
MaxCompute推出外部项目功能,通过映射OSS上的Paimon catalog 目录,构建与标准Paimon文件系统层级一致的外部项目。访问权限基于用户RAMRole对OSS Bucket 的授权,支持对Paimon湖格式的元数据和数据进行读写。该方式实现 catalog级整体映射,需用户确保文件系统层级合规,由用户自主管理权限与湖格式文件存储,适用于权限可控、具备自主维护能力的流批一体场景。
适用范围
-
只支持Paimon格式表。
-
不支持写入Dynamic Bucket表。
-
不支持写入Cross Partition表。
操作步骤
步骤一:为RAM用户授权
如果操作用户是RAM用户,请确保已绑定如下权限策略。添加权限参考为为RAM用户授权。
-
AliyunMaxComputeFullAccess:用来完成创建外部数据源和外部项目操作。
步骤二:创建Filesystem Catalog外部数据源
-
开通OSS,并创建bucket存储了Paimon数据,详情请参见控制台快速入门。
-
登录MaxCompute控制台,在左上角选择地域。
-
在左侧导航栏,选择 。
-
在外部数据源页面,单击创建外部数据源。
-
在弹出的新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
是否必填
说明
外部数据源类型
必填
选择
Filesystem Catalog。外部数据源名称
必填
可自定义命名。命名规则如下:
-
以字母开头,且只能包含小写字母、下划线和数字。
-
不能超过128个字符。
例如
external_fs。外部数据源描述
选填
根据需要填写。
地域
必填
默认为当前地域。
认证和鉴权
必填
默认为阿里云RAM角色。
RoleARN
必填
RAM角色的ARN信息。此角色需要包含能够访问OSS服务的权限。
-
登录RAM控制台。
-
在左侧导航栏选择。
-
在基础信息区域,可以获取ARN信息。
示例:
acs:ram::124****:role/aliyunodpsdefaultrole。存储类型
必填
-
OSS
-
OSS-HDFS
Endpoint
必填
自动生成,杭州地域为:
oss-cn-hangzhou-internal.aliyuncs.com。外部数据源补充属性
选填
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
-
-
单击确认,完成外部数据源的创建。
-
在外部数据源页面,单击目标数据源对应的操作的详情,可查看数据源详细信息。
步骤三:创建外部项目
-
登录MaxCompute控制台,在左上角选择地域。
-
在左侧导航栏,选择。
-
在外部项目页签,单击新建项目。
-
在弹出的新增项目对话框,根据界面提示文案配置项目信息,单击确认完成项目创建。
参数
是否必填
说明
项目类型
必填
默认为外部项目。
地域
必填
默认为当前地域,此处无法修改。
项目名称(全网唯一)
必填
字母开头,包含字母、数字及下划线(_),长度在3-28个字符。
MaxCompute外部数据源类型
选填
选择Filesystem Catalog。
MaxCompute外部数据源
选填
-
选择已有:会出现已经创建过的外部数据源。
-
新建外部数据源:即可新建并使用新的外部数据源。
MaxCompute外部数据源名称
必填
-
选择已有:在下拉列表中选择已经创建好的外部数据源名称。
-
新建外部数据源:则会使用新建的外部数据源名称。
Bucket 数据目录
必填
选择完整的OSS Bucket和至Catalog级别的文件系统目录。本示例中
oss://paimon-fs/paimon-test/。表格式
必填
默认为Paimon。
计算资源付费类型
必填
包年包月或按量付费。
默认Quota
必填
选择已有Quota.
