
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
如果您需要将RDS MySQL中的数据同步到阿里云Elasticsearch中,可使用阿里云Logstash的logstash-input-jdbc插件(默认已安装,不可卸载),通过管道配置将全量或增量数据实时同步至阿里云Elasticsearch中。本文介绍具体的实现方法。
背景信息
阿里云Logstash是一款强大的数据收集和处理工具,提供了数据采集、转换、优化和输出的能力。通过Logstash的logstash-input-jdbc插件(默认已安装,不可卸载),可批量查询RDS MySQL中的数据并同步到Elasticsearch中。同时,logstash-input-jdbc插件会定期对RDS中的数据进行轮询查询,并将自上次轮询以来插入或更改的记录同步到Elasticsearch。更多详细信息,请参见官方文档中的如何使用Logstash和JDBC确保Elasticsearch与关系型数据库保持同步。本方案适用于同步全量数据且接受秒级延迟的场景或批量查询特定条件的数据然后进行同步的场景。
前提条件
建议您在同一专有网络下创建以下实例:
您也可以使用公网环境的服务,前提是需要配置SNAT、打开RDS MySQL的公网地址并取消白名单限制。SNAT的具体配置方法,请参见配置NAT公网数据传输。设置白名单操作,请参见设置IP白名单。
创建RDS MySQL实例。具体操作请参见创建RDS MySQL实例。本文以MySQL 5.7版本为例。
创建阿里云Elasticsearch实例。具体操作请参见创建阿里云Elasticsearch实例。本文以7.10版本ES实例为例。
创建阿里云Logstash实例。具体操作参见创建阿里云Logstash实例。
使用限制
确保MySQL实例、Logstash实例、阿里云Elasticsearch实例在同一时区,否则当同步与时间相关的数据时,同步前后的数据可能存在时区差。
Elasticsearch中的_id字段必须与MySQL中的id字段相同。
该条件可以确保当您将MySQL中的记录写入Elasticsearch时,同步任务可在MySQL记录与Elasticsearch文档之间建立一个直接映射的关系。例如当您在MySQL中更新了某条记录时,同步任务会覆盖Elasticsearch中与更新记录具有相同ID的文档。
说明根据Elasticsearch内部原理,更新操作的本质是删除旧文档然后对新文档进行索引,因此在Elasticsearch中覆盖文档的效率与更新操作的效率一样高。
当您在MySQL中插入或者更新数据时,对应记录必须有一个包含更新或插入时间的字段。
Logstash每次对MySQL进行轮询时,都会保存其从MySQL所读取的最后一条记录的更新或插入时间。在读取数据时,Logstash仅读取符合条件的记录,即该记录的更新或插入时间需要晚于上一次轮询中最后一条记录的更新或插入时间。
重要logstash-input-jdbc插件无法实现同步删除,需要在Elasticsearch中执行相关命令手动删除。
操作步骤
步骤一:环境准备
在阿里云Elasticsearch实例中开启自动创建索引功能。具体操作,请参见快速访问与配置。
在Logstash实例中上传与RDS MySQL版本兼容的SQL JDBC驱动(本文使用mysql-connector-java-5.1.48.jar)。具体操作,请参见配置扩展文件。
准备测试数据,本文使用的建表语句如下。
CREATE table food ( id int PRIMARY key AUTO_INCREMENT, name VARCHAR (32), insert_time DATETIME, update_time DATETIME );插入数据语句如下。
