本文介绍冷数据的特点和适应场景,通过表格存储Tablestore和Delta Lake结合示例,演示数据的冷热分层。冷热分层可以充分利用计算和存储资源,以低成本承载更优质服务。
背景信息
在海量大数据场景下,随着业务和数据量的不断增长,性能和成本的权衡成为大数据系统设计面临的关键挑战。
Delta Lake是新型数据湖方案,推出了数据流入、数据组织管理、数据查询和数据流出等特性,同时提供了数据的ACID和CRUD操作。通过结合Delta Lake和上下游组件,您可以搭建出一个便捷、易用、安全的数据湖架构。在数据湖架构设计中,通常会应用HTAP(Hybrid Transaction and Analytical Process)体系结构,通过合理地选择分层存储组件和计算引擎,既能支持海量数据分析和快速的事务更新写入,又能有效地降低冷热数据分离的成本。
更多介绍请参见结构化大数据分析平台设计、面向海量数据的极致成本优化-云HBase的一体化冷热分离和云上如何做冷热数据分离。
冷热数据
数据按照实际访问的频率可以分为热数据、温数据和冷数据。其中冷数据的数据量较大,很少被访问,甚至整个生命周期都不会被访问。
冷热数据的区分方式如下:
按照数据的创建时间:通常,数据写入初期,用户的关注度较高且访问频繁,此时的数据为热数据。但随着时间的推移,旧数据访问频率会越来越低,仅存在少量查询,甚至完全不查询,此时数据为冷数据。
常见于交易类数据、时序监控和IM聊天等场景。
按照访问热度:采用业务打标或系统自动识别等方式,按照数据的访问热度来区分冷热数据。
例如,某旧博客突然被大量访问。此时不应该按照时间区分,而是应该按照具体的业务和数据分布规律来区分冷热数据。
说明本文主要讨论按照数据创建时间的冷热数据分层。
冷数据特点
数据量大:相对于热数据,冷数据通常需要保存较长时间,甚至永久保存。
成本管控:数据量大且访问频率较低,不宜投入过多成本。
性能要求低:相较于普通的TP请求查询,无需在毫秒级别返回。冷数据的查询可以接受数十秒甚至更长时间返回结果,或者可以进行异步处理。
操作简单:通常,冷数据都是执行批量写入和删除操作,没有更新操作。
当查询数据时,您只需要读取指定条件的数据,且查询条件不会过于复杂。
适用场景
时序类数据场景:时序类数据天然具备时间属性,数据量大,且仅执行追加操作。示例如下:
IM场景:通常用户会查询最近若干条聊天记录,只有在特殊需求的时候才会查询历史数据。例如钉钉。
监控场景:通常用户只会查看近期的监控,只有在调查问题或者制定报表时才会查询历史数据。例如云监控。
账单场景:通常用户只会查询最近几天或者一个月内的账单,不会查询超过一年以上的账单。例如支付宝。
物联网场景:通常设备近期上报的数据是热点数据,会经常被分析,而历史数据的分析频率都较低。例如IoT。
归档类场景:对于读写简单,查询复杂的数据,您可以定期归档数据至成本更低的存储组件或更高压缩比的存储介质中,以达到降低成本的目的。
海量结构化数据Delta Lake架构
针对结构化冷热分层的数据场景,阿里巴巴集团推出了海量结构化数据的Delta Lake架构。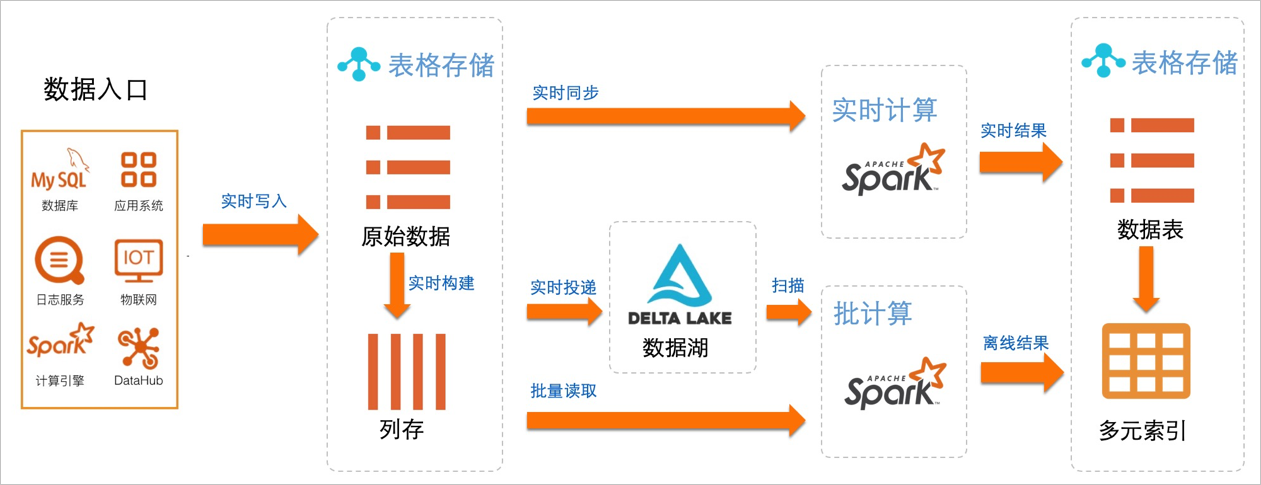
基于Tablestore的通道服务,原始数据可以利用变更数据捕获CDC(Change Data Capture)技术写入多种存储组件中。
示例
本示例结合Tablestore和Delta Lake,进行数据的冷热分层。
实时流式投递。
创建数据源表。