描述
选填
自定义项目描述。
-
步骤四:使用SQL访问数据源系统
由于外部项目和数据源之间是映射关系,所以删除外部项目并不会删除任何数据;
但与普通外部表不同,如果在外部项目中执行DROP TABLE / DROP SCHEMA 操作,该请求会发送到对端服务,因此会真正删除对应表或数据库中的数据,请谨慎执行DROP操作。
-
选择连接工具登录外部项目。
-
列出外部项目中的schema,默认只会列出存储Paimon表的DB路径。
-- 打开session级别支持schema语法开关。 SET odps.namespace.schema=true; SHOW schemas; -- 返回结果如下。 ID = 20250922********wbh2u7 default OK -
在外部项目中列出schema下的表。
-- schema_name为外部项目中展示出来的Schema名称。 USE SCHEMA <schema_name>; SHOW tables; -
在外部项目中新建schema。
CREATE schema <schema_name>; -- 示例如下。 CREATE schema schema_test; -
使用新建的schema。
use schema <schema_name>; -- 示例如下。 use schema schema_test; -
在schema中新建表并插入数据。
-
命令格式:
-- 新建表。 CREATE TABLE [IF NOT EXISTS] <table_name> ( <col_name> <data_type>, ... ) [COMMENT <table_comment>] [PARTITIONED BY (<col_name> <data_type>, ...)] ; -- 插入数据。 INSERT {INTO|OVERWRITE} TABLE <table_name> [PARTITION (<pt_spec>)] [(<col_name> [,<col_name> ...)]] <select_statement> FROM <from_statement> -
使用示例:
CREATE TABLE new_table(id INT,name STRING); INSERT INTO new_table VALUES (101,'张三'),(102,'李四'); -- 查询表new_table。 SELECT * FROM new_table; -- 返回结果如下。 +------------+------------+ | id | name | +------------+------------+ | 101 | 张三 | | 102 | 李四 | +------------+------------+
-
Paimon表属性透传
Apache Paimon 包含特有的核心配置选项。在外部项目中创建 Paimon 表时,如需配置这些参数,需将其添加到 Paimon 外部表的 WITH SERDEPROPERTIES 子句中。
配置方式: 在 TBLPROPERTIES 列表中添加以 mcfed.为前缀的参数,参数名称与开源 Paimon 原生参数保持一致。
参考示例
Paimon外表设置bucket>0、主键列为id和分区字段。
-
创建表,配置外部表参数
-- 进入到外部项目,如已经在外部项目内,可不加。 use <your external project>; -- 打开session级别支持schema语法开关。 SET odps.namespace.schema=true; -- 选择要使用的schema。 use schema <your schema>; CREATE TABLE oss_extable_bucket_pk_pt_bucket ( id BIGINT, name STRING, dt STRING )tblproperties ( 'mcfed.bucket'='3', -- bucket数量 'mcfed.bucket-key'='id', -- bucket key,有primary-key时可不写 "mcfed.primary-key"="dt,id", -- primary-key "mcfed.partition"="dt" -- 分区字段 ); -
