
本文介绍在阿里云E-MapReduce创建的包含Flink和kafka服务的DataFlow集群中,如何通过PyFlink来处理Kafka中的实时流数据。
前提条件
步骤一:创建Topic
本示例将创建两个名称为payment-msg和result的Topic。
登录集群的Master节点,详情请参见登录集群。
执行如下命令,创建Topic。
kafka-topics.sh --partitions 3 --replication-factor 2 --bootstrap-server core-1-1:9092 --topic payment-msg --create kafka-topics.sh --partitions 3 --replication-factor 2 --bootstrap-server core-1-1:9092 --topic result --create说明创建Topic后,请保留该登录窗口,后续步骤仍将使用。
步骤二:准备测试数据
执行如下命令,不断生成测试数据。
python3 -m pip install kafka
rm -rf produce_data.py
cat>produce_data.py<<EOF
import random
import time, calendar
from random import randint
from kafka import KafkaProducer
from json import dumps
from time import sleep
def write_data():
data_cnt = 20000
order_id = calendar.timegm(time.gmtime())
max_price = 100000
topic = "payment-msg"
producer = KafkaProducer(bootstrap_servers=['core-1-1:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8'))
for i in range(data_cnt):
ts = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
rd = random.random()
order_id += 1
pay_amount = max_price * rd
pay_platform = 0 if random.random() < 0.9 else 1
province_id = randint(0, 6)
cur_data = {"createTime": ts, "orderId": order_id, "payAmount": pay_amount, "payPlatform": pay_platform, "provinceId": province_id}
producer.send(topic, value=cur_data)
sleep(0.5)
if __name__ == '__main__':
write_data()
EOF
python3 produce_data.py步骤三:创建并运行PyFlink作业
登录集群的Master节点,详情请参见登录集群。
执行如下命令,生成PyFlink作业文件。
