
StarRocks官方提供了Spark Connector用于Spark和StarRocks之间的数据读写,Serverless Spark可以在开发时添加对应的配置连接StarRocks。本文为您介绍在EMR Serverless Spark中实现StarRocks的读取和写入操作。
前提条件
使用限制
Serverless Spark引擎的版本要求为esr-2.5.0、esr-3.1.0、esr-4.1.0及以上版本。
操作流程
步骤一:获取Spark Connector JAR并上传至OSS
参见使用Spark Connector读取数据,选择相应的方式下载对应版本的Spark Connector JAR。
例如,本文选择直接下载已经编译好的JAR,即从Maven Central Repository获取不同版本的Connector JAR包。
说明Connector JAR包的命名格式为
starrocks-spark-connector-${spark_version}_${scala_version}-${connector_version}.jar。例如,您使用的引擎版本为esr-4.1.0 (Spark 3.5.2, Scala 2.12),想使用1.1.2版本的Connector,则可以选择starrocks-spark-connector-3.5_2.12-1.1.2.jar。将下载的Spark Connector JAR上传至阿里云OSS中,上传操作可以参见简单上传。
步骤二:添加网络连接
获取网络信息。
您可以在EMR Serverless Starrocks页面,进入目标StarRocks实例的实例详情页面,以获取该实例的专有网络和交换机信息。
新增网络连接。
在EMR Serverless Spark页面,进入目标Spark工作空间的网络连接页面,单击新增网络连接。
在新增网络连接对话框中,输入连接名称,并选择之前获取到的StarRocks实例的专有网络和交换机信息,然后单击确定。
更多网络连接信息,请参见EMR Serverless Spark与其他VPC间网络互通。
步骤三:在StarRocks中创建库表
连接StarRocks实例,详情请参见通过EMR StarRocks Manager连接StarRocks实例。
在SQL Editor的查询列表页面,单击文件或者右侧区域的
 图标,然后单击确认以新增文件。
图标,然后单击确认以新增文件。在新增的文件中输入以下SQL语句,单击运行。
CREATE DATABASE `testdb`; CREATE TABLE `testdb`.`score_board` ( `id` int(11) NOT NULL COMMENT "", `name` varchar(65533) NULL DEFAULT "" COMMENT "", `score` int(11) NOT NULL DEFAULT "0" COMMENT "" ) ENGINE=OLAP PRIMARY KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`);
步骤四:通过Serverless Spark读写StarRocks
方式一:使用SQL会话、Notebook会话读写StarRocks
会话类型更多介绍,请参见会话管理。
SQL会话
通过Serverless Spark向StarRocks写入数据。
创建SQL会话,详情请参见管理SQL会话。
创建会话时,选择与Spark Connector版本对应的引擎版本,在网络连接中选择上一步创建好的网络连接,并在Spark配置中添加以下参数来加载Spark Connector。
spark.emr.serverless.user.defined.jars oss://<bucketname>/path/connector.jar其中,
oss://<bucketname>/path/connector.jar为您步骤一中上传至OSS的Spark Connector的路径。例如,oss://emr-oss/spark/starrocks-spark-connector-3.5_2.12-1.1.2.jar。在数据开发页面,创建一个SparkSQL类型的任务,然后在右上角选择创建好的SQL会话。
更多操作,请参见SparkSQL开发。
拷贝如下代码到新增的SparkSQL页签中,并根据需要修改相应的参数信息,然后单击运行。
