
本方案通过结合HBase Snapshot和HBase Replication技术,在源端HBase集群不停服的情况下,实现存量数据和增量数据的在线迁移,确保迁移过程中数据无丢失。
方案介绍
在HBase数据迁移过程中,传统基于Snapshot的方式仅支持离线迁移,无法满足源集群不停服的需求。由于迁移期间源端集群仍然在运行,可能会导致以下问题:
增量数据丢失:在Snapshot导出和恢复的过程中,源集群产生的写入或更新操作可能无法同步到目标集群。
数据一致性难以保障:单纯依赖Snapshot无法处理迁移过程中的实时增量数据。
为解决上述问题,提出以下在线迁移方案:
建立复制关系(Peer):
使用HBase Replication功能,在源集群和目标集群之间建立表级别的复制关系,并暂时关闭自动同步功能。
源集群会记录针对表的实时写入和变更操作,但不会立即将其同步到目标集群。
迁移存量数据:
利用HBase Snapshot导出源集群的存量数据。
如果源集群和目标集群的存储系统(如HDFS或OSS-HDFS)互通,则直接将Snapshot导出到目标集群;否则,需先导出到源集群的中间路径,再同步到目标集群。
同步增量数据:存量数据恢复完成后,开启Replication Peer的自动同步功能,回放迁移期间产生的增量数据,确保源端和目标端的数据一致性。
通过上述步骤,本方案在保证源集群服务持续运行的同时,完整迁移存量和增量数据,避免数据丢失。
注意事项
HBase版本兼容性:
HBase 1.x版本:需设置
hbase.replication=true,并重启主备集群以启用Replication功能。HBase 2.x版本:默认已移除
hbase.replication参数,无需额外设置。
Replication配置:HBase是以列族为单位设置是否启用Replication。如果需要迁移特定列族的数据,请确保相关列族已正确配置Replication属性。
网络连通性:
通过CEN(云企业网)、专线或VPN等方式,确保源HBase集群与目标HBase集群之间的网络互通。
提前打通源集群和目标集群的网络连接,确保以下端口对源集群开放:
Zookeeper服务端口:目标集群Zookeeper所在ECS实例的
2181端口。HBase服务端口:目标集群EMR HBase所在ECS实例的
16010、16020和16030端口。
操作流程
步骤一:创建Peer(复制关系)
在源集群和目标集群之间建立表级别的复制关系,并暂时关闭自动同步功能,待完成存量Snapshot数据的同步之后再开启自动同步。
登录源集群的Master节点,详情请参见登录集群。
执行以下命令,进入HBase Shell。
hbase shell添加Peer(复制关系)。
在HBase Shell中执行以下命令,为目标集群添加一个Peer(复制关系),并指定待迁移的表。
add_peer '${peer_name}', CLUSTER_KEY => "${slave_zk}:${port}:/hbase", TABLE_CFS => { "${table_name}" => [] }涉及参数如下:
${peer_name}:复制关系名称,您可以自定义。本文示例为peer1。${slave_zk}:目标集群ZooKeeper的地址。通常是多个ZooKeeper节点的内网IP地址或主机名,格式为{slave_zk1}:2181,{slave_zk2}:2181,{slave_zk3}:2181。${port}:目标集群ZooKeeper的端口,默认端口为2181。${table_name}:待迁移的表名。本文示例为t1。
启用表级复制。
启用表级复制功能,确保指定的表能够将写入的数据同步到目标集群。
enable_table_replication 't1'暂时关闭自动同步。
该命令用于暂停指定对等体的数据复制过程。禁用后,源集群将不再向目标集群发送新的数据变更,但已有的数据不会被删除或影响。
disable_peer 'peer1'
步骤二:创建Snapshot
在源集群的HBase Shell中,执行以下命令为待迁移的表创建Snapshot,用于导出存量数据。
snapshot '${table_name}', '${snapshot_name}'涉及参数如下:
${table_name}:待迁移的表名。本文示例为t1。${snapshot_name}:自定义的Snapshot名称。本文示例为t1-snapshot。
示例如下所示。
snapshot 't1', 't1-snapshot'
步骤三:导出Snapshot到目标集群
场景1:源集群与目标集群的存储系统互通
如果源集群和目标集群的存储系统互通,则可以在源集群执行以下命令,直接导出Snapshot到目标集群。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot ${snapshot_name} -copy-to ${target_rootdir_path}涉及参数如下:
${snapshot_name}:自定义的Snapshot名称。本文示例为t1-snapshot。${target_rootdir_path}:目标集群HBase的根目录路径,请根据实际情况替换。OSS-HDFS:您可以通过控制台,在目标集群的HBase服务中,查看hbase-site.xml文件的hbase.rootdir配置项,获取详细的路径信息。
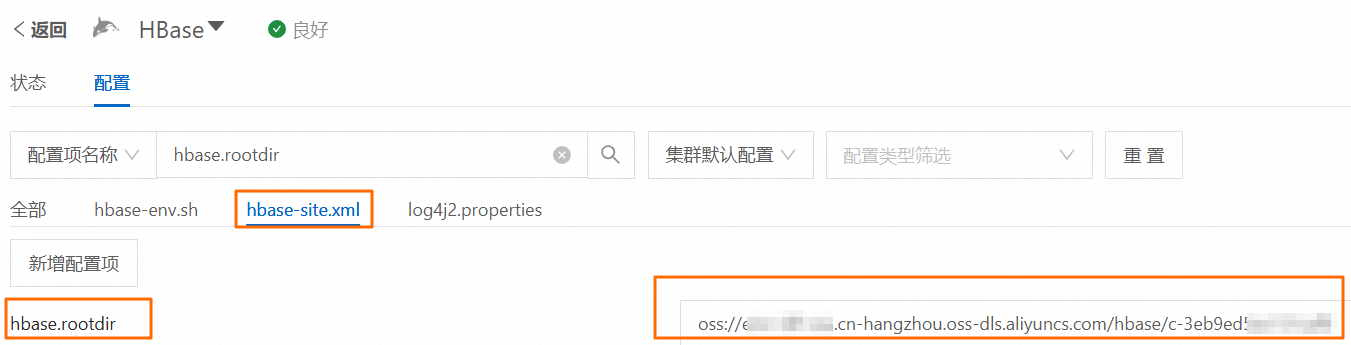
HDFS:您可以通过控制台,在目标集群的Hadoop-Common服务中,查看core-site.xml中的fs.defaultFS配置项,获取详细的路径信息。
示例如下所示。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot t1-snapshot -copy-to oss://xxx.cn-hangzhou.oss-dls.aliyuncs.com/hbase/c-9d34bc8fxxx
场景2:源集群与目标集群的存储系统不互通
如果源集群无法直接访问目标集群的存储路径,则需要先将Snapshot导出到源集群的中间路径(如HDFS或OSS),然后再同步到目标集群。本文以将数据从HDFS迁移到OSS-HDFS为例。
导出Snapshot到中间路径。
在源HBase集群中执行以下命令,将Snapshot导出到源集群的中间路径。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot ${snapshot_name} -copy-to ${src_temp_path}/${table_name}涉及参数如下:
${snapshot_name}:自定义的Snapshot名称。本文示例为t1-snapshot。${src_temp_path}:源集群的中间路径。例如,本文源集群使用的是HDFS,则可以选择一个HDFS路径作为中间路径。${table_name}:待迁移的表名。本文示例为t1。
示例如下所示。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot t1-snapshot -copy-to hdfs:///tmp/hbase-snapshot/t1
迁移数据到目标路径。
执行以下命令,使用JindoDistCp工具将数据从源集群的中间路径迁移到目标集群的路径。关于JindoDistCp的更多介绍,请参见JindoDistCp使用说明。
在EMR控制台配置OSS/OSS-HDFS的AccessKey。
在Hadoop-Common服务的core-site.xml页签,新增以下配置项,以避免使用时多次填写的问题。新增配置项的具体操作,请参见管理配置项。
参数
说明
fs.oss.accessKeyId
OSS/OSS-HDFS的AccessKey ID。
fs.oss.accessKeySecret
OSS/OSS-HDFS的AccessKey Secret。
在源HBase集群中,进入
jindo-distcp-tool-*.jar所在的目录。cd /opt/apps/JINDOSDK/jindosdk-current/tools说明EMR集群:EMR-5.6.0及以上版本、EMR-3.40.0及以上版本的集群已部署JindoDistCp,可在
/opt/apps/JINDOSDK/jindosdk-current/tools目录下找到jindo-distcp-tool-*.jar。非EMR集群:您可以自行下载JindoSDK(其中包含JindoDistCp工具),详情请参见JindoSDK下载安装和升级。
执行以下命令,将Snapshot迁移至目标HBase集群。
hadoop jar jindo-distcp-tool-*.jar --src ${src_temp_path}/${table_name} --dest ${target_temp_path}/${table_name} --disableChecksum --parallelism 10涉及参数如下:
${src_temp_path}:源集群的中间路径。${target_temp_path}:目标集群的中间路径。${target_bucket}:目标Bucket名称。
示例如下所示。
