本文使用Beats、Elasticsearch、Logstash和Kibana,在分布式环境下采集、汇聚、解析阿里云RocketMQ客户端SDK日志,帮助您在消息队列开发场景中快速定位并解决应用开发问题。
背景信息
阿里云Elasticsearch(简称ES)已具备Elastic Stack全栈套件:Elasticsearch、Logstash、Kibana和Beats,具有日志汇聚、快速分析、可视化展示等能力,与开源产品相比具有以下优势:
Beats和Logstash服务部署在专有网络VPC(Virtual Private Cloud)中,所有数据私网通信,高速且安全。
Elastic Stack全栈套件具有“0部署,轻运维”的特性,省去了在分布式环境下逐个节点安装与配置Beats采集器的繁琐工作,同时解决了分布式消息中间件日志分散、采集困难的问题。
支持在控制台快速添加和移除Beats实例,能够适应RocketMQ的弹性伸缩特性。
本方案使用的产品包括:阿里云消息队列RocketMQ版和阿里云Elasticsearch,方案架构如下。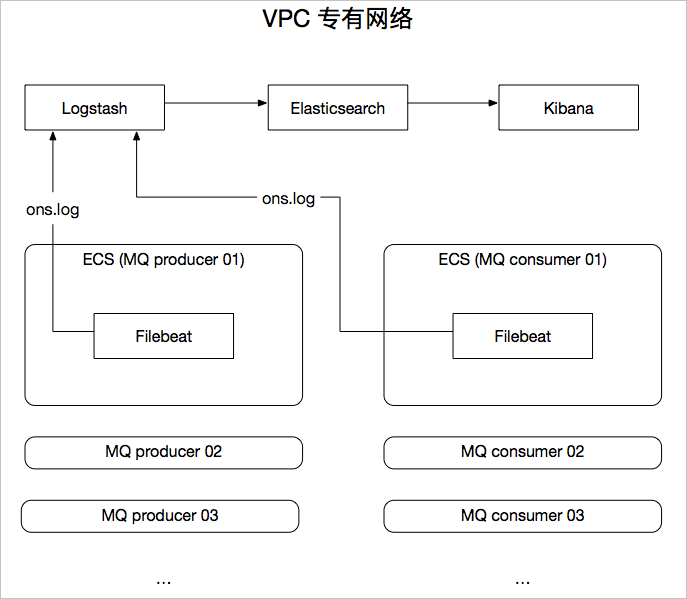
操作流程
完成创建阿里云ES实例和Logstash实例、开通RocketMQ消息队列服务、创建ECS实例并在实例中安装云助手和Docker服务。各实例或服务的功能如下:
RocketMQ消息队列服务:提供RocketMQ资源,包括实例、Topic、Group。
ECS实例:安装Filebeat并运行RocketMQ测试工程,生成客户端日志。
阿里云Logstash实例:通过管道配置将Filebeat采集的日志同步到阿里云ES中。
阿里云ES实例:对日志进行分析,并进行可视化展示。
重要请确保阿里云ES实例、Logstash实例和ECS实例在同一专有网络VPC(Virtual Private Cloud)下。
通过Filebeat将RocketMQ的客户端日志采集到Logstash中。
通过管道配置,使用Grok filter插件处理Filebeat采集的RocketMQ客户端日志,然后同步到阿里云ES中。
在安装Filebeat的ECS上运行RocketMQ客户端测试工程,生成日志数据。
创建索引模式,并在Kibana的Discover页面查看日志的详细信息。
以筛选ERROR级别日志为例,演示在Kibana中分析并解读日志数据的方法。
准备工作
创建阿里云ES实例,并开启自动创建索引功能。
具体操作步骤请参见创建阿里云Elasticsearch实例和快速访问与配置。