数据源表是原始订单表OrderSource,有两个主键UserId(用户ID)和OrderId(订单ID),两个属性列price(价格)和timestamp(订单时间)。使用Tablestore SDK的BatchWrite接口写入订单数据,订单的时间戳的时间范围为最近90天(本示例的模拟时间范围为2020-02-26~2020-05-26),共计写入3112400条。
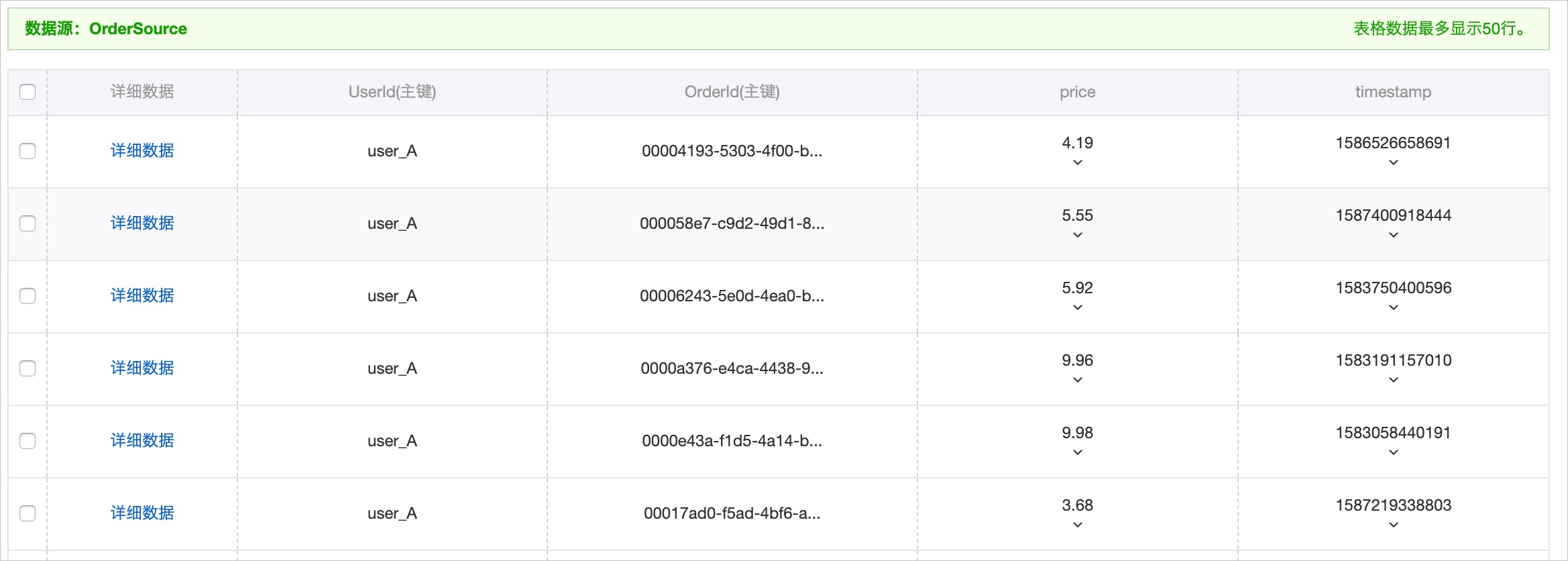
在模拟订单写入时,对应Tablestore表属性列的版本号也会被设置为相应的时间戳。通过配置表上的TTL属性,当写入数据的保留时长超过设置的TTL时,系统会自动清理对应版本号的数据。
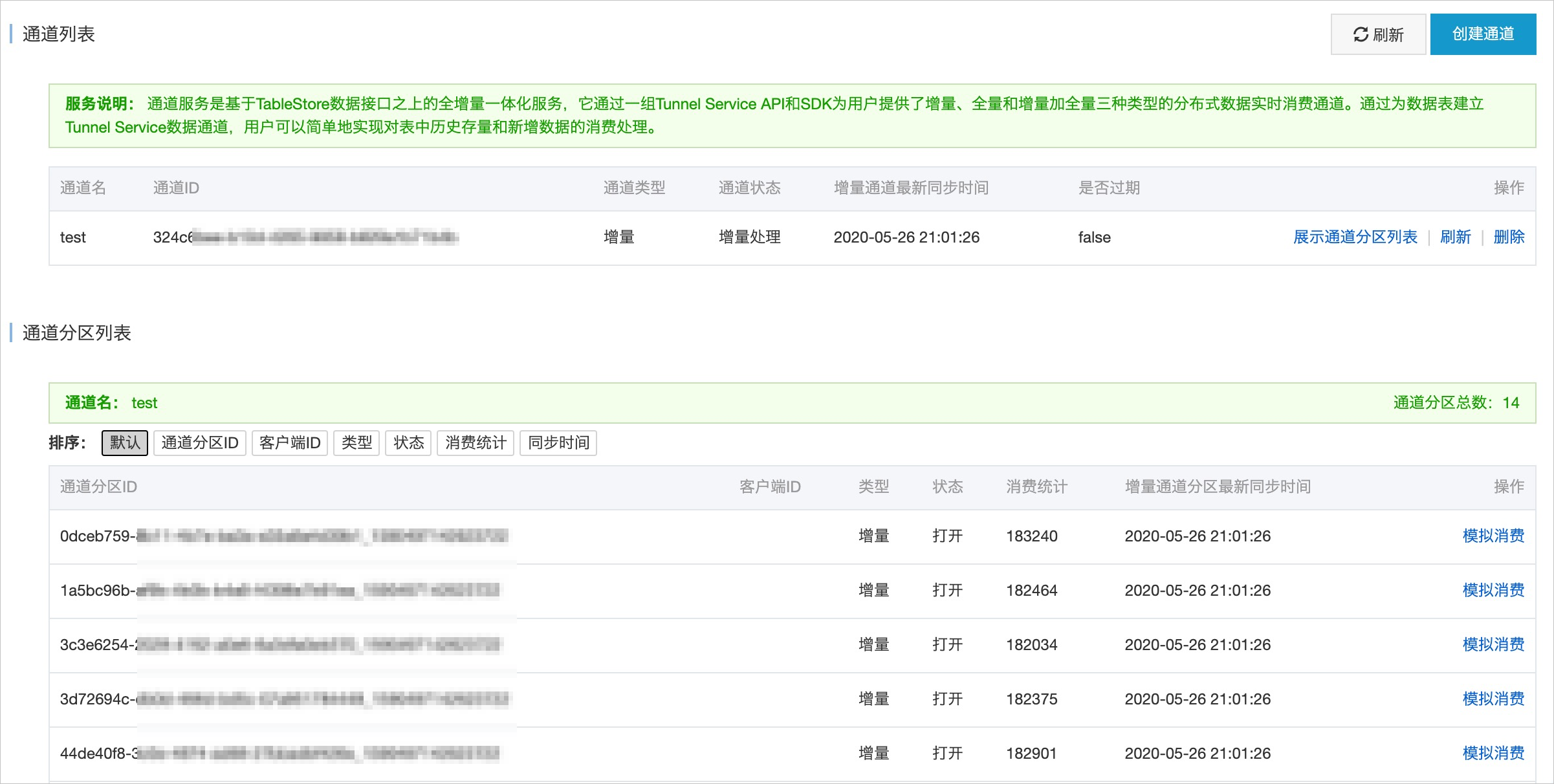
在Tablestore控制台上创建增量通道。
利用增量通道提供的CDC技术,同步新增的主表数据至Delta。通道ID用于后续的SQL配置。
在EMR集群的Header节点,启动
streaming-sql交互式命令行。streaming-sql --master yarn --use-emr-datasource --num-executors 16 --executor-memory 4g --executor-cores 4执行以下命令,创建源表和目的表。
// 1. 创建源表。 DROP TABLE IF EXISTS order_source; CREATE TABLE order_source USING tablestore OPTIONS( endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com", access.key.id="", access.key.secret="", instance.name="vehicle-test