
Hologres中的向量计算功能可以应用于相似度搜索、图像检索、场景识别等多种场景。通过灵活应用向量计算,可以提升数据处理和分析的效果,并实现更精准的搜索和推荐功能。本文为您介绍在Hologres中使用Proxima进行向量计算的方法及完整示例。
操作步骤
-
连接Hologres。
通过开发工具连接Hologres,详情请参见连接开发工具。如果是JDBC连接,请使用Prepare Statement模式。
-
安装Proxima插件。
Proxima是以一个Extension的方式与Hologres连通,因此在使用之前需要Superuser执行如下命令安装Proxima插件。
--安装Proxima插件 CREATE EXTENSION proxima;Proxima插件是针对数据库级别使用的,一个数据库仅需要安装一次即可,如需卸载Extension请执行如下命令。
DROP EXTENSION proxima;重要不推荐使用
DROP EXTENSION <extension_name> CASCADE;命令级联卸载Extension。CASCADE(级联)删除命令不仅会删除指定扩展本身,还会一并清除扩展数据(例如PostGIS数据、RoaringBitmap数据、Proxima数据、Binlog数据、BSI数据等)以及依赖该扩展的对象(包括元数据、表、视图、Server数据等)。 -
创建向量表和向量索引。
向量在Hologres中一般用FLOAT4数组表示,创建向量表的语法如下。
说明-
仅列存、行列共存表支持向量索引,行存表不支持。
-
定义向量时,数组维度仅支持定义为
1,即array_ndims、array_length的第二入参都必须设置为1。 -
Hologres V2.0.11版本起,支持先导入数据、再创建向量索引,无需对compaction过程中的文件构建向量索引,缩短索引创建时间。
-
先创建向量索引、再导入数据:适用于实时数据场景。
--设置单个索引 BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) --定义向量 ); CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); --构建向量索引 COMMIT; --设置多个索引 BEGIN; CREATE TABLE t1 ( f1 INT PRIMARY KEY, f2 FLOAT4[] NOT NULL CHECK(array_ndims(f2) = 1 AND array_length(f2, 1) = 4), f3 FLOAT4[] NOT NULL CHECK(array_ndims(f3) = 1 AND array_length(f3, 1) = 4) ); CALL set_table_property( 't1', 'proxima_vectors', '{"f2":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}, "f3":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT; -
先导入数据、再创建向量索引:适用于离线分析场景。
说明Hologres从V2.1.17版本起支持Serverless Computing能力,针对大数据量向量离线导入、大数据量向量查询等场景,使用Serverless Computing执行该类任务可以直接使用额外的Serverless资源,避免使用实例自身资源,无需为实例预留额外的计算资源,显著提升实例稳定性、减少OOM概率,且仅需为任务单独付费。Serverless Computing详情请参见Serverless Computing,Serverless Computing使用方法请参见Serverless Computing使用指南。
--设置单个索引 BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) --定义向量 ); COMMIT; -- (可选)推荐使用Serverless Computing执行大数据量离线导入和ETL作业 SET hg_computing_resource = 'serverless'; -- 导入数据 INSERT INTO feature_tb ...; VACUUM feature_tb; -- 构建向量索引 CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- 重置配置,保证非必要的SQL不会使用serverless资源。 RESET hg_computing_resource;
参数说明如下。
分类
参数
描述
示例
向量基本属性
feature_col
向量列名称。
feature。
array_ndims
向量的维度,仅支持一维向量。
构建一维且长度为4的向量示例如下。
feature float4[] check(array_ndims(feature) = 1 and array_length(feature, 1) = 4)array_length
向量的长度,最大不超过1000000。
向量索引
proxima_vectors
代表构建向量索引,其中:
-
algorithm:用于指定构建向量索引的算法,目前仅支持
Graph。 -
distance_method:用于定义构建向量索引使用的距离计算方法,目前支持三种距离计算函数:
-
(推荐使用)SquaredEuclidean:平方欧式距离, 查询效率最高。适合查询时使用
pm_approx_squared_euclidean_distance。 -
Euclidean:开方的欧式距离,仅适合查询时使用
pm_approx_euclidean_distance,如果使用其他距离函数会利用不上索引。 -
InnerProduct(避免使用):内积距离,会在底层转换为开方的欧式距离的计算,所以构建索引和查询索引都会多一层计算开销,比较低效,尽量避免使用,除非业务有强需求。仅适合查询时使用
pm_approx_inner_product_distance。
-
-
builder_params:控制索引构建的参数,是一个JSON格式的字符串,包含以下参数。
-
min_flush_proxima_row_count:数据写入到磁盘时建索引的最少行数,建议值为1000。
-
min_compaction_proxima_row_count:数据在磁盘做合并时建索引的最小行数,建议值为1000。
-
max_total_size_to_merge_mb: 数据在磁盘做合并时的最大文件大小,单位MB,建议值为2000。
-
-
proxima_builder_thread_count:控制写入时build向量索引的线程数,默认值为4,一般场景无需修改。
说明索引需要在一定的场景下使用才能发挥更好的作用。
使用平方欧式距离查询,构建对应的向量索引示例如下。
call set_table_property( 'feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph", "distance_method":"SquaredEuclidean", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -
-
向量导入。
可以通过离线或者实时的方式将数据导入至向量表,详情请参见数据同步概述,可以根据业务需求选择合适的同步方式。但需要注意的是,在批量导入后,需要执行VACUUM和Analyze命令以提升查询效率。
-
VACUUM会让后端的文件compaction成更大的文件,对查询更高效。 但是VACUUM需要耗费一定的CPU资源,表的数据量越大,执行VACUUM的时间越久,当VACUUM还在执行中时,请耐心等待执行结果。
VACUUM <tablename>; -
Analyze是收集统计信息,用于优化器QO(Query Optimizer)生成较优的执行计划,提高查询性能。
analyze <tablename>;
-
-
向量查询。
Hologres支持精确和近似向量查询,其中以
pm_开头的UDF都为精准查询,以pm_approx_开头的UDF都为近似查询。只有以pm_approx_开头的非精确查询才能命中向量索引,对于构建向量索引的场景,更建议使用近似查询,查询效率会更高。只有单表查询时才能命中向量索引,优先推荐单表向量查询,避免join操作。-
近似查询(使用向量索引)
非精确查询可以命中向量索引,更适用于扫描数据量大,要求执行效率更高的场景,默认召回精度99%以上。使用向量索引,只需要在对应的距离计算函数前加上
approx_前缀,对应的距离计算函数如下:说明-
平方欧式距离、欧式距离的非精确查询,只支持
order by distance asc场景下命中向量索引,不支持倒序。 -
内积距离的非精确查询,只支持
order by distance desc场景下命中向量索引,不支持正序。
FLOAT4 pm_approx_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_inner_product_distance(FLOAT4[], FLOAT4[])同时查询时的函数需要和建表时的
proxima_vector参数中的distance_method一一对应,使用示例如下。示例使用如下的方式查询Top N,且近似查询中的第二个参数必须是常量值。说明索引查询是有损查询,会有一定的精度损失,默认召回精度一般在99%以上。
-- 计算平方欧式距离的TOPK,此时建表里面的proxima_vector参数的distance_method需要为SquaredEuclidean SELECT pm_approx_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 计算欧式距离的TOPK,此时建表里面的proxima_vector参数的distance_method需要为Euclidean SELECT pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 计算内积距离的TOPK,此时建表里面的proxima_vector参数的distance_method需要为InnerProduct SELECT pm_approx_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ; -
-
精确查询(不使用向量索引)
精确查询更加适用于SQL扫描数据量少,且对召回率要求高的场景。欧式距离、平方欧式距离、内积距离三种距离计算方式分别对应以下三种距离计算函数。
FLOAT4 pm_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_inner_product_distance(FLOAT4[], FLOAT4[])如果召回和目标向量距离最近的TOP K个邻居,可以使用以下SQL进行查询。
说明示例中是进行精确召回计算的SQL。执行过程为:扫描feature列的所有向量进行距离计算,最后将计算结果排序,取前10条输出。这种SQL适合数据量小,对召回率要求特别高的场景。
-- 召回平方欧式距离最近的10个邻居 SELECT pm_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 召回欧式距离最近的10个邻居 SELECT pm_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 召回内积距离最大的10个邻居 SELECT pm_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;
-
完整使用示例
对4维x10万的向量表,使用Proxima索引召回平方欧式距离最近的40条数据示例如下。
-
创建向量表。
CREATE EXTENSION proxima; BEGIN; -- 新建一个shard_count = 4 的table group CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE feature_tb ( id BIGINT, feature FLOAT4[] CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = 4) ); CALL set_table_property ('feature_tb', 'table_group', 'test_tg_shard_4'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params": {"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT; -
数据导入。
-- (可选)推荐使用Serverless Computing执行大数据量离线导入和ETL作业 SET hg_computing_resource = 'serverless'; INSERT INTO feature_tb SELECT i, ARRAY[random(), random(), random(), random()]::FLOAT4[] FROM generate_series(1, 100000) i; ANALYZE feature_tb; VACUUM feature_tb; -- 重置配置,保证非必要的SQL不会使用serverless资源。 RESET hg_computing_resource; -
查询。
-- (可选)使用Serverless Computing执行大数据量向量查询作业 SET hg_computing_resource = 'serverless'; SELECT pm_approx_squared_euclidean_distance (feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance LIMIT 40; -- 重置配置,保证非必要的SQL不会使用serverless资源。 RESET hg_computing_resource;
性能调优
-
设置向量索引的场景