创建阿里云Logstash实例,要求与阿里云ES实例在同一VPC下。
具体操作步骤请参见创建阿里云Logstash实例。
开通RocketMQ消息队列服务,并创建所需资源,包括实例、Topic、Group。
具体操作步骤请参见开通消息队列服务并授权和创建资源。
创建一个或多个ECS实例,并且该实例与阿里云ES实例和Logstash实例处于同一VPC下。
具体操作步骤请参见自定义购买实例。
重要ECS的操作系统必须为Alibaba Cloud Linux (Alinux)、RedHat或CentOS。因为Beats仅支持这三种操作系统。
在ECS实例中安装云助手和Docker服务。
具体操作步骤请参见安装云助手Agent和部署并使用Docker。
重要所选ECS必须安装云助手和Docker,且对应服务已正常运行。因为安装Beats时会依赖这两个服务。
步骤一:创建并配置Filebeat采集器
在左侧导航栏,单击Beats数据采集中心。
在创建采集器区域,单击ECS日志。
配置并安装采集器。
详情请参见通过Filebeats采集ECS服务日志和采集器YML配置,本文使用的配置如下。
参数
说明
采集器名称
自定义采集器名称。
安装版本
目前只支持6.8.5版本。
采集器Output
指定目标阿里云Logstash的实例ID,在YML配置中不需要重新指定Output。
填写Filebeat文件目录
填写数据源所在的目录,同时需要在YML配置中开启log数据采集,并配置log路径。
采集器Yml配置
开启log数据采集,将
enabled修改为true。修改
paths为具体的日志文件路径,与Filebeat文件目录保持一致。调整Multiline options相关配置,解决多行日志及java stacktrace的情况。
multiline.pattern: '^([0-9]{4}-[0-9]{2}-[0-9]{2})' multiline.negate: true multiline.match: after multiline.timeout: 120s #default 5s multiline.max_lines: 10000 #default 500
完整的filebeat.yml配置如下。