INSERT INTO food values(null,'巧克力',now(),now()); INSERT INTO food values(null,'酸奶',now(),now()); INSERT INTO food values(null,'火腿肠',now(),now());在RDS MySQL的白名单中加入阿里云Logstash节点的IP地址(可在Logstash实例的基本信息页面获取)。
步骤二:配置Logstash管道
- 进入阿里云Elasticsearch控制台的Logstash页面。
- 进入目标实例。
- 在顶部菜单栏处,选择地域。
- 在Logstash实例中单击目标实例ID。
在左侧导航栏,单击管道管理。
单击创建管道。
在创建管道任务页面,输入管道ID,并进行Config配置。
本文使用的Config配置如下。
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash实例ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<数据库名称>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "xxxxx" jdbc_password => "xxxx" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from food where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash实例ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" } } filter { } output { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" index => "rds_es_dxhtest_datetime" user => "elastic" password => "xxxxxxx" document_id => "%{id}" } }说明代码中
<Logstash实例ID>需要替换为您创建的Logstash实例的ID。获取方式,请参见查看实例的基本信息。表 1. Config配置说明
配置
说明
input
指定输入数据源。支持的数据源类型,请参见Input plugins。本文使用JDBC数据源,具体参数说明请参见input参数说明。
filter
指定对输入数据进行过滤的插件。支持的插件类型,请参见Filter plugins。
output
指定目标数据源类型。支持的数据源类型,请参见Output plugins。本文需要将MySQL中的数据同步至Elasticsearch中,因此output中需要指定目标Elasticsearch的信息。具体参数说明,请参见步骤三:创建并运行管道任务。
重要如果output中使用了file_extend参数,需要先安装logstash-output-file_extend插件。具体操作,请参见安装或卸载插件。
表 2. input参数说明
参数
描述
jdbc_driver_class
JDBC Class配置。
jdbc_driver_library
指定JDBC连接MySQL驱动文件,格式为/ssd/1/share/<Logstash实例ID>/logstash/current/config/custom/<驱动文件名称>。您需要提前在控制台中上传驱动文件,阿里云Logstash支持的驱动文件及其上传方法,请参见配置扩展文件。
jdbc_connection_string
