
当Elasticsearch(ES)集群的CPU、内存、磁盘等资源使用率持续处于高位,或查询与写入性能无法满足业务需求时,可通过扩展节点数量、 提升节点规格、增加磁盘空间、新增节点类型等方式升级集群配置,恢复服务稳定性。
升配前须知
升配操作可能引发服务延迟、配置冲突及费用变更,请务必提前完整阅读以下须知内容。
升配前检查
未完成以下检查直接升配可能导致集群崩溃、数据丢失或服务不可用,请逐项检查验证。
集群健康
执行
GET _cluster/health确保集群为状态为GREEN。如遇集群状态不健康,请参照集群变更报错-集群状态不健康进行解决。负载安全
执行
GET _cat/nodes?v,建议CPU ≤ 60%,如果超出,客户端启用重试机制,同时增加索引副本数。索引就绪
执行
GET /_cat/indices?v检查是否存在状态为CLOSE的索引。如果存在,需执行POST /<index_name>/_open临时打开这些索引,否则配置变更可能失败,原因说明:存在CLOSE状态的索引时,集群状态无法达到GREEN。ES在执行某些敏感配置变更(如分片分配规则调整)前会强制要求集群状态为GREEN。
变配过程中集群会重新分配分片:
关闭索引的分片无法参与重分配。
导致依赖GREEN状态的操作失败。
导致集群状态无法达到GREEN(最高只能达到YELLOW)。
执行
GET _cat/indices?v检查索引副本数是否至少为1。对于多可用区实例,在变更时需确保集群中任意一个索引的副本数小于可用区数,建议副本数设置为1,变更完成后,手动增加副本数。
分片均衡
执行
GET _cat/shards?v检查是否存在不均衡的分片。重要升配前检查分片分布是否均衡,是预防升配过程中或完成后集群性能恶化甚至崩溃的关键措施。
prirep:副本分片(r)是否未分配(UNASSIGNED)。state:是否存在长期迁移卡住(RELOCATING)。
上述问题会阻止新节点正常接收分片,导致升配后集群状态持续YELLOW/RED,如存在上述问题,请参见集群负载不均解决方案进行解决。
方式一:通过控制台升配
在实例列表,单击升配。

