
本文为您介绍如何创建E-MapReduce(简称EMR)Kafka集群、使用Kafka Topic和Kafka Connect服务,帮您快速了解和上手使用EMR Kafka。
注意事项
创建EMR Kafka集群前,您需要根据业务的预估负载,选择合适的ECS实例机型以及Broker实例个数。由于业务场景差异很大,所以无法给出通用的集群规划,您需要根据您的实际环境创建集群。通常,建议您选择机型时考虑以下配置:
Broker机型的CPU和内存配比为1:4。
选择云盘作为数据存储盘。
充分考虑云盘的I/O吞吐率以及网卡带宽之间的关系。
在部署参数上,考虑以下因素:
由于EMR Kafka版本仍依赖于Zookeeper,且Zookeeper的可用性直接关系到Kafka服务的高可用,因此,建议您创建集群时,选择高可用的部署方式。启用高可用后,将创建3个节点的Zookeeper服务。
如果Master机器组只部署Zookeeper,则Master机器组只需要配置1块数据盘即可。
更详细的评估建议,请参见集群资源规格评估建议。
创建EMR Kafka集群
该部分内容为您简单介绍如何创建Kafka集群。如需更详细的创建操作,请参见创建集群。
进入创建集群页面。
单击上方的创建集群。
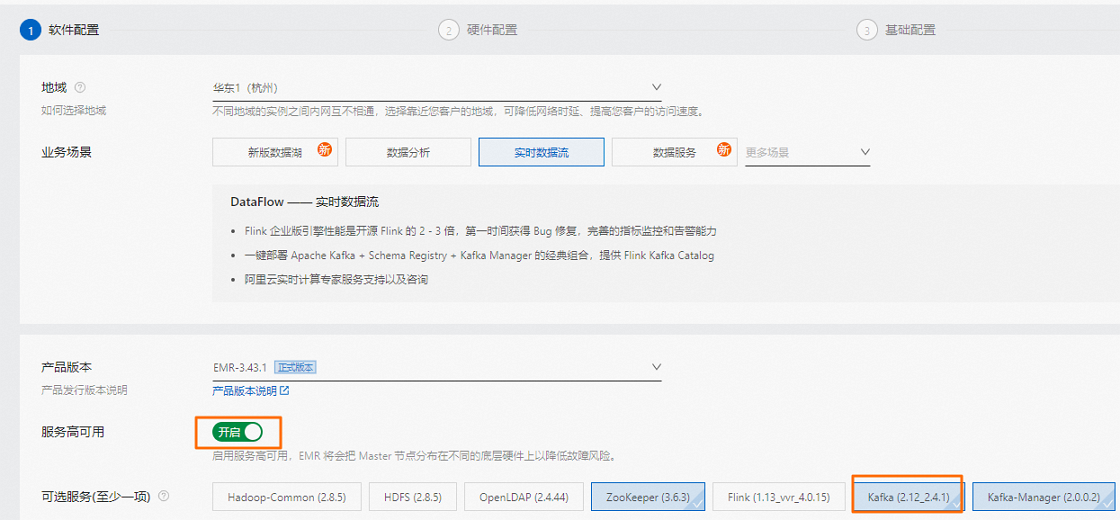
在软件配置阶段,您可以根据需要的Kafka版本,选择对应的EMR版本。
打开服务高可用开关,创建3节点的ZooKeeper集群。
 重要
重要启用高可用后,将在Master机器组上部署3个节点的Zookeeper服务。由于EMR Kafka版本的服务可用性仍依赖于Zookeeper,所以建议您创建集群时,选择高可用的部署方式。
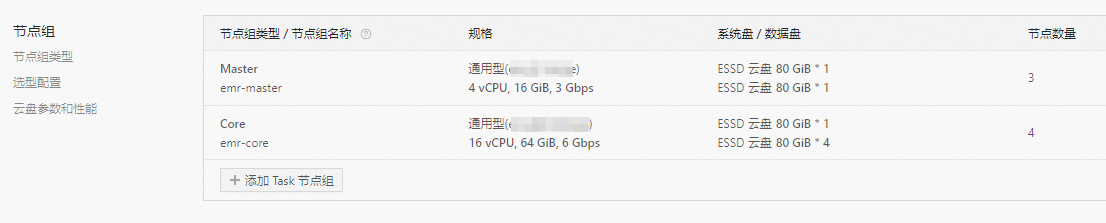
在硬件配置阶段,选择合适的ECS实例机型以及节点数量。
机型:Core节点组选择CPU和内存配比为1 Core:4 GB的机型。
节点数量:Core节点组选择比Kafka分区副本数多1的节点数量以保持足够的冗余。例如,如果规划副本数为3,则节点数选择为4。
请根据需求填写相关参数,以完成集群的创建。
使用Kafka Topic
该部分内容为您介绍如何使用Kafka Topic进行数据的生产消费。实际业务场景,您也可以使用Kafka Manager或Cruise Control等软件管理集群。
使用SSH方式登录Kafka集群的Master节点,详情请参见登录集群。
执行以下命令,创建Kafka Topic。
sudo su - kafka kafka-topics.sh --partitions 10 --replication-factor 2 --bootstrap-server core-1-1:9092 --topic test --create执行以下命令,查看Kafka topic详细信息。
