
本文基于使用主账号且从控制台获取测试Token的方式,为您介绍快速入门体验或轻量级开发测试,助您快速体验语音产品能力。
前提条件
已按照从这里开始完成准备阿里云主账号、开通服务、管理项目和通过控制台获取Token等操作。
体验方式
使用方法 | 说明 |
命令行操作,无需开发,可上传60s以内的音频。 | |
图形化界面操作,无需开发,可上传60s以内的音频。 | |
使用Java开发语言调用SDK,可用于生产环境。 | |
Python脚本示例,可上传长语音文件(512 MB以内)。 | |
使用Java开发语言调用SDK,可用于生产环境。 | |
命令行操作,无需开发,合成语音可下载。 说明 该服务无免费试用版,如果您希望体验长文本语音合成服务,请前往控制台将该服务升级为商用版。 | |
图形化界面操作,无需开发,合成语音可下载。 说明 该服务无免费试用版,如果您希望体验长文本语音合成服务,请前往控制台将该服务升级为商用版。 |
若您想了解更多SDK方式体验,请参见SDK概览。
通过Curl命令调用一句话识别RESTful接口
请准备一份时长在60s以内、单通道、16K采样率的录音文件(格式:WAVE Audio, Microsoft PCM, 16 Bit, Mono 16000 Hz)。您可以使用我们为您准备的示例录音文件。
在命令行操作页面,执行以下命令。
curl -X POST -H "X-NLS-Token: d9afc8a07b154e0b86d415226******" "http://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/asr?appkey=TuBrUhcloN******" --data-binary @./nls-sample-16k.wav说明示例中的d9afc8a07b154e0b86d415226******为您从智能语音交互控制台总览获取的Token;TuBrUhcloN******为您从智能语音交互控制台创建项目后,获取到的Appkey。
若您在Windows命令行窗口执行上述命令,您可以对上述HTTP的URL部分无需加引号。
若您了解得更多的接口说明,请参见接口说明。
命令执行完成以后,您可以获得如下识别结果。
{"task_id":"12964b9b46d046ae8f377fd516df****","result":"北京的天气","status":20000000,"message":"SUCCESS"}%
通过Postman调用一句话识别RESTful接口
请先下载Postman。
请准备一份时长在60s以内、单通道、16K采样率的录音文件(格式:WAVE Audio, Microsoft PCM, 16 Bit, Mono 16000Hz)。您可以使用我们为您准备的示例录音文件。
在Postman里发送如下Post请求。
参数
示例
请求URL
http://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/asr
Params
appkey:TuBrUhcloN*****,请在智能语音交互控制台获取Appkey。
Header
X-NLS-Token:d9afc8a07b154e0b86d415226******,请在智能语音交互控制台总览单击点击获取临时AccessToken。
Body
Binary格式,上传语音文件,例如nls-sample-16k.wav。
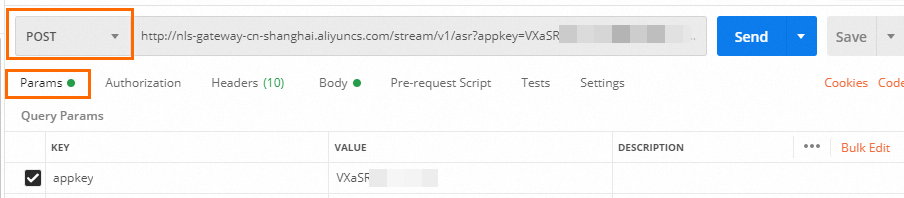
请按照下图填写Post URL与Params。
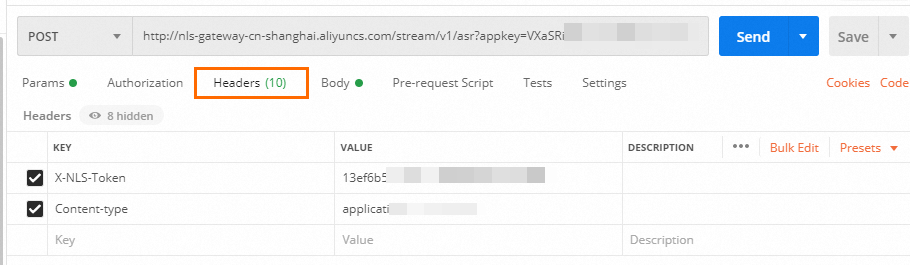
请按照下图填写Headers。
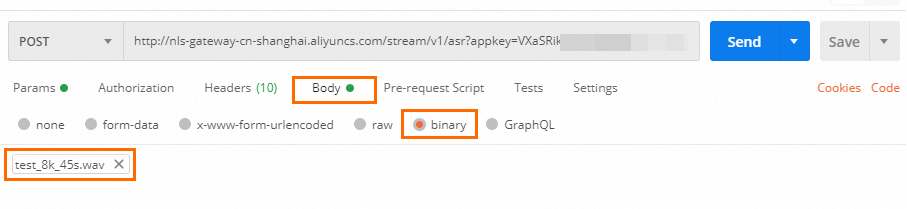
请按照下图填写Body。
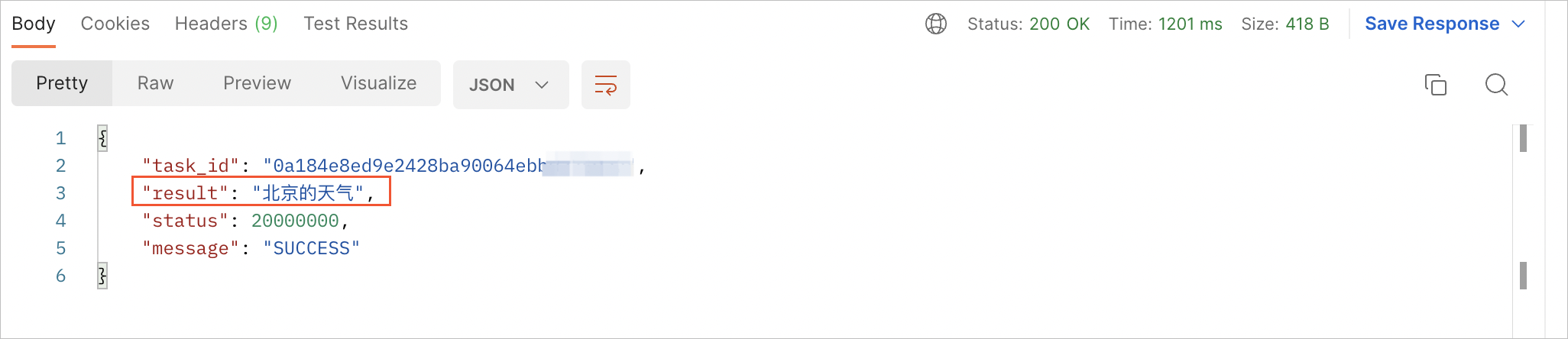
Response返回后,其中result即语音识别结果。
若您想查看一句话识别完整的接口文档,请参见接口说明。
通过SDK调用实时语音识别
在IDE编辑器中,打开上一步中下载的示例代码,填写Appkey以及Token等参数。填写完成后,单击鼠标右键,选择Run "SpeechTranscriberDemo main()"。
参数
参数值
Appkey
请在智能语音交互控制台获取Appkey。
Token
请在智能语音交互控制台总览单击点击获取临时AccessToken。
FilePath
默认:nls-sample-16k.wav ,语音文件在SDK代码包路径下,以本地文件模拟实时流式发送数据。
其他测试语音需满足实时识别语音格式要求,且放到SDK代码包路径下。
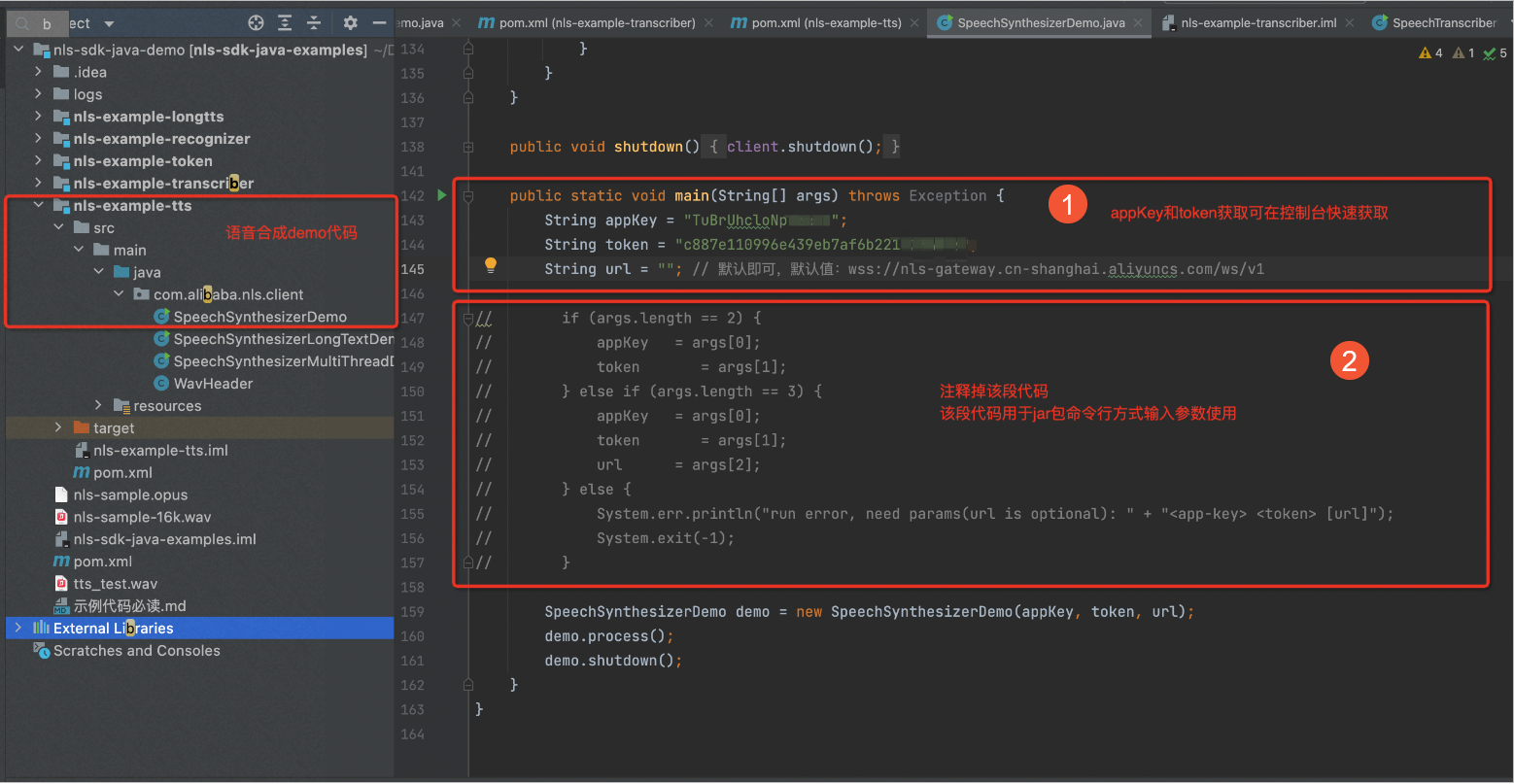
①:获取Appkey和Token,请参见从这里开始。
②:注释掉该段代码,该段代码用于JAR包命令行方式输入参数使用。
实时识别返回结果如下,result即为识别结果。
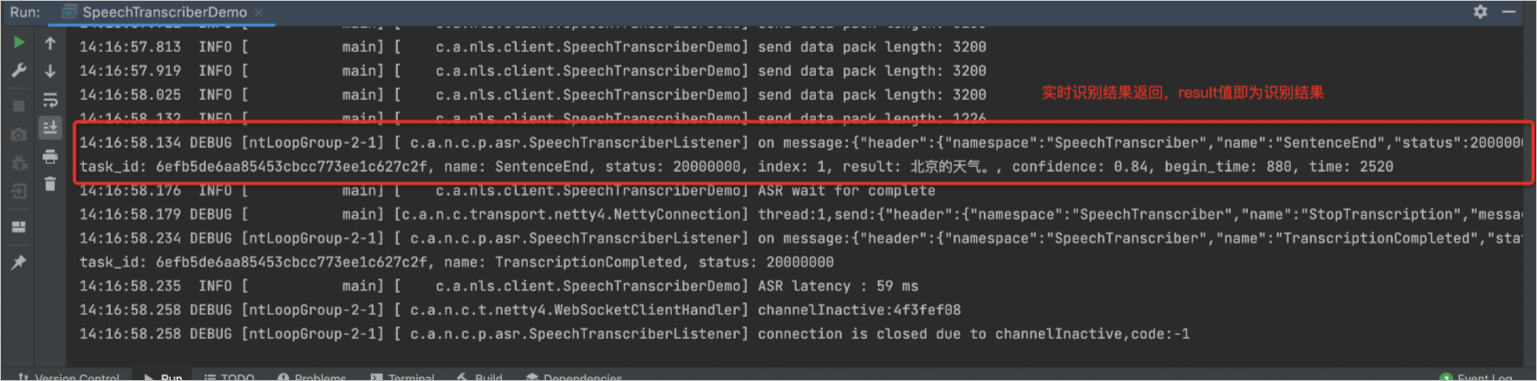
若您了解得更多的语音识别接口文档,请参见接口说明。
通过Python示例调用录音文件转写
调用接口前,需配置环境变量,通过环境变量读取访问凭证。智能语音交互的AccessKey ID、AccessKey Secret和AppKey的环境变量名:ALIYUN_AK_ID、ALIYUN_AK_SECRET、NLS_APP_KEY。
安装Python3以及Python SDK。
请先安装Python3。
执行如下命令,使用PIP安装(推荐)Aliyun-python-sdk-core,安装版本为2.13.3。
pip install aliyun-python-sdk-core==2.13.3
复制示例代码,填写参数。
获取如下参数。
参数
参数值
AccessKeyID
两者配套使用,请在访问控制台查看。
AccessKeySecret
Appkey
请在智能语音交互控制台获取Appkey。
FileLink
默认Demo测试录音。如需测试其他录音需上传录音文件至OSS,格式请参见接口说明;若OSS中文件访问权限未公开,请先获取访问链接,更多内容,请参见如何获取单个或多个文件的URL。
复制如下示例代码,修改上一步中的参数,保存到一个Python程序中,如《demo.py》。
# -*- coding: utf8 -*- import json import time from aliyunsdkcore.acs_exception.exceptions import ClientException from aliyunsdkcore.acs_exception.exceptions import ServerException from aliyunsdkcore.client import AcsClient from aliyunsdkcore.request import CommonRequest def fileTrans(akId, akSecret, appKey, fileLink) : # 地域ID,固定值。 REGION_ID = "cn-shanghai" PRODUCT = "nls-filetrans" DOMAIN = "filetrans.cn-shanghai.aliyuncs.com" API_VERSION = "2018-08-17" POST_REQUEST_ACTION = "SubmitTask" GET_REQUEST_ACTION = "GetTaskResult" # 请求参数 KEY_APP_KEY = "appkey" KEY_FILE_LINK = "file_link" KEY_VERSION = "version" KEY_ENABLE_WORDS = "enable_words" # 是否开启智能分轨 KEY_AUTO_SPLIT = "auto_split" # 响应参数 KEY_TASK = "Task" KEY_TASK_ID = "TaskId" KEY_STATUS_TEXT = "StatusText" KEY_RESULT = "Result" # 状态值 STATUS_SUCCESS = "SUCCESS" STATUS_RUNNING = "RUNNING" STATUS_QUEUEING = "QUEUEING" # 创建AcsClient实例 client = AcsClient(akId, akSecret, REGION_ID) # 提交录音文件识别请求 postRequest = CommonRequest() postRequest.set_domain(DOMAIN) postRequest.set_version(API_VERSION) postRequest.set_product(PRODUCT) postRequest.set_action_name(POST_REQUEST_ACTION) postRequest.set_method('POST') # 新接入请使用4.0版本,已接入(默认2.0)如需维持现状,请注释掉该参数设置。 # 设置是否输出词信息,默认为false,开启时需要设置version为4.0。 task = {KEY_APP_KEY : appKey, KEY_FILE_LINK : fileLink, KEY_VERSION : "4.0", KEY_ENABLE_WORDS : False} # 开启智能分轨,如果开启智能分轨,task中设置KEY_AUTO_SPLIT为True。 # task = {KEY_APP_KEY : appKey, KEY_FILE_LINK : fileLink, KEY_VERSION : "4.0", KEY_ENABLE_WORDS : False, KEY_AUTO_SPLIT : True} task = json.dumps(task) print(task) postRequest.add_body_params(KEY_TASK, task) taskId = "" try : postResponse = client.do_action_with_exception(postRequest) postResponse = json.loads(postResponse) print (postResponse) statusText = postResponse[KEY_STATUS_TEXT] if statusText == STATUS_SUCCESS : print ("录音文件识别请求成功响应!") taskId = postResponse[KEY_TASK_ID] else : print ("录音文件识别请求失败!") return except ServerException as e: print (e) except ClientException as e: print (e) # 创建CommonRequest,设置任务ID。 