁移报错,如何处理?
单击实例ID,进入任务详情页面,在任务管理中查看结构迁移模块的具体报错信息,然后针对具体报错信息进行解决。常见报错解决方法,请参见常见报错。
库表结构迁移和全量迁移是否收费?
不收费。更多收费信息,请参见计费项。
Redis间的数据迁移任务,目标端的zset数据是否会被覆盖?
目标端的zset会被覆盖。若目标端已经存在与源端相同的key,DTS会先删除目标端对应key的zset,然后将源端zset集合中的每个对象zadd到目标端。
全量迁移对源库有什么影响?
DTS全量迁移的流程是先进行数据切片,再对切片范围内的数据进行读取和写入。对于源库,在切片过程中会使源库的IOPS升高;在对切片范围内数据读取的过程中,对源库的IOPS、CachePool、源库出口带宽会造成一定的影响。结合DTS的实践经验,这些影响均可忽略。
PolarDB-X 1.0为源时,迁移任务的源端PolarDB-X 1.0是否支持扩缩节点?
不支持。若源端PolarDB-X 1.0发生节点的扩缩容,您需要重新配置任务。
DTS迁移到Kafka的数据可以保证唯一性吗?
不可以。由于写入到Kafka中的数据都是追加的形式,所以在DTS任务重启或重复拉取到源端日志的时候可能会有重复数据。DTS保证数据的幂等性,即数据是按顺序进行排列的,重复数据的最新值会排在后面。
先配置一个全量迁移任务,再配置增量数据迁移任务,是否会出现数据不一致?
可能会出现数据不一致。迁移任务单独配置增量数据迁移时,增量迁移任务启动后才开始迁移数据,在增量迁移任务启动之前,源实例产生的增量数据都不会被同步到目标实例。如果需要进行不停机迁移,建议配置任务时,迁移类型选择结构迁移、全量数据迁移及增量数据迁移。
配置迁移增量任务是否需要勾选库表结构迁移?
结构迁移是在数据迁移开始前,先将迁移对象的定义迁移到目标实例,例如将表A的表定义迁移到目标实例。如果需要进行增量迁移,为了保证迁移数据一致性,建议将库表结构迁移、全量数据迁移及增量数据迁移全部勾选上。
为什么将自建数据库迁移到RDS过程中,RDS使用的存储空间会比源数据库大?
因为DTS进行的是逻辑迁移,它是将待迁移数据封装成SQL后,迁移到目标RDS实例中的。此时会在目标RDS实例中产生Binlog数据,所以迁移过程中,RDS使用的存储空间可能比源数据库大。
DTS是否支持VPC网络下的MongoDB的迁移?
支持,DTS当前已经支持VPC网络的云数据库MongoDB作为迁移的源数据库。
数据迁移期间如果源数据库出现数据变化,迁移数据会产生什么结果?
如果迁移任务配置了库表结构迁移、全量迁移、增量迁移,那么迁移期间源数据库出现的数据变化,都会被DTS迁移到目标库。
释放已完成的迁移任务,是否会影响被迁移数据库的使用?
不会影响。迁移任务完成后(运行状态为已完成),您可以放心释放该迁移任务。
DTS是否支持MongoDB增量迁移?
支持。相关配置案例,请参见迁移方案概览。
迁移任务的源实例为RDS实例和以公网IP接入的自建数据库实例有什么区别?
配置迁移任务如果选择RDS实例时,那么当RDS实例发生DNS修改,网络类型切换等变更时,DTS迁移任务可以自适应,有效保证链路可靠性。
DTS是否支持VPC内的ECS上的自建数据库迁移到RDS实例?
支持。
若源ECS实例和目标RDS实例在相同地域,DTS可以直接访问VPC内ECS实例上的自建数据库。
若源ECS实例和目标RDS实例在不同的地域,ECS实例需要挂载弹性公网IP,配置迁移任务时,源实例选择ECS实例,DTS会自动使用ECS实例的弹性公网IP访问ECS实例上的数据库。
DTS迁移过程中,是否会锁表?对源数据库是否有影响?
DTS在进行全量数据迁移和增量数据迁移的过程中,均不会对源端数据库进行锁表。在全量数据迁移和增量数据迁移的过程中,迁移源端的数据表均可以正常读写访问。
DTS进行RDS迁移时,是从RDS的主库还是备库获取数据?
DTS进行数据迁移时,是从RDS的主库上拉取数据。
DTS是否支持定时自动迁移?
DTS暂时还不支持定时启动数据迁移任务。
DTS是否支持VPC模式下的RDS实例的数据迁移?
支持,配置迁移任务时,直接配置RDS实例ID即可。
DTS同一账号或跨账号迁移、同步时,对于ECS、RDS实例是走内网还是公网?是否会收取流量费用?