更多操作入口:在基本信息页面,单击
在变配页面,根据业务需要调整配置项参数。
重要可调整的配置项参数因集群类型和版本不同而有所出入,以降配页面为准。
可用区数量变配规则如下,如遇可用区规格库存不足时,需迁移可用区下的节点后再升配。
扩增:支持从 1 个可用区扩增至 2 个或 3 个可用区。
支持节点规格(节点存储类型)升级,按性能从低到高排序:
上一代云盘:云盘(普通云盘)-> 高效云盘->SSD云盘。
说明已在部分地域及可用区逐步停止售卖,您在选择云盘时,建议选用ESSD云盘。
ESSD云盘:ESSD(Enterprise SSD)云盘结合25 GE网络和RDMA技术,为您提供单盘高达100万的随机读写能力和单路低时延性能。
本地盘。
说明本地盘是ECS实例所在物理机上的本地硬盘设备,为ECS实例提供本地存储访问能力,适用于对存储I/O性能、海量存储性价比有极高要求的业务场景。
智能变更(默认开启):系统根据变配项自动选择最优变更方式。可手动关闭并指定变更方式:
变更方式
原理
耗时
服务影响和使用场景
蓝绿变更
添加新节点→拷贝数据→无缝切换
较长
节点IP会发生变化、集群性能可能出现短暂波动。
适用于对变更时长不敏感,对集群可用性要求较高的场景。
原地变更
滚动更新节点(无需数据拷贝)
较短
节点IP无变化、集群性能可能出现短暂波动。
适用于集群遇到性能瓶颈,期望快速完成变更的场景。
重要如果水位较高(如CPU>60%),谨慎选择原地变更。
强制变更:跳过健康检查,但会触发集群强制重启,可能导致服务长时间中断(恢复时间取决于数据量),仅用于紧急扩容且集群已不可用场景。
单击查看产品服务协议、服务等级协议,无异议后,单击立即购买,系统按照付费方式收取费用。
变更期间,集群状态变为生效中,集群性能可能出现短暂波动,可能出现请求闪断;变更完成后,集群状态更新为正常。
方式二:调用API升配
集群升配API文档:UpdateInstance
进度监控与升配后验证
升配开始后查看进度:通过控制台->实例列表->实例基本信息:
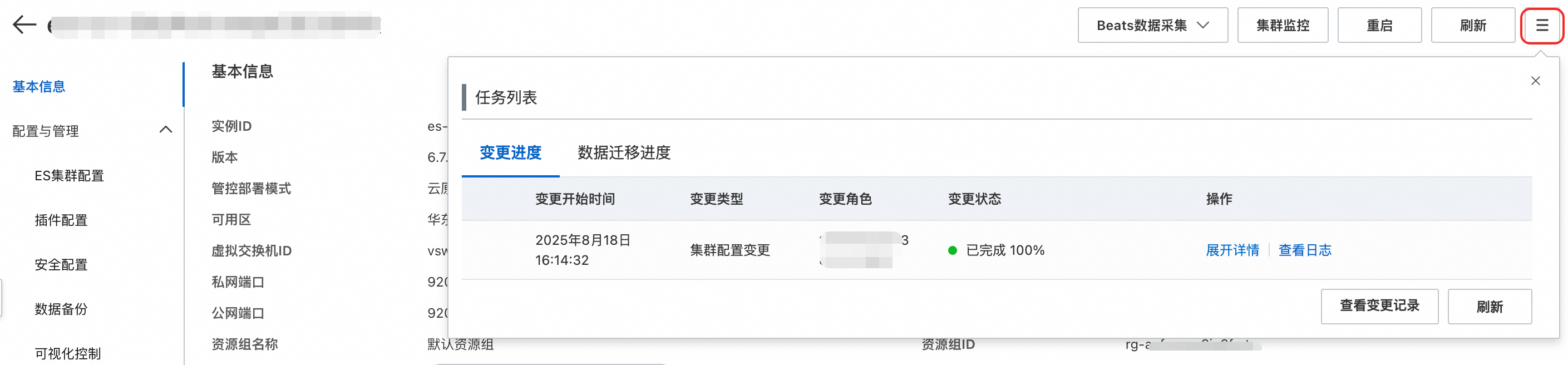
单击展开详情:
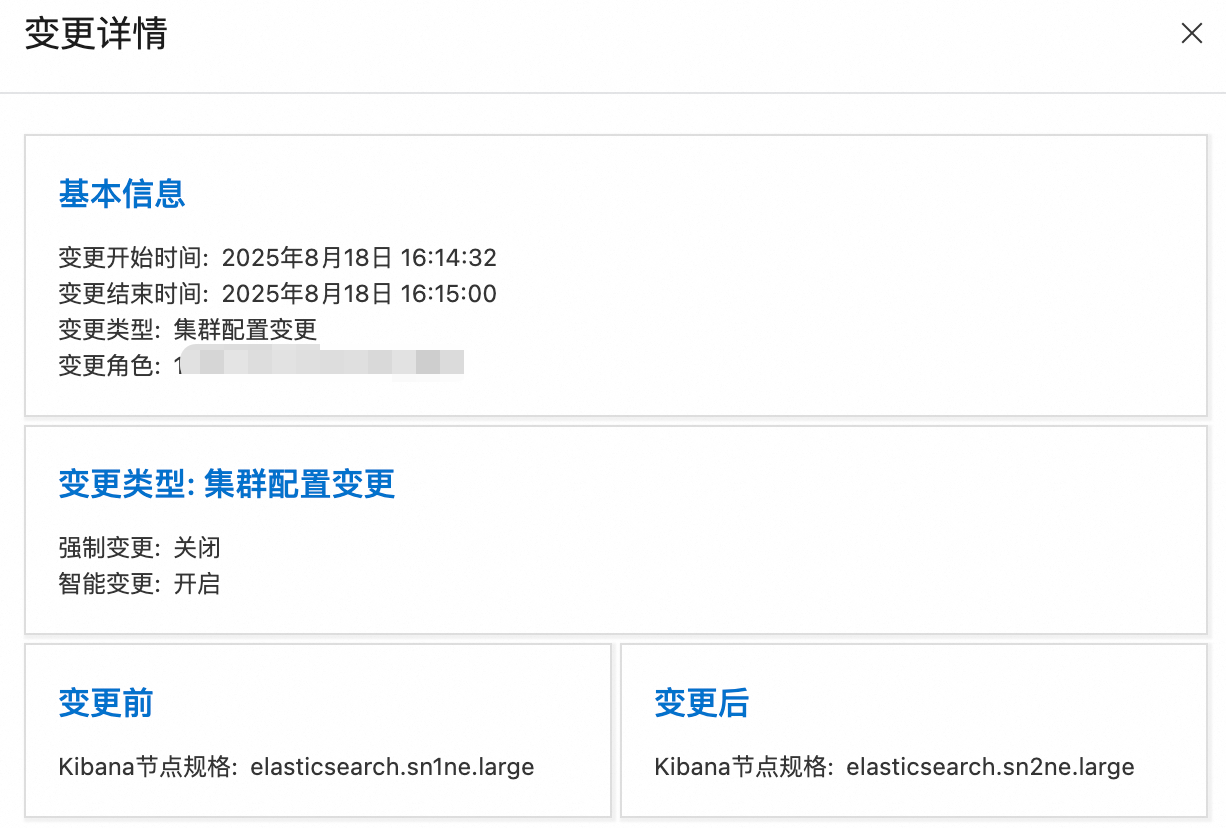
升配完成后通过集群基本信息页确认配置是否生效:
集群状态恢复为正常

可用区

节点数和存储规格:确认新节点已加入集群、存储规格是否正确。

分片均衡:
GET _cat/allocation?v检查分片分布,如遇分片不均衡,请参考集群负载不均解决方案进行解决。