rm -rf job.py cat>job.py<<EOF import os from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic from pyflink.table import StreamTableEnvironment, DataTypes from pyflink.table.udf import udf provinces = ("beijing", "shanghai", "hangzhou", "shenzhen", "jiangxi", "chongqing", "xizang") @udf(input_types=[DataTypes.INT()], result_type=DataTypes.STRING()) def province_id_to_name(id): return provinces[id] #请根据创建的DataFlow集群,输入以下信息。 def log_processing(): kafka_servers = "core-1-1:9092" source_topic = "payment-msg" sink_topic = "result" kafka_consumer_group_id = "test" env = StreamExecutionEnvironment.get_execution_environment() env.set_stream_time_characteristic(TimeCharacteristic.EventTime) t_env = StreamTableEnvironment.create(stream_execution_environment=env) t_env.get_config().get_configuration().set_boolean("python.fn-execution.memory.managed", True) source_ddl = f""" CREATE TABLE payment_msg( createTime VARCHAR, rt as TO_TIMESTAMP(createTime), orderId BIGINT, payAmount DOUBLE, payPlatform INT, provinceId INT, WATERMARK FOR rt as rt - INTERVAL '2' SECOND ) WITH ( 'connector' = 'kafka', 'topic' = '{source_topic}', 'properties.bootstrap.servers' = '{kafka_servers}', 'properties.group.id' = '{kafka_consumer_group_id}', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ) """ kafka_sink_ddl = f""" CREATE TABLE kafka_sink ( province VARCHAR, pay_amount DOUBLE, rowtime TIMESTAMP(3) ) with ( 'connector' = 'kafka', 