DTS进行同步或迁移任务时,使用的网络(内网或公网)与是否跨账号无关,是否收取流量费用取决于任务类型。
使用的网络
迁移任务:如果是进行同一个地区内部的数据迁移,那么DTS会使用内网连接ECS、RDS实例。如果是进行跨地区的迁移,那么DTS会使用外网连接源实例(ECS、RDS),使用内网连接目标RDS实例。
同步任务:使用内网。
流量费用
迁移任务:收取公网出云流量费用,其他类型均的DTS实例不收取流量费用。公网出云流量费用,是指目标数据库实例的接入方式为公网IP时产生的流量费用。
同步任务:不收取流量费用。
使用DTS进行数据迁移,源数据库的数据会不会在迁移后被删除掉?
不会,DTS进行数据迁移时,实际是将源数据库的数据复制一份到目标库,不会对源数据库的数据有影响。
DTS在执行RDS实例间的数据迁移时,是否可以指定迁移目标库的名称?
可以。您可以在执行RDS实例间的数据迁移时,使用DTS提供的库名映射功能来指定迁移目标库的名称,详情请参见不同库名间的数据同步或迁移。
DTS迁移任务的源端无法连接ECS实例,如何处理?
可能是ECS实例未开放公网IP,请给ECS实例绑定弹性IP后重试。绑定弹性IP的方法,详情请参见弹性公网IP。
为什么Redis间的迁移任务不显示全量迁移?
Redis间的迁移支持全量数据迁移和增量数据迁移,合并显示为增量迁移。
全量迁移可以跳过吗?
可以。跳过全量迁移后增量迁移会继续向下进行,但是可能会报错,建议您不要跳过全量迁移。
集群版的Redis是否支持以公网IP接入DTS?
不支持,当前仅单机版的Redis支持以公网IP接入DTS的迁移实例。
从MySQL 8.0迁移到MySQL 5.6需要注意什么?
您需要在MySQL 5.6中创建好数据库后再进行迁移操作。建议源和目标库版本保持一致,或者从低版本迁移到高版本以保障兼容性。如果是高版本迁移至低版本,可能存在数据库兼容性问题。
是否可以将源库中的账号迁移至目标库?
当前仅RDS MySQL实例间的迁移任务支持迁移账号,其余迁移任务暂不支持。
消息队列Kafka版为目标端时的参数如何配置?
请根据实际情况进行配置,部分特殊参数的配置方法请参见配置消息队列Kafka版实例的参数。
如何定时全量迁移?
您可以通过数据集成功能的调度策略配置,定期将源库中的结构和存量数据迁移至目标库中。更多信息,请参见配置RDS MySQL间的数据集成任务。
是否支持将ECS自建的SQL Server迁移至本地自建的SQL Server?
支持。本地自建的SQL Server需要接入到阿里云,详情请参见准备工作概览。
是否支持迁移其他云的PostgreSQL数据库?
当其他云的PostgreSQL数据库需允许DTS通过公网访问时,支持通过DTS迁移数据。
若PostgreSQL的版本低于10.0,则不支持增量迁移。
是否支持将MySQL的数据迁移到Mycat?
支持,您可以将Mycat以自建MySQL的方式接入到阿里云,然后使用DTS进行数据迁移。
数据迁移实例可以免费试用几个?
仅可免费试用1个迁移实例,有效期3个月。更多信息,请参见阿里云免费试用。
数据迁移期间是否支持DDL操作的增量迁移?
部分迁移场景下支持,详情请参见迁移任务的注意事项及限制。
数据订阅问题
数据订阅的工作原理是什么?
数据订阅的工作原理,请参见产品架构及功能原理。
数据订阅任务到期后,消费组是否会被删除?
DTS数据订阅到期后,数据消费组会保留7天。实例到期超过7天未续费会被释放,对应的消费组也会被删除。
只读实例是否可以作为订阅任务的源实例?
有如下两种情况:
实例为记录事务日志的只读实例(如RDS MySQL 5.7或8.0版本),可以作为源实例。
实例为不记录事务日志的只读实例(如RDS MySQL 5.6版本),不可以作为源实例。
如何消费订阅的数据?
详情请参见消费订阅数据。
为什么使用数据订阅功能传输数据后,日期数据格式发生变化?
DTS默认日期数据存储格式为YYYY:MM:DD,YYYY-MM-DD是展现出来的格式,实际存储是YYYY:MM:DD格式。所以传输写入的数据格式无论是哪一种,最终都要统一转化为默认格式。
如何排查订阅任务问题?
排查订阅任务的方法,请参见排查订阅任务问题。
SDK正常下载数据过程中突然暂停且不能订阅到数据,如何处理?
请排查SDK代码中是否调用ackAsConsumed接口汇报消费位点。如果不调用ackAsConsumed汇报位点,那么SDK内部设置的Record的缓存空间数据就不会删除,当缓存全部被占用时,就不能拉取新的数据,从而会出现SDK暂停且不能订阅数据。
SDK重新运行后不能成功订阅数据,如何处理?
在启动SDK之前,请先修改消费位点,使消费位点在数据范围内。修改消费位点的方法,请参见保存和查询消费位点。
客户端如何指定时间点进行数据消费?
在消费订阅数据时,填写initCheckpoint参数即可指定时间点。更多信息,请参见使用SDK示例代码消费订阅数据。
DTS订阅任务堆积了,如何重置位点?
