您可以通过Kafka表引擎导入数据至ClickHouse集群。本文为您介绍如何将Kafka中的数据导入至ClickHouse集群。
前提条件
使用限制
DataFlow集群和ClickHouse集群需要在同一VPC下。
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host1:port1,host2:port2',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format';| 参数 | 描述 |
|---|---|
db |
数据库名。 |
table_name |
表名。 |
cluster |
集群标识。 |
name1/name2 |
列名。 |
tyep1/type2 |
列的类型。 |
kafka_broker_list |
Kafka Broker的地址及端口。
DataFlow集群所有节点的内网IP地址及端口,您可以在EMR控制台集群管理页签中的主机列表页面查看。 |
kafka_topic_list |
订阅的Topic名称。 |
kafka_group_name |
Kafka consumer的分组名称。 |
kafka_format |
数据的类型。例如,CSV和JSONEachRow等,详细信息请参见Formats for Input and Output Data。 |
示例
- 在ClickHouse集群中执行以下操作。
- 执行如下命令,创建Kafka表。
CREATE TABLE IF NOT EXISTS kafka.consumer ON CLUSTER cluster_emr ( `uid` UInt32, `date` DateTime, `skuId` UInt32, `order_revenue` UInt32 ) ENGINE = Kafka() SETTINGS kafka_broker_list = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', kafka_topic_list = 'clickhouse_test', kafka_group_name = 'clickhouse_test', kafka_format = 'CSV';
- 执行如下命令,创建Kafka表。
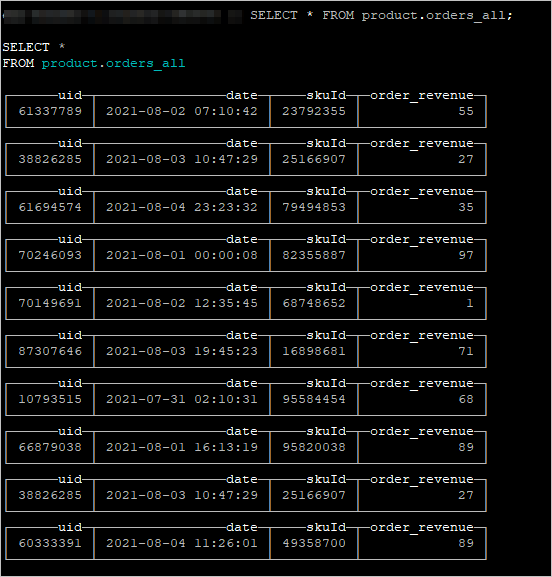
- 在ClickHouse命令窗口中,执行以下命令,可以查看从Kafka中导入至ClickHouse集群的数据。
您可以校验查询到的数据与源数据是否一致。
SELECT * FROM product.orders_all;