配置数据库连接的域名、端口及数据库,格式为
jdbc:mysql://<MySQL的连接地址>:<端口>/<数据库名称>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false。<MySQL的连接地址>:配置MySQL的内网地址。
<端口>:需要与MySQL的出方向端口保持一致,一般为3306。
说明如果使用外网地址,需要为Logstash配置NAT网关,将
jdbc:mysql://<MySQL的连接地址>:<端口>配置为公网域名,实现公网数据传输。具体操作,请参见配置NAT公网数据传输。jdbc_user
数据库用户名。
jdbc_password
数据库密码。
jdbc_paging_enabled
是否启用分页,默认false。
jdbc_page_size
分页大小。
statement
指定SQL语句,多表查询可使用join语句。
说明sql_last_value用于计算要查询哪一行,在运行任何查询之前,此值设置为1970年1月1日星期四。详细信息,请参见Jdbc input plugin。
schedule
指定定时操作,"* * * * *"表示每分钟定时同步数据。该参数使用的是Rufus版的Cron表达式。
record_last_run
是否记录上次执行结果。如果为true,则会把上次执行到的tracking_column字段的值记录下来,保存到last_run_metadata_path指定的文件中。
last_run_metadata_path
指定最后运行时间文件存放的地址。目前后端开放了
/ssd/1/<Logstash实例ID>/logstash/data/路径来保存文件。指定参数路径后,Logstash会在对应路径下自动生成文件,但不支持查看文件内容。说明配置Logstash管道时,建议按照
/ssd/1/<Logstash实例ID>/logstash/data/路径配置此参数。如果不按照该路径配置,会导致同步的条件记录因为权限不足而无法存放在last_run_metadata_path路径下的配置文件中。clean_run
是否清除last_run_metadata_path的记录,默认为false。如果为true,那么每次都要从头开始查询所有的数据库记录。
use_column_value
是否需要记录某个column的值。当该值设置成true时,系统会记录tracking_column参数所指定的列的最新的值,并在下一次管道执行时通过该列的值来判断需要更新的记录。
tracking_column_type
跟踪列的类型,默认是numeric。
tracking_column
指定跟踪列,该列必须是递增的,一般是MySQL主键。
重要以上配置按照测试数据配置,在实际业务中,请按照业务需求进行合理配置。input插件支持的其他配置选项,请参见官方Logstash Jdbc input plugin文档。
如果配置中有类似last_run_metadata_path的参数,那么需要阿里云Logstash服务提供文件路径。目前后端开放了
/ssd/1/<Logstash实例ID>/logstash/data/路径供您测试使用,且该目录下的数据不会被删除。因此在使用时,请确保磁盘有充足的使用空间。指定参数路径后,Logstash会在对应路径下自动生成文件,但不支持查看文件内容。为了提升安全性,如果在配置管道时使用了JDBC驱动,需要在jdbc_connection_string参数后面添加allowLoadLocalInfile=false&autoDeserialize=false,否则当您在添加Logstash配置文件时,调度系统会抛出校验失败的提示,例如