getRequest = CommonRequest() getRequest.set_domain(DOMAIN) getRequest.set_version(API_VERSION) getRequest.set_product(PRODUCT) getRequest.set_action_name(GET_REQUEST_ACTION) getRequest.set_method('GET') getRequest.add_query_param(KEY_TASK_ID, taskId) # 提交录音文件识别结果查询请求 # 以轮询的方式进行识别结果的查询,直到服务端返回的状态描述符为"SUCCESS"、"SUCCESS_WITH_NO_VALID_FRAGMENT", # 或者为错误描述,则结束轮询。 statusText = "" while True : try : getResponse = client.do_action_with_exception(getRequest) getResponse = json.loads(getResponse) print (getResponse) statusText = getResponse[KEY_STATUS_TEXT] if statusText == STATUS_RUNNING or statusText == STATUS_QUEUEING : # 继续轮询 time.sleep(10) else : # 退出轮询 break except ServerException as e: print (e) except ClientException as e: print (e) if statusText == STATUS_SUCCESS : print ("录音文件识别成功!") else : print ("录音文件识别失败!") return accessKeyId = os.getenv('ALIYUN_AK_ID') accessKeySecret = os.getenv('ALIYUN_AK_SECRET') appKey = os.getenv('NLS_APP_KEY') fileLink = "https://gw.alipayobjects.com/os/bmw-prod/0574ee2e-f494-45a5-820f-63aee583045a.wav" # 执行录音文件识别 fileTrans(accessKeyId, accessKeySecret, appKey, fileLink)
执行如下命令,运行示例代码。
python3 demo.py执行成功后,会返回如下结果,并在最后一行显示录音文件识别成功。

若您了解得更多的录音文件转写接口文档,请参见接口说明。
通过SDK调用语音合成
在IDE编辑器中,打开上一步下载的示例代码,参照下图填写语音合成的参数。填写完成后,单击鼠标右键,选择Run "SpeechSynthesizerDemo main()"。
参数
参数值
Appkey
请在智能语音交互控制台获取Appkey。
Token
请在智能语音交互控制台总览单击点击获取临时AccessToken。
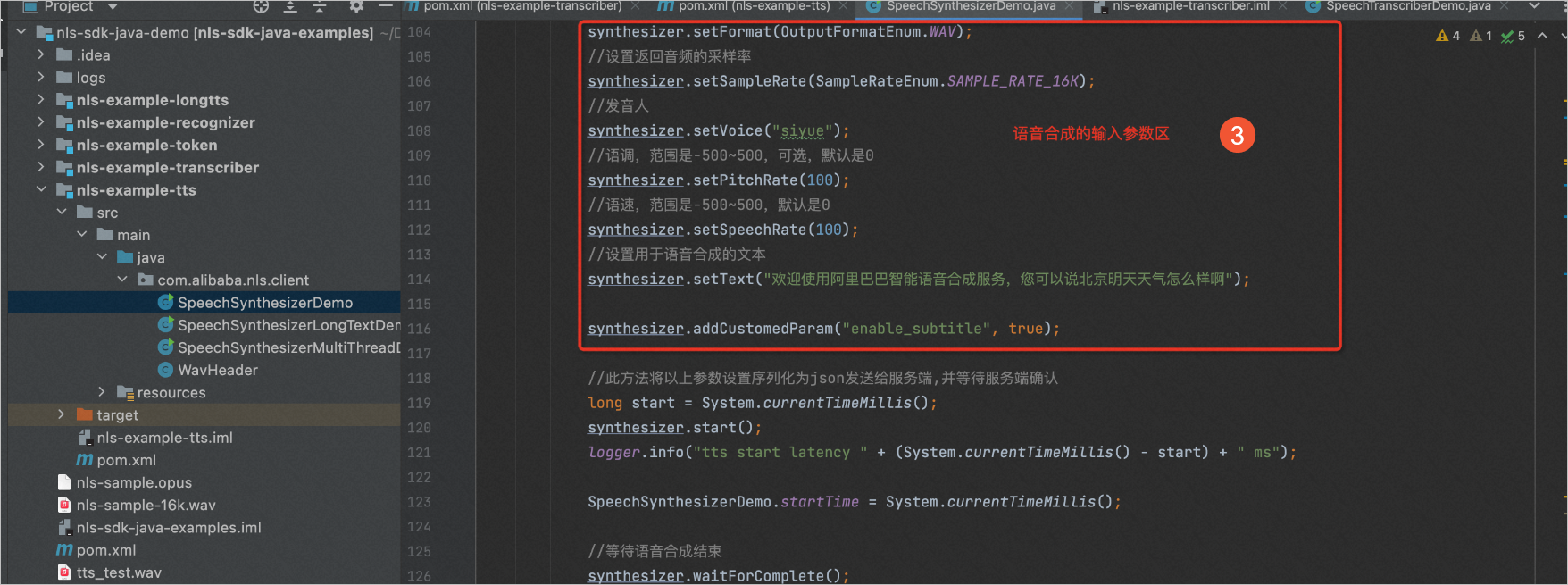
①:获取Appkey和Token,请参见从这里开始。
②:注释掉该段代码,该段代码用于JAR包命令行方式输入参数使用。
③:在该区域输入语音合成的参数。
实时识别返回结果如下,result即为识别结果。

若您了解得更多的语音合成接口文档,请参见接口说明。
通过Curl命令调用异步长文本合成RESTful接口
异步长文本语音合成无免费试用版,如果您希望体验长文本语音合成服务,请前往控制台将该服务升级为商用版。
在命令行执行如下命令,提交语音合成任务。
请在智能语音交互控制台获取Appkey。
请在智能语音交互控制台总览单击点击获取临时AccessToken。
curl -X POST 'https://nls-gateway-cn-shanghai.aliyuncs.com/rest/v1/tts/async' \ -H 'Content-Type: application/json' \ --data-raw '{ "payload":{ "tts_request":{ "voice":"xiaoyun", "sample_rate":16000, "format":"wav", "text":"今天天气好晴朗", "enable_subtitle": true }, "enable_notify":false }, "context":{ "device_id":"my_device_id" }, "header":{ "appkey":"TuBrUhcloN******", # 替换为您的Appkey。 "token":"d9afc8a07b154e0b86d4152265******" # 替换为您的Token。 } }'命令执行完成后,会获得如下返回结果,其中task_id为任务唯一标识。
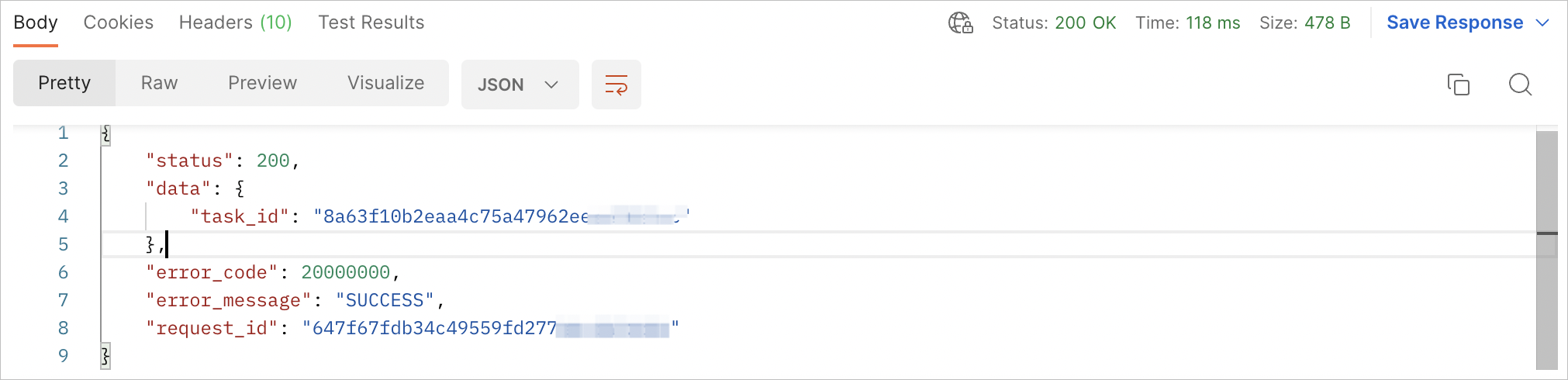