CREATE TEMPORARY VIEW score_board USING starrocks OPTIONS ( "starrocks.table.identifier" = "testdb.score_board", "starrocks.fe.http.url" = "<fe_host>:<fe_http_port>", "starrocks.fe.jdbc.url" = "jdbc:mysql://<fe_host>:<fe_query_port>", "starrocks.user" = "<user>", "starrocks.password" = "<password>" ); INSERT INTO `score_board` VALUES (1, "starrocks", 100), (2, "spark", 100);其中,涉及参数说明如下:
<fe_host>:Serverless StarRocks实例中FE的内网或公网地址。您可以在实例详情页面的FE详情区域查看。如果使用内网地址,请确保在同一VPC内。
如果使用公网地址,需确保安全组规则允许相应的端口通信,详情请参见网络访问与安全设置。
<fe_http_port>:Serverless StarRocks实例中FE的HTTP端口(默认为8030)。您可以在实例详情页面的FE详情区域查看。<fe_query_port>:Serverless StarRocks实例中FE的查询端口(默认为9030)。您可以在实例详情页面的FE详情区域查看。<user>:Serverless StarRocks实例的用户名。默认提供admin用户,具有管理员权限。您也可以通过用户管理页面新增用户来连接。新增用户操作,请参见管理用户及数据授权。<password>:用户<user>对应的密码。
通过Serverless Spark查询写入的数据。
在本文示例中,我们是在上述的SparkSQL任务中创建了一个临时视图
test_view,然后通过该视图查询score_board的数据。拷贝如下代码到新增的SparkSQL页签中,选中代码后单击运行选中。CREATE TEMPORARY VIEW test_view USING starrocks OPTIONS ( "starrocks.table.identifier" = "testdb.score_board", "starrocks.fe.http.url" = "<fe_host>:<fe_http_port>", "starrocks.fe.jdbc.url" = "jdbc:mysql://<fe_host>:<fe_query_port>", "starrocks.user" = "<user>", "starrocks.password" = "<password>" ); SELECT * FROM test_view;返回信息如下图所示。

Notebook会话
通过Serverless Spark向StarRocks写入数据。
创建Notebook会话,详情请参见管理Notebook会话。
创建会话时,选择与Spark Connector版本对应的引擎版本,在网络连接中选择上一步创建好的网络连接,并在Spark配置中添加以下参数来加载Spark Connector。
spark.emr.serverless.user.defined.jars oss://<bucketname>/path/connector.jar其中,
oss://<bucketname>/path/connector.jar为您步骤一中上传至OSS的Spark Connector的路径。例如,oss://emr-oss/spark/starrocks-spark-connector-3.5_2.12-1.1.2.jar。在数据开发页面,选择创建一个类型的任务,然后在右上角选择创建的Notebook会话。
更多操作,请参见管理Notebook会话。
拷贝如下代码到新增的Notebook的Python单元格中,单击运行。
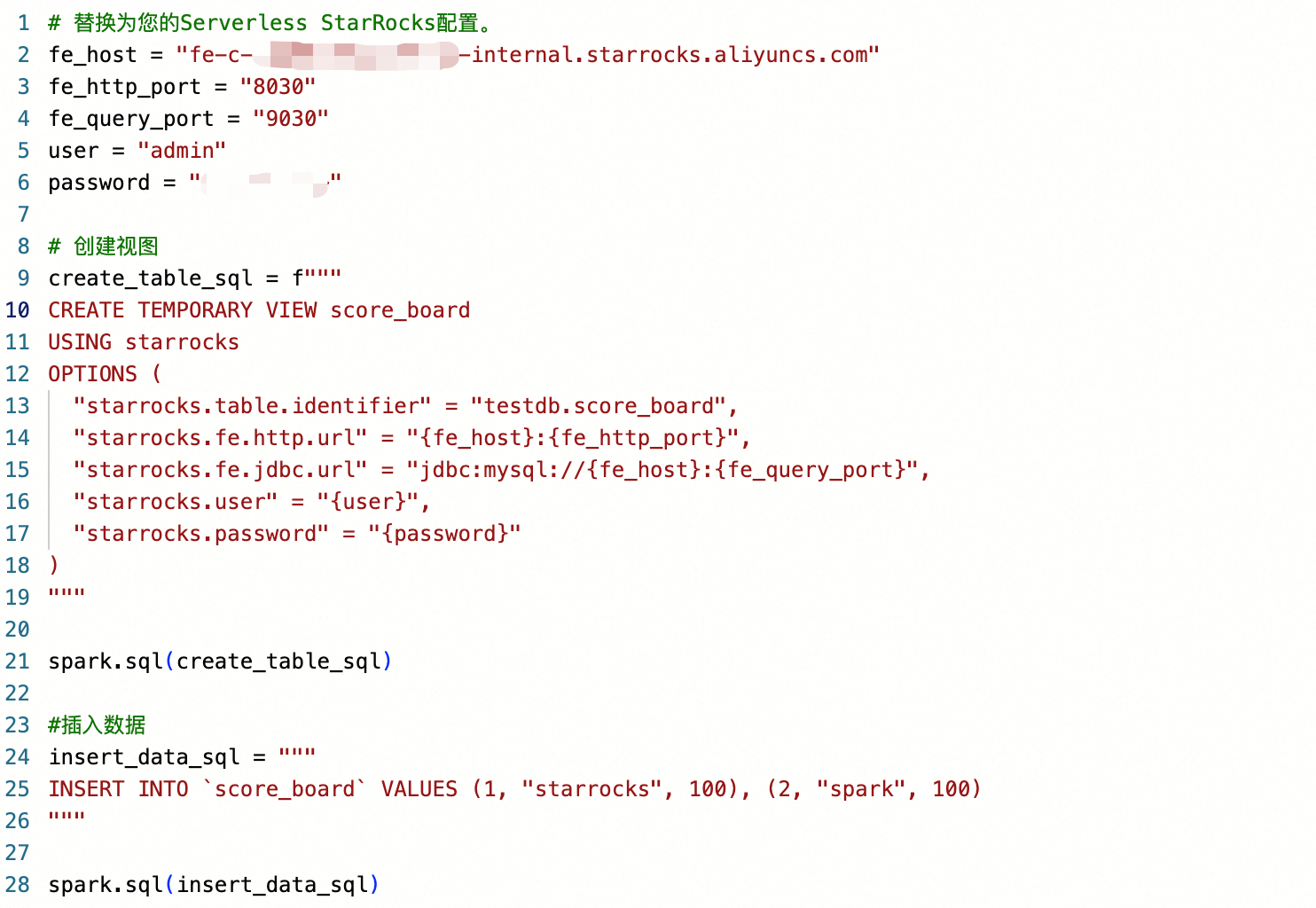
# 替换为您的Serverless StarRocks配置。 fe_host = "<fe_host>" fe_http_port = "<fe_http_port>" fe_query_port = "<fe_query_port>" user = "<user>" password = "<password>" # 创建视图 create_table_sql = f""" CREATE TEMPORARY VIEW score_board USING starrocks OPTIONS ( "starrocks.table.identifier" = "testdb.score_board", "starrocks.fe.http.url" = "{fe_host}:{fe_http_port}", "starrocks.fe.jdbc.url" = "jdbc:mysql://{fe_host}:{fe_query_port}", "starrocks.user" = "{user}", "starrocks.password" = "{password}" ) """ spark.sql(create_table_sql) #插入数据 insert_data_sql = """ INSERT INTO `score_board` VALUES (1, "starrocks", 100), (2, "spark", 100) """ spark.sql(insert_data_sql)填写示例如下图所示。
其中,涉及参数说明如下:
<fe_host>:Serverless StarRocks实例中FE的内网或公网地址。您可以在实例详情页面的FE详情区域查看。如果使用内网地址,请确保在同一VPC内。
如果使用公网地址,需确保安全组规则允许相应的端口通信,详情请参见网络访问与安全设置。
<fe_http_port>:Serverless StarRocks实例中FE的HTTP端口(默认为8030)。您可以在实例详情页面的FE详情区域查看。<fe_query_port>:Serverless StarRocks实例中FE的查询端口(默认为9030)。您可以在实例详情页面的FE详情区域查看。<user>:Serverless StarRocks实例的用户名。默认提供admin用户,具有管理员权限。您也可以通过用户管理页面新增用户来连接。新增用户操作,请参见管理用户及数据授权。<password>:用户<user>对应的密码。
通过Serverless Spark查询写入的数据。
在本文示例中,我们新增一个Python单元格,在其中创建了一个临时视图
test_view,然后通过该视图查询score_board的数据。拷贝如下代码到新增的Python单元格中,然后单击 图标。
图标。#创建view create_view_sql=f""" CREATE TEMPORARY VIEW test_view USING starrocks OPTIONS ( "starrocks.table.identifier" = "testdb.score_board", "starrocks.fe.http.url" = "{fe_host}:{fe_http_port}", "starrocks.fe.jdbc.url" = "jdbc:mysql://{fe_host}:{fe_query_port}", "starrocks.user" = "{user}", "starrocks.password" = "{password}" ) """ spark.sql(create_view_sql) #查询 query_sql="SELECT * FROM test_view" result_df = spark.sql(query_sql) result_df.show()返回信息如下图所示。

方式二:使用Spark批任务读写StarRocks
创建Spark批任务。
在EMR Serverless Spark页面,单击左侧的数据开发。
在开发目录页签下,单击
 图标。
图标。在新建对话框中,输入名称,类型选择,然后单击确定。
类型您可以根据实际情况进行调整,本文以SQL为例。更多类型参数介绍,请参见Application开发。
通过Spark批任务读写StarRocks。
在新建的任务开发的右上角选择队列。
添加队列的具体操作,请参见管理资源队列。
在新建的任务开发中,配置以下信息,其余参数无需配置,然后单击运行。
参数
说明
SQL文件
本示例所使用的文件为spark_sql_starrocks.sql,其内容是SQL会话中的SQL语句,请根据实际情况对具体配置进行替换。在使用之前,您需要先下载该文件并进行相应的修改,然后在文件管理页面进行上传。
引擎版本
选择与Spark Connector版本对应的引擎版本。
网络连接
选择前一步创建好的网络连接。
Spark 配置
在Spark配置中添加以下参数来加载Spark Connector。
spark.emr.serverless.user.defined.jars oss://<bucketname>/path/connector.jar其中,
oss://<bucketname>/path/connector.jar为您步骤一中上传至OSS的Spark Connector的路径。例如,oss://emr-oss/spark/starrocks-spark-connector-3.5_2.12-1.1.2.jar。
查看日志信息。
您可以在下方的运行记录区域,单击操作列的详情。
单击日志探查页签,查看该任务的日志信息。

相关文档
StarRocks的官方文档: