为满足业务对数据仓库中高度时效性数据的需求,MaxCompute基于Delta Table实现了分钟级近实时数据写入和主键更新功能,显著提升了数据仓库的数据更新效率。
数据写入场景
面对具有突发性和热点性的客户行为日志,如评论、评分和点赞,传统的关系型数据库和离线数据分析方法在处理这类数据时可能存在资源消耗大、成本高、数据延迟以及更新复杂的问题,通常只能满足次日分析需求。
针对上述问题,您可以采用近实时数仓数据入仓方案,可以在分钟级别内实现数据增量同步到Delta Table,从而将数据写入到查询的延迟控制在5~10分钟,极大地提高了数据分析的时效性。如果您的生产任务是将数据同步至MaxCompute ODS(Operational Data Store)层的普通表,为避免生产任务改造的风险,您可以使用Delta Table的Upsert功能,它能有效将数据同步至Delta Table,同时防止数据重复存储,并提高存储效率和降低存储成本。

示例
Flink数据写入Delta Table
本文以第三方引擎Flink为例,介绍了Flink集成MaxCompute Flink Connector进行近实时写入数据至Delta Table的主要流程。
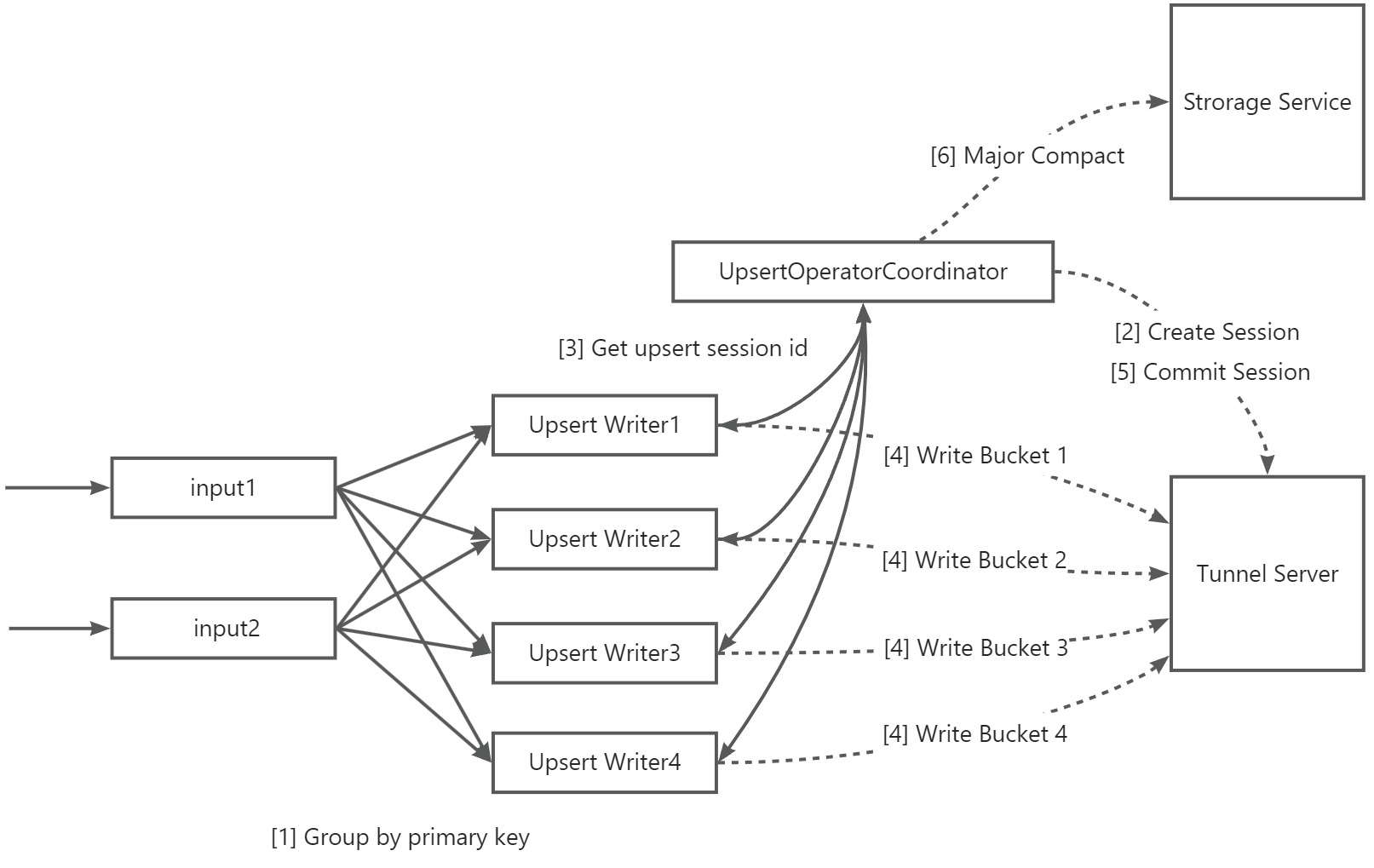
介绍如下:
序号 | 说明 |
【1】 | 支持按照数据的Primary Key列进行分组并发写入。 若您的并发写入的分区较多,且每个分区数据分布均匀,同时表的Bucket数量较少(如个位数),那么您也可以根据Partition列进行分组写入,有助于提高写入吞吐量。 |
【2】 | UpsertWriterTask收到数据后,会解析数据所属分区并向UpsertOperatorCoordinator发起请求,然后创建分区实时写入的Upsert Session。 |
【3】 | UpsertOperatorCoordinator向UpsertWriterTask返回已创建的Upsert session。 |
【4】 | UpsertWriterTask根据Upsert Session创建Upsert Writer,并连接MaxCompute的数据传输通道服务Tunnel Server,将数据持续写入。 在数据传输过程中,若启用了文件缓存,数据将会先进入Flink本地磁盘的缓存区,直到数据文件大小达到特定阈值或Checkpoint流程启动后,才将数据传输至Tunnel Server。 |
【5】 | Checkpoint流程启动后,Upsert Writer将数据全量提交至Tunnel Server,再向UpsertOperatorCoordinator发起请求,触发Commit操作,成功后数据可见。 |
【6】 | 若开启自动Major Compact,当分区Commit次数超过特定阈值时,由UpsertOperatorCoordinator向Storage Service发起Major compact操作。 说明 根据表数据量大小,此操作可能会对实时数据导入造成延时,因此需要谨慎使用。 |
将Flink数据写入至MaxCompute Delta Table的操作,详情请参见使用Flink写入数据到Delta Table。
Upsert写入参数配置建议
您可以通过调整Upsert实时写入场景的配置参数来提高系统吞吐量和性能,并确保稳定性,以满足不同的业务需求。Upsert写入参数详情,请参见Upsert写入参数。
通用关键参数配置