根据SDK客户端的使用模式,打开对应的代码文件。例如,DTSConsumerAssignDemo.java或DTSConsumerSubscribeDemo.java。
说明更多信息,请参见使用SDK示例代码消费订阅数据。
在订阅任务列表的数据范围列,查看目标订阅实例位点的可修改范围。
根据实际情况选择新的消费位点,并转化为Unix时间戳。
使用转化后的新消费位点,替换代码文件中的旧消费位点(initCheckpoint参数)。
重新运行客户端。
在客户端使用订阅任务的VPC地址连接不上,如何处理?
可能是客户端所在机器不在配置订阅任务时指定的VPC里(如客户端VPC更换),您需要重新配置任务。
为什么控制台上的消费位点要比数据范围最大值还要大?
因为订阅通道的数据范围更新频率为1分钟,而消费位点的更新频率为10秒。所以如果实时消费的话,消费位点的值可能比订阅通道数据范围的最大值要大。
DTS如何保证SDK订阅到的数据是一个完整的事务?
DTS根据提供的消费位点,服务端会搜索这个消费位点对应的完整事务,从整个事务的BEGIN语句开始向下游分发数据,所以可以接受到完整的事务内容。
如何确认数据是否正常消费?
如果数据正常消费,那么数据传输控制台的消费位点就会正常往前推进。
数据订阅SDK中usePublicIp=true是什么意思?
数据订阅SDK配置usePublicIp=true,表示SDK通过公网访问DTS订阅通道。
数据订阅任务源库RDS主备切换或主库重启时,是否会影响业务?
RDS MySQL、RDS PostgreSQL、PolarDB MySQL、PolarDB PostgreSQL和PolarDB-X 1.0(存储类型为RDS MySQL)实例发生主备切换或重启时,DTS都会自适应切换,业务不会受到影响。
RDS是否有可以实现自动的Binlog下载,下载到本地服务器?
DTS的数据订阅支持RDS Binlog日志的实时订阅,可以开通DTS的数据订阅服务,通过DTS的SDK订阅RDS Binlog数据并实时同步到本地服务器中。
数据订阅的实时增量数据,是只指新增数据,还是包含修改的数据?
DTS的数据订阅可以订阅的增量数据包括:所有的增删改以及结构变更(DDL)。
数据订阅任务消费端有一条记录没有ACK,SDK重启后为什么会收到重复数据?
当SDK有message没有ACK时,服务端会将buffer里的所有消息推送完成,当推送完后,SDK不能再接收到消息。此时,服务端保存的消费位点为未ACK之前的最后一条message的位点。当SDK重启时,为了保证消息不丢,服务端会从未ACK前一条message对应的位点开始重新推送数据,所以SDK此时会重复收取一部分消息。
数据订阅消费位点多久更新一次,为什么重启SDK时,有时候会重复接收数据?
数据订阅SDK消费完每条message,必须调用ackAsConsumed向服务端回复ACK。服务端接收到ACK后,会更新内存中的消费位点,然后每间隔10秒持久化一次消费位点。在最新ACK未持久化时重启SDK,为保证消息不丢失,服务端会从上一个持久化的消费位点开始推送消息,此时SDK会收到重复消息。
一个数据订阅实例,可以订阅多个RDS实例吗?
不可以,当前一个数据订阅实例只能订阅一个RDS实例。
数据订阅实例会出现数据不一致么?
不会,数据订阅任务只获取源库的变更,不涉及数据不一致。若客户端消费的数据与您期望的不一致,请自行排查。
消费订阅数据时出现UserRecordGenerator如何处理?
当消费订阅数据时,若出现如UserRecordGenerator: haven't receive records from generator for 5s的信息,你需要检查消费的位点是否在增量数据采集模块的位点范围内,并确保消费端正常运行。
一个Topic是否支持创建多个partition?
不支持。DTS为了保证消息的全局有序,每个订阅Topic只有一个partition,且固定分配至partition 0中。
数据订阅的SDK是否支持Go语言?
支持,示例代码请参见dts-subscribe-demo。
数据订阅的SDK是否支持Python语言?
支持,示例代码请参见dts-subscribe-demo。
flink-dts-connector是否支持多线程并发消费订阅数据?
不支持。
其他问题
数据同步或迁移任务运行时,修改目标库数据会有什么影响?
目标库修改数据有可能导致DTS任务失败。数据迁移或同步过程中,如果对目标库待迁移或同步的对象执行操作,可能会导致主键冲突,无更新记录等情况,最终DTS任务失败。但是可以执行不会导致DTS任务中断的操作,比如在目标实例创建一个表并执行写入,因为不在该表迁移或同步对象表中,因此不会引导致DTS失败。
由于DTS是读取源实例数据库信息,将其全量数据、结构数据、增量数据迁移或同步到目标实例中,因此任务进行时目标库修改数据可能会被来自源库迁移或同步的数据覆盖。
DTS实例运行中,如果修改源库或目标库的密码会如何?
DTS实例会报错中断。您可以单击实例ID进入实例详情,在基本信息页签中修改源端或目标端的账号密码。然后进入任务管理页签报错的实例进展模块,在基本信息中重启该模块。
为什么有的源库或目标库的接入方式没有公网IP?
