
本文为您介绍如何通过公网环境将谷歌云GCP(Google Cloud Platform)的BigQuery数据集迁移至阿里云MaxCompute。
前提条件
|
类别 |
平台 |
要求 |
参考文档 |
|
环境及数据 |
谷歌云GCP |
|
如果您没有相关环境及数据集,可参考如下内容准备:
|
|
阿里云 |
|
如果您没有相关环境,可参考如下内容准备:
|
|
|
账号 |
谷歌云GCP |
已创建具备访问谷歌Cloud Storage权限的IAM用户。 |
|
|
阿里云 |
已创建具备存储空间读写权限和在线迁移权限的RAM用户及RAM角色。 |
||
|
区域 |
谷歌云GCP |
无。 |
无 |
|
阿里云 |
开通OSS服务的区域与MaxCompute项目在同一区域。 |
无 |
背景信息
将BigQuery数据集迁移至阿里云MaxCompute的流程如下。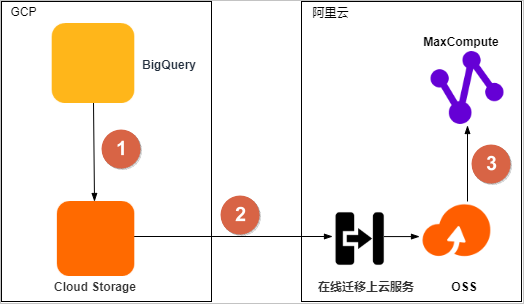
|
序号 |
描述 |
|
将BigQuery数据集导出至谷歌Cloud Storage。 |
|
|
通过对象存储服务OSS的在线迁移上云服务,将数据从谷歌Cloud Storage迁移至OSS。 |
|
|
③ |
将数据从OSS迁移至同区域的MaxCompute项目中,并校验数据完整性和正确性。 |
步骤一:将BigQuery数据集导出至谷歌Cloud Storage
您可以使用bq命令行工具执行bq extract命令,将BigQuery数据集导出至谷歌Cloud Storage。
-
登录Google Cloud控制台,创建存储迁移数据的分区(Bucket)。操作详情请参见创建存储分区。
创建完成后,在Cloud Storage的浏览器页面可查看已创建的存储分区,单击进入可在对象页签下查看分区内的文件夹和对象列表。
-
使用bq命令行工具,查询TPC-DS数据集中表的DDL脚本并下载至本地设备。操作详情请参见使用INFORMATION_SCHEMA获取表元数据。
如果您需要了解bq命令行工具,请参见使用bq命令行工具。
BigQuery不提供诸如
show create table之类的命令来查询表的DDL脚本。BigQuery允许您使用内置的用户自定义函数UDF来查询特定数据集中表的DDL脚本。DDL脚本示例如下。查询返回了xxx.tpcds_100gb.household_demographics和xxx.tpcds_100gb.web_sales两张表的 DDL 建表语句。其中household_demographics表包含hd_demo_sk INT64、hd_income_band_sk INT64、hd_buy_potential STRING、hd_dep_count INT64、hd_vehicle_count INT64等字段;web_sales表包含ws_sold_date_sk INT64、ws_sold_time_sk INT64、ws_ship_date_sk INT64等字段。 -
通过bq命令行工具执行
bq extract命令,将BigQuery数据集中的表依次导出至谷歌Cloud Storage的目标存储分区(Bucket)。相关操作及导出的数据格式和压缩类型详情请参见导出表数据。导出命令示例如下。
bq extract --destination_format AVRO --compression SNAPPY tpcds_100gb.web_site gs://bucket_name/web_site/web_site-*.avro.snappy; -
查看存储分区,检查数据导出结果。
步骤二:将导出至谷歌Cloud Storage的数据迁移至对象存储服务OSS
对象存储服务OSS支持通过在线迁移上云服务,将谷歌Cloud Storage的数据迁移至OSS,详情请参见谷歌云GCP迁移教程。在线迁移上云服务处于公测状态,您需要联系客服,并由在线服务团队开通后才可使用。
-
预估需要迁移的数据,包括迁移存储量和迁移文件个数。您可以使用gsutil工具或通过存储日志查看待迁移存储分区(Bucket)的存储量。详情请参见获取存储分区信息。
-
可选:如果您未创建存储分区,请登录OSS管理控制台,创建保存迁移数据的分区(Bucket),详情请参见控制台创建存储空间。
创建Bucket后,可在该Bucket的文件管理页面查看和管理已上传的文件及目录。
-
可选:如果您未创建RAM用户,请创建RAM用户并授予相关权限。
-
在GCP侧准备一个以编程方式访问谷歌Cloud Storage的用户。操作详情请参见通过JSON使用IAM权限。
-
登录IAM用户控制台,选择一个有权限访问BigQuery的用户。在操作列,单击
 > 创建密钥。
> 创建密钥。 -
在弹出的对话框,选择JSON,单击创建。将JSON文件保存至本地设备,并单击完成。
-
在创建服务账号页面,单击选择角色,选择,授予用户访问谷歌Cloud Storage的权限。
-
-
创建在线迁移数据地址。
-
登录阿里云数据在线迁移控制台。在左侧导航栏,在线迁移服务>数据地址。
-
在管理数据地址页面,单击创建数据地址,配置数据源及目标地址相关参数,单击确定。参数详情请参见迁移实施。
-
数据源配置示例:数据类型选择Google Storage,数据名称填写
google_storage_ds,Bucket填写gs_tpcds_100gb,Prefix选择迁移全部数据。说明Key File是步骤4下载的JSON文件。
-
目标地址配置示例:在创建数据地址弹窗中,数据类型选择OSS,数据名称填写
migration_destination_ds,数据所在区域选择印度尼西亚 (雅加达),OSS Endpoint填写对应区域的内网Endpoint,Access Key Id和Access Key Secret填写RAM用户的密钥信息,选择目标OSS Bucket,OSS Prefix填写tpc_ds_100gb/,然后单击确定。说明Access Key ID和Access Key Secret为RAM用户的密钥信息。
-
-
-
创建在线迁移任务。
-
在左侧导航栏,单击迁移任务。
-
在迁移任务列表页面,单击创建迁移任务,配置相关信息后,单击创建。参数详情请参见迁移实施。
-
任务配置在 任务配置 页签,设置 任务名称(例如
gs-to-oss-job),选择 源地址 和 目的地址,配置 迁移方式(全量迁移、增量迁移或数据同步)和 文件覆盖方式(最后修改时间优先、条件覆盖、全覆盖或不覆盖)。 -
单击性能调优页签,在数据预估区域填写待迁移存储量和待迁移文件个数,在流量控制区域可设置(每天)限流时间段和最大流量(MB/s),完成后单击创建。
说明待迁移存储量和待迁移文件个数是您通过Google Cloud控制台获取到的待迁移数据大小和文件个数。
-
-
创建的迁移任务会自动运行。请您确认任务状态为已完成,表示迁移任务成功结束。
-
在迁移任务的右侧单击管理,查看迁移任务报告,确认数据已经全部迁移成功。
-
登录OSS管理控制台。
-
在左侧导航栏,单击Bucket 列表。在Bucket 列表区域单击创建的Bucket。在Bucket页面,单击文件管理,查看数据迁移结果。
-
步骤三:将数据从OSS迁移至同区域的MaxCompute项目
您可以通过MaxCompute的LOAD命令将OSS数据迁移至同区域的MaxCompute项目中。
LOAD命令支持STS认证和AccessKey认证两种方式,AccessKey认证方式需要使用明文AccessKey ID和AccessKey Secret。STS认证方式不会暴露AccessKey信息,具备高安全性。本文以STS认证方式为例介绍数据迁移操作。
-
在DataWorks的临时查询界面或MaxCompute客户端(odpscmd),修改已获取到的BigQuery数据集中表的DDL,适配MaxCompute数据类型,创建与迁移数据相对应的表。
临时查询功能详情请参见使用临时查询运行SQL语句(可选)。命令示例如下。
CREATE OR REPLACE TABLE `****.tpcds_100gb.web_site` ( web_site_sk INT64, web_site_id STRING, web_rec_start_date STRING, web_rec_end_date STRING, web_name STRING, web_open_date_sk INT64, web_close_date_sk INT64, web_class STRING, web_manager STRING, web_mkt_id INT64, web_mkt_class STRING, web_mkt_desc STRING, web_market_manager STRING, web_company_id INT64, web_company_name STRING, web_street_number STRING, web_street_name STRING, web_street_type STRING, web_suite_number STRING, web_city STRING, web_county STRING, web_state STRING, web_zip STRING, web_country STRING, web_gmt_offset FLOAT64, web_tax_percentage FLOAT64 ) Modify the INT64 and FLOAT64 fields to obtain the following DDL script: CREATE TABLE IF NOT EXISTS <your_maxcompute_project>.web_site_load ( web_site_sk BIGINT, web_site_id STRING, web_rec_start_date STRING, web_rec_end_date STRING, web_name STRING, web_open_date_sk BIGINT, web_close_date_sk BIGINT, web_class STRING, web_manager STRING, web_mkt_id BIGINT, web_mkt_class STRING, web_mkt_desc STRING, web_market_manager STRING, web_company_id BIGINT, web_company_name STRING, web_street_number STRING, web_street_name STRING,` web_street_type STRING, web_suite_number STRING, web_city STRING, web_county STRING, web_state STRING, web_zip STRING, web_country STRING, web_gmt_offset DOUBLE, web_tax_percentage DOUBLE );BigQuery和MaxCompute数据类型的对应关系如下。
BigQuery数据类型
MaxCompute数据类型
INT64
BIGINT
FLOAT64
DOUBLE
NUMERIC
DECIMAL、DOUBLE
BOOL
BOOLEAN
STRING
STRING
BYTES
VARCHAR
DATE
DATE
DATETIME
DATETIME
TIME
DATETIME
TIMESTAMP
TIMESTAMP
STRUCT
STRUCT
GEOGRAPHY
STRING
-
可选:如果您未创建RAM角色,请创建具备访问OSS权限的RAM角色并授权。详情请参见访问外部数据源授权方案。
-
执行LOAD命令,将OSS的全部数据加载至创建的MaxCompute表中,并执行SQL命令查看和校验数据导入结果。LOAD命令一次只能加载一张表,有多个表时,需要执行多次。LOAD命令详情请参见LOAD。
LOAD OVERWRITE TABLE web_site FROM LOCATION 'oss://oss-<your_region_id>-internal.aliyuncs.com/bucket_name/tpc_ds_100gb/web_site/' --OSS存储空间位置。 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' WITH SERDEPROPERTIES ('odps.properties.rolearn'='<Your_RoleARN>','mcfed.parquet.compression'='SNAPPY') STORED AS AVRO;执行如下命令查看和校验数据导入结果。
SELECT * FROM web_site;返回结果示例如下。执行该语句后,返回
web_site表的24条记录,包含web_site_sk、web_site_id、web_name、web_manager、web_mkt_class、web_company_na等字段,表明数据已成功从OSS导入至MaxCompute。 -
通过表的数量、记录的数量和典型作业的查询结果,校验迁移至MaxCompute的数据是否和BigQuery的数据一致。