###################### Filebeat Configuration Example ######################### #=========================== Filebeat inputs ============================= filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /root/logs/ons.log #- c:\programdata\elasticsearch\logs\* ### Multiline options # Multiline can be used for log messages spanning multiple lines. This is common # for Java Stack Traces or C-Line Continuation multiline.pattern: '^([0-9]{4}-[0-9]{2}-[0-9]{2})' multiline.negate: true multiline.match: after multiline.timeout: 120s #default 5s multiline.max_lines: 10000 #default 500 #==================== Elasticsearch template setting ========================== setup.template.settings: index.number_of_shards: 3 #index.codec: best_compression #_source.enabled: false #================================ Processors ===================================== # Configure processors to enhance or manipulate events generated by the beat. processors: - add_host_metadata: ~ - add_cloud_metadata: ~单击下一步。
在采集器安装配置向导中,选择安装采集器的ECS实例。
页面显示所在专有网络和选择采集器安装实例配置项,下方列出当前VPC下可用的ECS实例,包含实例ID/实例名称、实例状态、操作系统、IP地址和采集器状态等信息,勾选目标ECS实例即可。
启动采集器并查看采集器安装情况。
单击启动。
启动成功后,系统弹出启动成功对话框。
单击前往采集中心查看,返回Beats数据采集中心页面,在采集器管理区域中,查看启动成功的Filebeat采集器。