jdbc_connection_string => "jdbc:mysql://xxx.drds.aliyuncs.com:3306/<数据库名称>?allowLoadLocalInfile=false&autoDeserialize=false"。
更多Config配置,请参见Logstash配置文件说明。
单击下一步,配置管道参数。
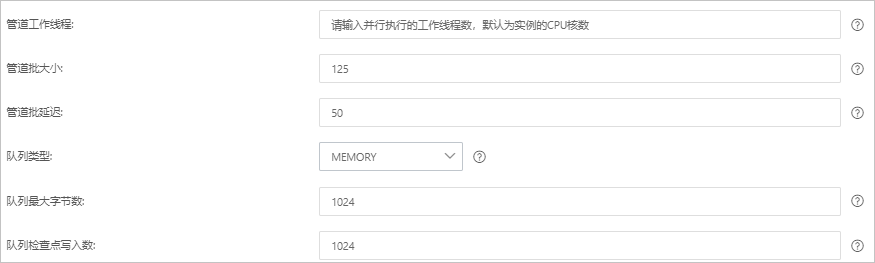
参数
说明
管道工作线程
并行执行管道的Filter和Output的工作线程数量。当事件出现积压或CPU未饱和时,请考虑增大线程数,更好地使用CPU处理能力。默认值:实例的CPU核数。
管道批大小
单个工作线程在尝试执行Filter和Output前,可以从Input收集的最大事件数目。较大的管道批大小可能会带来较大的内存开销。您可以设置LS_HEAP_SIZE变量,来增大JVM堆大小,从而有效使用该值。默认值:125。
管道批延迟
创建管道事件批时,将过小的批分派给管道工作线程之前,要等候每个事件的时长,单位为毫秒。默认值:50ms。
队列类型
用于事件缓冲的内部排队模型。可选值:
MEMORY:默认值。基于内存的传统队列。
PERSISTED:基于磁盘的ACKed队列(持久队列)。
队列最大字节数
请确保该值小于您的磁盘总容量。默认值:1024 MB。
队列检查点写入数
启用持久性队列时,在强制执行检查点之前已写入事件的最大数目。设置为0,表示无限制。默认值:1024。
警告配置完成后,需要保存并部署才能生效。保存并部署操作会触发实例重启,请在不影响业务的前提下,继续执行以下步骤。
单击保存或者保存并部署。
保存:将管道信息保存在Logstash里并触发实例变更,配置不会生效。保存后,系统会返回管道管理页面。可在管道列表区域,单击操作列下的立即部署,触发实例重启,使配置生效。
保存并部署:保存并且部署后,会触发实例重启,使配置生效。
步骤三:验证结果
登录阿里云Elasticsearch实例的Kibana控制台。
具体操作,请参见登录Kibana控制台。
在Kibana页面的左上角,选择
 > Management > Dev Tools
> Management > Dev Tools在Console中,执行如下命令,查看同步成功的索引数量。
GET rds_es_dxhtest_datetime/_count { "query": {"match_all": {}} }预期结果如下。
{ "count" : 3, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } }更新MySQL表数据并插入表数据。
UPDATE food SET name='Chocolates',update_time=now() where id = 1; INSERT INTO food values(null,'鸡蛋',now(),now());在Kibana控制台,查看更新后的数据。
查询name为Chocolates的数据。
GET rds_es_dxhtest_datetime/_search { "query": { "match": { "name": "Chocolates" }} }预期结果如下。
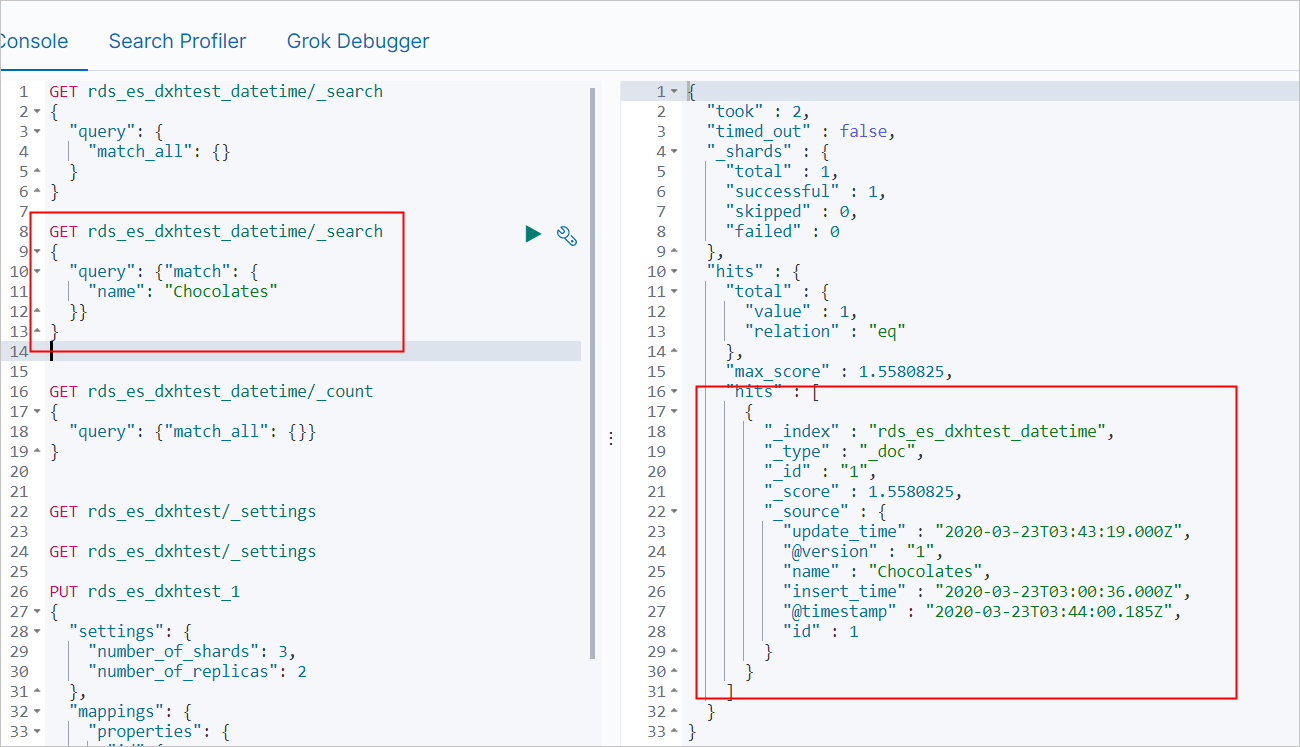
查询所有数据。
GET rds_es_dxhtest_datetime/_search { "query": { "match_all": {} } }预期结果如下。
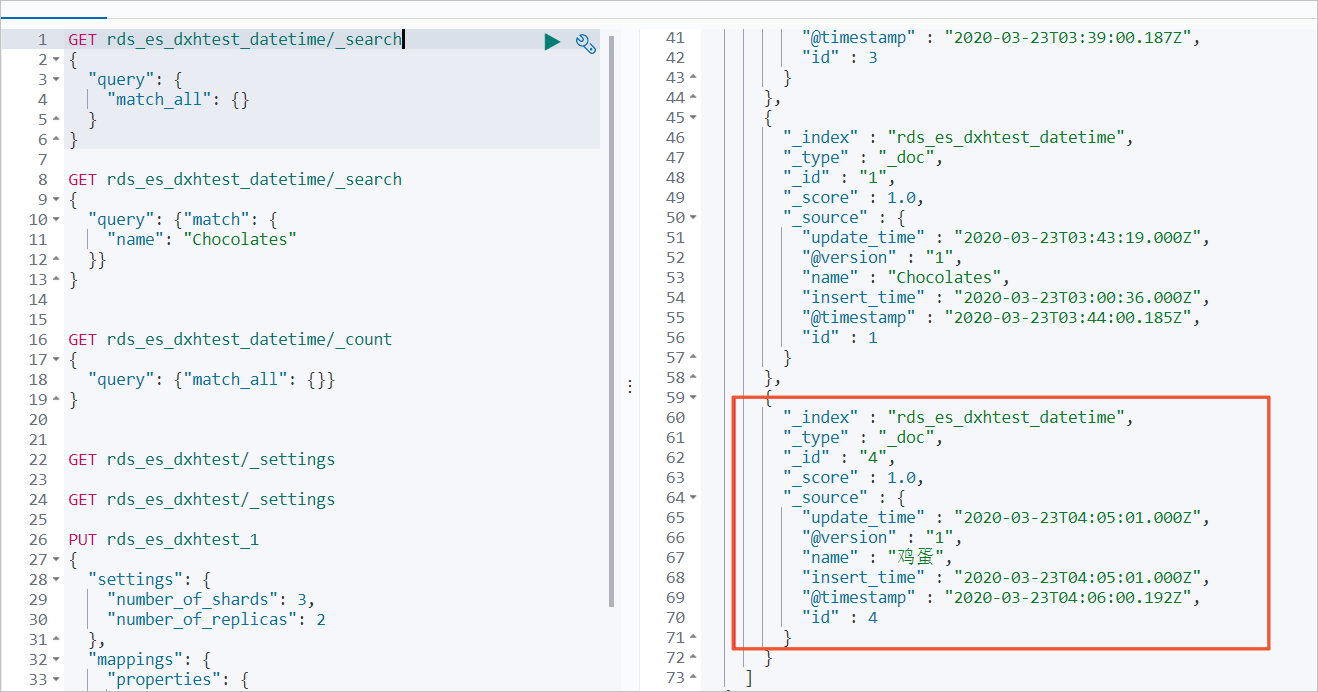
常见问题
Q:同步任务失败(例如管道一直在生效中、前后数据不一致、数据库连接不成功),如何解决?
