本文主要为您介绍使用Spark连接Phoenix,并将HBase中的数据写入到MaxCompute的实践方案。
背景信息
Phoenix是HBase提供的SQL层,主要为了解决高并发、低延迟、简单查询等场景。为了满足用户在Spark on MaxCompute环境下访问Phoenix的数据需求,本文从Phoenix表的创建与数据写入,再到IDEA上的Spark代码编写以及DataWorks上代码的冒烟测试,完整的描述了Spark on MaxCompute访问Phoenix的数据实践方案。
前提条件
在实践之前,您需要提前做好以下准备工作:
已开通MaxCompute服务并创建MaxCompute项目。详情请参见开通MaxCompute服务和创建MaxCompute项目。
已开通DataWorks服务。详情请参见DataWorks购买指导。
已开通HBase服务,详情请参见HBase购买指导。
说明本实践内容是以HBase 1.1版本为例。实际开发中,您也可以配套其他HBase版本。
已下载并安装Phoenix 4.12.0版本。详情请参见HBase SQL(Phoenix) 4.x使用说明。
说明HBase 1.1版本对应的Phoenix版本为4.12.0,实际开发过程中需要注意版本对应关系。
已开通专有网络VPC,并配置了HBase集群安全组。详情请参见网络开通流程。
说明本实践中,HBase是在VPC的网络环境下,所以安全组开放端口为2181、10600、16020。
操作步骤
进入Phoenix的
bin目录,执行如下示例命令启动Phoenix客户端。./sqlline.py hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181说明hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181为ZooKeeper的连接地址。您可以通过登录HBase控制台,在HBase集群实例详情页的数据库连接页面获取ZooKeeper的连接地址。在Phoenix客户端,执行如下语句创建表users,并插入数据。
CREATE TABLE IF NOT EXISTS users( id UNSIGNED_INT, username char(50), password char(50) CONSTRAINT my_ph PRIMARY KEY (id)); UPSERT INTO users(id,username,password) VALUES (1,'kongxx','Letmein');说明Phoenix语法详情,请参见HBase SQL(Phoenix) 入门。
在Phoenix客户端,执行如下语句查看users表的数据。
select * from users;在IDEA编译工具编写Spark代码逻辑并打包。
使用Scala编程语言编写Spark代码逻辑进行测试。
在IDEA中按照对应的Pom文件配置本地开发环境。您可以先使用公网连接地址进行测试,待代码逻辑验证成功后再调整代码示例中spark.hadoop.odps.end.point参数内容。公网连接地址请通过登录HBase控制台,在HBase集群实例详情页的数据库连接页面获取。具体代码如下:
package com.phoenix import org.apache.hadoop.conf.Configuration import org.apache.spark.sql.SparkSession import org.apache.phoenix.spark._ /** * 本示例适用于Phoenix 4.x版本。 */ object SparkOnPhoenix4xSparkSession { def main(args: Array[String]): Unit = { //HBase集群的ZooKeeper连接地址。 val zkAddress = hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181 //Phoenix侧的表名。 val phoenixTableName = users //Spark侧的表名。 val ODPSTableName = users_phoenix val sparkSession = SparkSession .builder() .appName("SparkSQL-on-MaxCompute") .config("spark.sql.broadcastTimeout", 20 * 60) .config("spark.sql.crossJoin.enabled", true) .config("odps.exec.dynamic.partition.mode", "nonstrict") // 需设置spark.master为local[N]才能直接运行,N为并发数。 //.config("spark.master", "local[4]") .config("spark.hadoop.odps.project.name", "***") .config("spark.hadoop.odps.access.id", "***") .config("spark.hadoop.odps.access.key", "***") //.config("spark.hadoop.odps.end.point", "http://service.cn.maxcompute.aliyun.com/api") .config("spark.hadoop.odps.end.point", "http://service.cn-beijing.maxcompute.aliyun-inc.com/api") .config("spark.sql.catalogImplementation", "odps") .getOrCreate() var df = sparkSession.read.format("org.apache.phoenix.spark").option("table", phoenixTableName).option("zkUrl",zkAddress).load() df.show() df.write.mode("overwrite").insertInto(ODPSTableName) } }对应的POM文件如下。
