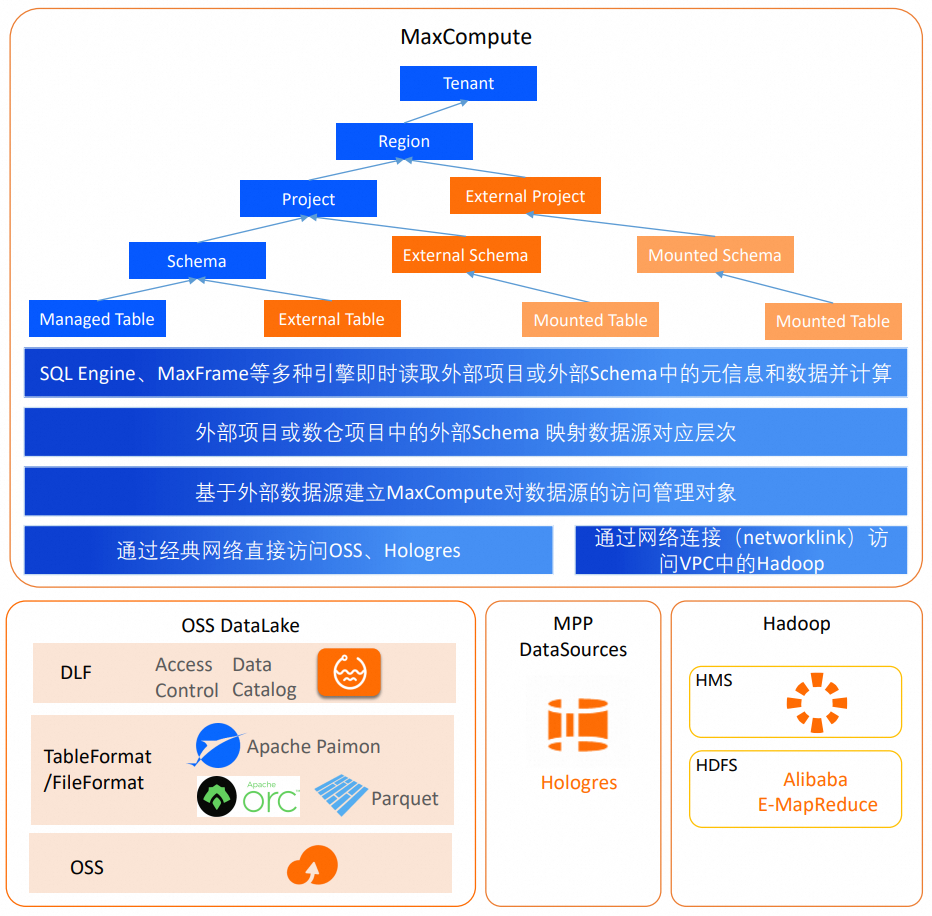
MaxCompute提供湖仓一体2.0方案,允许用户建立定义外部数据源元数据和数据访问方式的管理对象,并通过外部Schema映射机制实现直接访问外部数据源Database或Schema范围内的全部表的功能。该方案可以打破数据湖与数据仓库割裂的体系,并将数据湖的灵活性、丰富的多引擎生态与数据仓库的企业级能力进行融合,助力构建数据湖和数据仓库相融合的数据管理平台(本功能处于公测阶段)。
概念说明
数据仓库与数据湖对比
类别
能力
数据仓库
更强调对进入数仓的结构化、半结构化数据的管理和约束,并依赖强管理能力,获得更好的计算性能和更规范化的管理能力。
数据湖
更强调数据存储的开放性和数据格式的通用性,支持多种引擎按需生产或消费数据,为保障灵活性只提供弱管理能力,可以兼容非结构化数据,并支持后建Schema的使用方式,是一种更灵活的数据管理方式。
MaxCompute数据仓库
MaxCompute是基于Serverless架构的云原生数据仓库。您可以进行如下操作:
使用MaxCompute进行数据仓库建模。
使用ETL工具将数据加载入有结构定义的模型表中并存储。
使用标准的SQL引擎处理数仓中的海量数据,并通过Hologres OLAP引擎分析数据。
MaxCompute在数据湖上的使用场景和联邦场景
在数据湖场景中,数据存在于湖上,并有多种引擎生产或消费这些开放的数据。MaxCompute计算引擎作为湖上引擎的一种,也可以参与数据的加工和使用。此时,MaxCompute需要读取数据湖上游产生的数据,兼容多种主流开源数据格式,在引擎内计算,并持续向工作流下游生产数据。
同时,MaxCompute作为安全、高性能和高性价比、汇聚了高价值数据的数仓,也需要能够从数据湖上获取元数据和数据,进行外部数据的引擎内计算,并与仓内数据做联邦计算提取数据价值,向强管理的数仓汇聚。
除了在数据湖之上,MaxCompute作为数仓也需要获取多种外部数据源的数据,例如Hadoop、Hologres等,与仓内数据做联邦计算。在联邦计算场景下,MaxCompute同样需要支持读取外部系统的元数据和数据。
MaxCompute湖仓一体2.0
MaxCompute湖仓一体2.0基于MaxCompute计算引擎,支持通过云产品互联网络访问阿里云元数据或存储服务,或通过专线网络访问VPC中的外部数据源,允许用户建立定义外部数据源元数据和数据访问方式的管理对象,并通过外部Schema映射外部数据源的Database或Schema,实现直接访问外部数据源Database或Schema范围内的全部表的能力。
网络连接
详情请参见访问VPC方案(专线直连)中Networklink的相关说明。MaxCompute可以通过网络连接访问VPC网络中的数据源,例如EMR实例,RDS实例(准备中)。DLF(Data Lake Formation,数据湖构建)、OSS(对象存储)和Hologres位于云产品互联网络中,MaxCompute无需设置网络连接对象Networklink即可直接访问其中的数据。
外部数据源(Foreign Server)
包含了元数据和数据访问的信息,同时包含访问数据源系统的身份认证信息,位置信息和连接协议说明等。外部数据源是租户面的管理对象,由租户管理员定义。
在开启了项目级别租户资源访问控制功能模式下,由租户管理员将其挂载给使用外部数据源的项目,项目管理员再通过Policy将外部数据源的使用权限授予项目内部的用户。
外部Schema(External Schema)
外部Schema是MaxCompute数仓项目中一种特殊Schema,如上图所示,可以映射数据源的Database或Schema,并可直接访问对端Database或Schema范围内的表和数据,这种通过外部Schema映射至对端数据库的表被称为联邦外表。
联邦外表在MaxCompute内不存储元数据信息,而是由MaxCompute通过外部数据源对象中的元数据服务实时获取。用户查询时无需在数仓中通过DDL语句创建外部表,可直接以项目名称和外部Schema名称作为命名空间,引用数据源原表名的方式进行操作。数据源表结构或数据发生变化时,联邦外表能够即时反映数据源表的最新状态。外部Schema映射的数据源层次由外部数据源定义的层次与数据源中表层次之间的系统层次决定。外部数据源定义的层次由认证身份能访问的数据源层次决定。
外部项目(External Project)
在湖仓一体1.0中,外部项目是两层模式,和外部Schema一样映射一个数据源的Database或Schema,且需要依赖一个数仓项目才可以读取外部数据并计算。但是外部项目层级较高,映射数据源Database或Schema会导致外部项目数量过多,且无法和三层模式的数仓项目共用,MaxCompute会逐步收敛湖仓一体1.0的外部项目,存量用户可以迁移到外部Schema上。
在湖仓一体2.0中,用户可以通过外部Schema承接湖仓一体1.0中外部项目的全部能力,外部项目直接映射对端三层模式数据源Catalog或Database,并直接可见DLF Catalog之下的Database,或Hologres Database之下的Schema ,再以联邦外表的方式访问数据源表。湖仓一体2.0的外部项目会稍后推出,请关注官网文档说明。
数据源类型
外部数据源层次
外部Schema映射层次
湖仓一体2.0外部项目(稍后推出)映射层次
湖仓一体1.0外部项目(下线中)映射层次
认证方式
DLF+OSS
Region级别DLF服务和OSS服务
DLF的Catalog.Database
DLF的Catalog
DLF的Catalog.Database
RAMRole
Hive+HDFS
EMR实例
Hive的Database
不支持
Hive的Database
免认证方式
Hologres
Hologres实例的Database
Schema
Database
不支持
RAMRole
说明不同数据源的认证方式有多种类型,MaxCompute会在后续版本逐步提供多种认证方式,例如访问Hologres使用当前用户身份方式、访问Hive使用Kerberos认证方式等。
使用限制
仅华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华南1(深圳)、中国香港、新加坡和德国(法兰克福)地域支持构建湖仓一体2.0能力。
MaxCompute需要与DLF、OSS部署在同一地域。
外部Schema操作需要在内部项目中执行,因此要求内部项目必须已启用三层模型,您可在控制台界面进行操作,详情请参见功能开启。
注意事项
您需要为MaxCompute项目(即将创建External Schema的目标项目)开启项目级元数据支持的Schema开关,详情请参见项目级元数据支持的Schema开关。

您需要在执行Schema操作或查询External Schema的数据前,开启SQL语法支持的Schema开关,详情请参见SQL语法支持的Schema开关。
执行
SHOW tables IN <external_schema_name>命令(访问数据源系统)时:若在DataWorks数据开发IDE中执行,系统显示无法解析Schema时,除以上两点之外,您还需要保证DataWorks资源组集成的MaxCompute CMD为V0.46.8及以上版本,若CMD版本低于V0.46.8,请提交工单联系MaxCompute技术支持人员进行升级。
若在MaxCompute客户端(odpscmd)中执行,也需要将其升级至V0.46.8及以上版本。
说明您可以执行
SHOW VERSION;命令查看当前版本。创建的外部Schema支持查看Schema列表、查看Schema信息及删除Schema,其命令及使用方法与内部Schema相同。详情请参见Schema操作。
查看创建完成的外部数据源
在外部数据源管理列表中可以查看到已创建的外部表和数据源,参数信息如下:
参数名 | 描述 |
数据源名称 | 外部数据源的名称。 |
类型 | 外部数据源类型。目前支持DLF+OSS、Hive+HDFS和Hologres三种类型。 |
网络连接 | 使用了网络连接的外部数据源会显示网络连接名称。目前只有Hive+HDFS类型支持使用网络连接。 |
Owner账号 | 创建外部数据源的账号信息,外部Schema等会依赖外部数据源访问源端系统,访问的权限来源于外部数据源中创建者指定的身份信息。
|
已挂载项目 | 外部数据源挂载的项目数量。 |
创建时间 | 创建外部数据源的时间。 |
更新时间 | 上一次修改并保存外部数据源可编辑属性的时间。 |
操作-挂载项目 | 创建者设置外部数据源与项目的挂载关系。
|
操作-详情 | 查看外部数据源属性。 |
操作-编辑 | 修改外部数据源属性。 重要 修改了权限等信息,可能会造成项目内配置的授权关系因为可见对象范围变化而失效。 |
操作-删除 | 删除当前外部数据源。 重要 删除外部数据源后,依赖此外部数据源的任务都会失去访问外部系统的权限,且一并删除此外部数据源与所有项目之间的已配置的挂载关系。 |
创建并使用DLF+OSS湖仓一体
DLF+OSS数据源是以OSS作为数据湖存储服务,以DLF为湖上元数据管理服务的常用数据湖形态。MaxCompute支持创建此类型的外部数据源。通过MaxCompute与DLF和OSS的组合,可以实现数据仓库和数据湖的一体化,提供更加灵活和高效的数据管理和处理能力。