//POST响应结果返回如下,含Task_id。 {"status":200,"data":{"task_id":"8b240239f3c646748c84acaf98c****"},"error_code":20000000,"error_message":"SUCCESS","request_id":"cc03ca1bccab438eb74740127391****"}根据上一步中的task_id,发送GET请求,获取合成文件下载。
GET请求地址: https://nls-gateway-cn-shanghai.aliyuncs.com/rest/v1/tts/async?appkey={Appkey}&task_id={task_id}&token={Token} 样例如下: curl -X GET 'https://nls-gateway-cn-shanghai.aliyuncs.com/rest/v1/tts/async?appkey=TuBrUhcloNpE****&task_id=8b240239f3c646748c84acaf98c******&token=d9afc8a07b154e0b86d4152265******'命令执行成功后,会返回如下结果,其中audio_address为合成后语音的下载链接。
//GET请求响应返回示例,其中Audio_address即为合成语音的试听和下载地址,复制到浏览器中打开即可。 {"status":200,"data":{"sentences":[{"text":"今天天气好晴朗","begin_time":"0","end_time":"1985"}],"task_id":"8b240239f3c646748c84acaf9*","audio_address":"http://nls-cloud-cn-shanghai.oss-cn-shanghai.aliyuncs.com/jupiter-flow/tmp/8b240239f3c646748c84ac******.wav?Expires=16630****&OSSAccessKeyId=LTAI****************&Signature=rTFF****************","notify_custom":""},"error_code":20000000,"error_message":"SUCCESS","request_id":"6dd08e26170f4be8bd5a510daa2*****"}若您需要了解更多的异步长文本语音合成相关信息,请参见接口文档。
通过postman调用异步长文本合成RESTful接口