与源库或目标库的接入方式、任务类型和数据库类型有关,例如对于MySQL数据库类型的源端,迁移和订阅任务可以选择公网IP接入,而同步任务是不支持公网IP接入。
是否支持跨账号的数据迁移或数据同步?
支持。配置方式,请参见跨阿里云账号实现数据传输。
为什么Redis为目标库的任务会报错OOM command not allowed when used memory > 'maxmemory'?
可能是因为目标Redis实例的存储空间不足。若目标Redis实例的架构类型为集群版,也可能是某一个分片达到了内存上限,您需要升级目标实例的规格。
如何咨询DTS相关的问题?
您可以通过钉钉(钉钉通讯客户端下载地址)进入到DTS客户交流钉钉群(群号:68325004196或68640008972),进行咨询。
AliyunDTSRolePolicy权限策略是什么,有什么用?
AliyunDTSRolePolicy策略用于当前账号或跨账号访问云账号下的RDS、ECS等云资源,在执行数据迁移、同步或订阅任务的配置时可调用相关云资源信息。更多信息,请参见授予DTS访问云资源的权限。
如何进行RAM角色授权?
在您首次登录控制台时,DTS会要求您授权AliyunDTSDefaultRole角色,请根据控制台提示跳转到RAM授权页面进行授权。更多信息,请参见授予DTS访问云资源的权限。
您需要使用阿里云账号(主账号)登录控制台进行操作。
DTS任务填写的账号密码可以修改吗?
DTS任务填写的数据库账号密码支持修改,您可以单击实例ID进入实例详情,在基本信息页签中单击修改密码修改源端或目标端的账号密码。
DTS任务的系统账号密码不支持修改。
MaxCompute表为什么有base后缀?
结构初始化。
DTS将源库中待同步表的结构定义信息同步至MaxCompute中,初始化时DTS会为表名增加_base后缀。例如源表为customer,那么MaxCompute中的表即为customer_base。
全量数据初始化。
DTS将源库中待同步表的存量数据,全部同步至MaxCompute中的目标表名_base表中(例如从源库的customer表同步至MaxCompute的customer_base表),作为后续增量同步数据的基线数据。
说明该表也被称为全量基线表。
增量数据同步。
DTS在MaxCompute中创建一个增量日志表,表名为同步的目标表名_log,例如customer_log,然后将源库产生的增量数据实时同步到该表中。
说明关于增量日志表结构的详细信息,请参见增量日志表结构定义说明。
获取不到Kafka的topic,如何处理?
可能是当前配置的Kafka Broker没有topic信息,请参考如下命令检查topic的Broker分布情况:
./bin/kafka-topics.sh --describe --zookeeper zk01:2181/kafka --topic topic_name是否可以在本地搭建一个MySQL实例,作为RDS实例的从库?
可以,您可以使用数据传输服务DTS的数据迁移功能,配置RDS到本地自建MySQL实例的数据实时同步,实现主从架构。
如何将RDS实例的数据复制到新创建的RDS实例中?
可以使用DTS数据迁移功能,迁移任务的迁移类型选择库表结构迁移、全量迁移、增量迁移。配置方法,请参见RDS实例间的数据迁移。
DTS是否支持在一个RDS实例中,复制出一个除库名外一样的数据库?
支持,DTS提供的对象名映射功能,可以实现在一个RDS实例内复制出一个除库名外一样的数据库。
DTS实例总是显示延迟,如何处理?
可能原因如下:
源端数据库实例使用不同账号创建了多个DTS任务,导致实例的负载过高,请使用同一个账号创建任务。
目标端数据库实例的内存不足,请做好业务安排后重启目标库实例。若无法解决问题,请升级目标端实例规格或进行主备切换。
说明主备切换过程中可能导致网络闪断,请确保您的应用程序具有自动重连机制。
在旧版控制台同步或迁移到目标库后字段都是小写,如何处理?
请使用新版控制台配置任务,并使用目标库对象名称大小写策略功能。更多信息,请参见目标库对象名称大小写策略。
DTS任务暂停后还能恢复么?
一般情况下,暂停时间不超过24小时的DTS任务可以正常恢复;若数据量较小,则暂停时间不超过7天的DTS任务可以正常恢复。建议暂停时间不要超过6小时。
为什么任务暂停后重启,进度会从0开始?
任务重启后,DTS会重新查询已经完成的数据,然后继续处理剩余数据。在此过程中,任务进度可能会由于延迟而和实际有差异。
DDL无锁变更的原理是什么?
DDL无锁变更的主要原理,请参见主要原理。
DTS是否支持暂停某个表的同步或迁移?
不支持。
如果任务失败需要重新购买吗?
不需要,可以在原任务上重新配置。
多个任务都往同一个目标写数据会怎么样?
可能会导致数据不一致。
为什么实例续费后仍然是锁定状态?
续费锁定的DTS实例后,需要一段时间实例才可以解锁,请耐心等待。
DTS实例是否支持修改资源组?