如您当前账号没有开启过租户级Schema语法开关,需要在下文SQL前增加SET odps.namespace.schema=true;语句,以便后续执行Schema相关语句。
步骤一:授权
步骤二:创建DLF+OSS外部数据源
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择租户管理>外部数据源。
在外部数据源页面,单击创建外部数据源。
在新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
说明
外部数据源类型
选择DLF+OSS。
外部数据源名称
可自定义命名。命名规则如下:
以字母开头,且只能包含小写字母、下划线和数字。
不能超过128个字符。
外部数据源描述
根据需要填写。
地域
默认为当前地域。
DLF Endpoint
默认为当前地域的DLF Endpoint。
OSS Endpoint
默认为当前地域的OSS Endpoint。
RoleARN
RAM角色的ARN信息。此角色需要包含能够同时访问DLF和OSS服务的权限。
您可以登录RAM访问控制台,在左侧导航栏选择身份管理>角色,单击对应的RAM角色名称,即可在基本信息区域获取ARN信息。
示例:
acs:ram::124****:role/aliyunodpsdefaultrole。外部数据源补充属性
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
单击确认,完成外部数据源的创建。
步骤三:创建外部Schema
引用了DLF+OSS类型外部数据源的外部Schema创建命令如下:
CREATE EXTERNAL SCHEMA IF NOT EXISTS <external_schema_name>
with <dlfoss_foreign_server_name>
ON '<dlf_calaog_id>.<database_name>';参数说明如下:
步骤四:使用SQL访问数据源系统
命令格式:列出DLF和OSS的表名称。
方式1:
SHOW tables IN <external_schema_name>; --external_schema_name为外部Schema名称。方式2:
USE SCHEMA <external_schema_name>; --external_schema_name为外部Schema名称。 SHOW tables;
使用示例:
查询名称为
es_dlf的外部Schema下的所有表名。USE SCHEMA es_dlf; SHOW TABLES;返回结果示例:
ALIYUN$xxx@test.aliyunid.com:hellocsv ALIYUN$xxx@test.aliyunid.com:t1 ALIYUN$xxx@test.aliyunid.com:t2 ALIYUN$xxx@test.aliyunid.com:t3查询
lakehouse47_3项目中es_dlfSchema的hellocsv表数据。SELECT * FROM lakehouse47_3.es_dlf.hellocsv;返回结果示例:
+------------+------------+------------+------------+ | col1 | col2 | col3 | col4 | +------------+------------+------------+------------+ | 1 | hello | test | world | +------------+------------+------------+------------+从数据源将联邦外表
hellocsv的数据复制入数仓。-- 将联邦外表的数据复制到数仓中 CREATE TABLE hellocsv_copy AS SELECT * FROM lakehouse47_3.es_dlf.hellocsv; -- 查询数仓中已复制的表数据 SELECT * FROM hellocsv_copy;返回结果示例:
+------------+------------+------------+------------+ | col1 | col2 | col3 | col4 | +------------+------------+------------+------------+ | 1 | hello | test | world | +------------+------------+------------+------------+
创建并使用Hive+HDFS联邦
Hive是常见的开源大数据的数据仓库解决方案,元数据大多存储在HMS中,数据大多存储在HDFS上。MaxCompute支持创建此类型的外部数据源。通过MaxCompute与Hive的联邦,可以实现数据仓库访问、汇聚开源大数据系统数据的能力。
Hive+HDFS模式的SQL后付费联邦计算任务在公测期间暂不收费。
如您当前账号没有开启过租户级Schema语法开关,需要在SQL前增加
SET odps.namespace.schema=true;语句,以便后续执行Schema相关语句。
步骤一:创建Hive+HDFS外部数据源
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择租户管理>外部数据源。
在外部数据源页面,单击创建外部数据源。
在新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
说明
外部数据源类型
选择Hive+HDFS。
外部数据源名称
可自定义命名。命名规则如下:
以字母开头,且只能包含小写字母、下划线和数字。
不能超过128个字符。
外部数据源描述
根据需要填写。
网络连接对象
网络连接名称,选择或创建MaxCompute到阿里云E-MapReduce或Hadoop VPC网络的连接。参数详情请参见访问VPC方案(专线直连)中的创建MaxCompute与目标VPC网络间的网络连接步骤。
说明网络连接基本概念请参见Networklink。
VPC必须与MaxCompute外部数据源及外部数据源挂载的项目处于同一地域。
集群名称
在Hadoop集群高可用环境下用于指代NameNode的名称。
以EMR集群为例,集群名称的获取方法如下:
登录EMR控制台,单击目标集群ID,进入集群详情页面。
在集群服务页签,单击HDFS服务的配置,进入配置页面。
切换至hdfs-site.xml页签,在配置项名称栏搜索
dfs.nameservices,该配置项对应的值则为集群名称。
NameNode地址
目标Hadoop集群的Active和Standby NameNode服务地址和端口号(端口号通常是8020)。
以EMR集群为例,NameNode地址的获取方法如下:
登录EMR控制台,单击目标集群ID,进入集群详情页面。
在集群服务页签,单击HDFS服务,进入状态页面。
在组件列表区域,单击NameNode前面的
 图标,展开拓扑列表。
图标,展开拓扑列表。获取master-1-1节点对应的内网IP,NameNode 地址格式即为
内网IP:8020。
HMS服务地址
目标Hadoop集群的Active和Standby NameNode的Hive元数据服务地址和端口号(端口号通常是9083)。
格式为
内网IP:9083。认证类型
暂时仅支持无认证方式。
交换机
MaxCompute通过VPC访问数据源,默认采用反向访问2.0技术方案,该方案需要配置特定可用区的交换机(VSW),打通元数据访问链路。各个Region可用交换机的可用区在界面提示中都有说明,您需要在要访问的数据源所在的VPC中,选择已有或新建满足可用区要求的交换机。
说明目前仅华东2(上海)地域需要填写此项信息。
外部数据源补充属性
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
单击确认,完成外部数据源的创建。
步骤二:创建外部Schema
外部Schema是项目内的对象,可以使用SQL进行操作。若您当前账号没有打开过租户级别Schema语法开关,需要在SQL前增加SET odps.namespace.schema=true;语句,以方便后续执行Schema相关命令。
引用了Hive+HDFS类型的外部数据源的外部Schema创建命令如下:
CREATE EXTERNAL SCHEMA IF NOT EXISTS <external_schema_name>
WITH <hive_foreign_server_name>
ON '<database_name>' ;参数说明如下:
external_schema_name:外部Schema名称。
hive_foreign_server_name:已创建的外部数据源名称。
database_name:Hive数据库名称。
步骤三:使用SQL访问数据源系统
命令格式:列出Hive的表名称。
方式1:
SHOW tables IN <external_schema_name>; --external_schema_name为外部Schema名称。方式2:
USE SCHEMA <external_schema_name>; --external_schema_name为外部Schema名称。 SHOW tables;
使用示例:
查询名称为
es_hive3的外部Schema下的所有表名。USE SCHEMA es_hive3; SHOW TABLES;返回结果示例:
ALIYUN$xxx@test.aliyunid.com:t1查询
lakehouse47_3项目中es_hive3Schema的t1表数据。SELECT * FROM lakehouse47_3.es_hive3.t1;返回结果示例:
+------------+ | id | +------------+ | 1 | +------------+从数据源将联邦外表
hellocsv的数据复制入数仓。-- 将联邦外表的数据复制到数仓中 CREATE TABLE t1_copy AS SELECT * FROM lakehouse47_3.es_hive3.t1; -- 查询数仓中已复制的表数据 SELECT * FROM t1_copy;返回结果示例:
+------------+ | id | +------------+ | 1 | +------------+
创建并使用Hologres联邦
Hologres是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving)。Hologres与MaxCompute深度融合,Hologres可以支持MaxCompute数仓上的OLAP模型的创建、分析和查询。MaxCompute支持创建Hologres外部数据源,通过与Hologres的联邦,可以实现以下场景。
超大规模数据仓库读取实时数仓的数据并归档。
读取维度数据或数据集市模型数据,与ODS、DWD、DWS层事实表关联计算。
读取OLAP模型数据进行高性能低成本离线计算,并将模型结果通过Hologres外部表或远端函数调用等方式返回给实时数仓进行分析。
如您当前账号没有开启过租户级Schema语法开关,需要在下文SQL前增加SET odps.namespace.schema=true;语句,以便后续执行Schema相关语句。
步骤一:创建Hologres外部数据源
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择租户管理>外部数据源。
在外部数据源页面,单击创建外部数据源。
在新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
说明
外部数据源类型
选择Hologres。
外部数据源名称
可自定义命名。命名规则如下:
以字母开头,且只能包含小写字母、下划线和数字。
不能超过128个字符。
外部数据源描述
根据需要填写。
连接方式
目前只支持经典网络访问(内网)
Host
Hologres实例的Host信息。
您可以登录Hologres管理控制台,在左侧导航栏选择实例列表,并单击对应的实例ID,即可在实例详情页面的网络信息区域获取Host。
示例:
hgpostcn-cn-3m***-cn-shanghai-internal.hologres.aliyuncs.com。重要仅支持通过经典网络域名进行访问。不支持通过VPC 网络域名访问Hologres。
Port
Hologres实例的端口信息。
您可以登录Hologres管理控制台,在左侧导航栏选择实例列表,并单击对应的实例ID,即可在实例详情页面的网络信息区域获取端口。端口一般为
80。DBNAME
Hologres实例的数据库名称。
认证和鉴权
阿里云RAM角色:使用RAM角色扮演认证鉴权方式,支持跨主账号的方式访问Hologres。联邦外表暂时只支持RAMRole方式。RoleARN填写示例:
acs:ram::uid:role/aliyunodpsholorole。aliyunodpsholorole角色配置及授权,详情请参见创建Hologres外部表(STS模式)。任务执行者身份:MaxCompute和Hologres之间的用户身份互认模式,允许MaxCompute和Hologres基于相同的账号,当前用户以自身的身份可以在两个系统中看到有权访问的表和数据,可以直接通过
CALL EXEC_EXTERNAL_QUERY函数执行命令,不需要额外设置认证信息。重要ExecuteWithUserAuth模式暂不支持联邦外表使用方式。
RoleARN
RAM角色的ARN信息,此角色需要包含能够访问Hologres服务的权限。认证方式选择RAMRole时需要填写该参数。
您可以登录RAM访问控制台,在左侧导航栏选择身份管理>角色,单击对应的RAM角色名称,即可在基本信息区域获取ARN信息。
添加外部数据源补充数据
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
单击确认,完成外部数据源的创建。
步骤二:创建外部Schema
外部Schema是项目内的对象,可以使用SQL进行操作。若您当前账号没有打开过租户级别Schema语法开关,需要在SQL前增加SET odps.namespace.schema=true;语句,以方便后续执行Schema相关命令。
引用了Hologres类型外部数据源的外部Schema创建命令如下:
CREATE EXTERNAL SCHEMA IF NOT EXISTS <external_schema_name>
with <holo_foreign_server_name>
ON '<holoschema_name>' ;参数说明如下:
external_schema_name:外部Schema名称。
holo_foreign_server_name:已创建的外部数据源名称。
holoschema_name:Hologres需要映射的Schema名称。
步骤三:使用SQL访问数据源系统
命令格式:列出Hologres Schema中的表名称。
方式1:
SHOW tables IN <external_schema_name>; --external_schema_name为外部Schema名称。方式2:
USE SCHEMA <external_schema_name>; --external_schema_name为外部Schema名称。 SHOW tables;
使用示例:
查询名称为
es_holo_rolearn_nonl的外部Schema下的所有表名:SET odps.namespace.schema=true; USE SCHEMA es_holo_rolearn_nonl; SHOW TABLES;返回结果示例:
ALIYUN$xxx@test.aliyunid.com:mc_holo_external查询
lakehouse47_3项目中es_holo_rolearn_nonlSchema的mc_holo_external表数据。SELECT * FROM lakehouse47_3.es_holo_rolearn_nonl.mc_holo_external;返回结果示例:
+------------+------------+------------+------------+ | col1 | col2 | col3 | col4 | +------------+------------+------------+------------+ | 1 | hello | test | world | +------------+------------+------------+------------+从数据源将联邦外表
hellocsv的数据复制入数仓。-- 将联邦外表的数据复制到数仓中 CREATE TABLE mc_holo_external_copy AS SELECT * FROM lakehouse47_3.es_holo_rolearn_nonl.mc_holo_external; -- 查询数仓中已复制的表数据 SELECT * FROM mc_holo_external_copy;返回结果示例:
+------------+------------+------------+------------+ | col1 | col2 | col3 | col4 | +------------+------------+------------+------------+ | 1 | hello | test | world | +------------+------------+------------+------------+
基于当前用户身份向Hologres提交执行命令
MaxCompute支持使用CALL命令,运行EXEC_EXTERNAL_QUERY函数,向Hologres侧提交可执行的SQL命令。
命令语法
CALL EXEC_EXTERNAL_QUERY ( '<holo_ExecuteWithUserAuth_foreign_server_name>', r"###( <holo_query>)###");holo_ExecuteWithUserAuth_foreign_server_name:即上文中以ExecuteWithUserAuth模式创建的Hologres外部数据源名称。r:表示即将执行的命令。holo_query:是在边界符中填写的具体Hologres SQL命令。
说明函数参考C++的Raw String方式,用
""和()加delimiter的边界符方式,避免前后边界符与holo_query中的特殊字符发生冲突。 delimiter字符串可以修改,注意"[delimiter]( )[delimiter]"一定要前后成对。边界符不包括<>,建议的边界符为"###(<holo_query>)###"。使用示例
示例1:在MaxCompute中提交一条向Hologres内部表
public.current_user_test进行INSERT OVERWRITE操作的SQL,数据来源是Hologres查询当前用户UID的Query:SELECT current_user;在MaxCompute中执行如下SQL。
CALL EXEC_EXTERNAL_QUERY ( 'fs_holo_ExecuteWithUserAuth_nonl_y', r"###( CALL hg_insert_overwrite( 'public.current_user_test', $$SELECT current_user$$ );)###");在Hologres中查询内部表
public.current_user_test的数据。SELECT * FROM current_user_test;返回结果:返回当前MaxCompute侧与Hologres侧相同用户身份的UID,如
1117xxxxxx519。
示例2:在MaxCompute中提交一条向Hologres内部表
public.hologres_parent_insert1,分区子表是2020,进行INSERT OVERWRITE操作的SQL,数据来源是Hologres内部的一张基于MaxCompute表的外部表:SELECT * FROM mc_external_table WHERE a='2020';在MaxCompute中执行如下SQL。
CALL EXEC_EXTERNAL_QUERY ( 'fs_holo_ExecuteWithUserAuth_nonl_y', r"###( CALL hg_insert_overwrite( 'public.hologres_parent_insert1', '2020', $$SELECT * FROM mc_external_table WHERE a='2020'$$ );)###");在Hologres中查询内部表
public.hologres_parent_insert1的数据。-- hologres查表,会多一条数据 SELECT * FROM hologres_parent_insert1;返回结果:
a b c d 2020 1 2024-06-19 10:27:46.201636 a
外部数据源的权限配置
外部数据源是MaxCompute租户面的资源对象,RAM用户是否能够执行对外部数据源的操作,取决于租户管理员在RAM访问控制台的权限管理>权限策略中对外部数据源配置的权限,创建权限策略详情请参见通过脚本编辑模式创建自定义权限策略。
示例:使用阿里云账号创建一条名为ForeignServerTest的权限策略,并将其授权给子账号。权限策略示例如下:
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": "odps:CreateForeignServer",
"Resource": "acs:odps:*:12xxxxxxxx07:foreignservers/*"
}
]
}增加查询全部外部数据源和获取某个外部数据源信息的权限:
如果您在创建外部数据源(CreateForeignServer)的同时,需要指定NetworkLink,则Resource中需要添加networklink。
如果指定了RAM Role,需要有对RAM Role的
ram:PassRole权限。
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": [
"odps:CreateForeignServer",
"odps:GetForeignServer",
"odps:ListForeignServers"
],
"Resource": "acs:odps:*:12xxxxxxxx07:foreignservers/*"
}
]
}其他Action说明如下:
Action名称 | 描述 |
CreateForeignServer | 创建外部数据源。 |
UpdateForeignServer | 更新外部数据源。 |
DeleteForeignServer | 删除外部数据源。 |
GetForeignServer | 获取某个外部数据源信息。 |
ListForeignServers | 查询全部外部数据源。 |
将已创建的Policy授权给子账号,即可对已授权的外部数据源执行相应操作。
