
数据同步是指数仓或者数据湖内的数据与上游业务库内的数据保持同步的状态。当上游业务库内的数据发生变更之后,下游的数仓/数据湖立即感知到数据变化,并将数据变化同步过来。在数据库中,这类场景称为Change Data Capture(CDC)场景。
背景信息
CDC的实现方案比较多,但是大多是在数据库领域,相应的工具也比较多。在大数据领域,这方面的实践较少,也缺乏相应的标准和技术实现。通常您需要选择已有的引擎,利用它们的能力自己搭建一套CDC方案。常见的方案大概分为下面两类:
定期批量Merge方式:上游原始表捕获增量更新,将更新的数据输出到一个新的表中,下游仓库利用MERGE或UPSERT语法将增量表与已有表进行合并。这种方式要求表具有主键或者联合主键,且实时性也较差。另外,这种方法一般不能处理DELETE的数据,实际上用删除原表重新写入的方式支持了DELETE,但是相当于每次都重新写一次全量表,性能不可取,还需要有一个特殊字段来标记数据是否属于增量更新数据。
上游源表输出binlog(这里我们指广义的binlog,不限于MySQL),下游仓库进行binlog的回放。这种方案一般需要下游仓库能够具有实时回放的能力。但是可以将row的变化作为binlog输出,这样,只要下游具备INSERT、UPDATE、DELETE的能力就可以了。不同于第一种方案,这种方案可以和流式系统结合起来。binlog可以实时地流入注入Kafka的消息分发系统,下游仓库订阅相应的Topic,实时拉取并进行回放。
批量更新方式
此方案适用于没有Delete且实时性要求不高的场景。
建立一张MySQL表,插入一部分数据。
CREATE TABLE sales(id LONG, date DATE, name VARCHAR(32), sales DOUBLE, modified DATETIME); INSERT INTO sales VALUES (1, '2019-11-11', 'Robert', 323.00, '2019-11-11 12:00:05'), (2, '2019-11-11', 'Lee', 500.00, '2019-11-11 16:11:46'), (3, '2019-11-12', 'Robert', 136.00, '2019-11-12 10:23:54'), (4, '2019-11-13', 'Lee', 211.00, '2019-11-13 11:33:27'); SELECT * FROM sales;+------+------------+--------+-------+---------------------+ | id | date | name | sales | modified | +------+------------+--------+-------+---------------------+ | 1 | 2019-11-11 | Robert | 323 | 2019-11-11 12:00:05 | | 2 | 2019-11-11 | Lee | 500 | 2019-11-11 16:11:46 | | 3 | 2019-11-12 | Robert | 136 | 2019-11-12 10:23:54 | | 4 | 2019-11-13 | Lee | 211 | 2019-11-13 11:33:27 | +------+------------+--------+-------+---------------------+说明modified就是我们上文提到的用于标识数据是否属于增量更新数据的字段。将MySQL表的内容全量导出到HDFS。
sqoop import --connect jdbc:mysql://emr-header-1:3306/test --username root --password EMRroot1234 -table sales -m1 --target-dir /tmp/cdc/staging_sales hdfs dfs -ls /tmp/cdc/staging_sales Found 2 items -rw-r----- 2 hadoop hadoop 0 2019-11-26 10:58 /tmp/cdc/staging_sales/_SUCCESS -rw-r----- 2 hadoop hadoop 186 2019-11-26 10:58 /tmp/cdc/staging_sales/part-m-00000建立delta表,并导入MySQL表的全量数据。
执行以下命令,启动streaming-sql。
streaming-sql建立delta表。
-- `LOAD DATA INPATH`语法对delta table不可用,先建立一个临时外部表。 CREATE TABLE staging_sales (id LONG, date STRING, name STRING, sales DOUBLE, modified STRING) USING csv LOCATION '/tmp/cdc/staging_sales/'; CREATE TABLE sales USING delta LOCATION '/user/hive/warehouse/test.db/test' SELECT * FROM staging_sales; SELECT * FROM sales; 1 2019-11-11 Robert 323.0 2019-11-11 12:00:05.0 2 2019-11-11 Lee 500.0 2019-11-11 16:11:46.0 3 2019-11-12 Robert 136.0 2019-11-12 10:23:54.0 4 2019-11-13 Lee 211.0 2019-11-13 11:33:27.0 --删除临时表。 DROP TABLE staging_sales;切换到命令行删除临时目录。
hdfs dfs -rm -r -skipTrash /tmp/cdc/staging_sales/ # 删除临时目录。
在原MySQL表做一些操作,插入更新部分数据。
-- 注意DELETE的数据无法被Sqoop导出,因而没办法合并到目标表中 -- DELETE FROM sales WHERE id = 1; UPDATE sales SET name='Robert',modified=now() WHERE id = 2; INSERT INTO sales VALUES (5, '2019-11-14', 'Lee', 500.00, now()); SELECT * FROM sales;+------+------------+--------+-------+---------------------+ | id | date | name | sales | modified | +------+------------+--------+-------+---------------------+ | 1 | 2019-11-11 | Robert | 323 | 2019-11-11 12:00:05 | | 2 | 2019-11-11 | Robert | 500 | 2019-11-26 11:08:34 | | 3 | 2019-11-12 | Robert | 136 | 2019-11-12 10:23:54 | | 4 | 2019-11-13 | Lee | 211 | 2019-11-13 11:33:27 | | 5 | 2019-11-14 | Lee | 500 | 2019-11-26 11:08:38 | +------+------------+--------+-------+---------------------+sqoop导出更新数据。