向外部表插入数据
INSERT INTO oss_extable_bucket_pk_pt_bucket PARTITION (dt='2025-06-18') VALUES (1, 'Alice'),(2, 'Bob'); INSERT INTO oss_extable_bucket_pk_pt_bucket PARTITION (dt='2025-06-19') VALUES (3, 'Charlie'),(4, 'David'),(5, 'Eva'); -
查询外部表
SELECT * FROM oss_extable_bucket_pk_pt_bucket; -- 返回结果: +------------+---------+------------+ | id | name | dt | +------------+---------+------------+ | 1 | Alice | 2025-06-18 | | 2 | Bob | 2025-06-18 | | 4 | David | 2025-06-19 | | 3 | Charlie | 2025-06-19 | | 5 | Eva | 2025-06-19 | +------------+---------+------------+ -
登录数据湖构建(DLF)控制台,在左上角选择地域。
查看该catalog下生成表的详情:
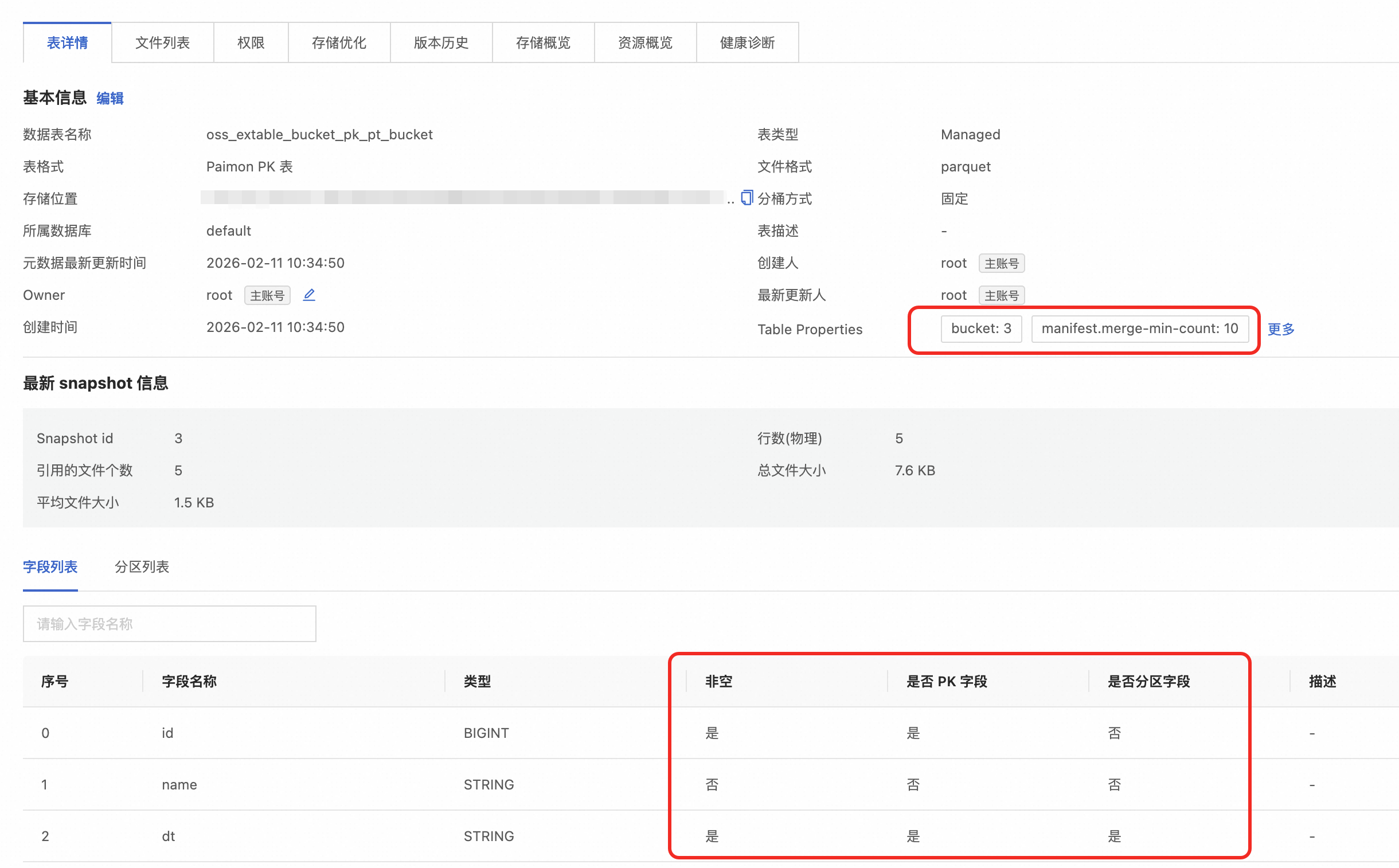
数据类型映射
MaxCompute数据类型请参见1.0数据类型版本和2.0数据类型版本。
|
开源Paimon数据类型 |
MaxCompute 2.0数据类型 |
是否支持读写 |
说明 |
|
TINYINT |
TINYINT |
|
8位有符号整型。 |
|
SMALLINT |
SMALLINT |
|
16位有符号整型。 |
|
INT |
INT |
|
32位有符号整型。 |
|
BIGINT |
BIGINT |
|
64位有符号整型。 |
|
BINARY(MAX_LENGTH) |
BINARY |
|
二进制数据类型,目前长度限制为8 MB。 |
|
FLOAT |
FLOAT |
|
32位二进制浮点型。 |
|
DOUBLE |
DOUBLE |
|
64位二进制浮点型。 |
|
DECIMAL(precision,scale) |
DECIMAL(precision,scale) |
|
10进制精确数字类型,默认为
|
|
VARCHAR(n) |
VARCHAR(n) |
|
变长字符类型。n为长度,[1,65535]。 |
|
CHAR(n) |
CHAR(n) |
|
固定长度字符类型。n为长度,[1,255]。 |
|
VARCHAR(MAX_LENGTH) |
STRING |
|
字符串类型目前长度限制为8MB。 |
|
DATE |
DATE |
|
日期类型格式为 |
|
TIME、TIME(p) |
不支持 |
|
Paimon数据类型TIME,不带时区的时间类型,由时分秒组成,精度可到纳秒。 TIME(p)表示小数位的精度,0-9之间,默认为0。 MaxCompute侧没有映射的类型。 |
|
TIMESTAMP、TIMESTAMP(p) |
TIMESTAMP_NTZ |
|
无时区时间戳类型,精确到纳秒。 读表需打开Native开关 |
|
TIMESTAMP WITH LOCAL TIME_ZONE(9) |
TIMESTAMP |
|
|
|
TIMESTAMP WITH LOCAL TIME_ZONE(9) |
DATETIME |
|
时间戳类型,精确到纳秒 格式为 |
|
BOOLEAN |
BOOLEAN |
|
BOOLEAN类型。 |
|
ARRAY |
ARRAY |
|
复杂类型。 |
|
MAP |
MAP |
|
复杂类型。 |
|
ROW |
STRUCT |
|
复杂类型。 |
|
MULTISET<t> |
不支持 |
|
MaxCompute侧没有映射的类型。 |
|
VARBINARY、VARBINARY(n)、BYTES |
BINARY |
|
可变长度二进制字符串的数据类型。 |