项目级别租户资源访问控制
湖仓一体2.0引入的外部数据源是一种租户粒度的资源,权限由RAM Policy控制。而用户在项目中使用归属项目的对象(例如表),权限由项目管理员控制。对于租户对象是否有权被项目使用,以及在项目中使用权限的再分配,有两种安全管理模式。
若开启项目级别租户资源访问控制,创建者可以通过设置外部数据源与项目的挂载关系,指定哪些项目可以使用其创建的外部数据源,再由项目管理员通过Policy对项目内部的用户授予使用外部数据源的权限。
若未开启项目级别租户资源访问控制,任何创建了外部项目或外部Schema的用户,都可以使用此外部数据源,访问外部系统时同样基于外部数据源中创建者指定的RAMRole权限进行访问。除了湖仓一体2.0引入的外部数据源,网络连接、自定义镜像、配额组(Quota)也是租户粒度的对象,一起受项目级别租户资源访问控制开关的控制。
项目级别租户资源访问控制详情请参见项目级别租户资源访问控制。目前此功能仅提供预览,暂不支持开启检查。
开启项目级别租户资源访问控制,使用外部数据源和外部Schema访问联邦外表需要执行如下操作:
进行租户对象与项目的挂载关系配置,配置方法为点击租户对象,例如外部数据源,选择挂载的项目,确定完成关系的配置。挂载完成的租户对象可以在项目的已挂载租户对象列表中查询到。
对于已挂载到项目上的租户对象,进行Policy配置。配置方法参考Policy权限控制。
操作步骤
在MaxCompute控制台的工作区>项目管理页面,单击目标Project操作列的管理。
在角色权限页签,单击目标角色操作列的编辑角色。
在编辑角色对话框中,选择授权方式为Policy。
在Policy授权脚本框中修改角色Policy。
示例
以外部数据源为例,配置用户a可以使用外部数据源fs_hive的Policy如下:
{ "Statement":[ { "Action":[ "odps:Usage" ], "Effect":"Allow", "Resource":[ "acs:odps:*:servers/fs_hive" ] } ], "Version":"1" }当用户具有租户资源使用权限后,才可以在开启项目级别租户资源访问控制模式下,进行用户/角色粒度的租户资源使用权限控制。
项目开启租户对象检查开关(即开启项目级别租户资源访问控制)。
登录MaxCompute控制台,选择地域。
在左侧导航栏的工作区>项目管理页面,单击目标Project操作列的管理。
在参数配置页签的权限属性区域,单击编辑。
打开开启项目级别租户资源访问控制开关,并单击提交。
重要开启后,项目将立即对正在使用和后续使用的租户对象(包括外部数据源、网络连接、自定义镜像、配额组(quota))进行使用权限校验。因此在没有完全完成租户对象与项目的挂载关系配置,以及Policy授权之前,请勿轻易打开检查开关。权限缺失可能会造成依赖权限的任务失败。
外部Schema内对联邦外表授权
当外部Schema创建成功后,其表的所有者归属于外部Schema的账号。如果您需要将外部Schema权限或表操作权限授予其他用户,请执行下述操作。
由于MaxCompute在湖仓一体模式下不持久化数据源的元数据,权限策略依据数据源对象名称管理。数据源对象名称变更会导致授权失效,须通过Revoke命令或删除Policy方式移除授权;未及时移除可能导致新同名对象继承旧策略的权限定义,允许原用户获得外部项目中的数据源新同名对象的非预期权限。
开启Project内租户对象鉴权后,创建外部Schema之前需要将当前项目挂载在外部数据源上,如果没有提前进行挂载操作,会在创建外部Schema的时候报错
假设创建和管理External Schema的项目名称为test_lakehouse_project:
操作 | 所需权限 | 示例步骤 |
创建External Schema |
|
|
查询全部External Schema | Project的CreateInstance和List权限。 |
|
查询某个External Schema | Schema的Describe权限。 |
|
修改External Schema属性 | 目前暂不支持修改External Schema属性。 | |
删除某个External Schema | Schema的Drop权限。 |
|
使用某个External Schema |
| 指定当前使用某个External Schema。 若项目从两层模式升级为三层模式,需要对指定的Schema授予Describe权限。 |
查询某个External Schema下的表 | Schema内表的Select权限 |
|
将某个External Schema下的表数据导入至内部表 |
|
|