数据量较小,比如几万条数据情况下,建议不设置索引直接计算即可。 或者实例资源较多的情况下但查询的数据量较少,也可以直接计算。 当直接计算满足不了需求(如延迟、吞吐等要求)时,可以考虑使用Proxima索引, 原因如下。
-
Proxima本身是有损索引,不保证结果的准确性,即计算出来的距离可能是有偏差的。
-
Proxima索引有可能导致召回的条数不足,如
limit 1000情况下,只返回了500条。 -
Proxima索引使用有一定难度。
-
-
设置合适的Shard Count
Shard Count越多, 实际构建Proxima索引的文件就越多, 查询吞吐就越差。所以在实际使用中,根据实例资源建议设置合理的Shard Count,一般可以将Shard Count设置为Worker的数量,例如64 Core的实例建议设置Shard Count为4。同时如果想减少单条查询的延时,可以减小Shard Count,但是这会降低写入性能。
-- 创建向量表,并且放于shard_count = 4 的table group中 BEGIN; CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE proxima_test ( id BIGINT NOT NULL, vectors FLOAT4[] CHECK (array_ndims(vectors) = 1 AND array_length(vectors, 1) = 128), PRIMARY KEY (id) ); CALL set_table_property ('proxima_test', 'proxima_vectors', '{"vectors":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params":{}, "searcher_init_params":{}}}'); CALL set_table_property ('proxima_test', 'table_group', 'test_tg_shard_4'); COMMIT; -
(推荐)不带过滤条件的查询场景
在有
where过滤条件的情况下,会影响索引使用,性能可能更差,所以推荐不带过滤条件的查询场景。对于不带过滤条件的向量检索,最极致的状态就是一个Shard上只有一个向量索引文件,这样查询就能直接落在一个Shard上。因此对于不带过滤条件的查询场景通常建表如下。
BEGIN; CREATE TABLE feature_tb ( uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) --定义向量 ); CALL set_table_property ('feature_tb', 'shard_count', '?'); --指定shard count,根据业务情况合理设置,若有可以不设置 CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}}'); --构建向量索引 END; -
带过滤条件的查询场景
对于带过滤条件的向量检索,情况细分为如下常见的过滤场景。
-
查询场景1:字符串列为过滤条件
示例查询如下,常见的场景为在某个组织内查找对应的向量数据,例如查找班级内的人脸数据。
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE uuid = 'x' ORDER BY d limit 10;建议进行如下优化。
-
将uuid设置为Distribution Key,这样相同的过滤数据会保存在同一个Shard,查询时一次查询只会落到一个Shard上。
-
将uuid设置为表的Clustering Key,数据将会在文件内根据Clustering Key排序。
-
-
查询场景2:时间字段为过滤条件
示例查询如下,一般是根据时间字段过滤出对应的向量数据。建议将时间字段time_field设置为表的segment_key,可以快速的定位到数据所在的文件。
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE time_field BETWEEN '2020-08-30 00:00:00' AND '2020-08-30 12:00:00' ORDER BY d limit 10;
因此对于带过滤条件的向量检索而言,其建表语句通常如下。
BEGIN; CREATE TABLE feature_tb ( time_field timestamptz NOT NULL, uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) ); CALL set_table_property ('feature_tb', 'distribution_key', 'uuid'); CALL set_table_property ('feature_tb', 'segment_key', 'time_field'); CALL set_table_property ('feature_tb', 'clustering_key', 'uuid'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}}'); COMMIT; -- 如果没有按照时间过滤的话,则time_field相关的索引可以删除。 -
常见问题
-
报错
ERROR: function pm_approx_inner_product_distance(real[], unknown) does not exist。原因:通常是因为未在数据库中执行
create extension proxima;语句来初始化Proxima插件。解决方法:执行
create extension proxima;语句初始化Proxima插件。 -
报错
Writing column: feature with array size: 5 violates fixed size list (4) constraint declared in schema。原因:由于写入到特征向量列的数据维度与表中定义的维度数不一致,导致出现该报错。
解决方法:可以排查下是否有脏数据。
-
报错
The size of two arrays must be the same in DistanceFunction, size of left array: 4, size of right array:。原因:由于
pm_xx_distance(left, right)中,left的维度与right的维度不一致所致。调整
pm_xx_distance(left, right)中,left的维度与right的维度一致。 -
实时写入报错
BackPressure Exceed Reject Limit ctxId: XXXXXXXX, tableId: YY, shardId: ZZ。原因:实时写入作业遇到了瓶颈,产生了反压的异常,说明写入作业开销大,写入慢,通常是由于min_flush_proxima_row_count较小,而实时写入速度较大,造成写入作业实时构建索引开销大,阻塞了实时写入。
调整min_flush_proxima_row_count为更大值。
-
如何通过Java写入向量数据?