sqoop import --connect jdbc:mysql://emr-header-1:3306/test --username root --password EMRroot1234 -table sales -m1 --target-dir /tmp/cdc/staging_sales --incremental lastmodified --check-column modified --last-value "2019-11-20 00:00:00" hdfs dfs -ls /tmp/cdc/staging_sales/ Found 2 items -rw-r----- 2 hadoop hadoop 0 2019-11-26 11:11 /tmp/cdc/staging_sales/_SUCCESS -rw-r----- 2 hadoop hadoop 93 2019-11-26 11:11 /tmp/cdc/staging_sales/part-m-00000为更新数据建立临时表,然后MERGE到目标表。
CREATE TABLE staging_sales (id LONG, date STRING, name STRING, sales DOUBLE, modified STRING) USING csv LOCATION '/tmp/cdc/staging_sales/'; MERGE INTO sales AS target USING staging_sales AS source ON target.id = source.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT *; SELECT * FROM sales; 1 2019-11-11 Robert 323.0 2019-11-11 12:00:05.0 3 2019-11-12 Robert 136.0 2019-11-12 10:23:54.0 2 2019-11-11 Robert 500.0 2019-11-26 11:08:34.0 5 2019-11-14 Lee 500.0 2019-11-26 11:08:38.0 4 2019-11-13 Lee 211.0 2019-11-13 11:33:27.0
实时同步
实时同步的方式对场景的限制没有第一种方式多,例如,DELETE数据也能处理,不需要修改业务模型增加一个额外字段。但是这种方式实现较为复杂,如果binlog的输出不标准的话,您还需要写专门的UDF来处理binlog数据。例如RDS MySQL输出的binlog,以及Log Service输出的binlog格式上就不相同。
在这个例子中,我们使用阿里云RDS MySQL版作为源库,使用阿里云DTS服务将源库的binlog数据实时导出到Kafka集群,您也可以选择开源的Maxwell或Canal等。 之后我们定期从Kafka读取binlog并存放到OSS或HDFS,然后用Spark读取该binlog并解析出Insert、Update、Delete的数据,最后用Delta的Merge API将源表的变动更新到Delta表,其链路如下图所示。
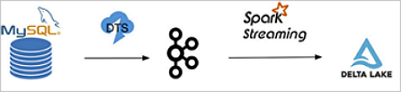
首先开通RDS MySQL服务,设置好相应的用户、Database和权限(RDS的具体使用请参见什么是RDS MySQL)。建立一张表并插入一些数据。
-- 该建表动作可以在RDS控制台页面方便地完成,这里展示最后的建表语句。 CREATE TABLE `sales` ( `id` bigint(20) NOT NULL, `date` date DEFAULT NULL, `name` varchar(32) DEFAULT NULL, `sales` double DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 -- 插入部分数据,并确认。 INSERT INTO sales VALUES (1, '2019-11-11', 'Robert', 323.00), (2, '2019-11-11', 'Lee', 500.00), (3, '2019-11-12', 'Robert', 136.00), (4, '2019-11-13', 'Lee', 211.00); SELECT * FROM `sales` ; ``` <img src="./img/rds_tbl.png" width = "400" alt="RDS Table" align=center />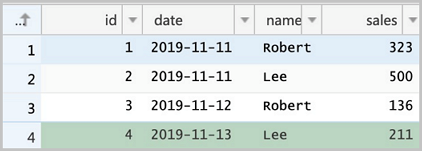
建立一个EMR Kafka集群(如果已有EMR Kafka集群的话请跳过),并在Kafka集群上创建一个名为sales的topic:
bash
kafka-topics.sh --create --bootstrap-server core-1-1:9092 --partitions 1 --replication-factor 1 --topic sales开通DTS服务(如果未开通的话),并创建一个同步任务,源库选择RDS MySQL,目标库选择Kafka。
配置DTS的同步链路,将RDS的sales table同步至Kafka,目标topic选择sales。正常的话,可以在Kafka的机器上看到数据。
编写Spark Streaming作业,从Kafka中解析binlog,利用Delta的MERGE API将binlog数据实时回放到目标Delta表。DTS导入到Kafka的binlog数据的样子如下,其每一条记录都表示了一条数据库数据的变更。 详情请参见附录:Kafka内binlog格式窥探。
|字段名称|值| |:--|:--| |recordid|1| |source|{"sourceType": "MySQL", "version": "0.0.0.0"}| |dbtable|delta_cdc.sales| |recordtype|INIT| |recordtimestamp|1970-01-01 08:00:00| |extratags|{}| |fields|["id","date","name","sales"]| |beforeimages|{}| |afterimages|{"sales":"323.0","date":"2019-11-11","name":"Robert","id":"1"}|说明这里最重要的字段是
recordtype、beforeimages、afterimages。其中recordtype是该行记录对应的动作,包含INIT、UPDATE、DELETE、INSERT几种。beforeimages为该动作执行前的内容,afterimages为动作执行后的内容。Scala
编写Spark代码。
以Scala版代码为例,代码示例如下。