异步长文本语音合成无免费试用版,如果您希望体验长文本语音合成服务,请前往控制台将该服务升级为商用版。
请先下载Postman。
在Postman里发送如下Post请求。
请在智能语音交互控制台获取Appkey。
请在智能语音交互控制台总览单击点击获取临时AccessToken。
参数
示例
URL
https://nls-gateway-cn-shanghai.aliyuncs.com/rest/v1/tts/async
Header
Content-Type:application/json
Body
请参考如下代码。
Body代码:
{ "payload":{ "tts_request":{ "voice":"xiaoyun", "sample_rate":16000, "format":"wav", "text":"今天天气好晴朗", "enable_subtitle": true }, "enable_notify":false }, "context":{ "device_id":"my_device_id" }, "header":{ "appkey":"TuBrUhcloN******", # 替换为您的Appkey "token":"d9afc8a07b154e0b86d4152265******" # 替换为您的Token } }请按照下图填写Post URL。
请按照下图填写Headers。
请按照下图填写Body。
以上Post请求发送成功后,返回Response如下,含有task_id。
获取合成文件并下载。
根据上一步中的task_id发送Get请求。
GET请求地址: https://nls-gateway-cn-shanghai.aliyuncs.com/rest/v1/tts/async?appkey={Appkey}&task_id={task_id}&token={Token} 样例如下: https://nls-gateway-cn-shanghai.aliyuncs.com/rest/v1/tts/async?appkey=TuBrUhcloN******&task_id=8a63f10b2eaa4c75a47962eeee******&token=d9afc8a07b154e0b86d4152265******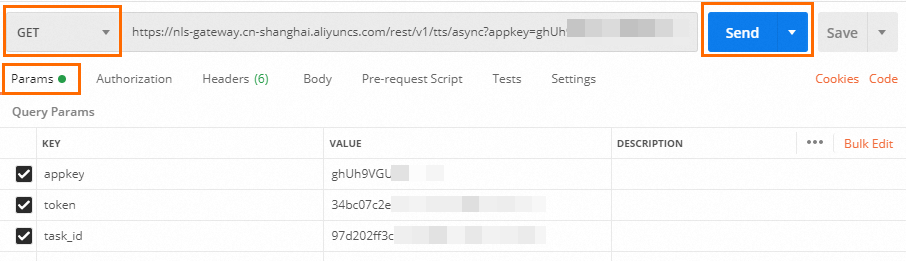
GET请求Response返回合成文件的audio_address地址,格式如下:
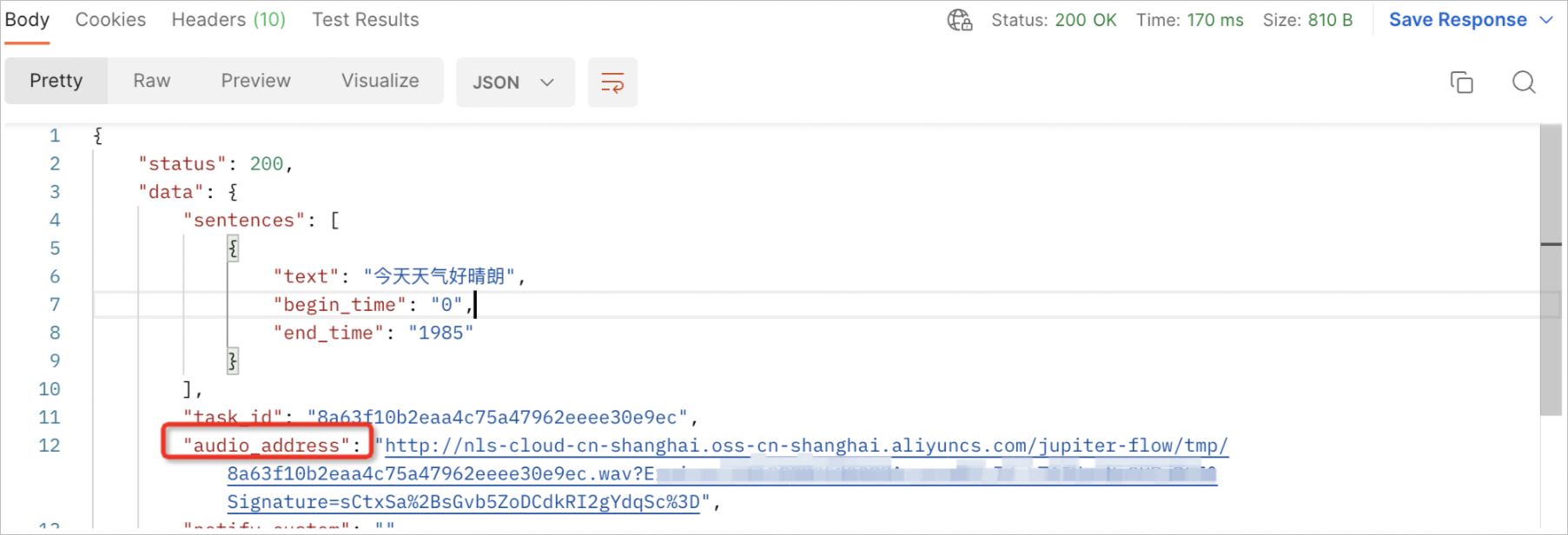
将上一步骤中的audio_address复制到浏览器即可试听和下载,此文件最多保留7天。

若您了解得更多的异步长文本语音合成接口文档,请参见接口文档。