支持。您可以进入实例的基本信息页面,在基本信息区域单击资源组名称后的修改进行变更。
DTS是否有Binlog分析工具?
DTS没有Binlog分析工具。
增量任务一直显示95%,是否正常?
正常。增量任务是持续进行、不会完成的,进度不会到100%。
为什么DTS任务超过7天还没被释放?
偶尔会有冻结的任务保存时间超过七天的情况。
已创建好的任务是否支持修改端口?
不支持。
DTS任务中的PolarDB-X 1.0下面挂载的RDS MySQL是否可以降配?
不建议降配,降配会触发主备切换,可能会导致数据丢失。
DTS任务运行期间,源或目标端实例是否可以升配或降配?
DTS任务运行期间,源或目标端实例升配或降配,可能会导致任务延迟或数据丢失,不建议对源或目标端实例变配。
DTS任务对源端和目标端实例有什么影响?
全量数据初始化时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,建议在业务低峰期执行全量任务。
DTS任务的延迟大概是多少?
DTS任务延迟时间无法估算,因为延迟受限于源实例的运行负载、传输网络的带宽、网络延时、目标实例写入性能等多种因素的影响。
若数据传输控制台自动跳转至数据管理DMS控制台,如何返回旧版数据传输控制台?
您可以在数据管理DMS控制台右下角的 中单击
中单击 ,返回至旧版数据传输控制台。
,返回至旧版数据传输控制台。
DTS是否支持数据加密功能?
DTS支持通过SSL加密连接安全地访问源库或目标库,以便从源库读取数据或在目标库中写入数据,但不支持在数据传输过程中进行数据传输加密。
DTS是否支持ClickHouse为源或目标?
不支持。
DTS是否支持云原生数据仓库 AnalyticDB MySQL 版 2.0为源或目标?
云原生数据仓库 AnalyticDB MySQL 版 2.0仅支持作为目标端,且以云原生数据仓库 AnalyticDB MySQL 版 2.0为目标的方案暂未上线新版控制台,目前仅支持在旧版控制台配置。
为什么在控制台上看不见新创建的任务?
可能是您选择的任务列表不正确,或者对任务进行了筛选。请在相应任务列表选择正确的筛选项,如在相应的任务列表选择正确的地域和资源组等。
数据校验任务出现数据不一致的原因有什么?
常见原因如下:
迁移或同步任务有延迟。
源库执行有默认值的加列操作,且任务有延迟。
目标库有除DTS以外的数据写入。
开启了多表归并功能的任务源库执行了DDL操作。
迁移或同步任务使用了库表列名映射功能。
已创建的任务置灰的配置项是否支持修改?
不支持。
DTS是否支持云原生数据仓库 AnalyticDB MySQL 版 5.0版?
支持,云原生数据仓库 AnalyticDB MySQL 版 5.0版即为云原生数据仓库 AnalyticDB MySQL 版 湖仓版(3.0)。
如何配置延迟告警及阈值?
DTS提供了监控报警功能,您可以通过控制台对重要的监控指标设置报警规则,让您及时了解运行状态。配置方法,请参见配置监控告警。
失败时间较长的任务,能否查看失败的原因?
不可以。若任务失败的时间较长(如失败超过7天),相关日志会被清除,从而无法查看失败的原因。
失败时间较长的任务,能否恢复?
不可以。若任务失败的时间较长(如失败超过7天),相关日志会被清除而无法恢复,您需要重新配置任务。
rdsdt_dtsacct是什么账号?
若您未创建rdsdt_dtsacct账号,则该账号可能是由DTS创建的。DTS会在部分数据库实例中创建内置账号rdsdt_dtsacct,用于连接源和目标数据库实例。
如何查看SQL Server中堆表、无主键表、压缩表、含计算列的表信息?
您可以执行如下SQL检查源库是否存在这些场景的表:
检查源库堆表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.indexes WHERE index_id = 0);检查无主键表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id NOT IN (SELECT parent_object_id FROM sys.objects WHERE type = 'PK');检查源库聚集索引列不包含的主键列信息:
SELECT s.name schema_name, t.name table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id WHERE t.type = 'U' AND s.name NOT IN('cdc', 'sys') AND t.name NOT IN('systranschemas') AND t.object_id IN ( SELECT pk_colums_counter.object_id AS object_id FROM (select pk_colums.object_id, sum(pk_colums.column_id) column_id_counter from (select sic.object_id object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id = sis.object_id AND sic.index_id = sis.index_id AND sis.is_primary_key = 'true') pk_colums group by object_id) pk_colums_counter inner JOIN ( select cluster_colums.object_id, sum(cluster_colums.column_id) column_id_counter from (SELECT sic.object_id object_id, sic.column_id FROM sys.index_columns sic, sys.indexes sis WHERE sic.object_id = sis.object_id AND sic.index_id = sis.index_id AND sis.index_id = 1) cluster_colums group by object_id ) cluster_colums_counter ON pk_colums_counter.object_id = cluster_colums_counter.object_id and pk_colums_counter.column_id_counter != cluster_colums_counter.column_id_counter);检查源库压缩表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.objects t, sys.schemas s, sys.partitions p WHERE s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id = p.object_id AND p.data_compression != 0;检查包含计算列表信息:
SELECT s.name AS schema_name, t.name AS table_name FROM sys.schemas s INNER JOIN sys.tables t ON s.schema_id = t.schema_id AND t.type = 'U' AND s.name NOT IN ('cdc', 'sys') AND t.name NOT IN ('systranschemas') AND t.object_id IN (SELECT object_id FROM sys.columns WHERE is_computed = 1);
源和目标端的结构不一致如何处理?