等待采集器状态变为已生效1/1后,单击右侧操作栏下的查看运行实例。
在查看运行实例页面,查看采集器安装情况,当显示为心跳正常时,说明采集器安装成功。
采集器管理表格显示采集器的ID、名称、状态、类型、版本和Output信息。查看运行实例面板显示ECS实例的ID、运行状态、操作系统、IP地址和采集器安装情况。
步骤二:创建并运行Logstash管道
进入目标实例。
在顶部菜单栏处,选择地域。
在Logstash实例中单击目标实例ID。
在左侧导航栏,单击管道管理。
单击创建管道。
在创建管道任务页面,输入管道ID并配置管道。
本文使用的Config配置如下。
input { beats { port => 8000 } } filter { grok { match => { "message" => "%{TIMESTAMP_ISO8601:log_time} %{LOGLEVEL:log_level} %{GREEDYDATA:log_message}" } } } output { elasticsearch { hosts => "http://es-cn-4591jumei000u****.elasticsearch.aliyuncs.com:9200" user =>"elastic" password =>"<your_password>" index => "rocketmq-%{+YYYY.MM.dd}" } }input:输入插件。以上配置使用beats插件,指定8000端口。
filter:过滤插件。以上配置提供了Grok filter示例,解析RocketMQ客户端SDK日志,提取
log_time、log_level以及log_message三个字段信息,方便您分析日志。您也可以根据需求修改filter.grok.match的内容。output:输出插件。以上配置使用elasticsearch插件,相关参数说明如下。
参数
说明
hosts
阿里云ES的访问地址,设置为
http://<阿里云ES实例的私网地址>:9200。说明您可在阿里云ES实例的基本信息页面获取其私网地址,详情请参见查看实例基本信息。
user
访问阿里云ES的用户名,默认为elastic。您也可以使用自建用户,详情请参见通过Elasticsearch X-Pack角色管理实现用户权限管控。
password
访问阿里云ES的密码,在创建实例时设置。如果忘记密码,可进行重置,重置密码的注意事项及操作步骤请参见重置实例访问密码。
index
索引名称。设置为