", table.name="OrderSource", catalog='{"columns": {"UserId": {"col": "UserId", "type": "string"}, "OrderId": {"col": "OrderId", "type": "string"},"price": {"col": "price", "type": "double"}, "timestamp": {"col": "timestamp", "type": "long"}}}' ); // 2. 创建Delta Lake Sink: delta_orders DROP TABLE IF EXISTS delta_orders; CREATE TABLE delta_orders( UserId string, OrderId string, price double, timestamp long ) USING delta LOCATION '/delta/orders'; // 3. 在源表上创建增量SCAN视图。 CREATE SCAN incremental_orders ON order_source USING STREAM OPTIONS( tunnel.id="324c6bee-b10d-4265-9858-b829a1b71b4b", maxoffsetsperchannel="10000"); // 4. 执行Stream作业,实时同步Tablestore CDC数据至Delta Lake。 CREATE STREAM orders_job OPTIONS ( checkpointLocation='/delta/orders_checkpoint', triggerIntervalMs='3000' ) MERGE INTO delta_orders USING incremental_orders AS delta_source ON delta_orders.UserId=delta_source.UserId AND delta_orders.OrderId=delta_source.OrderId WHEN MATCHED AND delta_source.__ots_record_type__='DELETE' THEN DELETE WHEN MATCHED AND delta_source.__ots_record_type__='UPDATE' THEN UPDATE SET UserId=delta_source.UserId, OrderId=delta_source.OrderId, price=delta_source.price, timestamp=delta_source.timestamp WHEN NOT MATCHED AND delta_source.__ots_record_type__='PUT' THEN INSERT (UserId, OrderId, price, timestamp) values (delta_source.UserId, delta_source.OrderId, delta_source.price, delta_source.timestamp);各操作含义如下。
操作
描述
创建Tablestore源表
创建order_source源表。
OPTIONS参数中的
catalog是表字段的Schema定义(本示例对应UserId、OrderId、price和timestamp四列)。创建Delta Lake Sink表
创建delta_orders目的表。
LOCATION中指定的是Delta文件存储的位置。
在Tablestore源表上创建增量SCAN视图
创建incremental_orders的流式视图。
tunnel.id:步骤1.b中创建的增量通道ID。maxoffsetsperchannel:通道每个分区可以写入数据的最大数据量。
启动Stream作业进行实时投递
根据Tablestore的主键列(UserId和OrderId)进行聚合,同时根据CDC日志的操作类型(PUT,UPDATE,DELETE),转化为对应的Delta操作。
__ots_record_type__是Tablestore流式Source提供的预定义列,表示行操作类型。
查询冷热数据。
通常,您可以保存热数据至Tablestore表中进行高效的TP查询,保存冷数据或是全量数据至Delta中。通过配置Tablestore表的生命周期(TTL),您可以灵活地控制热数据量。
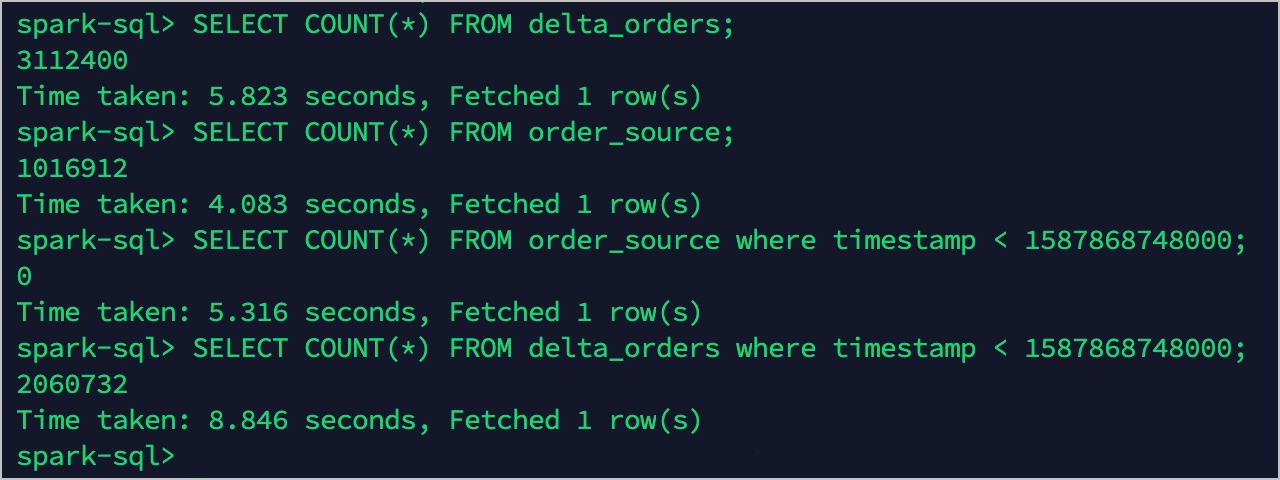
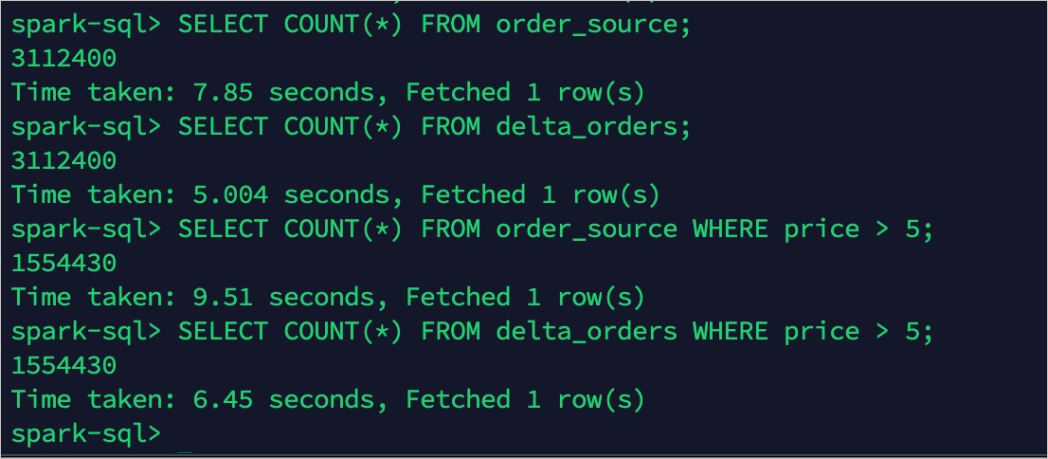
配置主表的TTL前,查询源表(order_source)和目的表(delta_orders)。
此时两边的查询结果一致。
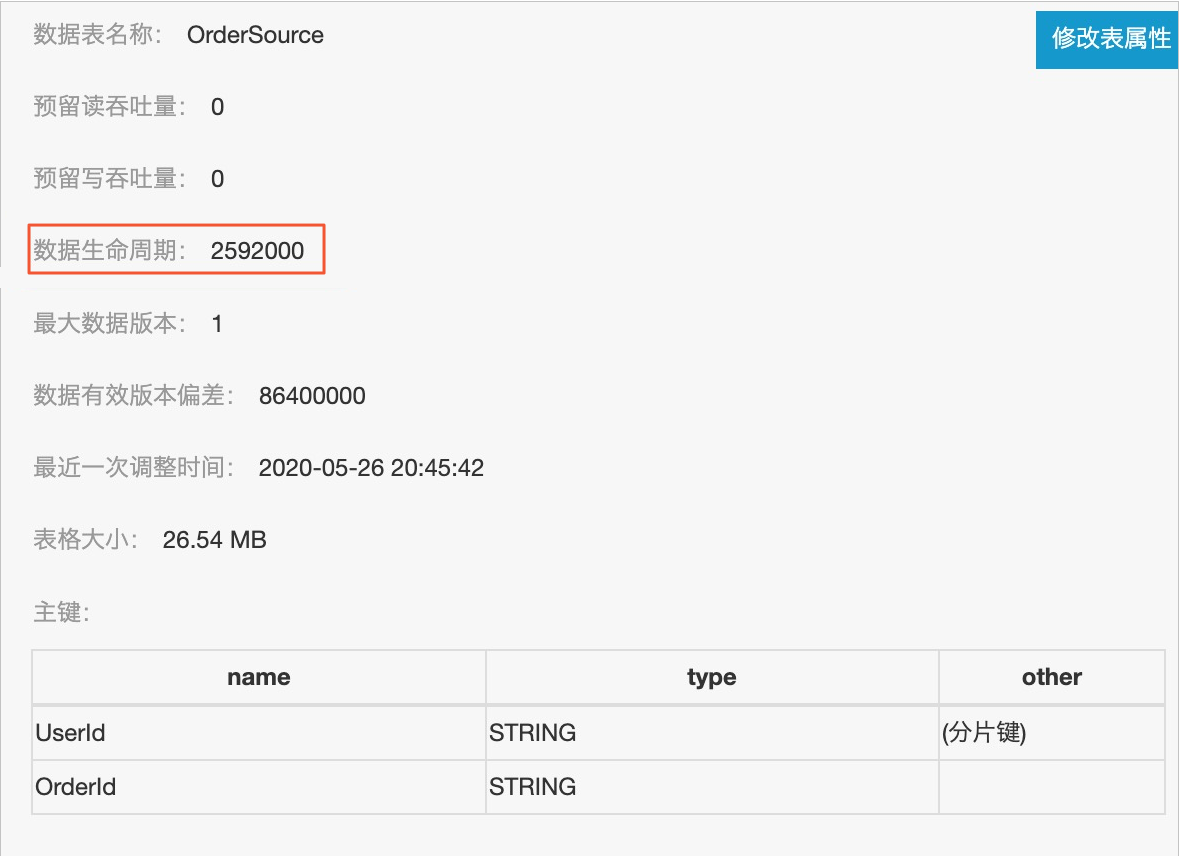
配置Tablestore的TTL为最近30天。
Tablestore中的热数据只有最近30天的数据,而Delta中依旧保留的是全量数据,以达到冷热分层的目的。
冷热分层后,再次查询源表(order_source)和目的表(delta_orders)。
冷热分层后热数据为1017004条,冷数据(全量数据)保持不变,仍然为3112400条。