A:查看Logstash实例的主日志是否有报错,根据报错判断原因,具体操作请参见查询日志。常见的原因及解决方法如下。
说明执行以下操作时,如果集群正在变更中,可参见查看实例任务进度详情先中断变更,操作完成后再触发重启恢复。
原因
解决方法
MySQL白名单中没有加入Logstash的IP地址。
参见通过客户端、命令行连接RDS MySQL实例,在MySQL白名单中加入Logstash节点的IP地址。
说明获取Logstash的IP地址的具体操作,请参见查看实例的基本信息。
Logstash的IP地址没有添加到对应ECS服务器的安全组中(ECS自建MySQL)。
参见添加安全组规则,在ECS安全组中添加Logstash的IP地址和端口号。
说明获取Logstash的IP地址和端口号的具体操作,请参见查看实例的基本信息。
Logstash和Elasticsearch不在同一VPC下。
选择以下任意一种方式处理:
参见创建阿里云Elasticsearch实例,重新购买同一VPC下的Elasticsearch实例。购买后,修改现有管道配置。
参见配置NAT公网数据传输,配置NAT网关实现公网数据传输。
MySQL地址不正确,端口不是3306。
参见查看和管理实例连接地址和端口,获取正确的地址和端口。使用正确的地址和端口,按照脚本格式替换管道配置中的jdbc_connection_string参数值。
重要<MySQL的连接地址>:需要配置MySQL的内网地址。如果使用外网地址,需要为Logstash配置NAT网关实现公网数据传输,具体操作请参见配置NAT公网数据传输。
Elasticsearch未开启自动创建索引。
参见配置YML参数,开启Elasticsearch实例的自动创建索引功能。
Elasticsearch或Logstash的负载太高。
参见升配集群,升级实例规格。
说明Elasticsearch负载情况可参见指标含义与异常处理建议,通过控制台监控指标查看。Logstash负载情况可参见配置X-Pack监控,通过Kibana X-Pack监控查看。
没有上传JDBC连接MySQL的驱动文件。
参见配置扩展文件,下载并上传驱动文件。
管道配置中包含了file_extend,但没有安装logstash-output-file_extend插件。
选择以下任意一种方式处理:
参见安装或卸载插件,安装logstash-output-file_extend插件。
在管道配置中,去掉file_extend配置。
更多问题原因及解决方法,请参见Logstash数据写入问题排查方案。
Q:管道input配置中,如何在一个管道中配置多个源端JDBC?
A:您可以在管道input配置中定义多个jdbc数据源,并在statement中指定对应表的查询语句,实现一个管道中配置多个源端JDBC,参考示例如下。
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash实例ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<数据库名称>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "xxxxx" jdbc_password => "xxxx" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from tableA where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash实例ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" type => "A" } jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash实例ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<数据库名称>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "xxxxx" jdbc_password => "xxxx" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from tableB where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash实例ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" type => "B" } } output { if[type] == "A" { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" index => "rds_es_dxhtest_datetime_A" user => "elastic" password => "xxxxxxx" document_id => "%{id}" } } if[type] == "B" { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" index => "rds_es_dxhtest_datetime_B" user => "elastic" password => "xxxxxxx" document_id => "%{id}" } } }以上示例在jdbc中,新增了一个属性type,用来在output中进行判断,将不同表的数据同步至不同的索引中。