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test --describe执行以下命令,生产数据。
kafka-console-producer.sh --broker-list core-1-1:9092 --topic test在此命令执行后,您可以输入消息并按回车键将其发送到Topic。
请新开一个终端窗口,执行以下命令,以消费数据。
kafka-console-consumer.sh --bootstrap-server core-1-1:9092 --topic test --from-beginning --group test-consumer-group
使用Kafka Connect服务
EMR-3.41.0之后版本、EMR-5.7.0之后版本支持Kafka Connect组件的部署。该部分内容为您介绍如何使用Kafka Connect服务。
进入节点管理页面。
在顶部菜单栏处,根据实际情况选择地域和资源组。
单击目标集群操作列的节点管理。
创建Kafka Connect节点组。
Connect安装在EMR Task节点组。在EMR Kafka集群创建Task节点组后,EMR会自动在该节点组创建Kafka Connect集群。
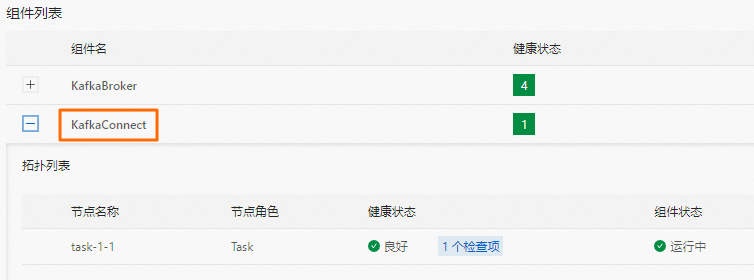
查看KafkaConnect服务状态,确保Kafka Connect集群已经启动。
您可以在Kafka服务的状态页面的组件列表区域,查看KafkaConnect的组件状态,确保组件在运行中。
检查Kafka Connect Rest服务状态。
使用SSH方式登录Kafka集群的Master节点,详情请参见登录集群。
执行以下命令,检查Kafka Connect Rest服务状态。
curl -X GET http://task-1-1:8083| jq .您会看到返回以下类似信息。
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 91 100 91 0 0 13407 0 --:--:-- --:--:-- --:--:-- 15166 { "version": "2.4.1", "commit": "42ce056344c5625a", "kafka_cluster_id": "6Z7IdHW4SVO1Pbql4c****" }
使用Kafka Connect迁移数据。
您可以在Kafka集群中启动MirrorMaker任务,进行数据复制与迁移。具体操作,请参见使用MirrorMaker 2(on Connect)跨集群同步数据。
相关文档
如果需要开启SSL,并使用SSL连接Kafka,详情请参见使用SSL加密Kafka链接。
如果需要开启SASL,并使用SASL连接Kafka,详情请参见使用SASL登录认证Kafka服务。