import io.delta.tables._ import org.apache.spark.internal.Logging import org.apache.spark.sql.{AnalysisException, SparkSession} import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions._ import org.apache.spark.sql.types.{DataTypes, StructField} val schema = DataTypes.createStructType(Array[StructField]( DataTypes.createStructField("id", DataTypes.StringType, false), DataTypes.createStructField("date", DataTypes.StringType, true), DataTypes.createStructField("name", DataTypes.StringType, true), DataTypes.createStructField("sales", DataTypes.StringType, true) )) //初始化delta表中INIT类型的数据。 def initDeltaTable(): Unit = { spark.read .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("failOnDataLoss", value = false) .load() .createTempView("initData") // 对于DTS同步到Kafka的数据,需要avro解码,EMR提供了dts_binlog_parser的UDF来处理此问题。 val dataBatch = spark.sql( """ |SELECT dts_binlog_parser(value) |AS (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) |FROM initData """.stripMargin) // 选择INIT类型的数据作为初始数据。 dataBatch.select(from_json(col("afterImages").cast("string"), schema).as("jsonData")) .where("recordType = 'INIT'") .select( col("jsonData.id").cast("long").as("id"), col("jsonData.date").as("date"), col("jsonData.name").as("name"), col("jsonData.sales").cast("decimal(7,2)")).as("sales") .write.format("delta").mode("append").save("/delta/sales") } try { DeltaTable.forPath("/delta/sales") } catch { case e: AnalysisException if e.getMessage().contains("is not a Delta table") => initDeltaTable() } spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("startingOffsets", "earliest") .option("maxOffsetsPerTrigger", 1000) .option("failOnDataLoss", value = false) .load() .createTempView("incremental") // 对于DTS同步到Kafka的数据,需要avro解码,EMR提供了dts_binlog_parser的UDF来处理此问题。 val dataStream = spark.sql( """ |SELECT dts_binlog_parser(value) |AS (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) |FROM incremental """.stripMargin) val task = dataStream.writeStream .option("checkpointLocation", "/delta/sales_checkpoint") .foreachBatch( (ops, id) => { // 该window function用于提取针对某一记录的最新一条修改。 val windowSpec = Window .partitionBy(coalesce(col("before_id"), col("id"))) .orderBy(col("recordId").desc) // 从binlog中解析出recordType, beforeImages.id, afterImages.id, afterImages.date, afterImages.name, afterImages.sales。 val mergeDf = ops .select( col("recordId"), col("recordType"), from_json(col("beforeImages").cast("string"), schema).as("before"), from_json(col("afterImages").cast("string"), schema).as("after")) .where("recordType != 'INIT'") .select( col("recordId"), col("recordType"), when(col("recordType") === "INSERT", col("after.id")).otherwise(col("before.id")).cast("long").as("before_id"), when(col("recordType") === "DELETE", col("before.id")).otherwise(col("after.id")).cast("long").as("id"), when(col("recordType") === "DELETE", col("before.date")).otherwise(col("after.date")).as("date"), when(col("recordType") === "DELETE", col("before.name")).otherwise(col("after.name")).as("name"), when(col("recordType") === "DELETE", col("before.sales")).otherwise(col("after.sales")).cast("decimal(7,2)").as("sales") ) .select( dense_rank().over(windowSpec).as("rk"), col("recordType"), col("before_id"), col("id"), col("date"), col("name"), col("sales") ) .where("rk = 1") //merge条件,用于将incremental数据和delta表数据做合并。 val mergeCond = "target.id = source.before_id" DeltaTable.forPath(spark, "/delta/sales").as("target") .merge(mergeDf.as("source"), mergeCond) .whenMatched("source.recordType='UPDATE'") .updateExpr(Map( "id" -> "source.id", "date" -> "source.date", "name" -> "source.name", "sales" -> "source.sales")) .whenMatched("source.recordType='DELETE'") .delete() .whenNotMatched("source.recordType='INSERT' OR source.recordType='UPDATE'") .insertExpr(Map( "id" -> "source.id", "date" -> "source.date", "name" -> "source.name", "sales" -> "source.sales")) .execute() } ).start() task.awaitTermination()打包程序并部署到DataLake集群。