您可以尝试使用映射功能,将源和目标端的列建立映射关系。更多信息,请参见库表列名映射。
不支持修改列的类型。
库表列映射是否支持修改列的类型?
不支持。
DTS是否支持限制源库的读取速度?
不支持,您需要在任务运行前评估源库的性能(如IOPS以及网络带宽是否满足要求),同时建议在业务低峰期运行任务。
如何清理MongoDB(分片集群架构)的孤立文档?
查看是否存在孤立文档
通过Mongo Shell连接MongoDB分片集群实例。
云数据库MongoDB的连接方法,请参见通过Mongo Shell连接MongoDB分片集群实例。
执行如下命令,切换至目标库。
use <db_name>执行如下命令,查看孤立文档信息。
db.<coll_name>.find().explain("executionStats")说明查看每个分片
executionStats中SHARDING_FILTER阶段(stage)的chunkSkips字段,如果不为0,则表示对应的分片上存在孤立文档。如下返回示例表示:在
SHARDING_FILTER阶段之前的FETCH阶段返回了102个文档("nReturned" : 102),然后在SHARDING_FILTER阶段过滤了2个孤立文档("chunkSkips" : 2),最终返回了100个文档("nReturned" : 100)。"stage" : "SHARDING_FILTER", "nReturned" : 100, ...... "chunkSkips" : 2, "inputStage" : { "stage" : "FETCH", "nReturned" : 102,关于
SHARDING_FILTER阶段的更多信息,请参见MongoDB Manual。
清理孤立文档
如果您有多个数据库,需清理每个数据库的孤立文档。
云数据库 MongoDB 版
MongoDB 4.2以下大版本或4.0.6以下小版本的实例在执行清理脚本时会报错。如何查看实例当前版本,请参见MongoDB小版本说明。如何升级小版本和大版本,请参见升级数据库大版本和升级数据库小版本。
清理孤立文档需要使用cleanupOrphaned命令。在MongoDB 4.4及以上版本和MongoDB 4.2及以下版本中的使用方法略有区别,具体操作方式如下。
MongoDB 4.4及以上版本
在可以连接分片集群实例的服务器上,创建一个用于清理孤立文档的JS脚本,脚本名称为
cleanupOrphaned.js。说明该脚本用于清理多个Shard节点的多个数据库中所有集合的孤立文档。如需清理特定集合中的孤立文档,可自行修改JS脚本来完成。
// shard实例名称列表 var shardNames = ["shardName1", "shardName2"]; // 数据库列表 var databasesToProcess = ["database1", "database2", "database3"]; shardNames.forEach(function(shardName) { // 遍历指定的数据库列表 databasesToProcess.forEach(function(dbName) { var dbInstance = db.getSiblingDB(dbName); // 获取该数据库实例的所有集合名称 var collectionNames = dbInstance.getCollectionNames(); // 遍历每个集合 collectionNames.forEach(function(collectionName) { // 完整的集合名称 var fullCollectionName = dbName + "." + collectionName; // 构建 cleanupOrphaned 命令 var command = { runCommandOnShard: shardName, command: { cleanupOrphaned: fullCollectionName } }; // 执行命令 var result = db.adminCommand(command); if (result.ok) { print("Cleaned up orphaned documents for collection " + fullCollectionName + " on shard " + shardName); printjson(result); } else { print("Failed to clean up orphaned documents for collection " + fullCollectionName + " on shard " + shardName); } }); }); });您需要对脚本中的
shardNames和databasesToProcess参数的值进行修改,具体说明如下:shardNames:分片集群实例中待清理孤立文档的Shard节点的ID数组,您可以在实例基本信息页面的Shard列表区域获取,例如d-bp15a3796d3a****。databasesToProcess:待清理孤立文档的数据库名称数组。
在
cleanupOrphaned.js脚本所在的目录下,执行以下命令清理孤立文档。mongo --host <Mongoshost> --port <Primaryport> --authenticationDatabase <database> -u <username> -p <password> cleanupOrphaned.js > output.txt参数说明如下。
参数
说明
<Mongoshost>分片集群实例Mongos节点的连接地址,格式为
s-bp14423a2a51****.mongodb.rds.aliyuncs.com。<Primaryport>分片集群实例Mongos节点的端口号,默认为3717。
<database>鉴权数据库名,即数据库账号所属的数据库。
<username>数据库账号。
<password>数据库账号的密码。
output.txt执行结果保存到output文件中。
MongoDB 4.2及以下版本
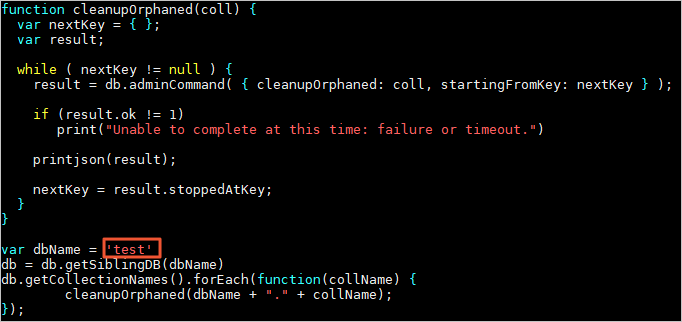
在可以连接分片集群实例的服务器上,创建一个用于清理孤立文档的JS脚本,脚本名称为
cleanupOrphaned.js。说明该脚本用于清理多个Shard节点中指定数据库下指定集合的孤立文档。如需清理数据库中多个集合的孤立文档,您可以修改
fullCollectionName参数并多次执行,也可以自行修改脚本通过遍历的方式执行。function cleanupOrphanedOnShard(shardName, fullCollectionName) { var nextKey = { }; var result; while ( nextKey != null ) { var command = { runCommandOnShard: shardName, command: { cleanupOrphaned: fullCollectionName, startingFromKey: nextKey } }; result = db.adminCommand(command); printjson(result); if (result.ok != 1 || !(result.results.hasOwnProperty(shardName)) || result.results[shardName].ok != 1 ) { print("Unable to complete at this time: failure or timeout.") break } nextKey = result.results[shardName].stoppedAtKey; } print("cleanupOrphaned done for coll: " + fullCollectionName + " on shard: " + shardName) } var shardNames = ["shardName1", "shardName2", "shardName3"] var fullCollectionName = "database.collection" shardNames.forEach(function(shardName) { cleanupOrphanedOnShard(shardName, fullCollectionName); });您需要对脚本中的
shardNames和fullCollectionName参数的值进行修改,具体说明如下:shardNames:分片集群实例中待清理孤立文档的Shard节点的ID数组,您可以在实例基本信息页面的Shard列表区域获取,例如d-bp15a3796d3a****。fullCollectionName:需要替换为待清理孤立文档的集合名称,格式为数据库名称.集合名称。
在
cleanupOrphaned.js脚本所在的目录下,执行以下命令清理孤立文档。mongo --host <Mongoshost> --port <Primaryport> --authenticationDatabase <database> -u <username> -p <password> cleanupOrphaned.js > output.txt参数说明如下。
参数
说明
<Mongoshost>分片集群实例Mongos节点的连接地址,格式为
s-bp14423a2a51****.mongodb.rds.aliyuncs.com。<Primaryport>分片集群实例Mongos节点的端口号,默认为3717。
<database>鉴权数据库名,即数据库账号所属的数据库。
<username>数据库账号。
<password>数据库账号的密码。
output.txt执行结果保存到output文件中。
自建MongoDB
在可以连接自建MongoDB数据库的服务器上下载cleanupOrphaned.js脚本文件。
wget "https://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/120562/cn_zh/1564451237979/cleanupOrphaned.js"修改cleanupOrphaned.js脚本文件,将
test替换为待清理孤立文档的数据库名。重要如果您有多个数据库,您需要重复执行步骤2~步骤3。
执行如下命令,清理Shard节点中指定数据库下所有集合的孤立文档。
说明您需要重复执行本步骤,为每个Shard节点清理孤立文档。
mongo --host <Shardhost> --port <Primaryport> --authenticationDatabase <database> -u <username> -p <password> cleanupOrphaned.js说明<Shardhost>:Shard节点的IP地址。
<Primaryport>:Shard节点中的Primary节点的服务端口。
<database>:鉴权数据库名,即数据库账号所属的数据库。
<username>:登录数据库的账号。
<password>:登录数据库的密码。
示例:
本案例的自建MongoDB数据库有三个Shard节点,所以需要分别为这三个节点清除孤立文档。
mongo --host 172.16.1.10 --port 27018 --authenticationDatabase admin -u dtstest -p 'Test123456' cleanupOrphaned.jsmongo --host 172.16.1.11 --port 27021 --authenticationDatabase admin -u dtstest -p 'Test123456' cleanupOrphaned.jsmongo --host 172.16.1.12 --port 27024 --authenticationDatabase admin -u dtstest -p 'Test123456' cleanupOrphaned.js
异常处理
若孤立文档对应的namespace上存在idleCursors,则可能会导致清理过程一直无法完成,且在对应孤立文档的mongod日志中存在如下信息:
Deletion of DATABASE.COLLECTION range [{ KEY: VALUE1 }, { KEY: VALUE2 }) will be scheduled after all possibly dependent queries finish您可以通过Mongo Shell连接mongod并执行如下命令,可以查看当前分片上是否存在idleCursors。如果存在,则需要通过restart mongod或者killCursors命令清理所有idleCursors后,重新清理孤立文档。更多信息,请参见JIRA ticket。
db.getSiblingDB("admin").aggregate( [{ $currentOp : { allUsers: true, idleCursors: true } },{ $match : { type: "idleCursor" } }] )如何处理分片集群架构的MongoDB数据分布不均衡?