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <properties> <spark.version>2.3.0</spark.version> <cupid.sdk.version>3.3.8-public</cupid.sdk.version> <scala.version>2.11.8</scala.version> <scala.binary.version>2.11</scala.binary.version> <phoenix.version>4.12.0-HBase-1.1</phoenix.version> </properties> <groupId>com.aliyun.odps</groupId> <artifactId>Spark-Phonix</artifactId> <version>1.0.0-SNAPSHOT</version> <packaging>jar</packaging> <dependencies> <dependency> <groupId>org.jpmml</groupId> <artifactId>pmml-model</artifactId> <version>1.3.8</version> </dependency> <dependency> <groupId>org.jpmml</groupId> <artifactId>pmml-evaluator</artifactId> <version>1.3.10</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> <exclusions> <exclusion> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> </exclusion> <exclusion> <groupId>org.scala-lang</groupId> <artifactId>scalap</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.aliyun.odps</groupId> <artifactId>cupid-sdk</artifactId> <version>${cupid.sdk.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-core</artifactId> <version>4.12.0-AliHBase-1.1-0.8</version> <exclusions> <exclusion> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-mapred</artifactId> </exclusion> <exclusion> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-commons</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-spark</artifactId> <version>4.12.0-AliHBase-1.1-0.8</version> <exclusions> <exclusion> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-core</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <minimizeJar>false</minimizeJar> <shadedArtifactAttached>true</shadedArtifactAttached> <artifactSet> <includes> <!-- Include here the dependencies you want to be packed in your fat jar --> <include>*:*</include> </includes> </artifactSet> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>**/log4j.properties</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>reference.conf</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/services/org.apache.spark.sql.sources.DataSourceRegister</resource> </transformer> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.3.2</version> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile-first</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>在IDEA中将代码以及依赖文件打成JAR包,并通过MaxCompute客户端上传至MaxCompute项目环境中。详情请参见添加资源。
说明由于DatadWork界面方式上传JAR包有50 MB的限制,因此采用MaxCompute客户端上传JAR包。
在DataWorks上进行冒烟测试。
按照如下建表语句,在DataWorks上创建MaxCompute表。详情请参见创建并使用MaxCompute表。
CREATE TABLE IF NOT EXISTS users_phoenix ( id INT , username STRING, password STRING ) ;在DataWorks上,选择对应的MaxCompute项目环境,将上传的JAR包添加到数据开发环境中。详情请参见创建并使用MaxCompute资源。
新建ODPS Spark,并设置任务参数。详情请参见开发ODPS Spark任务。
提交Spark任务的配置参数如下图所示。
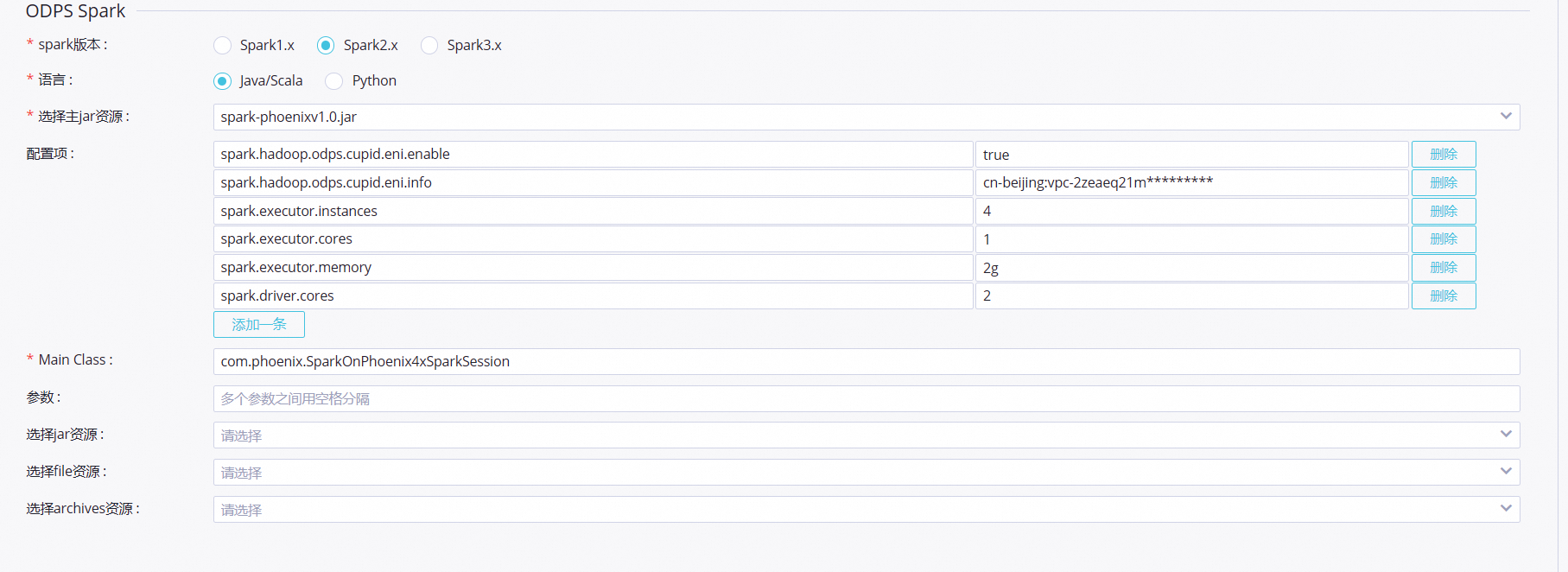
spark.hadoop.odps.cupid.eni.enable = true spark.hadoop.odps.cupid.eni.info=cn-beijing:vpc-2zeaeq21mb1dmkqh0****单击
 图标开始冒烟测试。
图标开始冒烟测试。
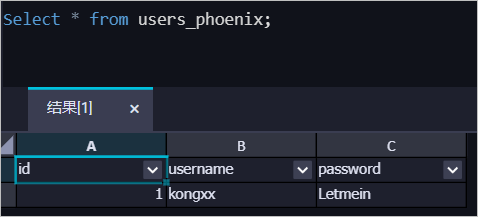
冒烟测试成功后,在临时查询节点中执行如下查询语句。
SELECT * FROM users_phoenix;可以看到数据已经写入MaxCompute的表中。