本地调试完成后,通过以下命令打包。
mvn clean install使用SSH方式登录DataLake集群,详情信息请参见登录集群。
上传JAR包至DataLake集群。
本示例是上传到DataLake集群的根目录下。
提交运行Spark作业。
执行以下命令,通过spark-submit提交Spark作业。
spark-submit \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 3g \ --num-executors 1 \ --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 \ --class com.aliyun.delta.StreamToDelta \ delta-demo-1.0.jar说明delta-demo-1.0.jar为您打包好的JAR包。--class和JAR包请根据您实际信息修改。
SQL
执行以下命令,进入streaming-sql客户端。
streaming-sql --master local执行以下SQL语句。
CREATE TABLE kafka_sales USING kafka OPTIONS( kafka.bootstrap.servers='192.168.XX.XX:9092', subscribe='sales' ); CREATE TABLE delta_sales(id long, date string, name string, sales decimal(7, 2)) USING delta LOCATION '/delta/sales'; INSERT INTO delta_sales SELECT CAST(jsonData.id AS LONG), jsonData.date, jsonData.name, jsonData.sales FROM ( SELECT from_json(CAST(afterImages as STRING), 'id STRING, date DATE, name STRING, sales STRING') as jsonData FROM ( SELECT dts_binlog_parser(value) AS (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) FROM kafka_sales ) binlog WHERE recordType='INIT' ) binlog_wo_init; CREATE SCAN incremental on kafka_sales USING STREAM OPTIONS( startingOffsets='earliest', maxOffsetsPerTrigger='1000', failOnDataLoss=false ); CREATE STREAM job OPTIONS( checkpointLocation='/delta/sales_checkpoint' ) MERGE INTO delta_sales as target USING ( SELECT recordId, recordType, before_id, id, date, name, sales FROM( SELECT recordId, recordType, CASE WHEN recordType = "INSERT" then after.id else before.id end as before_id, CASE WHEN recordType = "DELETE" then CAST(before.id as LONG) else CAST(after.id as LONG) end as id, CASE WHEN recordType = "DELETE" then before.date else after.date end as date, CASE WHEN recordType = "DELETE" then before.name else after.name end as name, CASE WHEN recordType = "DELETE" then CAST(before.sales as DECIMAL(7, 2)) else CAST(after.sales as DECIMAL(7, 2)) end as sales, dense_rank() OVER (PARTITION BY coalesce(before.id,after.id) ORDER BY recordId DESC) as rank FROM ( SELECT recordId, recordType, from_json(CAST(beforeImages as STRING), 'id STRING, date STRING, name STRING, sales STRING') as before, from_json(CAST(afterImages as STRING), 'id STRING, date STRING, name STRING, sales STRING') as after FROM ( select dts_binlog_parser(value) as (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) from incremental ) binlog WHERE recordType != 'INIT' ) binlog_wo_init ) binlog_extract WHERE rank=1 ) as source ON target.id = source.before_id WHEN MATCHED AND source.recordType='UPDATE' THEN UPDATE SET id=source.id, date=source.date, name=source.name, sales=source.sales WHEN MATCHED AND source.recordType='DELETE' THEN DELETE WHEN NOT MATCHED AND (source.recordType='INSERT' OR source.recordType='UPDATE') THEN INSERT (id, date, name, sales) values (source.id, source.date, source.name, source.sales);
待上一步骤中的Spark Streaming作业启动后,我们尝试读一下这个Delta Table。
执行以下命令,进入spark-shell客户端,并查询数据。