启用Balancer功能并进行预分片,可以有效解决大部分数据都写入到单个分片上(数据倾斜)的问题。
开启Balancer
如果Balancer处于关闭状态,或者还未达到Balancer窗口设置的时间段,您可以开启或者临时取消Balancer的窗口期,以立即开始数据均衡。
连接MongoDB分片集群实例。
在mongos节点命令窗口中,切换至config数据库。
use config根据实际情况,执行如下命令。
开启Balancer功能
sh.setBalancerState(true)临时取消Balancer的窗口期
db.settings.updateOne( { _id : "balancer" }, { $unset : { activeWindow : true } } )
预分片
MongoDB支持范围分片和哈希分片两种分片方式,预分片可以使Chunk(块)的取值尽可能分散到多个Shard节点中,从而在DTS数据同步或迁移过程中实现负载尽可能均衡。
哈希分片
使用numInitialChunks参数,方便快捷地实现预分片。取值默认为分片数×2,最大可以设置为分片数×8192。更多信息,请参见sh.shardCollection()。
sh.shardCollection("phonebook.contacts", { last_name: "hashed" }, false, {numInitialChunks: 16384})范围分片
如果源MongoDB也是分片集群架构,则可以通过
config.chunks中的数据来获取源MongoDB对应分片表的Chunk范围,并作为后续预分片命令中<split_value>的取值参考。如果源MongoDB是副本集,则只能通过
find命令明确分片键的具体范围,然后再设计合理的分裂点。# 获得片键的最小值 db.<coll>.find().sort({<shardKey>:1}).limit(1) # 获得片键的最大值 db.<coll>.find().sort({<shardKey>:-1).limit(1)
命令格式
以splitAt命令为例,更多信息,请参见sh.splitAt()、sh.splitFind()、Split Chunks in a Sharded Cluster。
sh.splitAt("<db>.<coll>", {"<shardKey>":<split_value>})示例语句
sh.splitAt("test.test", {"id":0})
sh.splitAt("test.test", {"id":50000})
sh.splitAt("test.test", {"id":75000})在完成预分片的操作后,您可以在mongos节点执行sh.status()命令确认预分片的效果。
如何在控制台的任务列表设置每页显示实例的条数?
本操作以同步实例为例,进行介绍。
进入目标地域的同步任务列表页面(二选一)。
通过DTS控制台进入
登录数据传输服务DTS控制台。
在左侧导航栏,单击数据同步。
在页面左上角,选择同步实例所属地域。
通过DMS控制台进入
说明实际操作可能会因DMS的模式和布局不同,而有所差异。更多信息,请参见极简模式控制台和自定义DMS界面布局与样式。
登录DMS数据管理服务。
在顶部菜单栏中,选择。
在同步任务右侧,选择同步实例所属地域。
在页面右侧,将滚动条拖动到页面底部。
在页面的右下角,选择每页显示。
说明每页显示仅支持选择为10、20或50。
DTS实例提示ZooKeeper连接超时如何处理?
请尝试重启实例,查看实例是否可以恢复。重启操作,请参见启动DTS实例。
若异常无法解决,请通过钉钉(钉钉通讯客户端下载地址)进入到DTS客户交流钉钉群(群号:68325004196或68640008972),进行咨询。
在CEN中删除DTS网段后,为何会自动重新添加回来?
可能是因为您使用了云企业网CEN的基础版转发路由器,将数据库接入到DTS。若您使用该数据库创建DTS实例,即使在CEN中删除DTS网段,DTS也会自动将服务器的IP地址段添加到相应的路由器中。
DTS任务是否支持导出?
不支持。
如何使用Java语言调用OpenAPI?
Java语言调用OpenAPI的方法与Python语言类似,请参见Python调用SDK示例。您可以进入数据传输服务DTS SDK页面,在所有语言选择目标编程语言后,查看示例代码。
如何使用API给同步或迁移任务配置ETL功能?
您可以在API接口的预留参数Reserve中,通过公共参数(如etlOperatorCtl和etlOperatorSetting)进行配置。更多信息,请参见ConfigureDtsJob和Reserve参数说明。
DTS是否支持Azure SQL Database?
支持。Azure SQL Database作为源库时,SQLServer增量同步模式需选择轮询查询CDC实例做增量同步。
DTS同步或迁移结束后,源库数据是否会被保留?
是,DTS不会删除源库的数据。若您无需保留源库中的数据,请自行删除。
如何打开阿里云AI助理咨询DTS功能?
您可以在任务列表页面上方,单击DTS功能AI咨询进入阿里云AI助理对话框。

DTS是否支持按时间段抽样同步或迁移数据?
不支持。
DTS是否支持自动扩缩容?
DTS Serverless实例能够自动调整实例资源,从而实现自动扩缩容的功能。更多信息,请参见什么是DTS Serverless实例。
公共云是否支持TDDL?
不支持。若您待同步或迁移的数据配置了TDDL规则,可能会导致任务失败。