
Hive支持通过内表或外表的方式访问Iceberg数据。本文通过示例为您介绍如何使用EMR上的Hive访问EMR Iceberg数据。
前提条件
已创建Hadoop集群,详情请参见创建集群。
说明 此文档仅适用于EMR-3.38.0及后续版本与EMR-5.4.0及后续版本的Hadoop集群。
使用限制
EMR-3.38.0及后续版本与EMR-5.4.0及后续版本的Hadoop集群,支持Hive读写Iceberg的数据。
操作步骤
- 可选:如果您创建的是EMR-3.38.0与EMR-5.4.0版本的集群,则需要修改以下配置项。因为EMR-3.38.0与EMR-5.4.0版本的Hive与Iceberg集成存在一定兼容性问题,所以需要修改以下配置。
- 根据您创建集群的版本,修改配置信息。
- EMR-3.38.0版本:在Hive服务的配置页面,搜索参数hive.metastore.event.listeners,删除参数值。
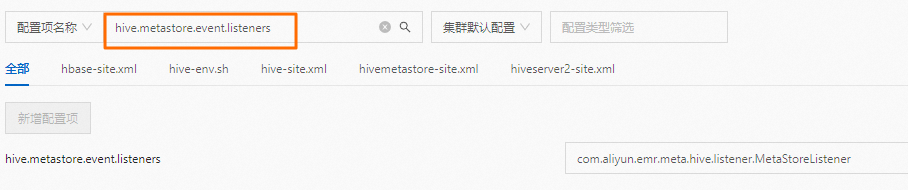
- EMR-5.4.0版本:在Hive服务的配置页面,搜索参数metastore.event.listeners,删除参数值。
- EMR-3.38.0版本:在Hive服务的配置页面,搜索参数hive.metastore.event.listeners,删除参数值。
- 根据您创建集群的版本,修改配置信息。
- 进入Hive命令行。
- 创建表。
- 如果创建集群时,元数据选择设置为DLF统一元数据,则可以按照以下步骤操作。
使用DLF统一元数据作为Hive元数据。该场景下,Hive只支持以外部表的方式访问Iceberg表。
- EMR-3.38.x版本和EMR-5.3.x~EMR-5.4.x版本(包含),需要设置Hive接入Iceberg使用DLF统一元数据的必要配置,其余版本已默认添加。
SET iceberg.catalog=dlf_catalog; SET iceberg.catalog.dlf_catalog.type=custom; SET iceberg.catalog.dlf_catalog.io-impl=org.apache.iceberg.hadoop.HadoopFileIO; SET iceberg.catalog.dlf_catalog.catalog-impl=org.apache.iceberg.aliyun.dlf.DlfCatalog; SET iceberg.catalog.dlf_catalog.access.key.id=<yourAccessKeyId>; SET iceberg.catalog.dlf_catalog.access.key.secret=<yourAccessKeySecret>; SET iceberg.catalog.dlf_catalog.warehouse=<yourOSSWarehousePath> SET iceberg.catalog.dlf_catalog.dlf.catalog-id=<yourCatalogId>; SET iceberg.catalog.dlf_catalog.dlf.endpoint=<yourDLFEndpoint>; SET iceberg.catalog.dlf_catalog.dlf.region-id=<yourDLFRegionId>;说明 示例中dlf_catalog为您创建的Catalog名称,warehouse配置使用阿里云对象存储OSS路径,其余参数含义请参见数据湖元数据配置。 - 创建Iceberg表。
- EMR-3.39.0及后续版本和EMR-5.5.0及后续版本,使用内表的方式创建Iceberg表。
create database iceberg_db; use iceberg_db; CREATE TABLE hive_iceberg ( id BIGINT, data STRING ) PARTITIONED BY ( dt STRING ) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'hdfs://master-1-1.c-****:9000/user/hive/warehouse/iceberg_db/hive_iceberg' TBLPROPERTIES ('iceberg.catalog'='dlf'); insert into hive_iceberg values(1,"abc","20230407"),(2,"hello", "20230407"); select * from hive_iceberg;说明LOCATION 'hdfs://master-1-1.c-****:9000/user/hive/warehouse/iceberg_db/hive_iceberg':存储数据路径,支持HDFS和OSS路径。请根据实际情况更换为实际路径。 - EMR-3.38.x版本和EMR-5.3.x~EMR-5.4.x版本(包含),使用外表的方式创建Iceberg表,映射已经存在的iceberg_db.sample表。
CREATE EXTERNAL TABLE iceberg_db.sample_tbl STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'oss://some_bucket/some_path/sample' TBLPROPERTIES ( 'iceberg.catalog'='<yourCatalogName>', 'name'='iceberg_db.sample' );
- EMR-3.39.0及后续版本和EMR-5.5.0及后续版本,使用内表的方式创建Iceberg表。
- EMR-3.38.x版本和EMR-5.3.x~EMR-5.4.x版本(包含),需要设置Hive接入Iceberg使用DLF统一元数据的必要配置,其余版本已默认添加。
- 如果创建集群时,元数据选择设置为内置MySQL或自建RDS,则可以按照以下步骤操作。
- 使用默认Catalog时,执行以下命令,创建表。
CREATE TABLE iceberg_db.sample_tbl ( id BIGINT, name STRING ) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'; - 自定义Catalog时,执行以下命令。说明 Iceberg支持Hive类型、Hadoop类型或其他限定的自定义Catalog,本文档以Hive类型为例。
- 设置Hive接入Iceberg的配置。
SET iceberg.catalog.hive_catalog.type=hive; - 创建Hive表。
CREATE TABLE iceberg_db.sample_tbl ( id bigint, name string ) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' TBLPROPERTIES ('iceberg.catalog'='hive_catalog');
- 设置Hive接入Iceberg的配置。
- 使用默认Catalog时,执行以下命令,创建表。
- 如果创建集群时,元数据选择设置为DLF统一元数据,则可以按照以下步骤操作。
- 执行以下命令,向表中写入数据。
INSERT INTO iceberg_db.sample_tbl VALUES (4, 'd'), (5, 'e'), (6, 'f');如果写数据时,遇到异常提示return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask,找不到fb303相关类路径。您可以在Hive命令行中手动执行以下命令:- 非DataLake集群
add jar /usr/lib/hive-current/lib/libfb303-0.9.3.jar - DataLake集群
add jar /opt/apps/HIVE/hive-current/lib/libfb303-0.9.3.jar
- 非DataLake集群
- 执行以下命令,查看表数据。
SELECT * FROM iceberg_db.sample_tbl;
示例1
本示例使用DLF统一元数据,通过Hive外部表的方式对一张已有的Iceberg表进行读写操作。
- 创建一个EMR-5.4.0的Hadoop集群,元数据选择DLF统一元数据,详情请参见创建集群。
- 修改配置项,详情请参见操作步骤中的步骤1。
- 进入Hive命令行,详情请参见操作步骤中的步骤2。
- 根据您实际信息替换以下配置,设置Hive接入Iceberg使用DLF统一元数据的必要配置。
SET iceberg.catalog=dlf_catalog; SET iceberg.catalog.dlf_catalog.type=custom; SET iceberg.catalog.dlf_catalog.io-impl=org.apache.iceberg.hadoop.HadoopFileIO; SET iceberg.catalog.dlf_catalog.catalog-impl=org.apache.iceberg.aliyun.dlf.DlfCatalog; SET iceberg.catalog.dlf_catalog.access.key.id=<yourAccessKeyId>; SET iceberg.catalog.dlf_catalog.access.key.secret=<yourAccessKeySecret>; SET iceberg.catalog.dlf_catalog.warehouse=<yourOSSWarehousePath> SET iceberg.catalog.dlf_catalog.dlf.catalog-id=<yourCatalogId>; SET iceberg.catalog.dlf_catalog.dlf.endpoint=<yourDLFEndpoint>; SET iceberg.catalog.dlf_catalog.dlf.region-id=<yourDLFRegionId>;说明 示例中dlf_catalog为默认的Catalog名称,warehouse配置使用阿里云对象存储OSS路径,其余参数含义请参见数据湖元数据配置。 - 执行以下命令,创建数据表iceberg_db.sample_ext,映射已有的iceberg_db.sample表。
CREATE EXTERNAL TABLE iceberg_db.sample_ext STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'oss://mybucket/iceberg-test/warehouse/iceberg_db.db/sample' TBLPROPERTIES ( 'iceberg.catalog'='dlf_catalog', 'name'='iceberg_db.sample' ); - 执行以下命令,通过外部表查询Iceberg表数据。
SELECT * FROM iceberg_db.sample_ext;返回信息如下。OK 1 a 2 b 3 c Time taken: 19.075 seconds, Fetched: 3 row(s) - 执行以下命令,向表中写入数据。
INSERT INTO iceberg_db.sample_ext VALUES (4, 'd'), (5, 'e'), (6, 'f'); - 执行以下命令,查询Iceberg表数据。
SELECT * FROM iceberg_db.sample_ext;返回信息如下。OK 1 a 2 b 3 c 4 d 5 e 6 f Time taken: 18.908 seconds, Fetched: 6 row(s)
示例2
本示例使用Hive默认元数据,创建一张格式为Iceberg的Hive内表并对其进行读写操作。
- 创建一个EMR-5.4.0的Hadoop集群,元数据选择内置MySQL,详情请参见创建集群。
- 修改配置项,详情请参见操作步骤中的步骤1。
- 进入Hive命令行,详情请参见操作步骤中的步骤2。
- 执行以下命令,创建数据库iceberg_db。
CREATE DATABASE IF NOT EXISTS iceberg_db; - 执行以下命令,创建数据表sample_tbl。
CREATE TABLE iceberg_db.sample_tbl ( id BIGINT, name STRING ) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'; - 执行以下命令,向表中写入数据。
INSERT INTO iceberg_db.sample_tbl VALUES (1, 'a'), (2, 'b'), (3, 'c'); - 执行以下命令,查询Iceberg表数据。
SELECT * FROM iceberg_db.sample_tbl;返回信息如下。OK 1 a 2 b 3 c Time taken: 0.233 seconds, Fetched: 3 row(s)