
本文汇总了使用EMR Serverless Spark时的常见问题。
与DLF适配问题
读取数据时报错“java.net.UnknownHostException”,该如何处理?
-
问题现象
在数据开发中执行SQL查询从DLF 1.0的数据表中读取信息时,遇到了
UnknownHostException异常。
-
问题原因
通常是因为系统找不到指定的主机,导致无法成功查询数据表。
-
解决方案
与OSS适配问题
如何跨账号访问阿里云OSS?
在使用EMR Serverless Spark执行Spark任务时,如果您需要访问不同阿里云账户下的OSS资源,可以采用两种方式。一种是在工作空间级别,赋予工作空间的执行角色对目标OSS的读写权限;另一种是在任务或会话级别,通过在Spark配置中增加配置进行设置。
-
工作空间级别
您需要在目标OSS的Bucket Policy中配置相应的访问权限,以允许Serverless Spark工作空间的执行角色进行OSS的读写操作。以下是具体操作步骤:
-
进入阿里云OSS的Bucket 授权策略页面。
登录OSS管理控制台。
单击Bucket 列表,然后单击目标Bucket名称。
-
在左侧导航栏,选择。
-
在Bucket 授权策略页面的按图形策略添加页签,单击新增授权。
-
在新增授权面板,配置以下参数,然后单击确定。
参数
说明
授权资源
选择整个Bucket。
授权用户
选择其他账号。Principal填写为
arn:sts::<uid>:assumed-role/<role-name>/*。其中:-
<uid>需要替换为阿里云账号ID(主账号ID)。 -
<role-name>需要替换为Serverless Spark工作空间的执行角色名称(请注意区分大小写)。您可以在EMR Serverless Spark的工作空间列表页面,单击目标工作空间操作列的详情,以查看执行角色,默认使用的角色是AliyunEMRSparkJobRunDefaultRole。
其余参数可以根据实际情况进行配置,更多参数介绍请参见图形化配置Bucket Policy。
-
-
-
任务、会话级别
在创建任务和会话时,在Spark配置中添加下列配置,可以访问目标OSS。
spark.hadoop.fs.oss.bucket.<bucketName>.endpoint <endpoint> spark.hadoop.fs.oss.bucket.<bucketName>.credentials.provider com.aliyun.jindodata.oss.auth.SimpleCredentialsProvider spark.hadoop.fs.oss.bucket.<bucketName>.accessKeyId <accessID> spark.hadoop.fs.oss.bucket.<bucketName>.accessKeySecret <accessKey>请根据您的实际情况替换以下信息。
-
<bucketName>:您要访问的OSS Bucket的名称。 -
<endpoint>:OSS的Endpoint。 -
<accessID>:访问OSS数据所使用阿里云账号的AccessKey ID。 -
<accessKey>:访问OSS数据所使用阿里云账号的AccessKey Secret。
-
任务执行报错:OSS文件不存在或无权限访问
问题现象
在使用阿里云EMR Serverless Spark执行任务时,可能会遇到报错提示,主程序引用的OSS文件不存在或无权限访问。
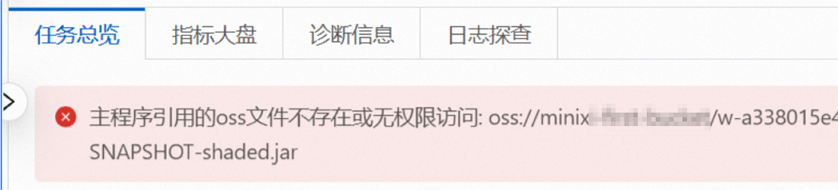
问题原因
执行角色权限不足 创建Serverless Spark工作空间时,指定的执行角色未正确配置,或者修改了默认的执行角色,导致无法访问OSS资源。
OSS文件路径错误 主程序中引用的OSS文件路径拼写错误或文件实际不存在。
引用的文件名称中包含空格
如果引用的OSS文件名称中包含空格,可能会导致解析失败。
解决方案
检查并正确配置执行角色
查看当前执行角色:在Serverless Spark页面,单击目标工作空间操作列的详情,查看执行角色,确保为
AliyunEMRSparkJobRunDefaultRole。如果使用的是默认角色但仍然遇到问题,请进一步排查其他原因。
如果使用的是使用自定义角色:
请确保权限策略中包含了相应的内容,例如,是否具有对目标OSS资源的读取权限(oss:GetObject)。具体请参见AliyunEMRSparkJobRunDefaultRolePolicy进行权限设置。
如果权限配置较复杂或不确定,建议重新创建工作空间,并确保指定的执行角色为默认的
AliyunEMRSparkJobRunDefaultRole。 说明
说明建议您使用默认角色,而非自定义角色,以避免权限配置问题。
验证OSS文件路径
确认路确认OSS文件路径的正确性,包括路径前缀
oss://、Bucket名称、目录路径和文件名。使用OSS控制台验证目标文件是否存在。
处理文件名中的空格
检查并重命名文件,确保文件名中不包含空格或其他特殊字符。
如果通过以上排查问题仍未解决,可以联系阿里云技术支持。
权限问题
角色绑定的系统策略被误删如何恢复?
