
在变更集群配置或处理集群异常时,需要重启集群或其中的节点。了解不同重启方式的适用场景与风险,有助于安全、高效地完成重启操作。
重启前:健康检查与准备
为确保重启过程平稳,在执行重启操作前,需完成以下健康检查和准备工作。
确认集群健康状态
通过Kibana连接集群执行GET _cluster/health命令,确保status字段为green。例外:只有在执行强制重启时,才允许在
yellow或red状态下操作。确保数据冗余
执行GET _cat/indices?v命令,检查所有关键索引的rep(副本数) 值。确保副本数至少为
1,没有副本的索引在重启期间将无法访问。对于多可用区实例,确保任意索引的副本数都小于可用区数量。
检查并处理关闭状态的索引
执行GET _cat/indices?v命令,检查是否存在status为close的索引。原因:关闭状态的索引会导致集群健康检查失败,分片无法正常分配,从而阻塞重启流程。
操作:如果存在,执行
POST /<index_name>/_open命令将其打开。
评估集群负载
在实例的集群监控页面,检查以下核心指标,确保资源使用率满足要求,为重启过程中的分片迁移预留足够资源。节点CPU使用率:建议在80%以下。
节点HeapMemory使用率:建议在50%左右。
节点load_1m:建议低于数据节点的CPU核数。
执行重启操作
完成健康检查后,按照以下步骤执行重启。
登录阿里云Elasticsearch控制台,在左侧导航栏,单击Elasticsearch实例。
在顶部菜单栏选择目标实例所在的地域,然后单击目标实例ID,在基本信息页面,单击右上角的重启。

在弹出的重启对话框中,根据需求配置以下参数。
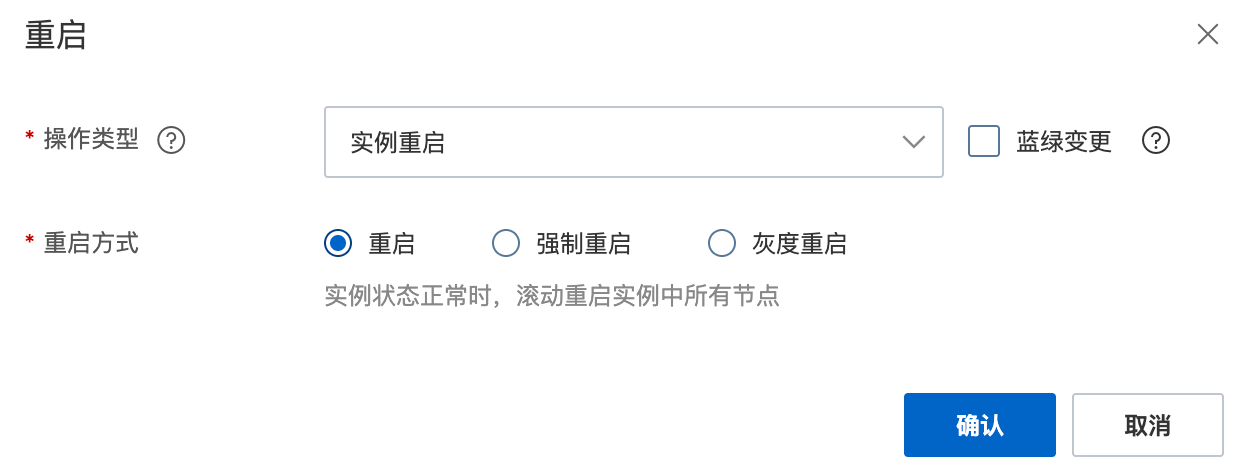
操作类型
实例重启:重启实例中的所有节点。适用于集群级别的变更。
节点重启:选择并重启一个或多个指定节点。适用于处理个别问题节点。
角色节点重启(仅适用于基础管控集群v2):按角色(如数据节点、Kibana节点)选择并重启节点。
蓝绿变更和重启方式
重启操作会影响集群的稳定性与可用性,执行重启操作前,请根据具体场景、集群状态和风险承受能力,选择合适的重启方式。
重启方式
集群状态要求
适用场景
服务影响
适用实例版本
蓝绿变更
正常 (绿色)
此操作通过向集群添加新节点,将原节点数据迁移至新节点后,再删除原节点。
该方案适用于集群中单个节点性能不佳(例如 CPU 使用率持续高位运行),且对变更时长不敏感但对集群可用性要求较高的场景。
重要蓝绿变更不允许与强制重启同时使用。
节点IP会发生变化、集群性能可能出现短暂波动。
不支持1核2GB规格
重启 (标准)
正常 (绿色)
计划内维护、集群常规配置。
节点IP无变化,重启耗时较长,在有副本分片的情况下,服务可持续提供但可能出现短暂波动。
所有版本
灰度重启
正常 (绿色)
在生产环境中,希望分批验证重启效果,降低整体风险。
选择此项后,需要先选择要灰度重启的节点。待第一批节点重启完成且集群稳定后,再手动触发后续变更以重启剩余节点。
节点IP无变化。先重启部分节点进行观察,再继续重启剩余节点。
仅限云原生新管控 (v3) 集群
强制重启
非正常 (黄色/红色)
当实例处于非健康状态(黄色或红色)时,其他重启操作将被禁用,必须执行强制重启。
重要当磁盘使用率超过
cluster.routing.allocation.disk.watermark.low阈值时,可能导致集群进入非健康状态(黄色或红色)。期间,请避免执行以下操作:节点扩容
磁盘扩容
重启(常规或强制)
修改密码
其他配置变更类操作
需待实例恢复至健康状态(绿色)后,再进行上述操作。
节点IP无变化。
提升并发度可显著加快强制重启速度,但也会带来更大影响:
高并发度风险: 若设为 100%,将同时重启所有节点,导致集群服务完全中断,且未持久化的缓存数据可能丢失。
使用建议: 集群异常需紧急恢复时使用高并发度设置。
并发度:指同时重启的节点数量,默认值为集群总节点数的 10%(向上取整,至少为 1 个节点)。例如并发度设为 10%,表示每次重启集群中 10% 的节点。
该参数仅在强制重启模式下显示。
所有版本
确认参数无误后,单击确认。
如果执行强制重启,需额外勾选确定要强制重启。操作开始后,实例状态将变为生效中,可在页面右上角的任务列表中查看重启进度。重启完成后,实例状态将恢复为正常。