通过Java写入向量数据的示例如下。
private static void insertIntoVector(Connection conn) throws Exception { try (PreparedStatement stmt = conn.prepareStatement("insert into feature_tb values(?,?);")) { for (int i = 0; i < 100; ++i) { stmt.setInt(1, i); Float[] featureVector = {0.1f,0.2f,0.3f,0.4f}; Array array = conn.createArrayOf("FLOAT4", featureVector); stmt.setArray(2, array); stmt.execute(); } } } -
如何通过执行计划检查是否利用上Proxima索引?
如果执行计划中存在
Proxima filter: xxxx表明使用了索引,如下所示;如果没有,则索引没有使用上,一般是建表语句与查询语句不匹配。执行explain analyze语句,若执行计划中出现Proxima Filter: ProximaCond,则说明查询已利用 Proxima 索引。示例如下。test=# explain analyze select pm_approx_squared_euclidean_distance(feature, array[0.1,0.1,0.1,0.1,0.2]::float4[]) from test_get_ordered_array_according_to_docs order by 1 limit 10; QUERY PLAN Limit (cost=0.00..27.64 rows=0 width=4) -> Sort (cost=0.00..27.56 rows=10 width=4) Sort Key: (ProximaDistanceRef) [node_id=7; Row_count=10; Avg_Open_Time=0ms; Max_Open_Time=0ms; Min_Open_Time=0ms; Avg_Get_Next_Time=0ms; Max_Get_Next_Time=0ms; Min_Get_Next_Time=0ms] -> Exchange (Gather Exchange) (cost=0.00..1.68 rows=10 width=4) [node_id=6; Row_count=10; Avg_Open_Time=0ms; Max_Open_Time=0ms; Min_Open_Time=0ms; Avg_Get_Next_Time=0ms; Max_Get_Next_Time=0ms; Min_Get_Next_Time=0ms] -> Decode (cost=0.00..1.68 rows=10 width=4) [node_id=4; Row_count=10; Avg_Open_Time=0ms; Max_Open_Time=0ms; Min_Open_Time=0ms; Avg_Get_Next_Time=0ms; Max_Get_Next_Time=0ms; Min_Get_Next_Time=0ms] -> Result (cost=0.00..1.58 rows=10 width=4) -> Index Scan using holo_index:[1] on test_get_ordered_array_according_to_docs (cost=0.00..0.53 rows=10 width=1) Proxima Filter: ProximaCond -> KNN: $5 distance_method: pm_approx_squared_euclidean_distance search_params: {NULL} args: {featureARRAY[$1, $2, $3, $4]}
距离函数说明
Hologres支持的三种向量距离评估函数如下:
-
不开方的欧式距离(SquaredEuclidean),计算公式如下。
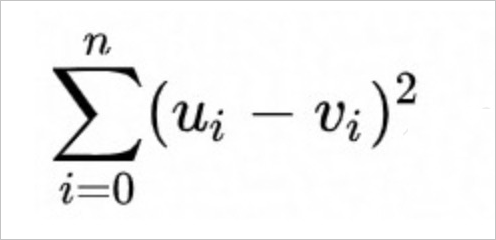
-
开方的欧氏距离(Euclidean),计算公式如下。
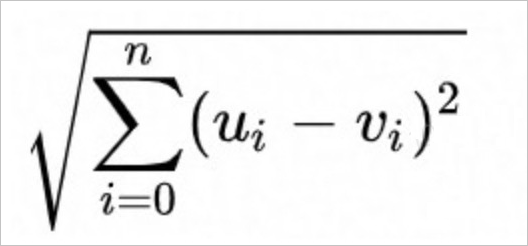
-
内积距离(InnerProduct),计算公式如下。
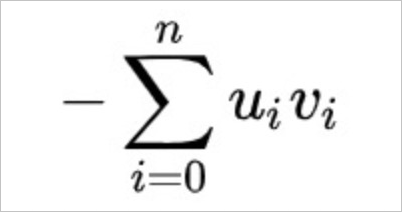
如果您选用欧式距离进行向量计算,不开方的欧式距离与开方的欧式距离相比,可以少一个开方的计算,并且计算出的Top K记录一致。因此,不开方的欧式距离性能更好,在满足功能需求的情况下,一般建议您使用不开方的欧式距离。