rocketmq-%{+YYYY.MM.dd}表示索引名称以rocketmq为前缀,以日期为后缀,例如rocketmq-2020.05.27。
更多Config配置详情请参见Logstash配置文件说明。
单击下一步,配置管道参数。
参数
说明
管道工作线程
并行执行管道的Filter和Output的工作线程数量。当事件出现积压或CPU未饱和时,请考虑增大线程数,更好地使用CPU处理能力。默认值:实例的CPU核数。
管道批大小
单个工作线程在尝试执行Filter和Output前,可以从Input收集的最大事件数目。较大的管道批大小可能会带来较大的内存开销。您可以设置LS_HEAP_SIZE变量,来增大JVM堆大小,从而有效使用该值。默认值:125。
管道批延迟
创建管道事件批时,将过小的批分派给管道工作线程之前,要等候每个事件的时长,单位为毫秒。默认值:50ms。
队列类型
用于事件缓冲的内部排队模型。可选值:
MEMORY:默认值。基于内存的传统队列。
PERSISTED:基于磁盘的ACKed队列(持久队列)。
队列最大字节数
队列允许存储的最大数据量,单位为
MB。取值范围为:1~253-1的整数,默认值为1024MB。说明请确保该值小于您的磁盘总容量。
队列检查点写入数
启用持久性队列时,在强制执行检查点之前已写入事件的最大数目。设置为0,表示无限制。默认值:1024。
警告配置完成后,需要保存并部署才能生效。保存并部署操作会触发实例重启,请在不影响业务的前提下,继续执行以下步骤。
单击保存或者保存并部署。
保存:将管道信息保存在Logstash里并触发实例变更,配置不会生效。保存后,系统会返回管道管理页面。可在管道列表区域,单击操作列下的立即部署,触发实例重启,使配置生效。
保存并部署:保存并且部署后,会触发实例重启,使配置生效。
步骤三:模拟RocketMQ客户端日志
连接安装了Filebeat的ECS实例。
具体操作步骤请参见连接实例。
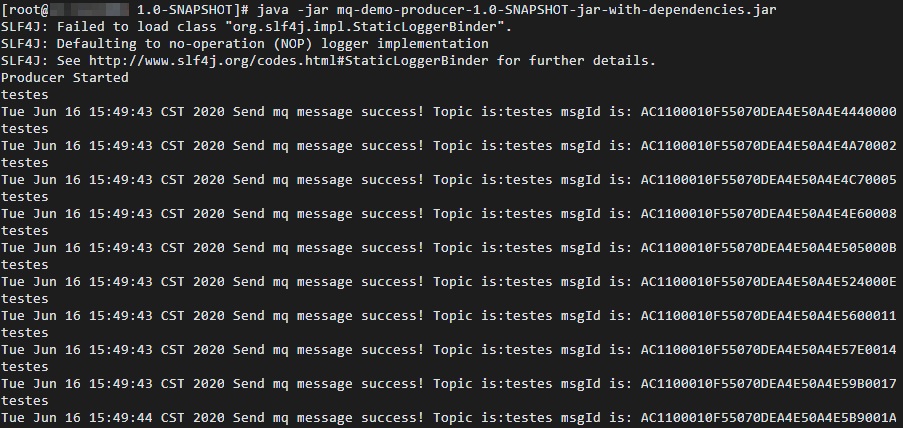
搭建并运行消息队列RocketMQ版测试工程,发送若干条测试消息,生成日志。

步骤四:通过Kibana查看日志
登录目标阿里云ES实例的Kibana控制台。
具体操作步骤请参见登录Kibana控制台。
创建一个索引模式。
在左侧导航栏,单击Management。
在Kibana区域,单击Index Patterns。
单击Create index pattern。
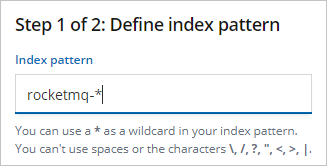
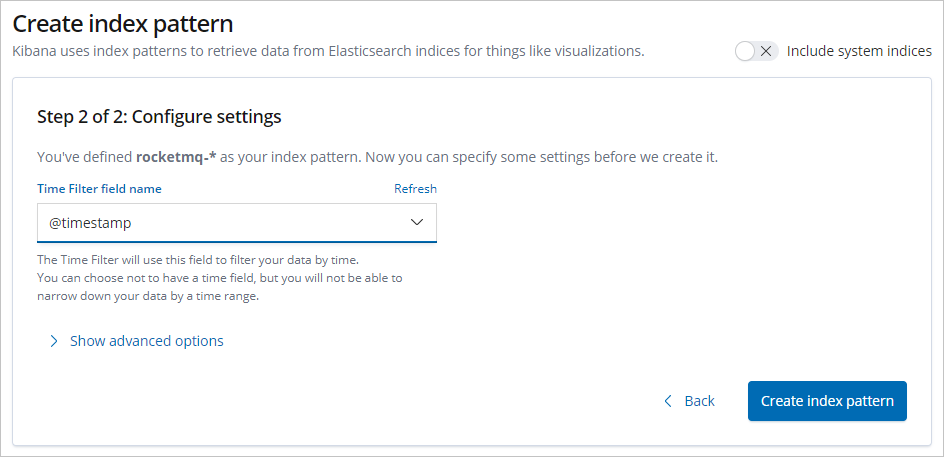
输入Index pattern(本文使用rocketmq-*),单击Next step。
选择Time Filter field name(本文选择@timestamp),单击Create index pattern。
 说明
说明选择@timestamp作为时间过滤器,可以方便通过直方图等其他可视化图表展示日志数据。
在左侧导航栏,单击Discover。
从页面左侧的下拉列表中,选择您已创建的索引模式(rocketmq-*)。
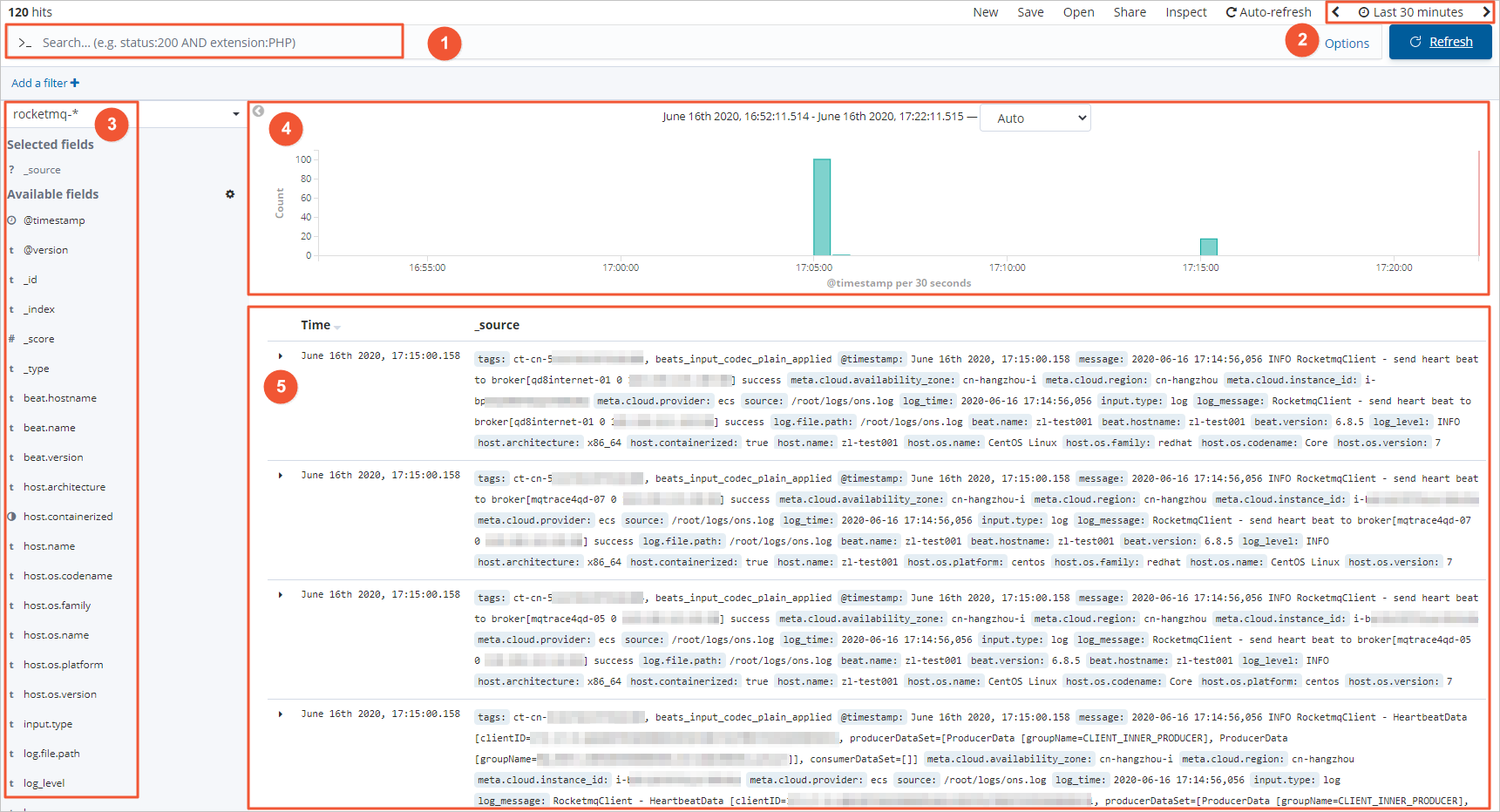
在页面右上角,选择一段时间,查看对应时间段内的Filebeat采集的日志数据。

区域
说明
①
数据查询区域。您可根据需求在此区域输入查询语句,查询语句需符合Kibana Query Language要求,例如
log_level:ERROR。②
时间和刷新频率选择区域。您可在此区域选择展示哪个时间段内的数据,以及数据刷新的频率。
③
字段选择区域。您可根据需求在此区域选择要展示的字段。
④
直方图展示区域。系统会根据创建索引模式时指定的@timestamp字段,通过直方图在此区域汇聚展示所选字段的数据。
⑤
数据展示区域。您可在此区域查看所选字段的数据。
步骤五:通过Kibana分析日志
对于Java开发类日志,开发者在运维时最为关心的是ERROR日志,以下示例演示如何筛选ERROR级别日志。为了演示需要,本例在RocketMQ控制台将topic删除,制造ERROR场景。具体分析方法如下:
在Discover页面的数据查询区域输入如下搜索语句,筛选出ERROR级别日志。
log_level:ERROR解读筛选的日志信息。
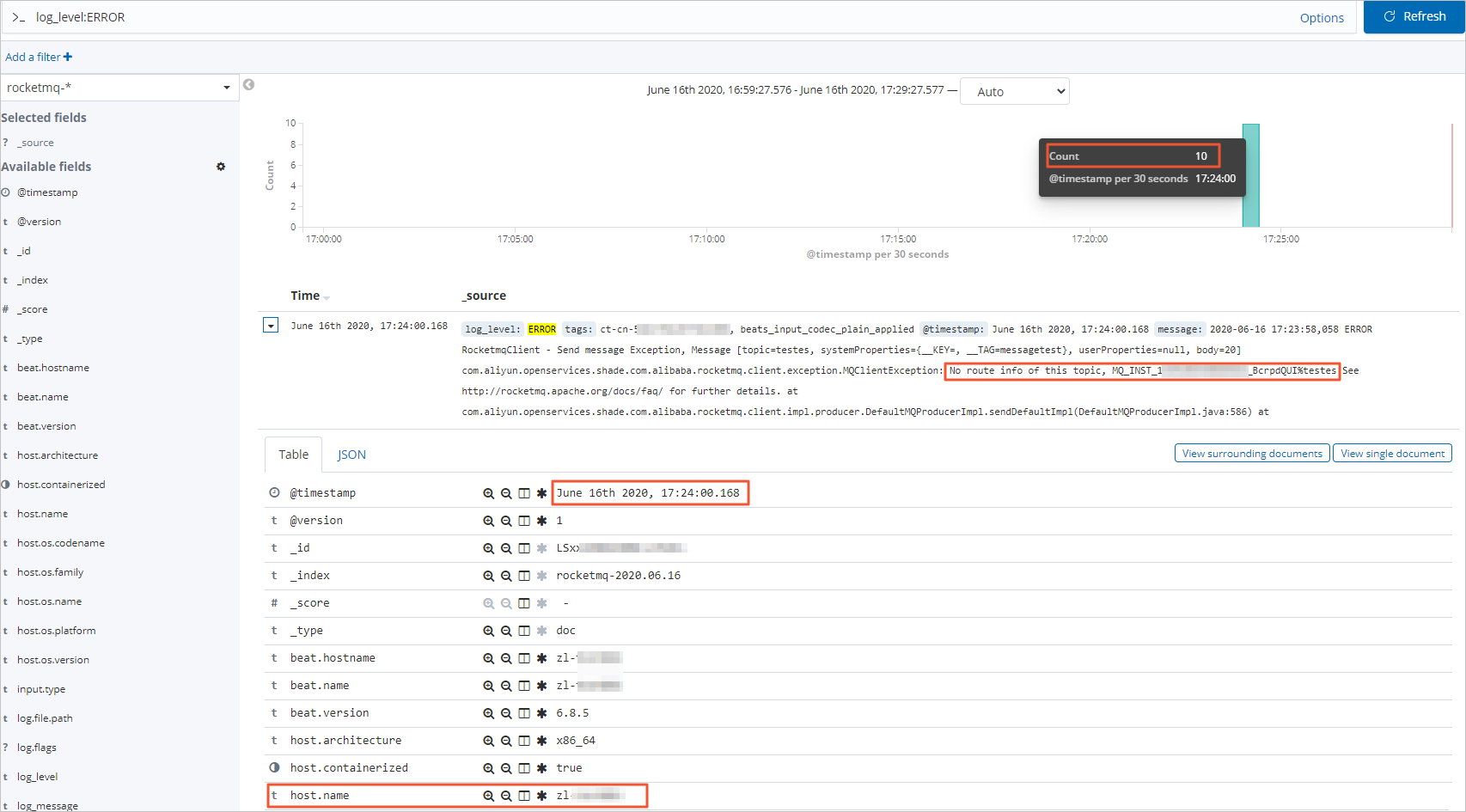
从筛选结果可以看到:
所选时间段内有10条ERROR日志。
具体的报错信息是
No route info of this topic, MQ_INST_**********_BcrpdQUI%testes,从报错信息可以判断出现ERROR日志的原因是该实例(MQ_INST_**********_BcrpdQUI)中topic(testes)的路由信息丢失,可能原因是topic配置错误、topic被误删等。报错的时间点为
June 16th 2020, 17:24:00.168。将单个报错信息展开后,还能看到具体抛出ERROR日志的主机(
host.name)信息,进而精确定位到具体的应用实例,然后通过远程登录该实例快速定位排查问题。