当默认执行角色 AliyunEMRSparkJobRunDefaultRole 绑定的系统策略AliyunEMRSparkJobRunDefaultRolePolicy被移除时,Serverless Spark 任务将因缺少必要权限而无法正常访问 OSS等依赖资源。
恢复操作如下:
-
登录RAM 访问控制控制台。
-
在左侧导航栏,选择。
-
在角色列表中搜索
AliyunEMRSparkJobRunDefaultRole,单击角色名称进入详情页。 -
在权限管理页签,单击精准授权。
-
在弹出的精确授权对话框中,输入完整策略名称
AliyunEMRSparkJobRunDefaultRolePolicy,勾选该策略,然后单击确定。
多云部署问题
如何访问S3?
在创建任务和会话时,在Spark配置中添加下列配置,可以访问S3。
spark.hadoop.fs.s3.impl com.aliyun.jindodata.s3.JindoS3FileSystem
spark.hadoop.fs.AbstractFileSystem.s3.impl com.aliyun.jindodata.s3.S3
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.s3.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.s3.credentials.provider com.aliyun.jindodata.s3.auth.SimpleCredentialsProvider请根据您的实际情况替换以下信息。
-
<bucketName>:您要访问的S3 Bucket的名称。 -
<endpoint>:S3的Endpoint。 -
<accessID>:访问S3数据所使用账号的AccessKey ID。 -
<accessKey>:访问S3数据所使用账号的AccessKey Secret。
如何访问OBS?
在创建任务和会话时,在Spark配置中添加下列配置,可以访问OBS。
spark.hadoop.fs.obs.impl com.aliyun.jindodata.obs.JindoObsFileSystem
spark.hadoop.fs.AbstractFileSystem.obs.impl com.aliyun.jindodata.obs.OBS
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.obs.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.obs.credentials.provider com.aliyun.jindodata.obs.auth.SimpleCredentialsProvider请根据您的实际情况替换以下信息。
-
<bucketName>:您要访问的OBS Bucket的名称。 -
<endpoint>:OBS的Endpoint。 -
<accessID>:访问OBS数据所使用账号的AccessKey ID。 -
<accessKey>:访问OBS数据所使用账号的AccessKey Secret。
如何访问COS?
在创建任务和会话时,在Spark配置中添加下列配置,可以访问COS。
spark.hadoop.fs.cos.impl com.aliyun.jindodata.cos.JindoCosFileSystem
spark.hadoop.fs.AbstractFileSystem.cos.impl com.aliyun.jindodata.cos.COS
spark.hadoop.fs.cos.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.cos.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.cos.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.cos.credentials.provider com.aliyun.jindodata.cos.auth.SimpleCredentialsProvider请根据您的实际情况替换以下信息。
-
<bucketName>:您要访问的COS Bucket的名称。 -
<endpoint>:COS的Endpoint。 -
<accessID>:访问COS数据所使用账号的AccessKey ID。 -
<accessKey>:访问COS数据所使用账号的AccessKey Secret。