表Bucket数量可影响同时写入的最大并发数,在一定程度上决定了最大写入吞吐,推荐按照1 M/s * 表Bucket数量来计算总吞吐。
实际能达到的吞吐量与Sink节点并发等参数相关。详情请参见表格式和数据治理。
sink.parallelism:数据写入的Sink节点并发数,强烈建议表Bucket数量是该配置值的整数倍,可达到较好的性能效果。当sink.parallelism参数值与表Bucket数量一致时,理论上可以实现最佳性能。
非分区表提升吞吐的参数配置
如果设置了sink parallelism参数以增加写入并发,但发现吞吐量并未提升,可能的问题在于Sink节点的上游数据处理链路效率低下,建议您可优化数据处理链路来提高整体性能。
若表Bucket的数量是sink.parallelism的整数倍,那单个Sink节点写入的Bucket数量 = 表Bucket数量 ÷ sink.parallelism,若Bucket值过大,也会影响性能。建议您优先调整表Bucket数量和sink.parallelism参数值。若upsert.writer.buffer-size ÷ 单节点Bucket数量低于特定阈值(如128 K)时,可能会导致网络传输效率降低。为改善网络性能,建议考虑增大upsert.writer.buffer-size。
upsert.flush.concurrent参数:默认值为2,表示可并发flush的Bucket数。为了优化吞吐量,可以适当增加该值以观察性能提升。
说明需要注意的是,如果此值设置得过大,可能会导致过多的Bucket同时发送,从而引起网络拥堵,反而会使整体吞吐量下降。因此,在调整这个参数时需要谨慎,找到一个平衡点以确保系统的稳定和高效运行。
少量分区并发写入提升吞吐的参数配置
在此场景下,您可以参考通用关键参数配置和非分区表参数配置建议。同时,您还可以参考以下内容。
单个Sink节点在写入数据时涉及多个分区的操作,同时在Checkpoint阶段,每个分区需要独立进行Commit操作,这些特性可能会对整体的写入吞吐量产生影响。
单个Sink节点Buffer数据的最大内存=upsert.writer.buffer-size * 分区数,因此如果发生内存溢出(OOM),建议调整upsert.writer.buffer-size参数,减小其值以防止内存超出限制。
增加upsert.commit.thread-num参数值,可减少checkpoint阶段Commit的耗时。此参数默认值为16,意味着有16个线程并发处理分区进行Commit操作。
说明尽管可以适当增加这个数值以提高性能,但要注意不应超过32,以防止过度并发可能导致的问题。
海量分区并发写入(FileCached模式)提升吞吐的参数配置
在此场景下,您可以参考少量分区并发写入参数配置建议。同时,您还可以参考以下内容:
每个分区的数据都会首先缓存在本地文件中,然后在Checkpoint阶段并发写入MaxCompute中。
sink.file-cached.writer.num参数默认值为16,增加该参数值(不建议超过32),可增加单个Sink节点并发写入的分区数量。建议并发写入的Bucket数量建议等于sink.file-cached.writer.num * upsert.flush.concurrent。但需注意此值不应设置得过大,以防止引发网络拥堵问题,从而导致整体吞吐量下降。
FileCached模式写入参数详情,请参见FileCached模式写入参数。
其他建议
如果参考以上参数建议都无法达到吞吐要求,或者吞吐不稳定,需考虑以下因素:
每个项目空间可免费使用的公共数据传输服务资源组是有限的,达到上限后,会Block数据写入,从而导致整体吞吐下降。如果数据写入吞吐较大,同时对延时要求比较高,建议购买独享数据传输服务资源组,确保资源供给。
Connector的上游数据处理链路效率低下,导致整体吞吐率不高。建议您优化数据处理链路,以提高整体性能。
常见问题
Flink相关问题
问题一:
问题现象:提示出现报错信息“Checkpoint xxx expired before completing”。
问题原因:Checkpoint流程超时,通常由于Checkpoint过程中写入的分区数过多。
解决措施:
建议调整Flink Checkpoint时间,增加其时间间隔。
配置sink.file-cached.enable参数,开启文件缓存模式。详情请参见附录:新版Flink Connector全量参数。
问题二:
问题现象:提示出现报错信息“org.apache.flink.util.FlinkException: An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency. ”。
问题原因:通常由于JobManager与TaskManager通信异常导致,任务会自动发起重试。
解决措施:建议提升任务资源来确保任务稳定性。
数据写入问题
问题一:
问题现象:TIMESTAMP类型的数据在写入MaxCompute后,时间偏移了8小时。
问题原因:Flink中的TIMESTAMP类型不包含时区信息,且在MaxCompute写入过程中也不会进行时区转换,因此数据会被视为零时区数据。然而,MaxCompute在读取这些数据时,会根据项目的时区设定对数据进行转换。
解决措施:使用TIMESTAMP_LTZ类型替换MaxCompute Sink Table中的TIMESTAMP类型。
Tunnel相关问题
问题一:
问题现象:数据写入时出现Tengine相关报错,报错信息内容如下。
<body> <h1>An error occurred.</h1> <p>Sorry, the page you are looking for is currently unavailable.<br/> Please try again later.</p> <p>If you are the system administrator of this resource then you should check the <a href="http://nginx.org/r/error_log">error log</a> for details.</p> <p><em>Faithfully yours, tengine.</em></p> </body> </html>问题原因:远程Tunnel服务暂时不可用。
解决措施:等待Tunnel服务恢复后任务可以自动重试成功。
问题二:
问题现象:提示出现报错信息“java.io.IOException: RequestId=xxxxxx, ErrorCode=SlotExceeded, ErrorMessage=Your slot quota is exceeded.”。
问题原因:写入Quota超出限制,需要降低写入并发,或者增加独享Tunnel并发数。
解决措施:
降低写入并发,以减少对系统资源的占用。
增加独享Tunnel并发数,通过提升处理能力来适应更高的数据写入需求。购买独享资源详情,请参见购买与使用独享数据传输服务资源组。