'topic' = '{sink_topic}', 'properties.bootstrap.servers' = '{kafka_servers}', 'properties.group.id' = '{kafka_consumer_group_id}', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ) """ t_env.execute_sql(source_ddl) t_env.execute_sql(kafka_sink_ddl) t_env.register_function('province_id_to_name', province_id_to_name) sink_ddl = """ insert into kafka_sink select province_id_to_name(provinceId) as province, sum(payAmount) as pay_amount, tumble_start(rt, interval '5' second) as rowtime from payment_msg group by tumble(rt, interval '5' second), provinceId """ t_env.execute_sql(sink_ddl) if __name__ == '__main__': log_processing() EOF请您根据集群的实际情况,修改如下参数。
参数
描述
kafka_servers指定DataFlow集群中Broker节点的内网IP地址和端口号,端口号默认为9092。
source_topic源表的Kafka Topic,本文示例为payment-msg。
sink_topic结果表的Kafka Topic,本文示例为result。
执行以下命令,运行PyFlink作业。
flink run -t yarn-per-job -py job.py -j /opt/apps/FLINK/flink-current/opt/connectors/kafka/flink-sql-connector-kafka-*.jar
步骤四:查看作业信息
访问YARN UI,访问Web UI详情请参见访问链接与端口。
通过访问YARN UI查看Flink作业的信息。
在Hadoop控制台,单击作业的ID。
您可以查看作业运行详情。
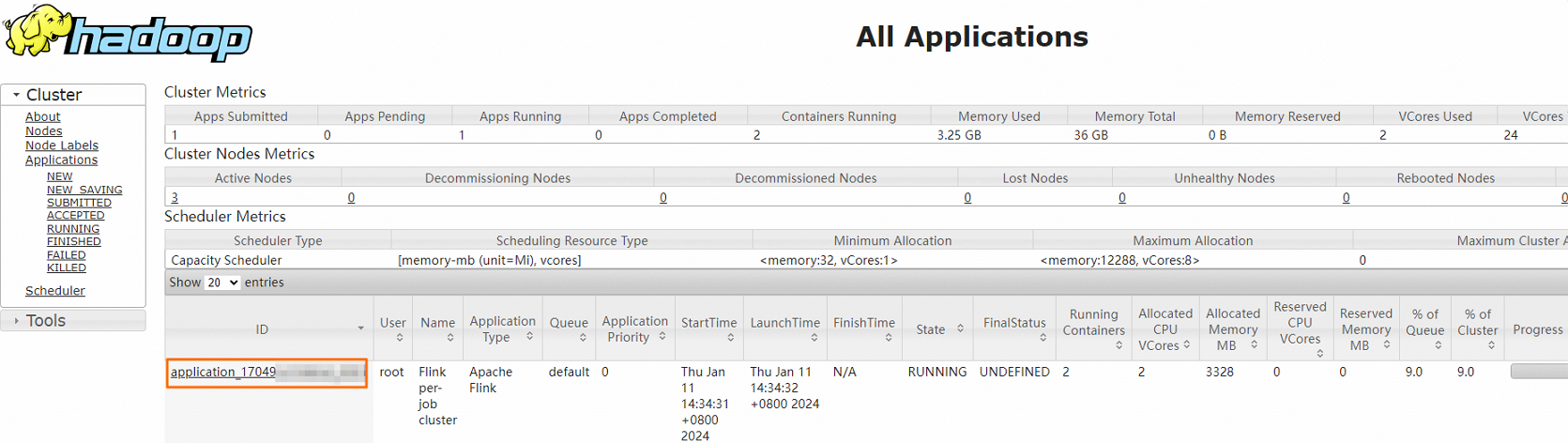
详细信息如下。
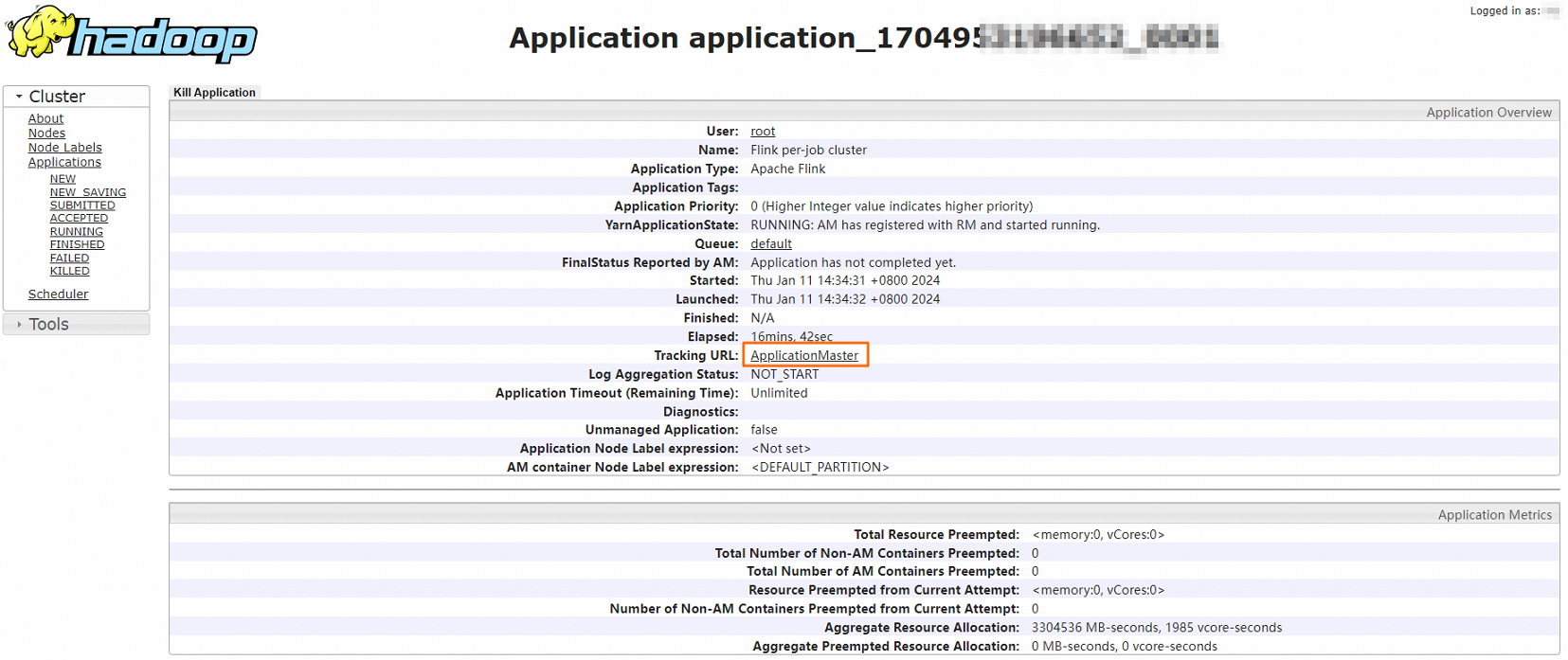
可选:单击Tracking URL后面的链接,进入Apache Flink Dashboard页面。
您可以查看详情的作业信息。
步骤五:查看输出数据
登录集群的Master节点。详情请参见登录集群。
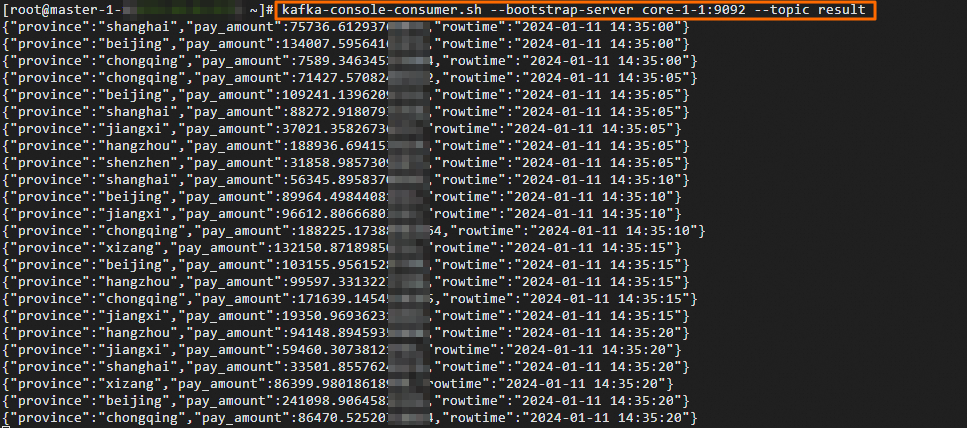
执行如下命令,查看result的数据。
kafka-console-consumer.sh --bootstrap-server core-1-1:9092 --topic result返回信息如下。
相关文档
如需全面了解Kafka topic中数据的生产和消费机制,详情请参见Apache Kafka SQL连接器。
该文章对您有帮助吗?