hadoop jar jindo-distcp-tool-4.6.11.jar --src hdfs:///tmp/hbase-snapshot/t1 --dest oss://hbase-test.cn-hangzhou.oss-dls.aliyuncs.com/hbase/recv/t1 --disableChecksum --parallelism 10
将Snapshot导入目标HBase集群。
在目标HBase集群运行以下命令,将Snapshot从目标路径导入到HBase根目录。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot ${snapshot_name} -copy-from ${target_temp_path} -copy-to ${target_rootdir_path}涉及参数如下:
${target_temp_path}:目标集群的临时路径。${target_rootdir_path}:目标HBase集群的根目录路径。您可以通过控制台,在目标集群的HBase服务中,查看hbase-site.xml文件的hbase.rootdir配置项,获取详细的路径信息。
示例如下所示。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot t1-snapshot -copy-from oss://hbase-test.cn-hangzhou.oss-dls.aliyuncs.com/hbase/recv/t1 -copy-to oss://hbase-target.cn-hangzhou.oss-dls.aliyuncs.com/hbase/c-5418ce2a4xxx
检查迁移结果。
迁移完成后,可以通过以下命令检查目标路径下的数据是否完整。
hdfs dfs -ls ${target_rootdir_path}
步骤四:使用Snapshot恢复存量数据
登录目标集群的Master节点,详情请参见登录集群。
执行以下命令,进入HBase Shell。
hbase shell执行以下命令,在目标集群恢复Snapshot并启用表。
restore_snapshot '${snapshot_name}' enable '${table_name}'涉及参数如下:
${snapshot_name}:自定义的Snapshot名称。${table_name}:待迁移的表名。
示例如下所示。
restore_snapshot 't1-snapshot' enable 't1'
步骤五:开启增量数据同步
在源集群的HBase Shell中执行以下命令,开启Peer同步。
enable_peer '${peer_name}'示例如下所示。
enable_peer 'peer1'步骤六:验证数据
验证迁移后的数据是否完整。
小数据量场景:使用Scan验证。
scan '${table_name}'示例如下所示。
scan 't1'中等数据量场景:使用count验证。
count '${table_name}'大数据量场景:使用get抽样验证。
get '${table_name}', '${rowkey}'代码中的
${rowkey}为HBase表中每一行的唯一标识符。
步骤七:删除Snapshot
验证无误后,执行以下命令删除与目标表相关的所有快照,以释放存储空间。
delete_table_snapshots '${table_name}'示例如下所示。
delete_table_snapshots 't1'步骤八:清理Peer
在增量数据同步完成后,需进行应用的双写或割接操作,确保所有读写请求切换到目标HBase集群。为避免数据重复同步,在完成切换后需要删除源集群与目标集群之间的复制关系(Peer)。
客户端迁移。
将涉及HBase集群的上下游应用切换到目标HBase集群,包括通过API或命令行读写HBase的应用。具体操作如下:
更新连接配置:修改应用的配置文件或代码,将HBase连接信息(如Zookeeper地址、端口等)从源集群切换为目标集群。
验证功能:确保应用能够正常读写目标集群,并进行必要的功能测试和数据校验。
双跑或割接:根据业务需求,选择双跑(同时读写源和目标集群)或直接割接到目标集群。
禁用Peer的自动同步功能。
在源集群的HBase Shell中,禁用指定Peer的自动同步功能,确保数据同步立即停止。
disable_peer '${peer_name}'示例如下所示。
disable_peer 'peer1'删除Peer。
禁用Peer后,删除Peer以彻底断开源集群与目标集群之间的复制关系。
remove_peer '${peer_name}'示例如下所示。
remove_peer 'peer1'验证Peer是否删除成功。
执行以下命令,列出当前的所有Peer,确保本文示例中的
peer1已被成功删除。list_peers