spark-shell --master localspark.read.format("delta").load("/delta/sales").show +---+----------+------+------+ | id| date| name| sales| +---+----------+------+------+ | 1|2019-11-11|Robert|323.00| | 2|2019-11-11| Lee|500.00| | 3|2019-11-12|Robert|136.00| | 4|2019-11-13| Lee|211.00| +---+----------+------+------+在RDS控制台执行下列四条命令并确认结果,注意我们对于
id = 2的记录update了两次,理论上最终结果应当为最新一次修改。DELETE FROM sales WHERE id = 1; UPDATE sales SET sales = 150 WHERE id = 2; UPDATE sales SET sales = 175 WHERE id = 2; INSERT INTO sales VALUES (5, '2019-11-14', 'Robert', 233); SELECT * FROM sales;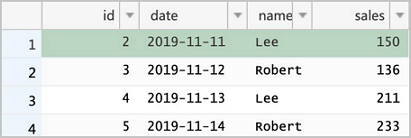
重新读一下Delta表,发现数据已经更新了,
且id=2的结果为最后一次的修改:spark.read.format("delta").load("/delta/sales").show +---+----------+------+------+ | id| date| name| sales| +---+----------+------+------+ | 5|2019-11-14|Robert|233.00| | 3|2019-11-12|Robert|136.00| | 4|2019-11-13| Lee|211.00| | 2|2019-11-11| Lee|175.00| +---+----------+------+------+
最佳实践
随着数据实时流入,Delta内的小文件会迅速增多。针对这种情况,有两种解决方案:
对表进行分区。一方面,写入多数情况下是针对最近的分区,历史分区修改往往频次不是很高,这个时候对历史分区进行compaction操作,compaction因事务冲突失败的可能性较低。另一方面,带有分区谓词的查询效率较不分区的情况会高很多。
在流式写入的过程中,定期进行compaction操作。例如,每过10个mini batch进行一次compaction。这种方式不存在compaction由于事务冲突失败的问题,但是由于compaction可能会影响到后续mini batch的时效性,因此采用这种方式要注意控制compaction的频次。
对于时效性要求不高的场景,又担心compation因事务冲突失败,可以采用如下所示处理。在这种方式中,binlog的数据被定期收集到OSS上(可以通过DTS到Kafka然后借助kafka-connect-oss将binlog定期收集到OSS,也可以采用其他工具),然后启动Spark批作业读取OSS上的binlog,一次性地将binlog合并到Delta Lake。其流程图如下所示。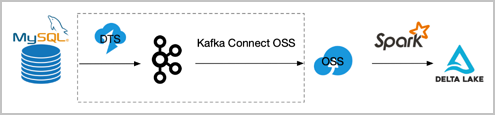
虚线部分可替换为其他可能方案。
附录:Kafka内binlog格式窥探
DTS同步到Kafka的binlog是avro编码的。如果要探查其文本形式,我们需要借助EMR提供的一个avro解析的UDF:dts_binlog_parser。
Scala
执行以下命令,进入spark-shell客户端。
spark-shell --master local执行以下Scala语句,查询数据。
spark.read .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("maxOffsetsPerTrigger", 1000) .load() .createTempView("kafkaData") val kafkaDF = spark.sql("SELECT dts_binlog_parser(value) FROM kafkaData") kafkaDF.show(false)
SQL
执行以下命令,进入streaming-sql客户端。
streaming-sql --master local执行以下SQL语句,建表并查询数据。
CREATE TABLE kafkaData USING kafka OPTIONS( kafka.bootstrap.servers='192.168.XX.XX:9092', subscribe='sales' ); SELECT dts_binlog_parser(value) FROM kafkaData;最终显示结果如下所示。
+--------+---------------------------------------------+---------------+----------+-------------------+---------+----------------------------+------------+--------------------------------------------------------------+ |recordid|source |dbtable |recordtype|recordtimestamp |extratags|fields |beforeimages|afterimages | +--------+---------------------------------------------+---------------+----------+-------------------+---------+----------------------------+------------+--------------------------------------------------------------+ |1 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"323.0","date":"2019-11-11","name":"Robert","id":"1"}| |2 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"500.0","date":"2019-11-11","name":"Lee","id":"2"} | |3 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"136.0","date":"2019-11-12","name":"Robert","id":"3"}| |4 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"211.0","date":"2019-11-13","name":"Lee","id":"4"} | +--------+---------------------------------------------+---------------+----------+-------------------+---------+----------------------------+------------+--------------------------------------------------------------+